概要
最近家族とオンライン麻雀サイト天鳳で週に1回2時間ほど楽しんでいます。
今回は対戦成績の分析を家族が皆がウェブ上で見れるようにしたのでその解説です。
プロセスとしては:
- Pythonで分析
- Dashを使って可視化
- HerokuとGithubを使ってデブロイ
こんな感じに仕上がりました↓
https://drmahjong.herokuapp.com/
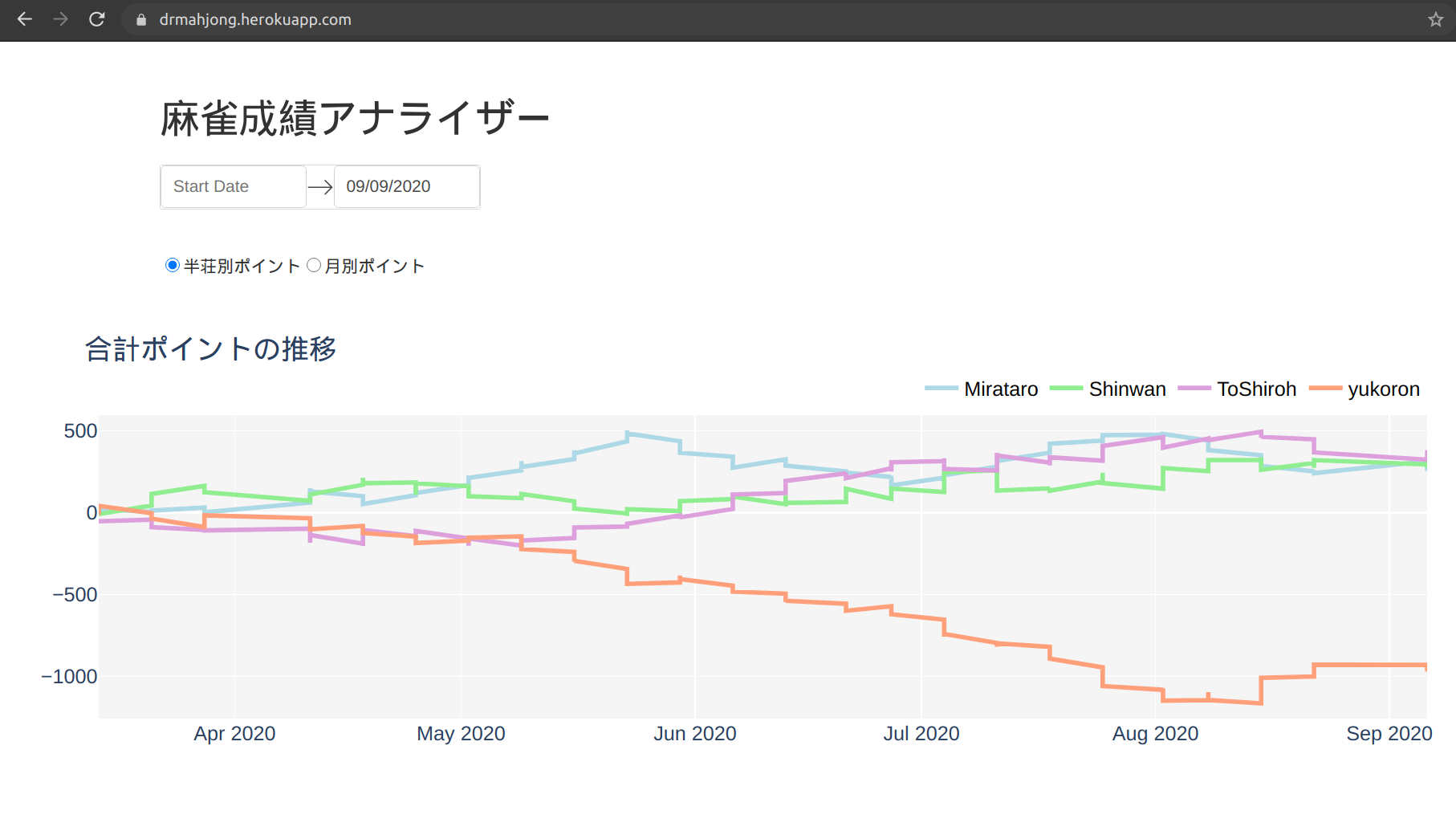
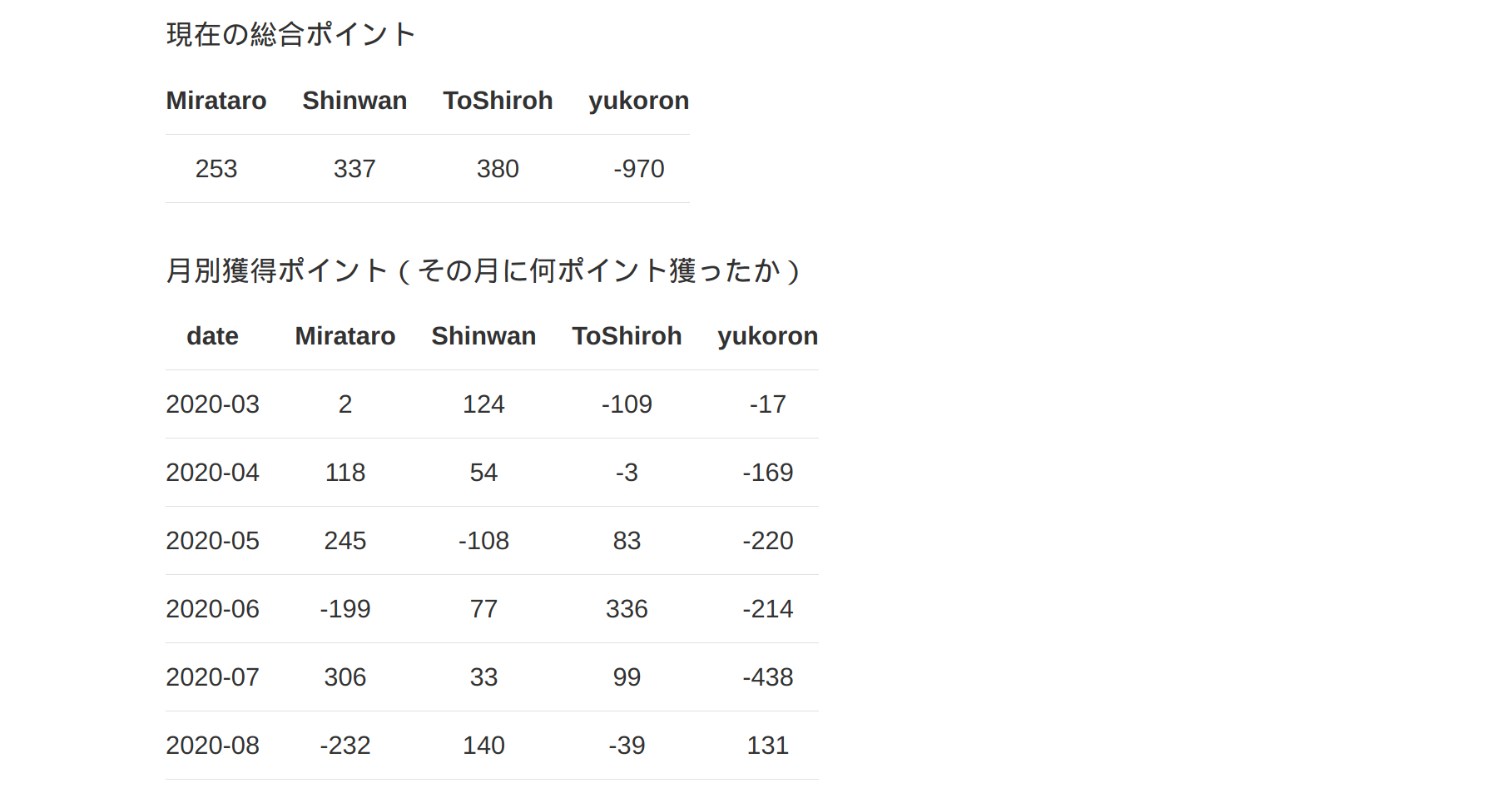
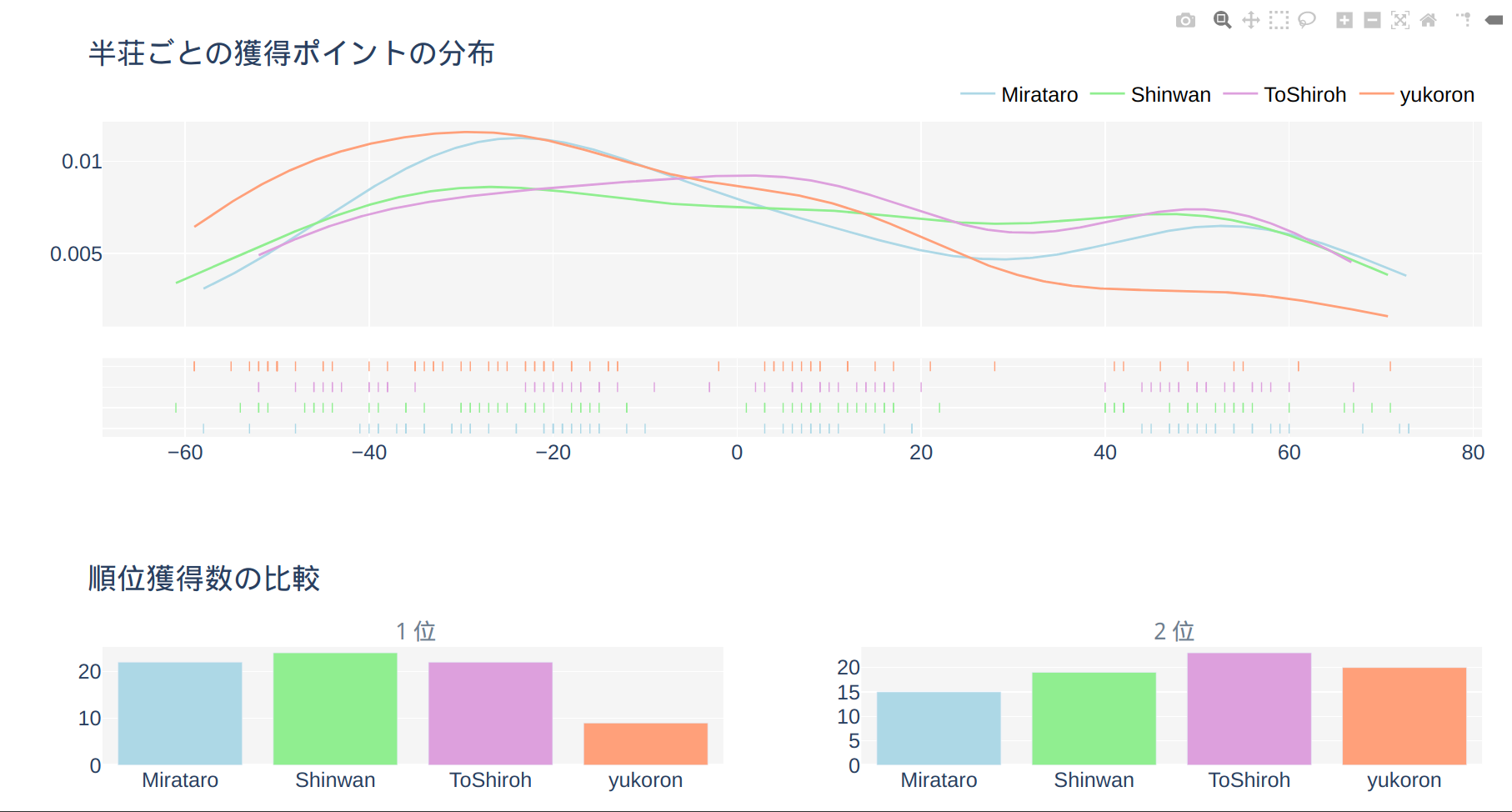
Codeは以下のGithubで見ることができます。
https://github.com/mottoki/mahjan-score
データを取る
天鳳のデータはログから取ることができます。requestというModuleを使用してデータを取ります。
import requests
import datetime
new_date = datetime.datetime.now().strftime('%Y%m%d')
url = "https://tenhou.net/sc/raw/dat/"+f"sca{new_date}.log.gz"
filename = f"sca{new_date}.log.gz"
# Download gz file from the url
with open(filename, "wb") as f:
r = requests.get(url)
f.write(r.content)
PythonとPandasを使ってデータ処理
Rawデータをプレイヤーの名前でフィルターをかけて、splitを使用してプレイヤーの名前とポイントだけのデータフレームを摘出します。
import os
import pickle
import pandas as pd
# プレイヤーの名前
playercol = ['date', 'Mirataro', 'Shinwan', 'ToShiroh', 'yukoron']
# Pandasのデータフレームに変換
df = pd.read_csv(filename, usecols=[0], error_bad_lines=False, header=None)
df[len(df.columns)] = new_date
# プレイヤーの名前でフィルターをかける
df = df[(df[0].str.contains(playercol[1])) &
(df[0].str.contains(playercol[2])) &
(df[0].str.contains(playercol[3])) &
(df[0].str.contains(playercol[4]))]
# データフレームの処理を行う
df[['one','two','three','four']] = df[0].str.split('|', 3, expand=True)
df.columns = ['original', 'date', 'room', 'time', 'type', 'name1']
df['date'] = pd.to_datetime(df['date'], format='%Y%m%d')
df[['empty', 'n1', 'n2', 'n3', 'n4']] = df.name1.str.split(" ", n=4, expand=True)
# 重要なコラムだけ使用
df = df[['date', 'n1', 'n2', 'n3', 'n4']]
# スコアと名前についているカギカッコを取り去りデータフレーム化する
new_score = pd.DataFrame(columns=playercol)
k=0
for i, j in df.iterrows():
dd = j[0]
new_score.loc[k, 'date'] = dd
for name in df.columns[1:]:
s = j[name]
player = s.split('(')[0]
score = [p.split(')')[0] for p in s.split('(') if ')' in p][0]
score = int(float(score.replace('+', '')))
new_score.loc[k, player] = score
k += 1
# 古いデータをPickleから呼ぶ
current_dir = os.getcwd()
old_score = pd.read_pickle(f"{current_dir}/players_score.pkl")
# 新しいデータと古いデータを合わせる
concat_score = pd.concat([old_score, new_score], ignore_index=True)
concat_score.to_pickle(f"{current_dir}/players_score.pkl")
Dashを使って可視化する
Dashというライブラリを使って素早くデータの可視化を行います。
Dashのチュートリアルが一番わかりやすいです。(参考:Dash Documentation & User Guide)
Dashで引っかかるところのはCallbackという機能ですが、Pythonの可視化ライブラリDashを使う 2 Callbackをみるなど詳しく説明されている方がいますのでそちらを参照してください。
1. Front側(ウェブに見えるもの)
全てのコードを説明すると長くなってしまうので、コアとなる部分を例として説明します。
基本的に最初の app.layout= の中に書かれているものは全てウェブサイトで表示されるものです。
表示したくないもの(例えば何度も使うデータ「intermediate-values」)は style={'display': 'none'} と入れるとウェブ上で見えなくなります。
# フロントエンドはこのなかに書く
app.layout = html.Div([
# データに反映される日付をユーザーが選べるようにする
html.Div([
html.H2("DR.麻雀"),
dcc.DatePickerRange(
id='my-date-picker-range',
min_date_allowed=dt(2020, 3, 1),
max_date_allowed=dt.today(),
end_date=dt.today()
),
], className="mytablestyle"),
# 何度も使うデータ:style={'display': 'none'}で見えなくする
html.Div(id='intermediate-value', style={'display': 'none'}),
# ポイントの推移(グラフ)
dcc.Graph(id='mygraph'),
# 総合ポイント(テーブル)
html.Div([
html.Div(html.P('現在の総合ポイント')),
html.Div(id='totalscore'),
], className="mytablestyle"),
])
2. CallbackでデータをJson化する
データをpandasのread_pickleで読み込み、日付でフィルターをかけ、json化して戻します。
こうすることによって同じデータをグラフやテーブルに何度も使えるようになります。
@app.callback(Output("intermediate-value", "children"),
[Input("my-date-picker-range", "start_date"),
Input("my-date-picker-range", "end_date")])
def update_output(start_date, end_date):
players = pd.read_pickle('players_score.pkl')
if start_date is not None:
start_date = dt.strptime(re.split('T| ', start_date)[0], '%Y-%m-%d')
players = players.loc[(players['date'] >= start_date)]
if end_date is not None:
end_date = dt.strptime(re.split('T| ', end_date)[0], '%Y-%m-%d')
players = players.loc[(players['date'] <= end_date)]
return players.to_json(date_format='iso', orient='split')
3. Callbackでデータをグラフ化&テーブル化
json化したデータをPandasのデータフレームに戻し、グラフ化とテーブル化していきます。
グラフ化はPlotlyの様式に乗っ取り、go.Figure()で表します。
テーブル化はhtml.Tableで表しました。テーブルはdash_tableというライブラリもあるのですが、今回のテーブルは簡易なものだったので必要ないろ思いこのスタイルにしました。
@app.callback([Output('mygraph', 'figure'),
Output('totalscore', 'children')],
[Input('intermediate-value', 'children'),
Input('datatype', 'value')])
def update_fig(jsonified_df, data_type):
# Json化したデータをPandasでもとに戻す。
players = pd.read_json(jsonified_df, orient='split')
# グラフ化
fig = go.Figure()
for i, name in enumerate(players.columns[1:]):
fig.add_trace(go.Scatter(x=players.date,
y=np.array(players[name]).cumsum(),
mode='lines',
name=name,
line=dict(color=colors[i], width=4)))
fig.update_layout(plot_bgcolor='whitesmoke',
title='合計ポイントの推移',
legend=dict(
orientation="h",
yanchor="bottom",
y=1.02,
xanchor="right",
x=1,)
)
# 総合ポイントを計算
summed = players.sum()
# グラフと表を返す
return fig, html.Table([
html.Thead(
html.Tr([html.Th(col) for col in summed.index])
),
html.Tbody(
html.Tr([html.Td(val) for val in summed])
),
])
HerokuとGithubを使ってデプロイ
最後にHerokuとGithubを使ってデプロイしていきます。
公式サイト(Deploying Dash Apps)にはGitとHerokuのやりかたが詳しく載っているので、ほとんどやり方は一緒です。
プロセスはこんな感じです:
-
Githubのアカウントにサインアップする
-
Githubの新しいレポジトリを作成する
-
GithubにSSH接続する。(オプショナルですが、やったほうが楽。参照:GitHubにssh接続できるようにする)
-
デプロイに必要なファイル(
.ignore,Procfile,requirements.txt)を作成する。gunicornも必要なのでpip install gunicornでインストールする。 -
Gitコマンドで上記のファイルと
app.pyやplayers_score.pklのデータファイルをGithubにプッシュする。git init git add . git commit -m "メッセージ" git remote add origin git@github.com:<ユーザー名>/<レポジトリ名> git push origin master -
Githubにプッシュされているのを確認したらHerokuのアカウントを作成して
New > create new appのボタンで新しいアプリを作成(Regionは日本がないので、United Statesを選択)。 -
作成されたアプリのDeployのタブをクリックし、
Deployment methodをGithubにし、2.で作成したレポジトリに接続します。 -
最後に
Manual deployのDeploy Branchという黒いボタンを押すと勝手にデプロイしてくれます。
最後に
いかかでしたでしょうか。
cronとHerokuのAutomatic Deployを使えば天鳳から取ってくる新しいデータのアップデートを自動化することも可能です。(参考:cronでGithubにPushするプロセスを自動化する)