概要
今更ですが、ちょっとTensorBoardを動かしてみました。その際に、TensorBoardの最も基本的な使い方というページが非常に参考になりました。サンプルが非常にシンプルで、簡単に試してみることができるのがもっとも良い点でした。
ただ、コメントにもあるようにバージョンが違うと色々と違いがあるようで、最新環境で動かしてみたという内容です。
ですので、大元のページをご覧になった上で、こちらも参考に見ていただければと思いますが、基本は大元のページのコピペに過ぎないので、こちらを参考にする必要もないかもしれません。
再掲:TensorBoardの最も基本的な使い方
環境
$ pip list | grep tens
tensorboard 1.14.0
tensorflow 1.14.0
tensorflow-estimator 1.14.0
と、
tensorboard 2.0.1
tensorflow 2.0.0
tensorflow-estimator 2.0.1
v1系 (1.14)
# 必要なライブラリのインポート
import tensorflow as tf
import numpy as np
# 変数の定義
dim = 5
LOGDIR = './logs'
x = tf.compat.v1.placeholder(tf.float32, [None, dim + 1], name='X')
w = tf.Variable(tf.zeros([dim+1,1]), name='weight')
y = tf.matmul(x,w, name='Y')
t = tf.compat.v1.placeholder(tf.float32, [None, 1], name='TEST')
sess = tf.compat.v1.Session()
# 損失関数と学習メソッドの定義
loss = tf.reduce_sum(tf.square(y - t))
train_step = tf.compat.v1.train.AdamOptimizer().minimize(loss)
# TensorBoardで追跡する変数を定義
with tf.name_scope('summary'):
# 戻りを利用する
loss_summary = tf.compat.v1.summary.scalar('loss', loss)
if tf.io.gfile.exists(LOGDIR):
tf.io.gfile.rmtree(LOGDIR) # ./logdirが存在する場合削除
writer = tf.compat.v1.summary.FileWriter(LOGDIR, sess.graph)
# セッションの初期化と入力データの準備
sess.run(tf.compat.v1.global_variables_initializer())
train_t = np.array([5.2, 5.7, 8.6, 14.9, 18.2, 20.4,25.5, 26.4, 22.8, 17.5, 11.1, 6.6])
train_t = train_t.reshape([12,1])
train_x = np.zeros([12, dim+1])
for row, month in enumerate(range(1, 13)):
for col, n in enumerate(range(0, dim+1)):
train_x[row][col] = month**n
# 学習
i = 0
for _ in range(100000):
i += 1
sess.run(train_step, feed_dict={x: train_x, t: train_t})
if i % 10000 == 0:
# 上記で取得したloss_summeryを渡す
s, loss_val = sess.run([loss_summary, loss] , feed_dict={x: train_x, t: train_t})
print('Step: %d, Loss: %f' % (i, loss_val))
# これによりSCALARSが出力される
writer.add_summary(s, global_step=i)
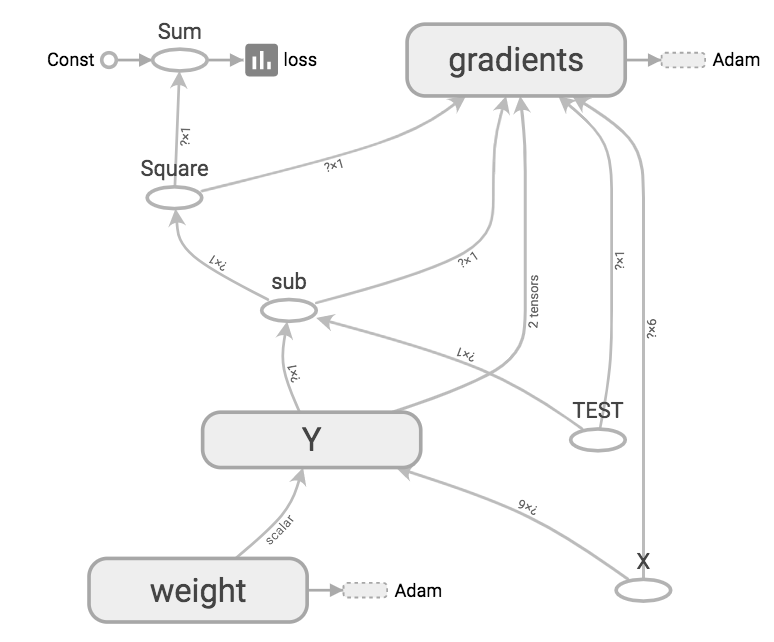
- GRAPHSの画像

nameで名前をつけておくと、わかりやすくなります。
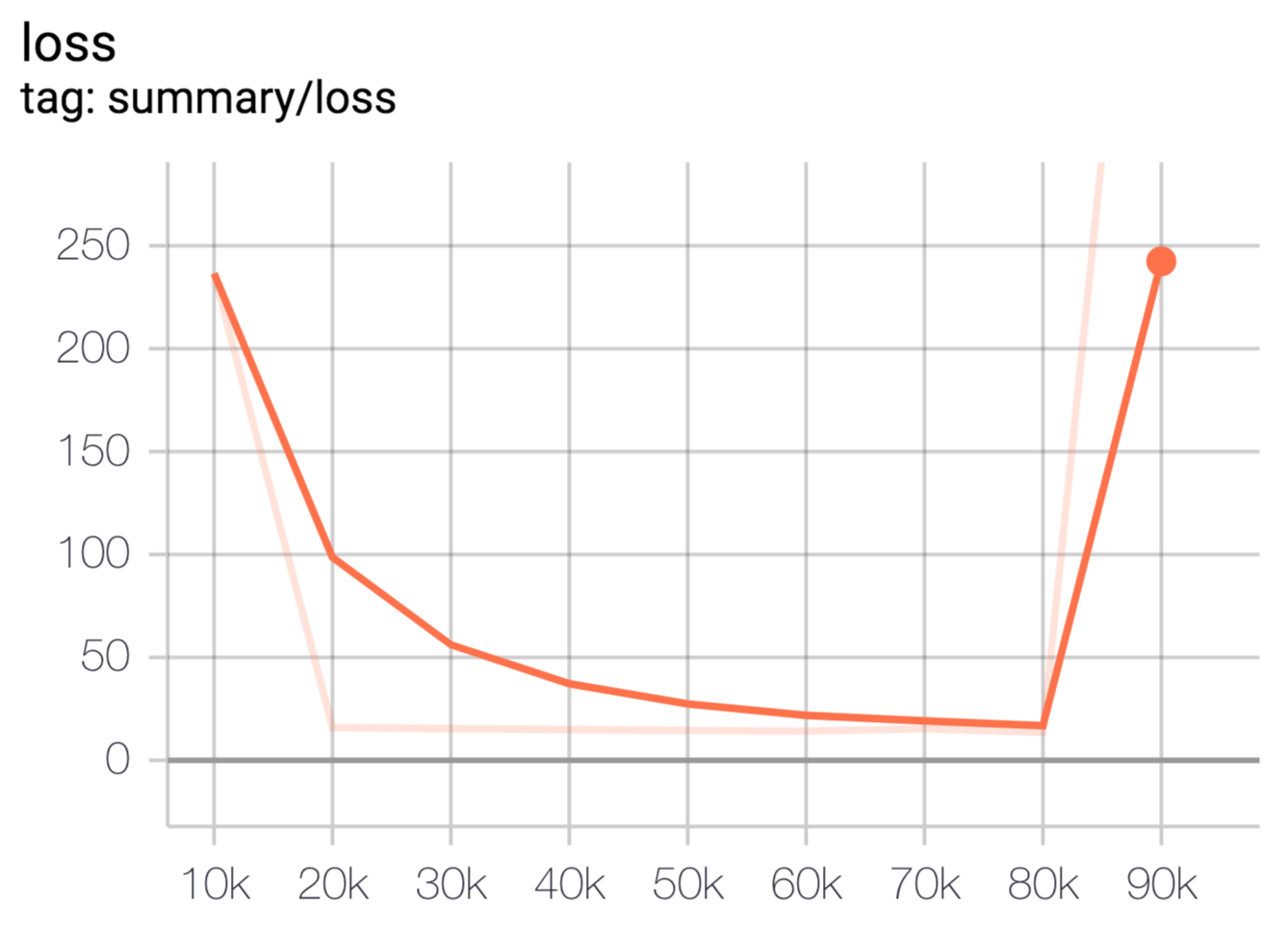
- SCALARSのグラフ
ちなみに、以下のような感じにすると、既存のコードをあまり変更しなくても済むっぽいです。
tensorflowのドキュメントに記載があるから、これが適切な記述方法かな。
import tensorflow.compat.v1 as tf
v2系 (2.00)
というわけで、こちらは書き方を変えてみる。
また、v2のポイントとしては、Variableの書き方が変わった点でしょうか。
あと、良くわからないのが、EagerTensorsの部分でしょうか。とりあえず、sessionをwithで指定して見た。
# 必要なライブラリのインポート
import tensorflow.compat.v1 as tf
import numpy as np
# 変数の定義
dim = 5
LOGDIR = './logs'
with tf.Session() as sess:
x = tf.placeholder(tf.float32, [None, dim + 1], name='X')
with tf.variable_scope('weight'):
w = tf.get_variable("weight", shape=[dim+1,1], initializer=tf.zeros_initializer())
y = tf.matmul(x,w, name='Y')
t = tf.placeholder(tf.float32, [None, 1], name='TEST')
# 損失関数と学習メソッドの定義
loss = tf.reduce_sum(tf.square(y - t))
train_step = tf.train.AdamOptimizer().minimize(loss)
# TensorBoardで追跡する変数を定義
with tf.name_scope('summary'):
loss_summary = tf.summary.scalar('loss', loss)
if tf.io.gfile.exists(LOGDIR):
tf.io.gfile.rmtree(LOGDIR) # ./logdirが存在する場合削除
writer = tf.summary.FileWriter(LOGDIR, sess.graph)
# セッションの初期化と入力データの準備
sess.run(tf.global_variables_initializer())
train_t = np.array([5.2, 5.7, 8.6, 14.9, 18.2, 20.4,25.5, 26.4, 22.8, 17.5, 11.1, 6.6])
train_t = train_t.reshape([12,1])
train_x = np.zeros([12, dim+1])
for row, month in enumerate(range(1, 13)):
for col, n in enumerate(range(0, dim+1)):
train_x[row][col] = month**n
# 学習
i = 0
for _ in range(100000):
i += 1
sess.run(train_step, feed_dict={x: train_x, t: train_t})
if i % 10000 == 0:
s, loss_val = sess.run([loss_summary, loss] , feed_dict={x: train_x, t: train_t})
print('Step: %d, Loss: %f' % (i, loss_val))
writer.add_summary(s, global_step=i)
- SCALARSのグラフ
Yの部分が違っているようです。