はじめに
Kolmogorov-Arnolds Network (KAN) は2024年に Liu et al. ICLR 2025 によって発表された論文です。1 KANの発想としては、今まで多層パーセプトロン (MLP) ではReLUなどの パラメータを持たない非線形変換 が用いられていたところ、 学習可能なパラメータを持つ非線形変換 を活性化関数として用いるというものです。具体的な手法としては、B-Splineを用いてパラメトリックでなめらかな関数を生成し、アルゴリズム的な工夫によってある程度の速度で動作させる、ということでした。
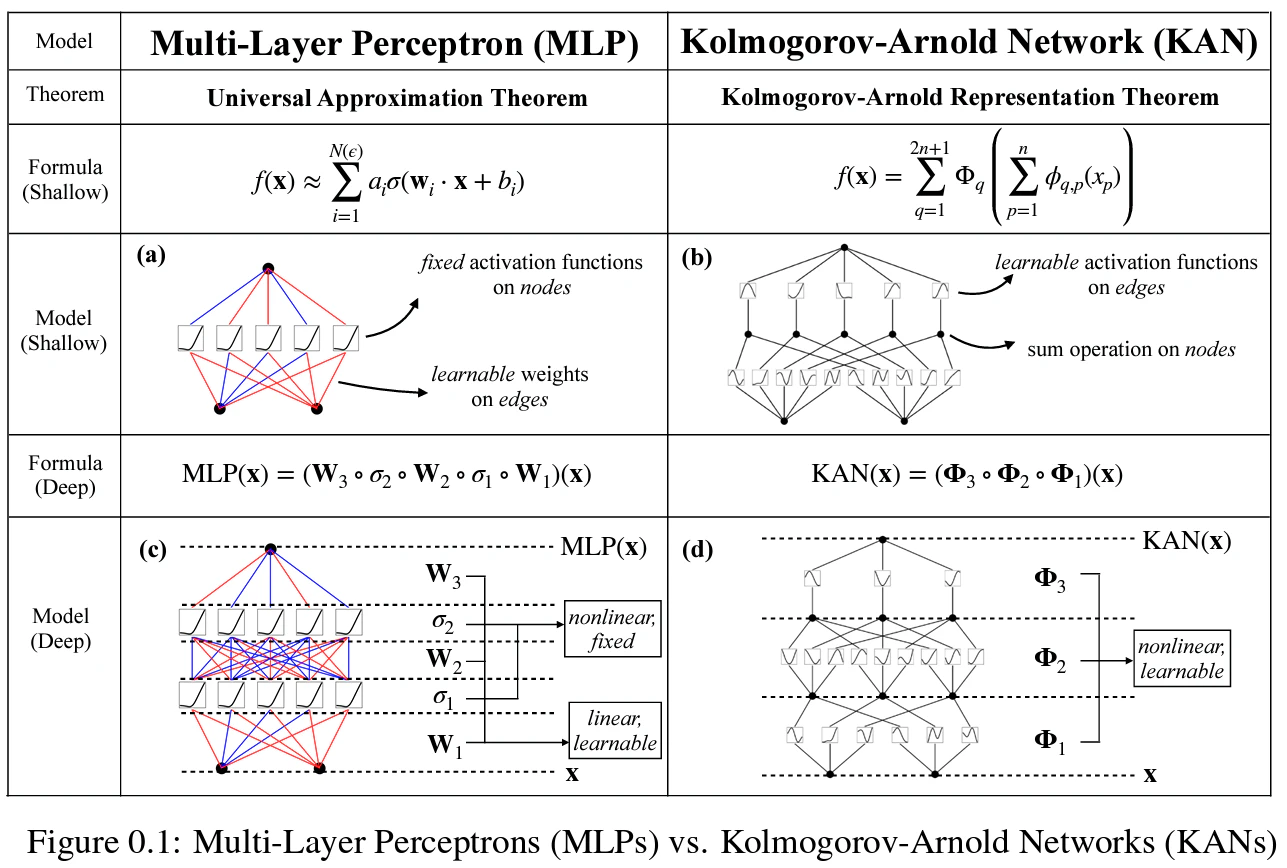
(Source: https://www.pondhouse-data.com/blog/kolmogorov-arnold-networks)
KANの売りはMLPと同様にほとんどの連続関数を近似できるというものでした。実際に、元論文での実験は主に、複雑な非線形関数をKANに学習させ、MLPよりも省パラメータ・高精度な近似を発見させる、というものでした。物理的なモデリングなどを念頭に置いていたように思われます。
そんなKANですが、次第に機械学習系のモデルに対しても有効性が確認されてきました。しばらくの間はVision系の複雑なタスクには応用できない、と思われていましたが、それも解決されつつあります。最新の FlashKAT (Raffel & Chen, AAAI 2026) では KANをViTに組み込んで精度を上げ、さらに速度的にもMLPと同等程度まで高速化されています。(特に大事なのは、推論だけではなく 訓練速度も十分高速である ということです。FlashKAT以前のモデルはここが不十分でした)
2025年は Linear Attention 系 (Mamba, RWKV) のモデルが流行っていた印象ですが、そろそろ様々なVisionタスクにKANが出てくるのではないかと思います。この記事では、そうしたVision + KAN の研究動向を通時的に追うことを試みます。
KAN発表直後のVision系研究
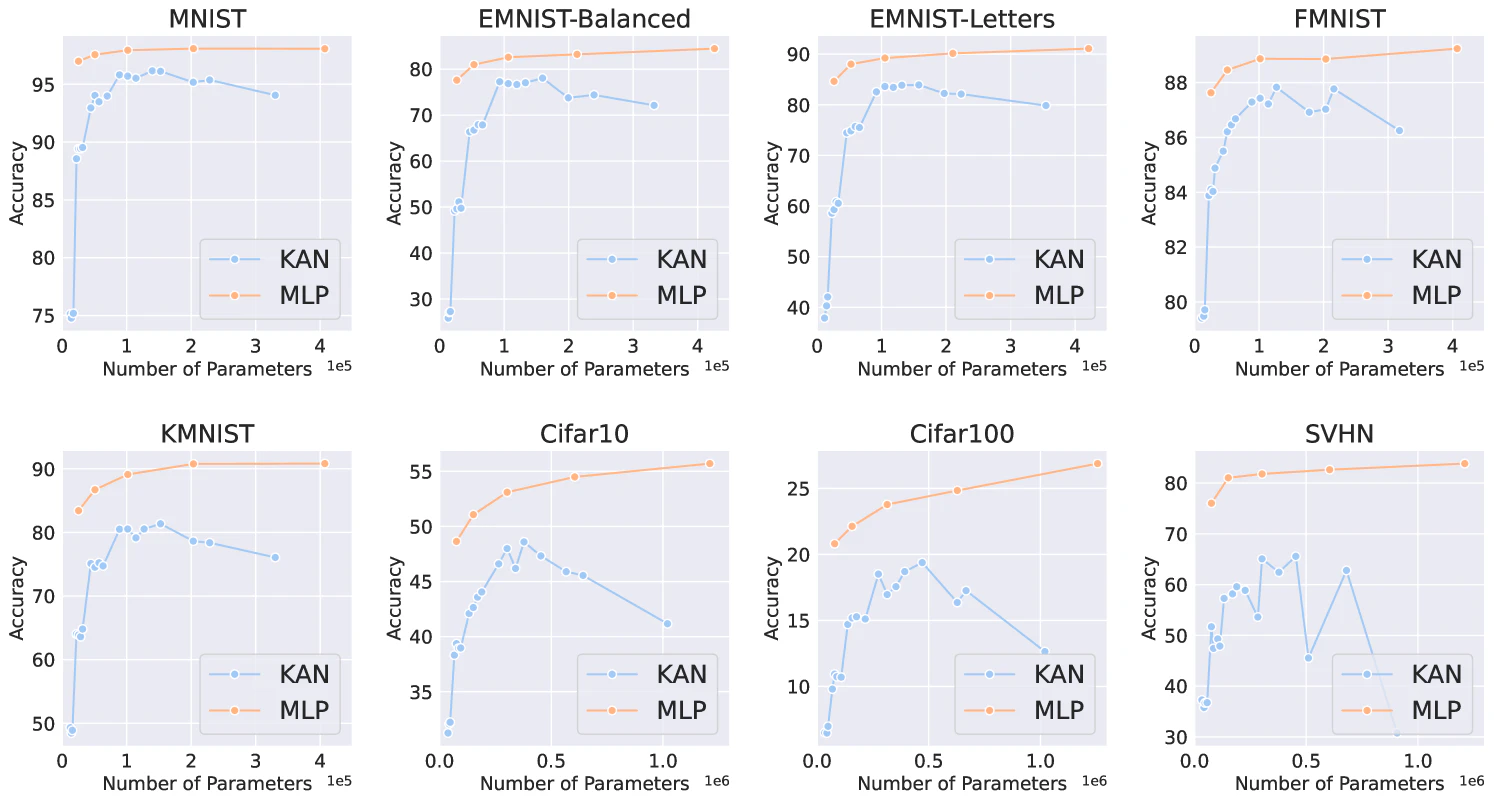
KANが2024年4月に発表され話題になると、多くの人が機械学習のタスク (MNIST, CIFAR-10, etc) に使えるの、本当にMLPを超えるアーキテクチャであるのかに関心を持ちました。そんな中、Yu et al. arXiv 2024 が検証を行い、「同じパラメータ量/計算量では、KANは数式フィッティング以外のほとんどのタスク (機械学習・自然言語処理・画像処理・音声処理)でMLPに負ける」ということを示しました。特にMNIST系の画像データでは下図のような性能で、さらにKANは同じパラメータ数ではMLPよりはるかに重いため、実用上はさらに悪化することが明らかでした。
同じく初期の研究としては Cheon, arXiv 2024 がありますが、これもあまり芳しい結果ではありません。主張としては、MLP-Mixerと同様のアーキテクチャをKANで作った結果、CIFAR-10でMLP-Mixerが60.26%, Resnet-18が86.29%なのに対して、KAN-Mixerは66.93%である、というものです。この時点でResnetに負けていますし、MLP-Mixerも特に工夫がなくとも70%~80%程度のパフォーマンスが出るはずです。2 アーキテクチャや訓練手法を見て比較しようにもそのあたりの結果が論文には示されておらず、そもそもこの論文があまり信用に足るものではないと思います。
他にも畳み込みネットワークと組み合わせた Bodner et al. arXiv 2024 や、 Vision Transformer のMLP層をKANに置き換えた Vision-KAN (論文なし) などが発表されましたが、いずれも大規模データセットでViTに勝つほどのパフォーマンスは達成できていませんでした。
Kolmogorov-Arnold Transformer (KAT)
KANとVision Task は厳しい戦いが続いていましたが、2024年9月に発表された Kolmogorov-Arnold Transformer (Yang & Wang, ICLR 2025) では、「適切に設計されたKANでViTのMLP層を置き換えることで、ViT, DeiTを超えSwinに迫る」という期待のおける結果が示されました。
では何を行ったのかというと、(1) 活性に有理数関数を用いたこと、(2) グループ化されたKANを用いたこと、が主な貢献です。順を追って(1)から説明します。KANの後続研究では、重いB-Splineを別の関数で置き換えるアプローチがよく取られており (Bozorgasl & Chen, arXiv 2024のWav-KAN, Li arXiv 2024のFastKAN), その中の一つ Aghaei arXiv 2024の rKAN で使われたのが有理数関数による近似です。
式で表すと
$$
\phi(x) = wF(x) = w\frac{P(x)}{Q(x)} = w\frac{a_0 + a_1x+\dots + a_m x^m}{b_0 + b_1x+\dots + b_n x^n}
$$
このように表され、$w, a_i, b_i$ は学習可能なパラメータ、$m, n$ はハイパーパラメータです。この式の勾配は明に計算することができます。数学的には Pedé近似というものに相当します。
さて、次にパラメータのことを考えてみます。上記の多項式では、分子に $(m+1)$個、分母に$(n+1)$個、さらに w が一つのパラメータがあるので、各入力に対して $m + n + 3$パラメータが必要です。ハイパーパラメータに関しては論文では $m=6, n = 4$ などが用いられます。この上で入力が128次元、出力が256次元なら、$128 \times 256 \times 14 + 256\simeq 0.42M$ パラメータです。MLPの場合は $128 \times 256$ (行列) + $256$ (バイアス) = $0.03M$ パラメータで済むことを考えると、KANは非常にヘヴィーなネットワークです。
一つのKAN層をMLPと同じ程度まで軽くするには、パラメータ数を10倍ほど小さくしないといけません。ここで著者たちは「すべての入出力のペアだけ多項式を作るのではなく、$g$種類の多項式のみ使う」という大胆なパラメータ共有手法を入れます。論文では G = 8が使われているので、入出力が何百次元あろうとも、8種類の多項式のみを用意します。数十個のパスが多項式部分には同じ値を共有することになります。
さらに追加の工夫として、パラメータ初期化の際にGELUやReLUを模倣するような値を用いることで、訓練の安定性を高め、訓練済みViTの重みから始めて学習することも可能になっています。これらの工夫を入れたのがKAT (Kolmogorov-Arnold Transformer) で、各タスクの性能ではViT, DeiTを超えています。ImageNetなど画像認識ではSwinに負けるものの、Semantic SegmentationやObject Detection では同サイズのSwinに勝つことが報告されています。
FlashKAT
KATは十分高速という触れ込みでしたが、動かしてみると意外と遅いことに気付きます。というのも、推論測度は十分高速でも、訓練時の逆伝播が異常なほど低速です。これを分析・改善したのが FlashKAT (Raffel & Chen, AAAI 2026) です。
技術的には面白いものの、実用上は「KATが筋の良い実装によって高速に動いた」ということがわかれば十分なので、こちらの説明は簡潔にします。
まず、計算ボトルネックになるのは逆伝播のメモリアクセスです。元の実装では新しく実装したRational KAN の係数の勾配をグローバルメモリで要素ごとに行っていたので、ここが低速でした。そこでFlashKATは2Dグリッド化・共有メモリ上での勾配蓄積・適切なバッチ化処理を入れることで、実際の速度を十分高速にしました。
今後の課題
発表当初はVisionでかなり渋い性能を示していたKANですが、最近のモデルでは各タスクでViT + MLPを超える性能を叩き出すに至りました。それでは、今後KANがVision研究の主流に食い込んでくるのでしょうか?
というところでは、まだ課題が残っていると思います。KATはViTよりは高性能ですが、タスクによってはSwinに負けていますし、それ以降のアーキテクチャにはもちろん負けます。性能そのものが十分に良いとは言えない状況です。
加えて、最近ではTransformerのMLP部分には、ただのMLPではなくSwiGLU (Swish Gated Linear Unit) などの洗練されたアーキテクチャが入るようになっています。KANがトップ性能になるためには、こうした新しいMLPヴァリアントにも勝つ必要があります。今後の研究に期待したいところです。
-
以下、出典は第一著者・学会/ジャーナル名・年で表記します。KAN論文のように、arXivで先に公開され、その後に学会投稿されたものは発表年と書誌情報の年が違うことがあります。 ↩
-
https://github.com/sayakpaul/MLP-Mixer-CIFAR10 の実験では2層のMLPブロックでも70.94%、https://wandb.ai/sulbing/CIFAR10/reports/CIFAR10-Only-MLP-Not-CNN---Vmlldzo1NjkyNjMw では81%程度の性能が報告されています。 ↩