背景
forループを使って複数のヒストグラムを重ね合わせて表示する場合、bin幅を指定しないとデータごとに幅が異なり比較しづらかったので、bin幅を統一して表示する方法を調べました。
※自分用のメモなので読みづらかったらすみません
import・使ったデータセット
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
wine = load_wine()
df_wine = pd.DataFrame(data=wine.data, columns=wine.feature_names)
df_wine['target'] = wine.target
scikit-learnのワインデータセットを使います。
targetという列にはワインの種類を表すラベルを入れました。
方法
plt.hist()の引数のbinsにリストを渡すと、リストで指定された値を区間の区切りとしたヒストグラムが描出される。
(bins=[0,1,2,3,4]とすると、0~1, 1~2, 2~3, 3~4の4つの区間の棒が描出される)
これを利用して、np.linspace(最小値, 最大値, 区切りたい数)でリストを作り、各ラベル用のplt.hist()の引数として渡すことで、共通のbinを指定する。
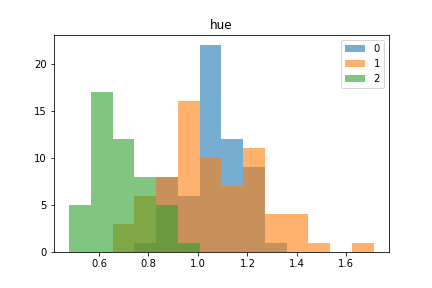
↓bin幅調整なし
feature_name = 'hue'
target_names = df_wine['target'].unique()
for target in target_names:
plt.hist(df_wine[df_wine.target == target][feature_name], alpha=0.6, label=target)
plt.title(feature_name)
plt.legend()
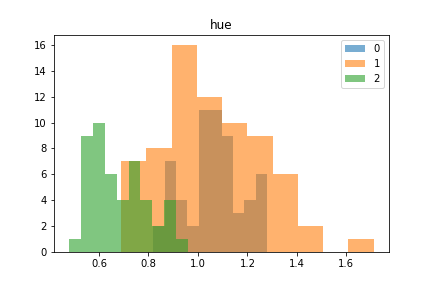
↓bin幅調整あり
feature_name = 'hue'
target_names = df_wine['target'].unique()
# 最大値と最小値の間をn_bin等分した幅でヒストグラムの棒を表示するように設定(各targetのbin幅を統一する)
n_bin = 15
x_max = df_wine[feature_name].max()
x_min = df_wine[feature_name].min()
bins = np.linspace(x_min, x_max, n_bin)
for target in target_names:
plt.hist(df_wine[df_wine.target == target][feature_name], bins=bins, alpha=0.6, label=target)
plt.title(feature_name)
plt.legend()