
VigetがWgetになっているので精度は若干良くない。GIFの例では普通に文字列をコピーできるが、本来は画像になっている文字列で使用することを想定。
Copying Text From Images to Your Clipboard | Vigetを元に設定をする。
Tesseractのインストール
まず、画像からテキストを取り出すtesseractをインストールする。
$ brew install tesseract
日本語が抽出できるようにhttps://github.com/tesseract-ocr/tessdata から日本語用のデータをダウンロードする。
現時点で、Homebrewでインストールされるバージョンは3.04
$ tesseract -v (git)-[bisect/bad] <!bisect>
tesseract 3.04.01
leptonica-1.74.1
libjpeg 8d : libpng 1.6.28 : libtiff 4.0.7 : zlib 1.2.8
なので、3.04treeからデータをダウンロードする。
$ curl -L -o /usr/local/share/tessdata/jpn.traineddata 'https://github.com/tesseract-ocr/tessdata/raw/3.04.00/jpn.traineddata'
使える言語にjpnがあることを確認する。
$ tesseract --list-langs
Automaterの設定
Automaterでサービスを作る。
Automaterを起動して「新規書類」。「サービス」を選択。
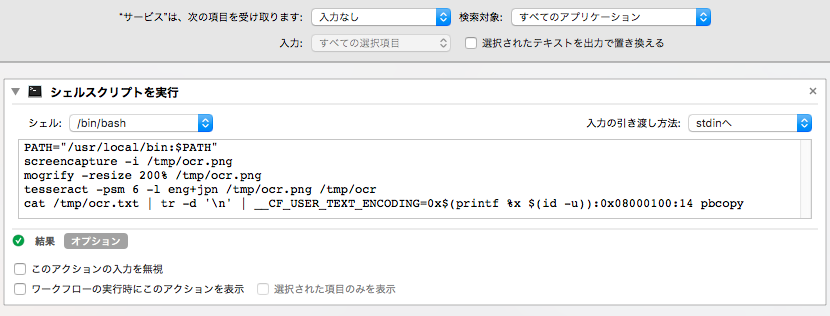
アクションを「シェル」で検索して、出てきた「シェルスクリプトを実行」をダブルクリック。
受け取る項目を「入力なし」にする。
シェルを「/bin/bash」などにする。内容は以下のようにする。
PATH="/usr/local/bin:$PATH"
screencapture -i /tmp/ocr.png
mogrify -resize 200% /tmp/ocr.png
tesseract -psm 6 -l eng+jpn /tmp/ocr.png /tmp/ocr
cat /tmp/ocr.txt | tr -d '\n' | __CF_USER_TEXT_ENCODING=0x$(printf %x $(id -u)):0x08000100:14 pbcopy
screencapture -iでスクリーンショットを取るインタラクティブモードに入り、それを/tmp/ocr.pngに保存する。
tesseractは文字のサイズが小さいとうまく認識されないので、mogrify -resize 200%で2倍にしている。mogrifyはimagemagickをインストールすると入るコマンドなので、ない場合は
$ brew install imagemagick
でインストールする。
tesseract -psm 6 -l eng+jpn /tmp/ocr.png /tmp/ocr
で/tmp/ocr.pngの画像から文字列を抽出して、/tmp/ocr.txtに保存する。-l eng+jpnで英語と日本語を対象にしている。-psm 6は抽出の形式。
テキストをクリップボードに保存する部分でtr -d '\n'しているのは、いらない改行を取り除くため。__CF_USER_TEXT_ENCODINGの部分は日本語をクリップボードに保存するためのおまじない。
screenshot_to_textなど適当な名前で保存する。
ショートカットを登録する
「システム環境設定」ー「キーボード」ー「ショートカット」ー「サービス」を選択して、「一般」にあるscreenshot_to_textを選択して、ショートカットを登録する。
スクリーンショットをクリップボードに保存するのが、Ctrl+Shift+Command+4なので、Ctrl+Shift+Command+5などに設定する。