はじめに
Watson Studio CloudのJupyter Notebookジョブ実行。日経平均株価を毎日取得してDb2 on Cloudに保管 に掲載されている通り、Watson Studio Cloud には Jupyter Notebook をそのまま Job として実行できる機能があります。
また、SPSS Modeler Flowでバッチ処理をしよう に記載されている通り、SPSS Modeler Flow で予測モデルを作成し、 Watson Machine Learning のデプロイメント・スペースにプロモートして作成したバッチ処理をそのまま Job として実行できる機能もあります。
一方で、スケジュールに祝日カレンダーを含めたい、成功・警告・失敗時を運用管理用のメールなどに通知したいといった様々な要件を満たすために機能拡張が必要になるケースがあるかと思います。
IBM Workload Scheduler、Apache Airflow、JP1 などの外部の Job scheduler から Watson Studio Cloud のこれらの Job を実行できれば、上記の課題を解決できると思います。
そこで、Watson Data API を使用して Python でサンプルコードを実装してみました。
前提
- 今回は Watson Studio CloudのJupyter Notebookジョブ実行。日経平均株価を毎日取得してDb2 on Cloudに保管 を一通り実行し、Watson Studio Cloud に Job を登録済みであること。
- Python の実行環境が準備済みであること。
- 今回は Python 3.10 を使用して動作させています。
- Job scheduler の代替として Python の schedule で定期実行します。
作業手順の流れ
- IBM Cloud の API キーを取得
- Watson Data API を使用して Watson Studio Cloud のJob を起動
- Job を schedule に登録して定期実行
作業手順1. IBM Cloud の API キーを取得
- IBM Cloud にログインします。
- API キー の画面を表示します。
-
IBM Cloud API キーの作成ボタンを押下します。

-
名前と説明に任意の文字を反映し、作成ボタンを押下します。

- ポップアップにて
ダウンロードリンクを押下します。

- ⚠️注意 API キーは悪用されると第三者にご自身の IBM Cloud 環境の操作をされてしまう恐れがあるため、厳重に管理してください。
- ポップアップを閉じます。
作業手順2. Watson Data API を使用して Watson Studio Cloud の Job を起動
- Python 仮想環境の作成します。
python3 -m venv venvsource venv/bin/activate - 必要な python ライブラリーをインストールします。
pip install requests schedule - 以下、サンプルコード の関数
job()の変数をご自身の環境に合わせて修正することで Job を実行することができます。- api_key: 1. IBM Cloud の API キーを取得 の API キーを設定
- job_name: 今回は
nikkei3を設定 - project_id: 以下 URL の
projects/と/jobsの間の文字列を設定

api_key = "<your api key>" job_name = "<your job name>" project_id = "<your project id>" - 関数
job()では以下の処理を行なっています。- ベアラートークン生成 (関数
generate_bearer_token()) - Job ID 取得 (関数
get_job_id()) - Job 実行 (関数
run_job()) - Job ステータス確認 (関数
check_job_status())
- ベアラートークン生成 (関数
作業手順3. Job を schedule に登録して定期実行
- 今回は Job scheduler の代替として Python の schedule で1分毎に Job を実行します。
- 以下のコードが該当箇所になります。
schedule.every(1).minutes.do(job) while True: schedule.run_pending() time.sleep(1) -
サンプルコード のスクリプトを実行します。
python3 path/to/main.py - 実行結果は以下の通りになります。
- なお、IBM Cloud の画面操作で該当 Job の実行をキャンセルした場合、
Completedの部分がCanceledになります。
INFO:__main__:Job is working... INFO:__main__:Bearer token has been generated. INFO:__main__:Job ID is [9f4b81f1-1362-43d4-86bb-78c3418f7364]. INFO:__main__:Run ID is [53bc2716-dedc-419b-ae6d-e9061fe48aab]. INFO:__main__:Job status is [Starting]. INFO:__main__:Job status is [Starting]. INFO:__main__:Job status is [Starting]. INFO:__main__:Job status is [Starting]. INFO:__main__:Job status is [Running]. INFO:__main__:Job status is [Running]. INFO:__main__:Job status is [Running]. INFO:__main__:Job status is [Completed]. INFO:__main__:Completed. (切り返し実行) - なお、IBM Cloud の画面操作で該当 Job の実行をキャンセルした場合、
- 以下の操作で Job 実行履歴の画面を確認をします。
-
ナビゲーション・メニューを押下 -
プロジェクト > すべてのプロジェクトの表示リンクを押下
-
<ご自身のプロジェクト名>リンクを押下
-
ジョブタブを押下 -
<ご自身のジョブ名>リンクを押下
-
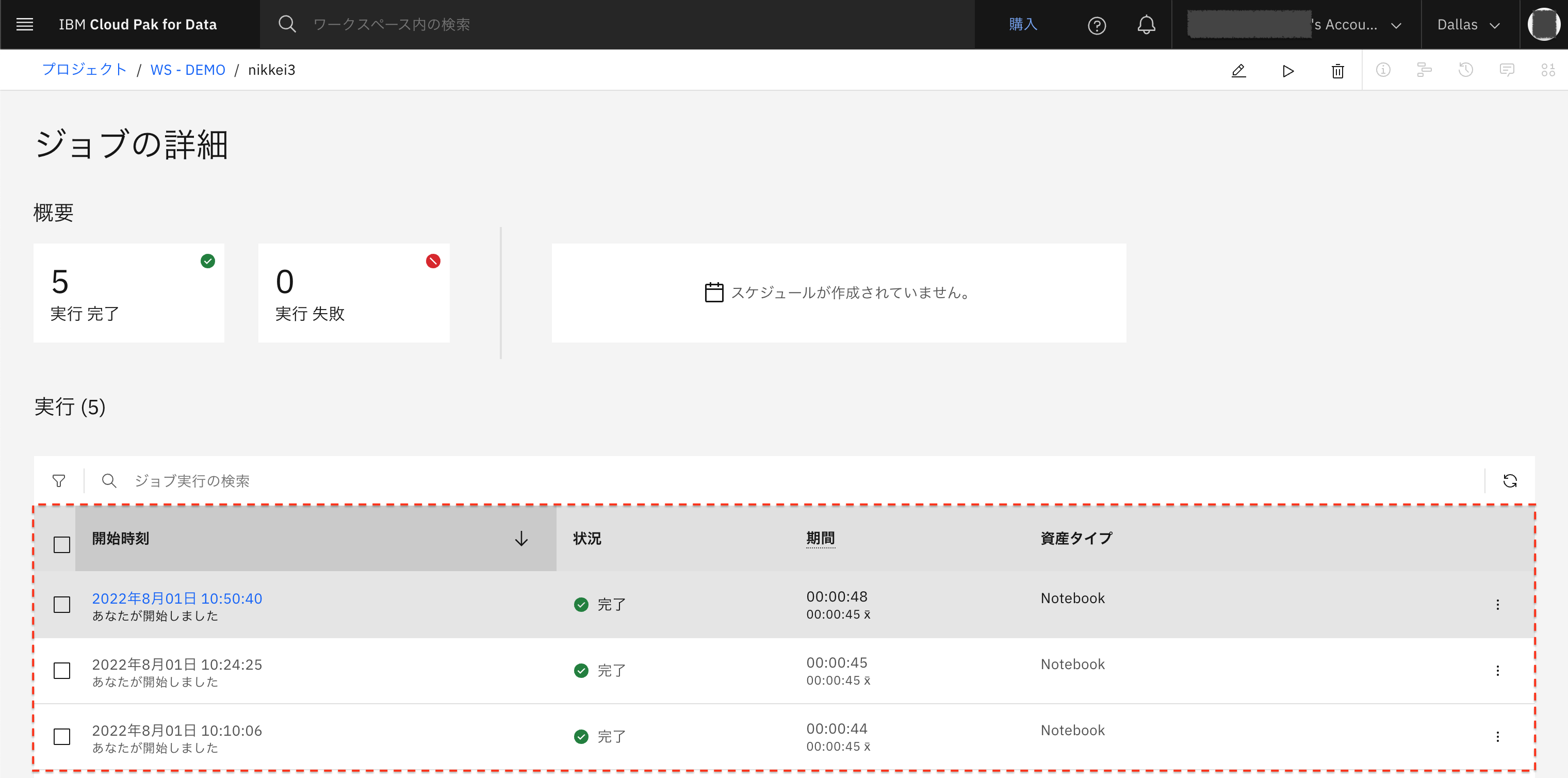
ジョブの詳細にて実行履歴を表示
-
終わりに
今回は Watson Data API にフォーカスしましたが、API & SDK リファレンス・ライブラリー に掲載されている通り、他の API や Java、Node.js、Python、.NET の SDK を使用して開発することができます。なお、現時点で SDK がない API があるのでご留意ください。
参考
- API & SDK リファレンス・ライブラリー
- How to Access Watson Studio Assets by API
- schedule — schedule 1.1.0 documentation
お断り
このサイトの掲載内容は私自身の見解であり、必ずしも所属会社の立場、戦略、意見を代表するものではありません。 記事は執筆時点の情報を元に書いているため、必ずしも最新情報であるとはかぎりません。 記事の内容の正確性には責任を負いません。自己責任で実行してください。