Summary
JavaScript(TypeScript) で MCMC ・メトロポリス・ヘイスティング法を実装して解説してみる記事です。
概ね こちらの記事 の JavaScript 実装版です。
この節の内容を実感するために一番良い方法は、どんな計算機言語でもいいから、
ここで述べたことを白紙から実装してみることである。
という訳で実際にやってみました。
手元でアニメーションで動いてくれるものが出来て理解が深まりました 😉👌
作ったもの
まずは 成果物 をご覧ください。
最初の50回を Burn-in 期間として、棄却含め250回までのサンプリングを散布図にプロットしています。
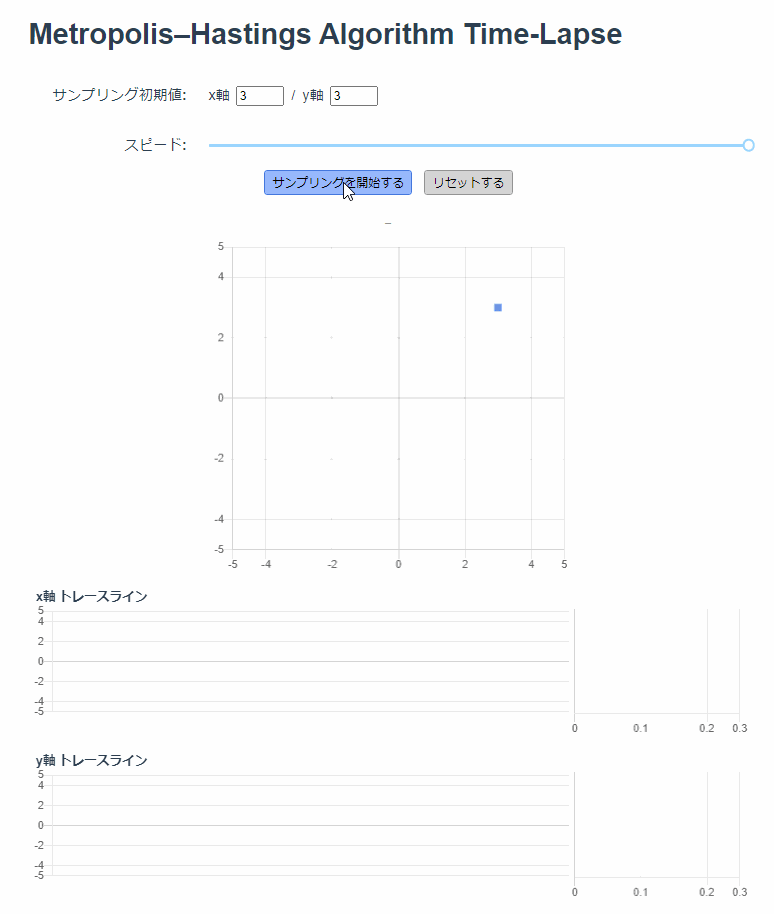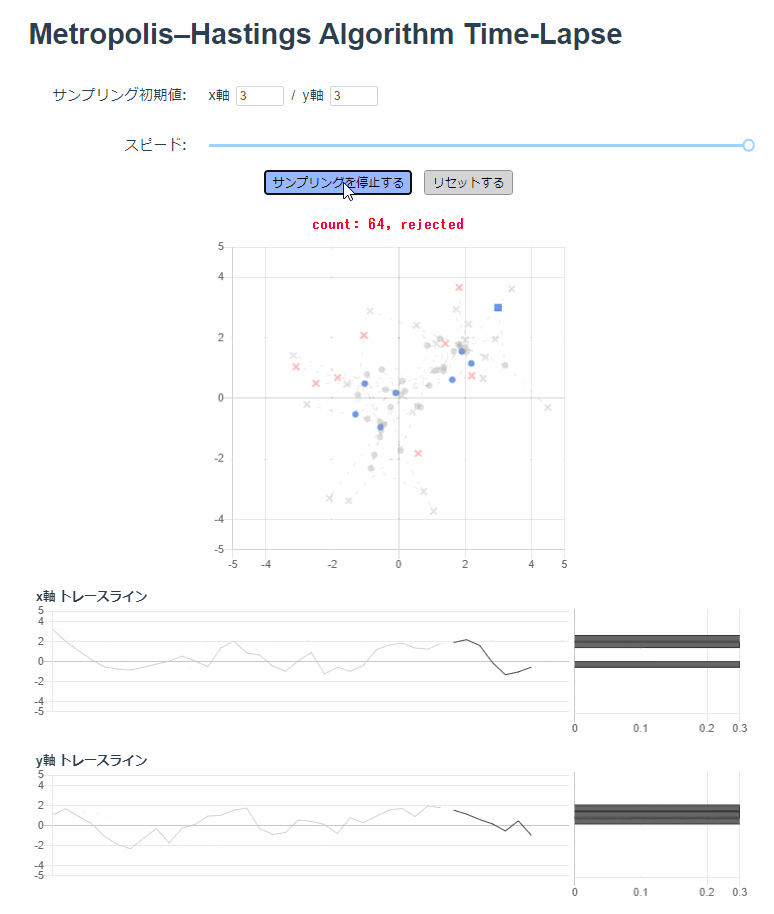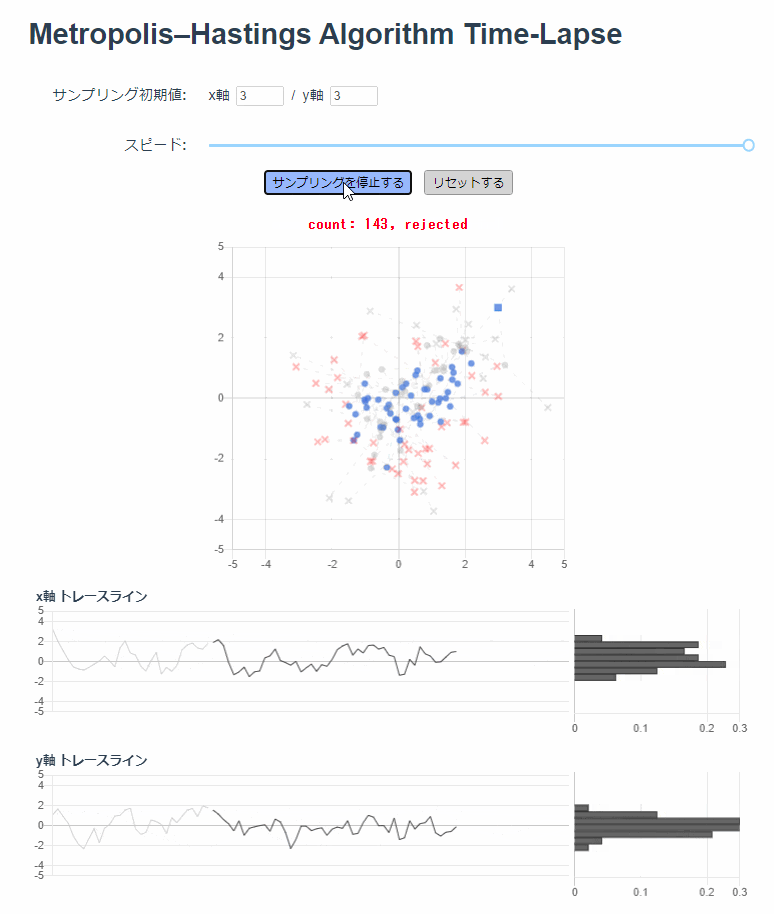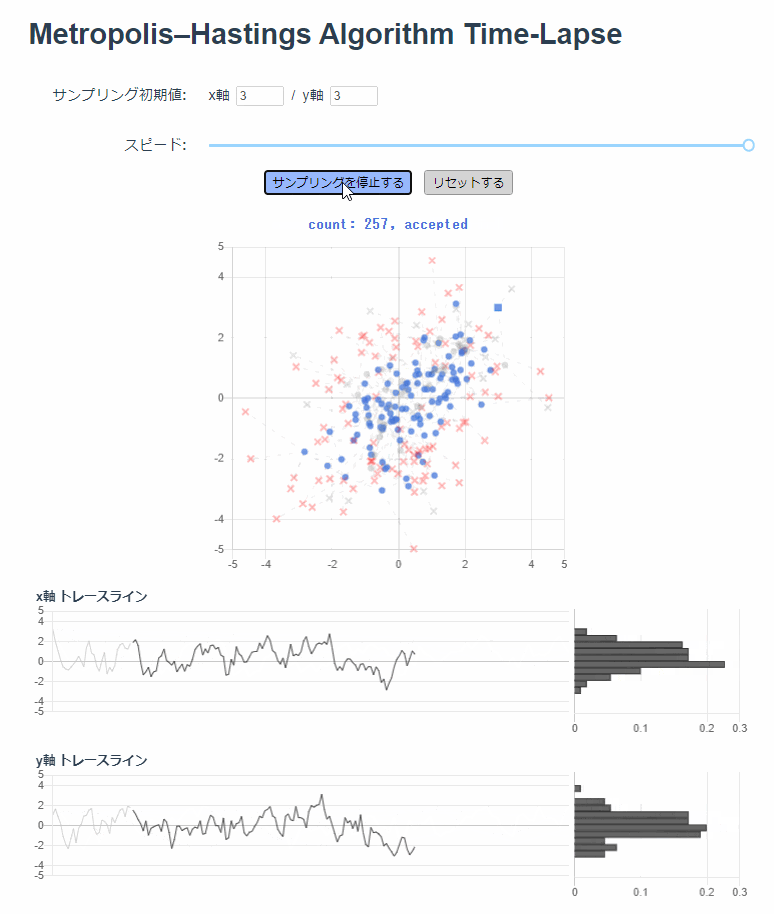
薄い灰色でプロットされているのは Burn-in 期間です。受容されたサンプルは青い丸印で、棄却されたサンプルは赤いバツ印でプロットしています。
画面の下半分には、受容されたサンプルだけ使ってトレースラインとヒストグラムを描画しています。
しばらく放置して棄却含め2000回までサンプリングしたらこんな感じになります。

本記事では実装のコードを見ながら若干の解説を加えます。
ちなみに、サンプルしたデータの表示のために Vue.js と Chart.js を使いましたが、サンプリングそのもののロジックはライブラリを使わずに(Vanilla JS で)書いています。
目標分布 (Target Distribution)
{f(x,y) = {\sqrt{1-b^2} \over 2\pi } \exp \left( -{1 \over 2} (x^2 - 2bxy + y^2) \right) \\
\propto \exp \left( -{1 \over 2} (x^2 - 2bxy + y^2) \right) \\
}
本家に倣って 2次元正規分布から正規化定数を除いたものを使います。
実際にコードに組み込むのは $\exp \left( -{1 \over 2} (x^2 - 2bxy + y^2) \right)$ の式になります。この関数は全区間で積分したときに結果が 1 になりません。その意味でこの関数は 確率密度関数ではありません 。このような目標とする確率分布に比例する関数を 目標分布のカーネル と呼びます。
目標分布のカーネルさえ知っていれば、目標分布に従う乱数を生成できるのが MCMC の強みです。
目標分布のカーネルを App.vue の中で p という関数として定義してあります。
/** 目標分布のカーネル */
p ({ x, y }: Point): number {
return Math.exp(-0.5 * (x * x - 2 * RHO * x * y + y * y))
}
ご覧の通り、 $\exp \left( -{1 \over 2} (x^2 - 2bxy + y^2) \right)$ を愚直に JavaScript で書き下しただけです。
提案分布 (Proposal Distribution)
次に提案分布です。提案分布は 詳細釣り合い条件(Detailed Balance)を満たせるものなら自由に選べますが、こちらも本家に倣って下記のようにしました。 1
/** 提案分布 */
q ({ x, y }: Point): Point {
return {
x: x + rnorm(0, SIGMA),
y: y + rnorm(0, SIGMA)
}
}
ここで rnorm () は正規分布です。今回は Box-Muller法 で実装しました。 2
/**
* @param m 平均
* @param s 標準偏差
*/
rnorm (m = 0, s = 1) {
const rnorm = Math.sqrt(-2 * Math.log(1 - Math.random())) * Math.cos(2 * Math.PI * Math.random())
return (rnorm + m) * s * s
}
実装の詳細はともかく q() は直前の点 $( x, y )$ を引数に与えると次の点の候補 $( x_{next}, y_{next} )$ を選んで返す関数になっています。
また、「自由に選べる」と書きましたが、直前の点 $( x, y )$ を中心として点対称な分布を選ぶと後々の実装がシンプルになるので便利です。今回は点対称な分布になっています。
もちろん提案分布が選んだ候補がすべて受容されるわけではありません。とあるロジックに従って次の点の候補を受容したり棄却したりします。
すべて受容されたら目標分布からのサンプリングにならないですからね。
では具体的にどのようなロジックで候補点の 受容/棄却 を決定するのでしょうか。続いて本題となるサンプリング部分の実装を見てみましょう。
サンプリング
/** サンプル取得処理 */
sample (): Sample {
// 点 current 、初回は current === undefined なので { x0, y0 } を使う
const current = this.current || { x: this.x0, y: this.y0 }
const next = this.q(current) // 提案分布を使って点 next を選ぶ
const pCurrent = this.p(current) // 点 current における目標分布の確率密度
const pNext = this.p(next) // 点 next における目標分布の確率密度
const r = pNext / pCurrent // 受容確率
// r が 1 以上ならそのまま受容する (accepted === true になる)
// r が 1 より小さいなら、確率 r で受容する
const accepted = r >= 1 || r > uniform(0, 1)
return {
count: this.count,
burnin: this.count < BURN_IN_PERIOD,
current,
next,
result: accepted ? 'accepted' : 'rejected'
}
}
流れを追ってみましょう。
まずは次の点を選ぶために点 current を変数に代入しておきます。
// 点 current 、初回は current === undefined なので { x0, y0 } を使う
const current = this.current || { x: this.x0, y: this.y0 }
ただし、初回のサンプリング時には current はありません。current の初期値は目標分布に合わせて適当に選びます。
...とはいえ多変量の確率分布の解析をするときは目標分布の大まかな形すら分からないことが多く、初期値を適当に選ぶのも容易ではありません。
ではどうするかと言うと、本当に何でもいいので適当に選びます。今回はユーザーが自由に初期値を設定できるような UI にしてみました。

提案分布 q() を使って次の点の候補になる next を取得します。
const next = this.q(current) // 提案分布を使って点 next を選ぶ
current, next を目標分布 p() に渡して、それぞれの点における確率密度を計算します。
const pCurrent = this.p(current) // 点 current における目標分布の確率密度
const pNext = this.p(next) // 点 next における目標分布の確率密度
pCurrent, pNext は確率密度なので必ず 0 以上の実数になります。とはいえ 確率ではない ので 1 以下になるとは限りません。
続いて pNext を pCurrent で割ったとある変数 r を定義します。
const r = pNext / pCurrent // 受容確率
r は確率密度同士の比ですが、こちらも 確率ではない ので 1 以下になるとは限りません。
この r を基準にして点 next を受容したり棄却したりします。具体的には、
- $ r \geqq 1 $ ならば確率 1 で点
nextを受容します。 - $ r < 1 $ ならば確率
rで点nextを受容します。
このようなロジックを採用すると詳細釣り合い条件を満たします。
r は実質的に受容確率と呼べる値になっていますね。
という訳で r を使って next を受容するか棄却するかを決めます。
// r が 1 以上ならそのまま受容する (accepted === true になる)
// r が 1 より小さいなら、確率 r で受容する
const accepted = r >= 1 || r > uniform(0, 1)
関数 uniform() は0以上1未満の一様分布から乱数を生成します。実質的に Math.random() と同等です。
最後に生成した諸々の値をまとめて return します。
return {
count: this.count,
burnin: this.count < BURN_IN_PERIOD,
current,
next,
result: accepted ? 'accepted' : 'rejected'
}
count は「何回目に生成されたサンプルなのか」を表現しています。burnin はサンプルが Burn-in 期間のものかを真理値で保持しています。
ここで見てきた関数 sample() はただ一度のサンプリングをする関数です。もちろん多数のサンプルを取得して目標分布の特徴を掴みたいわけなので sample() は繰り返し呼び出されます。
サンプリングループ
/** サンプル取得を繰り返す実行するためのループ */
loop () {
// サンプル取得
const sample = this.sample()
// 取得した sample が受容されていた場合は、次に備えて点 current を点 next で置き換える
if (sample.result === 'accepted') { this.current = sample.next }
this.samples.push(sample)
this.count += 1
// 1000 / speed ミリ秒だけ待ってから loop() を再び呼び出す
if (!this.pause) { setTimeout(this.loop, 1000 / this.speed) }
}
メトロポリス・ヘイスティング法の本質は sample() 関数の中で解説しきっているので、loop() の実装は短いです。
まずは先ほどの sample() を呼び出してサンプルを取得します。
// サンプル取得
const sample = this.sample()
取得したサンプルが受容されていれば current を sample.next で置き換えます。
逆に、サンプルが棄却されているなら何もしません。点 current は同じ値のまま、次の周回でリトライするということです。
// 取得した sample が受容されていた場合は、次に備えて点 current を点 next で置き換える
if (sample.result === 'accepted') { this.current = sample.next }
取得した sample を samples 変数にプッシュし、count 変数をインクリメントします。
本来であれば棄却されたサンプルは samples にプッシュせずに捨ててしまっていいのですが、散布図の表示に使ったり受容率の計算に使うこともできるので、今回は 受容/棄却 に依らず全件を samples に保持します。
this.samples.push(sample)
this.count += 1
最後の1行はサンプリングのスピードを調整したり、サンプリングを一時停止できるようにするためのものです。メトロポリス・ヘイスティング法のロジックとは全く関係ありません。
ともかく loop() の中で loop() を再帰的に呼び出すことでループを実現しています。
// 1000 / speed ミリ秒だけ待ってから loop() を再び呼び出す
if (!this.pause) { setTimeout(this.loop, 1000 / this.speed) }
実際に見てみる
ここまでの説明でいまいちピンと来なかった方も、実際に動いているアニメーションを見ればイメージが掴めるかも知れません。
下記に実際に動くページがあります。スピードの設定を 1 にしてゆっくりと動かしてみることをおすすめします。(宣伝)
一連のコードは JavaScript(TypeScript) で書かれていてサーバー無しでも動くので、GitHub からクローンして手元で動かしたり、適当に改変したりすると理解が深まると思いますよ。(宣伝)
私からは以上です。
補足: 提案分布の形と受容確率 r について
提案分布の項 で、
提案分布は 詳細釣り合い条件(Detailed Balance) を満たせるものなら自由に選べますが、
(...中略...)
また、「自由に選べる」と書きましたが、直前の点 (x,y) を中心として点対称な分布を選ぶと後々の実装がシンプルになるので便利です。
と書きました。
さらっと流しましたが重要なので補足しておきます。
MCMC の教科書を読むと、詳細釣り合い条件を満たすために受容確率3 $r$ は下記のような値でなければいけないと書かれています。
元の点\ p\ から次の候補点\ p_{next}\ が選ばれたとき、 \\
r = \frac{(p_{next}\ から\ p\ が選ばれる確率)(p_{next}\ における目標分布の確率密度)}{(p\ から\ p_{next}\ が選ばれる確率)(p\ における目標分布の確率密度)}
ところがコードの中では
const pCurrent = this.p(current) // 点 current における目標分布の確率密度
const pNext = this.p(next) // 点 next における目標分布の確率密度
const r = pNext / pCurrent // 受容確率
となっています。これは上記を忠実に実装したものではありません。
今回は下記のように元の点 $p$ を中心に点対称な確率分布を提案分布として採用しました。
/** 提案分布 */
q ({ x, y }: Point): Point {
return {
x: x + rnorm(0, SIGMA),
y: y + rnorm(0, SIGMA)
}
}
点対称な分布を採用することにより、常に $(p_{next}\ から\ p\ が選ばれる確率) = (p\ から\ p_{next}\ が選ばれる確率)$ が成り立ちます。
そのため $r$ の式中の $(p_{next}\ から\ p\ が選ばれる確率)/(p\ から\ p_{next}\ が選ばれる確率)$ が $1$ となり、計算上考えなくてよくなります。
これが「点対称な分布を選ぶと後々の実装がシンプルになるので便利」と書いた理由です。
逆に、点対称でない分布を提案分布とすることも可能ですが、上記のとおり詳細釣り合い条件を満たすように厳密に $r$ を計算しないといけないので面倒です。
提案分布として正規分布を使う他、適当な実数 $a$ を使って範囲が $[x - a, x + a]$ の一様分布を提案分布にしても同様に点対称な提案分布が作れるでしょう。
その場合、提案分布によって $[x - a, x + a]$ よりも外の点が選ばれることはありませんが、そのことはメトロポリス・ヘイスティング法において本質的な問題ではありません。
ただし、$[x - a, x + a]$ よりも外の点が選ばれることがないということは元の点 $p$ と次の候補点 $p_{next}$ が距離 $a$ くらいしか離れていないということになります。
$a$ をあまり近くしすぎるとサンプル列の前後の項の相関が大きくなりすぎるため、適当な実数 $a$ をどのように選定するか悩ましいところです。
同様の問題は提案分布として分散の小さな正規分布を使ったときにも起こります。
(とはいえ、一連のサンプリングによって得られたサンプル列を適当にシャッフルしてしまえば前後の項の相関は消えるので、あまり深く考えなくてもいいのかも。※サンプルサイズを充分に大きくする前提なら)
参考記事・参考書籍
スペシャルサンクス
-
【統計学】マルコフ連鎖モンテカルロ法(MCMC)によるサンプリングをアニメーションで解説してみる。
同じ例が Python 実装で解説してあります。この記事を JavsScript(TypeScript) で書き起こしたのが本記事です -
データ解析のための統計モデリング入門 - 一般化線形モデル・階層ベイズモデル・MCMC
ベイズの気持ち・MCMC のうれしさを理解するのに最良の入門書。所謂、緑本。ただし、メトロポリス・ヘイスティング法の実装については書かれていない -
基礎からのベイズ統計学 ハミルトニアンモンテカルロ法による実践的入門
読みやすく数式を添えて正確&網羅的に解説が加えてあるので、この本を理解すればメトロポリス・ヘイスティング法やハミルトニアンモンテカルロ法を実装に落とすことは可能だと思います
この記事を書くために4往復くらい読んでやっと理解したけど...