はじめに
概要
2つのAutonomous Database(ADW/ATP)間でデータを移行する方法について記載します。
- ATP : Autonomous Transaction Processing
- ADW : Autonomous Data Warehouse
Clone機能やDB Linkでの連携といった手段はありますが、他のリージョンにインスタンスを複製したいといった場合や、論理的にデータのバックアップしておきたい場合に有用です。
前提条件
最新のOracle Instant Clientがインストールされた、コマンド実行用のComputeインスタンスが構成されていること
実施イメージ
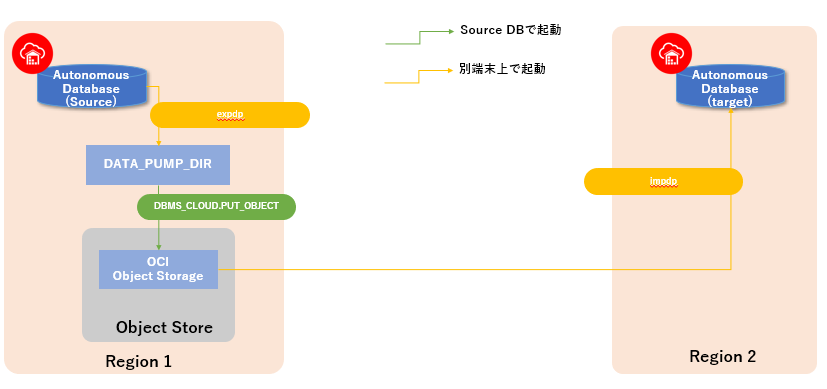
実施手順
以下ではソースDBとターゲットDBについて、ATPなのか、ADWなのか特に明記していませんが、
基本的にソース、ターゲットがATP/ADW、どちらであっても同じ手順です。
■ SourceDBからデータをエクスポートする
インスタンス作成時にデフォルトで構成されているディレクトリ・オブジェクト(DATA_PUMP_DIR)を指定することで、ADW/ATPインスタンスが構成されているExadataのローカルストレージ(DBFS)に出力されます。
以下は表単位でエクスポートする例ですが、スキーマ単位で実行することも可能です。
エクスポートの実行
expdp userid=<USER>/<PASSWORD>@<connect_string> \
tables=<table_name> \
directory=DATA_PUMP_DIR \
dumpfile=DATA_PUMP_DIR:expdp.dmp \
logfile=DATA_PUMP_DIR:expdp.log
DBMS_CLOUD.PUT_OBJECTによるオブジェクト・ストレージへの書き出しの際に(後述)、単一ファイルのサイズ制限として5GBが上限なので、対象となるデータサイズが大きい場合は、データを分割する必要があります。また出力するデータを圧縮することも可能であり、リージョンを跨いだデータ転送を高速化することができます。
エクスポートの実行(データ分割、圧縮あり)
expdp userid=<USER>/<PASSWORD>@<connect_string> \
schemas=<schema_name> \
directory=data_pump_dir \
filesize=<5GB以下のサイズを指定> \
parallel=<number_of_OCPU> \
dumpfile=data_pump_dir:expdp_%U.dmp \
compression=all \
compression_algorithm=high \
logfile=data_pump_dir:expdp.log
■ オブジェクト・ストレージ上にバケットを作成する
コンソール左上のハンバーガーアイコンから「オブジェクト・ストレージ」をクリック
「バケットの作成」ボタンをクリック
「バケット名」を入力し、「バケットの作成」ボタンをクリック
■ 認証トークンの取得する
コンソールの右上のユーザアイコン→「ユーザ設定」をクリック
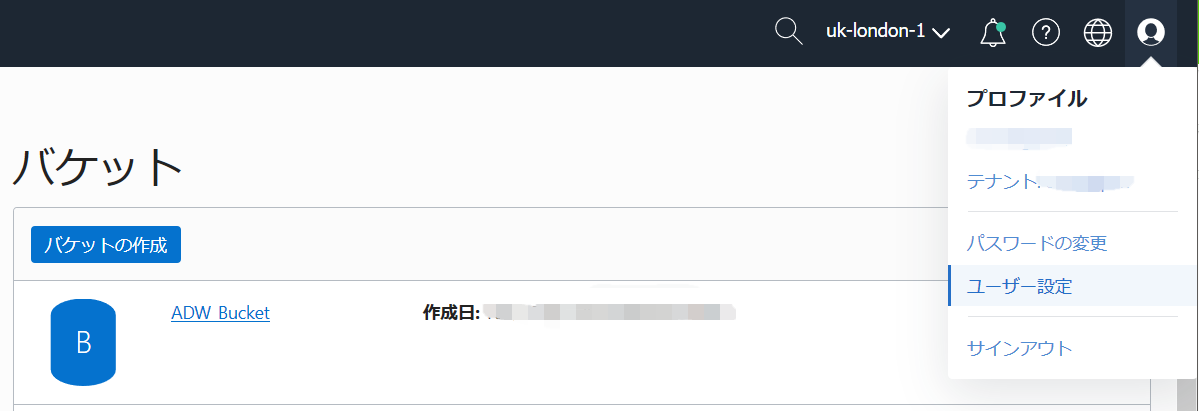
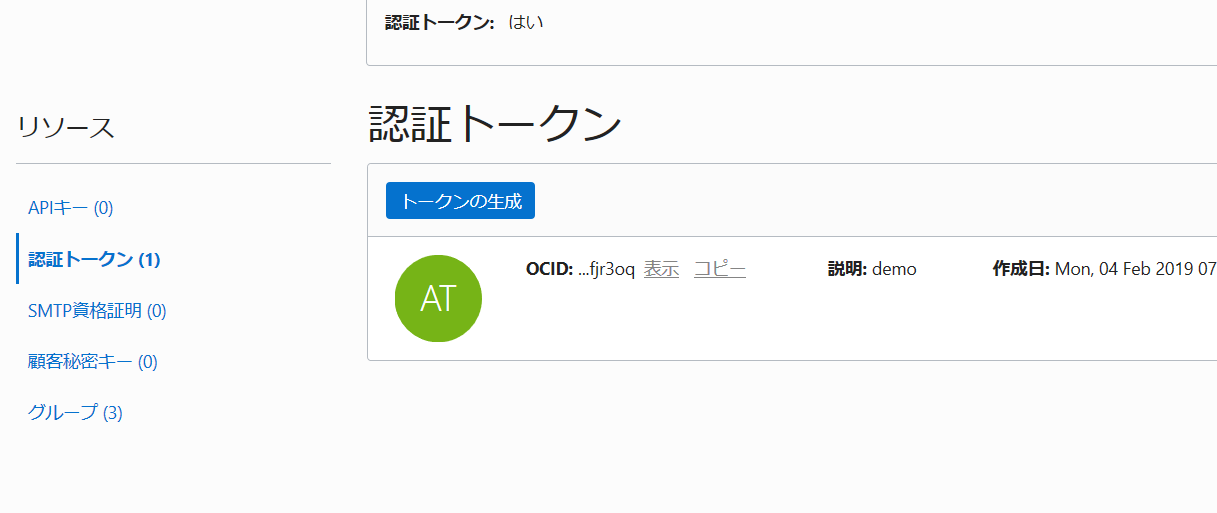
画面左側の「リソース」の「認証トークン」をクリック
「トークンの生成」ボタンをクリック
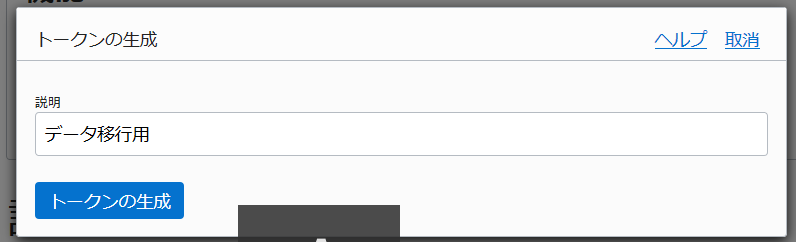
「説明」を入力し、「トークンの生成」ボタンをクリック
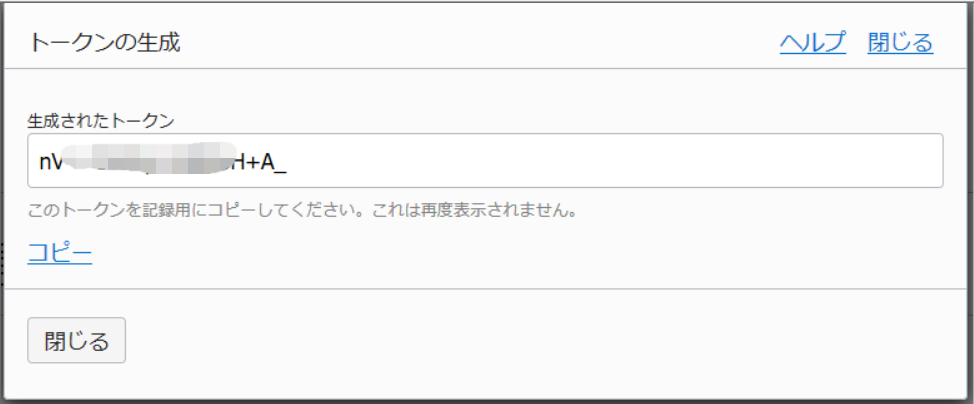
表示されたトークンをコピーする
※ 一度しか表示されないので、別途メモ帳などに保存しておくように。
■ Database Credentialの作成(SourceDBに接続して実施)
SQL*Plus等で以下を実行し、オブジェクトストレージへの接続情報を登録します。
oci_usernameはSourceDB内のスキーマではなく、OCIのユーザ名であることに注意してください。
auth_tokenは先の手順で保存した文字列で置き換えます。
SET DEFINE OFF;
BEGIN DBMS_CLOUD.create_credential(
credential_name => 'DATAPUMP_CREDENTIAL',
username => '<oci_username>',
password => '<auth_token>');
END;
/
■ dmpファイルのコピー(SourceDBに接続して実施)
SQL*Plus等で以下を実行します。
(SourceDBが配置されているExadataのローカルストレージ(DBFS)から、オブジェクトストレージにダンプファイルを出力されます)
BEGIN
DBMS_CLOUD.PUT_OBJECT(
credential_name=>'DATAPUMP_CREDENTIAL',
object_uri=>'https://swiftobjectstorage.<region>.oraclecloud.com/v1/<namespace_string>/<bucket_name>/expdp.dmp',
directory_name=>'DATA_PUMP_DIR',
file_name=>'expdp.dmp');
END;
/
現時点では、DBMS_CLOUD.PUT_OBJECTは"*"のようなワイルドカードをサポートしていないため、複数のダンプファイルをオブジェクトストレージに出力する際に、ファイルごとに実施する必要があります。シェルスクリプトでまとめて実行することも可能です。
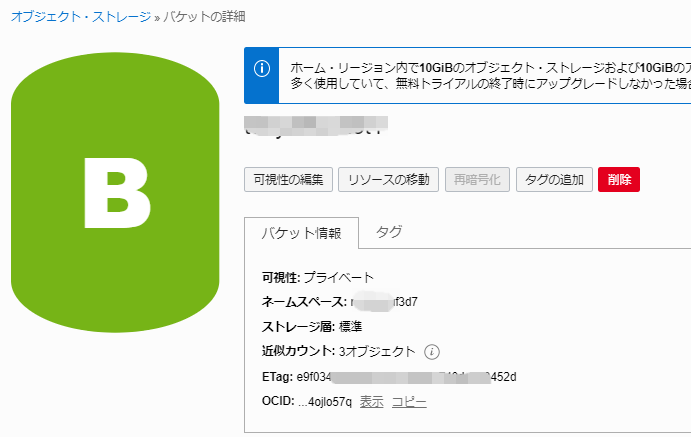
object_uriについて、以下は、リージョン:London、バケット名:ADW_Bucketの例です。
namespace_stringは、以下オブジェクトストレージの概要画面のネームスペースで示される文字(nrvxxxx3d7)を利用します。
https://swiftobjectstorage.uk-london-1.oraclecloud.com/v1/nrvxxxx3d7/ADW_Bucket/expdp.dmp
また、上記はSwift互換URIを利用していますが、Oracle Cloud のNative URIを利用することも勿論可能です。
■ Database Credentialの作成(TargetDBに接続して実施)
SQL*Plus等で以下を実行し、TargetDB内に、オブジェクトストレージへの接続情報を登録します。
oci_usernameはTargetDB内のスキーマではなく、OCIのユーザ名であることに注意してください。
auth_tokenは先の手順で保存した文字列で置き換えます。
SET DEFINE OFF;
BEGIN DBMS_CLOUD.create_credential(
credential_name => 'DATAPUMP_CREDENTIAL',
username => '<oci_username>',
password => '<auth_token>');
END;
/
■ ADWへのインポート(impdp)
インポートを実行します。
インポートの実行(単一のダンプファイルをインポートする場合)
impdp userid=admin/<admin_password>@<connect_string> parallel=<number_of_OCPU> credential=DATAPUMP_CREDENTIAL \
tables=<table_name> directory=DATA_PUMP_DIR \
dumpfile=https://swiftobjectstorage.<region>.oraclecloud.com/v1/<namespace_string>/<bucket_name>/<dumpfile_name>
logfile=DATA_PUMP_DIR:impdp.log
インポートの実行(複数のダンプファイルをインポートする場合)
impdp userid=admin/<admin_password>@<connect_string> schemas=<schema_name> parallel=<number_of_OCPU> \
credential=DATAPUMP_CREDENTIAL \
directory=DATA_PUMP_DIR table_exists_action=truncate \
exclude=index,cluster,indextype,materialized_view,materialized_view_log,materialized_zonemap,db_link \
partition_options=merge transform=segment_attributes:n transform=dwcs_cvt_iots:y \
transform=constraint_use_default_index:y \
dumpfile=https://swiftobjectstorage.<region>.oraclecloud.com/v1/<namespace_string>/<bucket_name>/expdp_%U.dmp \
logfile=DATA_PUMP_DIR:impdp.log
dumpfileについて、以下は、リージョン:London、テナント名:orasejapan、バケット名:ADW_Bucketの例です。(上記PUT_OBJECTを実施した際のURLと同じです)
https://swiftobjectstorage.uk-london-1.oraclecloud.com/v1/orasejapan/ADW_Bucket/expdp.dmp
注意点
その他
ここではリージョン1(London)のオブジェクト・ストレージから直接リージョン2のADBにインポートしましたが、一旦リージョン2のオブジェクト・ストレージにデータを複製(クロスリージョン・コピー)してから、インポートすることも可能です。
参考:https://qiita.com/tnagakub/items/19954aaf642e997688d8
データの内容によってOCPU数等の要因によって実行時間は変化するので参考値ですが、処理時間は以下のような感じでした。
・パラレル度を大きく設定すれば、Export/Importを高速に処理できる。
・PUT_OBJECTはOCPUの違いで差はない。
・参考までにOCPU=8で圧縮済み10GBのデータだと40分弱
参考コマンド
DATA_PUMP_DIRにあるファイル名、ファイルサイズの確認
SELECT * FROM DBMS_CLOUD.LIST_FILES('DATA_PUMP_DIR');
DATA_PUMP_DIRにあるファイルの削除
exec DBMS_CLOUD.DELETE_FILE('DATA_PUMP_DIR',‘expdp.log');
exec DBMS_CLOUD.DELETE_FILE('DATA_PUMP_DIR',‘expdp.dmp');
DataPumpのジョブの確認
select job_name from DBA_DATAPUMP_JOBS;
expdpの進行状況の確認
expdp userid=admin/<admin_password>@<connect_string> attach=SYS_EXPORT_TABLE_01
進行状況の更新
Export>status
ジョブのキャンセル
Export>kill_job