概要
OpenClawをきっかけに、自律型エージェントが再び注目を集めている。かつてAutoGPTなどが登場した際には、「ユーザーの代わりにタスクを実行する自律エージェント」というコンセプトが話題になった。しかし当時は、
- 挙動が予測しづらい
- トークン消費が制御できない
- 実用的な成果に繋がりにくい
といった問題により、実運用には適さないケースが多かった。
その結果、現在の主流は「ユーザー主導で制御可能なエージェント」へとシフトしている。
一方で、LLMの性能向上とともに、再び自律エージェントを実用レベルで扱おうとする動きが出てきている。その代表例の一つが OpenClaw である。
ただし、自律性を高めるほど「安全性・制御性」という新たな課題が発生する。この問題に対処するため、現在は各プロジェクトごとに異なるアプローチでサンドボックス化・ポリシー制御が実装されている。
本記事では以下の3つを比較する:
本質的な違いは「どの粒度でエージェントを制御するか」にある。
- 会話単位(NanoClaw)
- エージェント単位(OpenShell)
- ツール単位(IronClaw)
NanoClaw とは?
NanoClawは「分離を最小構成で実現することで安全性を担保する」設計である。
OpenClaw との違い
OpenClaw は何千ものソースファイルと多数の依存関係を持つモノリシックなフレームワークであるのに対し、NanoClaw は約15個のソースファイル・シングルの Node.js プロセス・OS レベルのコンテナ分離という真逆のアプローチを取っています。
| 項目 | NanoClaw | OpenClaw |
|---|---|---|
| ソースファイル | 53 | 3,680 |
| コード行数 | 約11,300 | 434,453 |
| 依存関係 | 10未満 | 70以上 |
| 理解にかかる時間 | 8分 | 1〜2週間 |
「コードが読めるくらい小さい」こと自体もセキュリティの一部として設計されているのが NanoClaw の大きな特徴です。
主な機能
- メッセージアプリ対応:WhatsApp・Telegram などに対応。スマホから普段使いのアプリ経由でAIエージェントに話しかけられる
- コンテナ分離:Apple Container(macOS)または Docker 上でエージェントが動作し、明示的にマウントされたものだけにアクセス可能
- エージェントスウォーム:複数の専門エージェントがチームを組んで複雑なタスクに取り組む機能
- スキルシステム:Gmail・Telegram などの機能をスキルとして追加拡張可能
- スケジュールタスク:朝のブリーフィングや週次レビューなど定期実行ジョブ
セッション管理の詳細
SPEC.md を元にSystem Diagramを示す。
基本的な仕組み
各グループ(会話単位)は、独自のコンテナ・ファイルシステム・IPCネームスペース・Claude セッションを持ちます。グループ同士はお互いのデータにアクセスできません。
コンテナ実装は基本的に Docker(Linux コンテナ)を前提としており、macOS でも同様のモデルで動作する。
つまり、WhatsApp のグループ A と グループ B がそれぞれ別のコンテナで動くため、一方が他方のデータを読めない構造になっています。
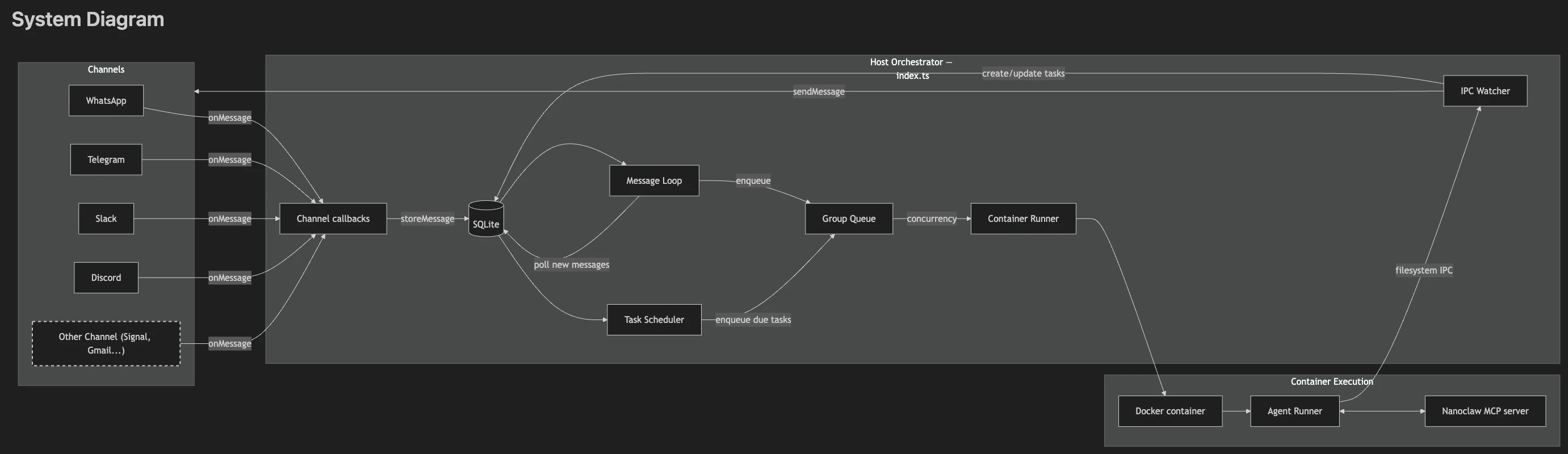
セッションは group_folder をキーに管理され、同一グループでは会話が継続される。
シングルの Node.js プロセスで動作し、メッセージが届くと SQLite に保存・重複排除され、グループごとの FIFO キューに入り、コンテナ(Claude Agent SDK)で処理されてレスポンスが返ってきます。
sandboxについて整理
NanoClaw/NemoClaw/IronClaw の大まかな違い
- NanoClaw は「グループ(会話)ごとにコンテナを立てる」シンプルな構造で、ファイルシステム分離が主眼です。ネットワークは制限されませんが、その分軽量で理解しやすい。
- NemoClaw(OpenShell) は「コンテナ + YAML ポリシーによる通信制御」が特徴で、ゲートウェイがすべての外部通信をインターセプトします。ネットワーク制御の細粒度では3つの中で最も強力ですが、Docker の中に K3s という重さがあります。
- IronClaw は他の2つとはまったく異なる思想で、ツール(関数)単位で WebAssembly サンドボックスに閉じ込め、クレデンシャルはネットワーク境界でのみ注入するため、LLM 自体はシークレットの値を知らないという設計です。さらにTEE(Trusted Execution Environment)上で動作し、暗号化された状態でエージェントが実行されます。
最大の違いは分離の粒度 で、NanoClaw がグループ単位、OpenShell がエージェント単位なのに対して、IronClaw はツール(関数)呼び出しの単位で分離しています。これにより、エージェント自体が悪意あるプロンプトインジェクションを受けても、個々のツールが取れるアクションが厳しく制限されます。
OpenShell(NemoClaw の基盤)の実態
まず重要な点として、OpenShell はコントロールプレーン(ゲートウェイ・サンドボックス・ポリシーエンジン・プライバシールーター)のすべてを、単一の Docker コンテナ内で動く K3s Kubernetes クラスターとして実装しています。別途 K8s のインストールは不要です。
つまり、カーネルレベル分離(Landlock / seccomp / netns)の上に、K3s クラスターが重なる多層構造になっている。
NanoClaw vs OpenShell およびironclawのサンドボックス比較
| 項目 | NanoClaw | OpenShell(NemoClaw) | ironclaw |
|---|---|---|---|
| 依存関係 | Docker 必須 | Docker 必須。gateway を Docker で起動し、その中で K3s ベースのクラスタを構成 | Docker は一部機能で使用。加えて Wasmtime ベースの WASM sandbox を内蔵 |
| 内部構造 | シンプルな Docker/Linux コンテナ。グループ単位で bind mount を分離 | gateway コンテナ内に K3s 制御面があり、sandbox は pod として生成・管理 | 本体アプリ + Docker job sandbox + WASM sandbox の併用構成 |
| ポリシー管理 | 宣言的 YAML ポリシーはなし。ただし mount allowlist、read-only mount、.env マスク、IPC 分離あり |
宣言的 YAML ポリシーで filesystem_policy / landlock / process / network_policies を管理 |
OpenShell 型の YAML ポリシーはなし。WASM capabilities/allowlist と Docker 側の設定・検証で制御 |
| ネットワーク制御 | 汎用的な egress 制御はほぼなし。Anthropic 向け通信のみ credential proxy 経由 | HTTP メソッド・パス単位まで制御可能。network_policies はホットリロード可 |
WASM は host/path/method allowlist あり。Docker job sandbox 自体には細粒度 egress 制御は見当たらない |
| 推論のルーティング | Anthropic API に直接接続ではなく、まずホスト上の credential proxy に流してから upstream へ転送 |
inference.local を managed route として gateway が解決・中継 |
LLM_BACKEND と provider 設定で各推論先を切替。OpenShell のような gateway 集約型ではない |
| 実装言語 | TypeScript(Node.js) | 主体は Rust、補助に Python / Shell | 主体は Rust、補助に JS / Python / Shell |
| コードの大きさ | コア実装は約 1.1 万行 / 50 ファイル | 少なくとも約 12.4 万行 / 427 ファイル | 少なくとも約 28.2 万行 / 693 ファイル |
| 特徴の要約 | 軽量で分かりやすいコンテナ分離 | 強いポリシー制御と gateway 中心の sandbox 基盤 | 拡張性重視。Docker sandbox と WASM sandbox を両立 |
LLMの差し替えやすさ
| プロダクト | 差し替えやすさ | どこまで簡単か |
|---|---|---|
| NanoClaw | 中 | Anthropic互換APIなら簡単。非互換APIへは実質つらい |
| OpenShell | 高 | provider と model を gateway 設定で切替可能 |
| ironclaw | 高 | env / settings で多数の LLM backend を切替可能 |
OpenShell の保護の4層
OpenShell はファイルシステム・ネットワーク・プロセス・推論(Inference)の4つのポリシードメインで多層防御を行っています。静的なもの(ファイルシステム・プロセス)はサンドボックス作成時にロックされ、動的なもの(ネットワーク・推論)は実行中のサンドボックスにホットリロードで適用可能です。
K3s とは何か
K3s は Kubernetes(コンテナ管理システム)の軽量版です。通常の Kubernetes は非常に重いシステムですが、K3s はその機能を最小限に絞って単一バイナリで動く形にしたものです。
OpenShell は、ゲートウェイ・サンドボックス・ポリシーエンジン・プライバシールーターのすべてを、単一の Docker コンテナ内で動く K3s クラスターとして実装しています。
つまり構造はこうなっています:
あなたのマシン
└── Docker コンテナ(1つ)
└── K3s(軽量 Kubernetes)
├── ゲートウェイ(制御プレーン)
├── サンドボックス(エージェントが動く場所)
├── ポリシーエンジン
└── プライバシールーター
K3s を使う理由は、各コンポーネントの起動・停止・ネットワーク管理をまとめて Kubernetes に任せられるからです。「Docker の中で K3s」という入れ子構造は一見複雑ですが、ユーザーには K3s の存在を意識させず、openshell コマンド1つで全部面倒を見てくれます。
4層防御がどう機能するか
OpenShell はファイルシステム・ネットワーク・プロセス・推論(Inference)の4層で多層防御を行っており、静的な層(ファイルシステム・プロセス)はサンドボックス作成時にロックされ、動的な層(ネットワーク・推論)は実行中にホットリロード可能です。
それぞれの層が何を守っているか:
① ファイルシステム層(作成時にロック)
- エージェントが読み書きできるパスを制限
-
/sandboxと/tmpのみ書き込み可能、それ以外は読み取り専用
② ネットワーク層(ホットリロード可)
- 外部への通信をすべてゲートウェイが仲介
- 未許可のホストへの接続はブロックされ、HTTP メソッドとパスのレベルで制御されます。たとえば GitHub API への GET は許可するが POST は拒否、という細粒度の制御が YAML で書けます
③ プロセス層(作成時にロック)
- 権限昇格や危険なシステムコールをブロック(seccomp によるカーネルレベル制限)
④ 推論(Inference)層(ホットリロード可)
- エージェントからの推論リクエストはサンドボックスを直接出ることなく、ゲートウェイがすべてのリクエストをインターセプトして設定済みのプロバイダーへルーティングします。
- 資格情報(API キー等)はサンドボックルのファイルシステムには置かれず、実行時に環境変数として注入されます
ネットワーク層の具体例
サンドボックスはデフォルトで最小限の外部アクセス権しか持ちません。ポリシーを適用することで段階的に許可を追加でき、実行中のサンドボックスを再起動せずにリロードできます。
README のデモがわかりやすいので、流れを示すと:
# サンドボックス起動直後 → 外部アクセス全てブロック
$ curl https://api.github.com/zen
→ 403(プロキシに遮断される)
# ホスト側でポリシーを適用(再起動不要)
$ openshell policy set demo --policy policy.yaml
# GETは通る、POSTは弾く
$ curl https://api.github.com/zen
→ 成功
$ curl -X POST https://api.github.com/...
→ 403(ポリシーに POST が許可されていない)
Claude Code等xxClaw以外のsandbox化
OpenShellの特徴の一つとして、既存エージェント(Claude Codeなど)もサンドボックス内で実行できる点がある。
OpenShellではREADMEに記載されており、明確に対応している
Claude Code例
- Claude Code 用のsandbox作成
Claude Code が sandbox 内で起動する
この時点で、Claude Code 自身が使うファイルアクセスや外向き通信は、sandbox の filesystem / network policy 配下に入ります。
$ openshell sandbox create -- claude - Claude Code への依頼例
Claude Code は内部で外部ツール利用
(git,gh,curl,npm / pip,MCP サーバー経由の各種 API 呼び出しなど)
text GitHub の issue を見て、修正して、branch を push して PR を作って - OpenShellが実行・通信を制御
たとえば GitHub だけ許可した policy にしておけば、Claude Code が api.github.com や GitHub git endpoint には行けても、関係ない外部サイトには出られないよう制御できます
| 観点 | NanoClaw | ironclaw |
|---|---|---|
| 内側 Docker sandbox | ある | ある |
| 外側 micro VM / Docker Sandbox との二重化 | 明示的な手順あり | 原理上は可能そうだが明示手順なし |
| DinD / nested Docker 前提の記述 | あり | 明示的には弱い |
| 実運用の確実性 | 比較的高い | 要検証・要調整 |
GPU サポートの比較
NanoClaw:GPU は関係なし
NanoClaw は推論を Anthropic の API に完全委譲する設計のため、ローカルの CPU/RAM ではなくネットワーク遅延がボトルネックになります。サンドボックス(Linux コンテナ)への GPU パススルーは設計上想定されておらず、ローカル GPU を使う仕組みはありません。
もちろん、LLMの差し替えが限定的ながら可能ではあるので、ローカルLLMに差し替えることは実現可能で、それを動かすためにGPUを利用するように構成しても良いと思うが、ここでは深く触れない。
NemoClaw(OpenShell):GPU サポートあり、ただし NVIDIA 限定
--gpu フラグを付けてサンドボックスを作成するとホストの GPU をサンドボックスに渡せます。ただし NVIDIA ドライバーと NVIDIA Container Toolkit がホストに必要で、デフォルトの base イメージには GPU ドライバーが含まれないためカスタムイメージが別途必要です。
動作環境としては、クラウド・オンプレミス・RTX PC・DGX Spark で動作します。
推論については、コンシューマー向け RTX GPU では Nemotron 3 Nano 4B がローカル動作し、大規模な Nemotron 3 Super 120B は NVIDIA クラウド(build.nvidia.com)経由です。ただしローカル推論オプション(NIM、Ollama、vLLM)は現時点では実験的扱いで、NEMOCLAW_EXPERIMENTAL=1 が必要です。
AMD・Apple Silicon・CPU のみの環境ではプライバシールーターのローカルモデル機能は使えません。
IronClaw:GPU は「推論クラウド経由」で独自のアプローチ
サンドボックス(WASM)自体は CPU ベースで動作するため、GPU を直接サンドボックス内で使う仕組みはありません。ただし GPU を活用する経路が2つあります。
① ローカル GPU(Ollama 経由):Ollama を含む複数の LLM バックエンドに対応しており、ホストの GPU でローカルモデルを動かして推論に使えます。
② Confidential GPU Marketplace(クラウド):IronClaw と同時に発表された独自インフラで、TEE で保護された GPU 上でジョブを実行し、データはメモリ内で暗号化されたまま処理されます。ホスト OS・GPU オペレーター・NEAR AI 自身さえも暗号学的にアクセスを遮断されており、すべてのリクエストは30秒以内にハードウェア署名付きの証明書を返します。
GPUサポートまとめ
| NanoClaw | NemoClaw | IronClaw | |
|---|---|---|---|
| サンドボックス内 GPU | なし | あり(--gpu) |
なし(WASM は CPU のみ) |
| ローカル GPU 推論 | なし | あり(RTX、実験的) | あり(Ollama 経由) |
| クラウド GPU | Anthropic API | NVIDIA クラウド | NEAR Confidential GPU Marketplace(TEE 付き) |
| GPU ベンダー縛り | なし | NVIDIA 必須 | なし |
| GPU の機密性保証 | なし | なし | TEE で暗号学的に保証 |
NemoClaw は「GPU をサンドボックスに渡せる」という点でインフラ的な GPU 統合が最も直接的ですが NVIDIA 限定。IronClaw は GPU を直接サンドボックス内で使えないものの、TEE 付きの分散 GPU マーケットプレイスという独自の機密性保証アプローチを持っています。NanoClaw は GPU を一切考慮していない設計です。
まとめ
自律エージェントの設計における本質は、「どこに制御境界を置くか」にある。
- NanoClaw:会話単位で分離(シンプル・理解しやすい)
- OpenShell:エージェント単位で制御(ポリシー駆動・高い制御性)
- IronClaw:ツール単位で制限(最も強い安全モデル)
※ OpenShellはエージェント単位としているが、ポリシーを細かく記載すれば、もう少し細かな単位での制御も可能。
この違いは、そのまま「どのように安全性を担保するか」という設計方針の違いに対応している。
- NanoClawは「理解可能な範囲で安全を担保する」アプローチ
- OpenShellは「ポリシーで制御する」アプローチ
- IronClawは「能力そのものを制限する」アプローチ
自律性とは、制御を放棄することではなく、どこまでを管理し、どこからを委ねるかを設計する問題である。
LLMの性能が向上するほど、自律性と安全性のトレードオフはより顕在化する。
そのため今後は、「より賢いエージェント」を考えるだけでなく、
「どのように制御されたエージェントを設計するか」 が重要になる。