フリーのtesseractというOCRを使って、pythonで日本語のOCRを行うまでに行った手順をまとめます。
環境
- Ubuntu 14.04
- Python 2.7
インストール
tesseractをインストールします。
インストール方針
インストールの方法には、
- apt-getでインストール
- ソースからビルド、インストール
の二つがあります。
1のapt-getでインストールできるバージョンは3.0.3です。
tesseractで日本語を扱うには、日本語で訓練されたデータ(jpn.traindata)が必要です。
これは自分でダウンロードしてくる必要があるのですが、ネット上で見つけられたものはver3.0.4のものだけです。3.03でこのデータを使おうとしても、うまくいかず、こんなエラーが出ます。
read_params_file: parameter not found: allow_blob_division
こちらのかたのように、traindataを編集して3.0.3で使うこともできますが、そのために必要なcombine_tessdataというコマンドはapt-getインストールでは使えません。そのため、現状で日本語でやりたかったら、ソースでインストールする他ないかと思われます。
基本的に、公式のコンパイルインストールのページを参考に、tesseract3.0.4をインストールします。
依存関係インストール
$ sudo apt-get install autoconf automake libtool
$ sudo apt-get install libpng12-dev
$ sudo apt-get install libjpeg62-dev
$ sudo apt-get install libtiff4-dev
$ sudo apt-get install zlib1g-dev
$ sudo apt-get install libicu-dev # (if you plan to make the training tools)
$ sudo apt-get install libpango1.0-dev # (if you plan to make the training tools)
$ sudo apt-get install libcairo2-dev # (if you plan to make the training tools)
Laptonicaインストール
Laptonicaという画像ライブラリが必要のようです。
ソースをダウンロードページからダウンロード、解凍します。tesseract3.0.4のインストールには、最低でもLaptonica1.71が必要なので、最新の1.7.3をインストールします。
# 解凍
gzip -dc leptonica-1.73.tar.gz |tar xvf -
cd leptonica-1.73
# makeとか
$ ./configure
$ make
$ sudo make install
tesseractインストール
基本的にこれどおりやります。
3.0.4のソースをこちらから取得
# 解凍、移動
$ unzip 3.04.zip
$ cd tesseract-3.04
# ライブラリパスを通しておく
$ export -p LD_LIBRARY=$LD_LIBRARY:/usr/local/lib
# インストール
$ ./autogen.sh
$ ./configure
$ sudo make # ここだけsudoにした。laptonicaが見当たらなかったので。
$ sudo make install
$ sudo ldconfig
日本語ファイルの取得、設定
こちらの言語データセットから、jpn.traindataという日本語のものをダウンロードし、こちらに置きます。
/usr/local/share/tessdata/
そして、このフォルダのパスを設定しておきます。
export TESSDATA_PREFIX="/usr/local/share/tessdata/tessdata/
動作確認
インストールがうまくいっていれば、コマンドライン上でOCRの実行が可能になっているはずです。
試しにこんな画像を日本語OCRにかけてみます。

tesseract ocr_test.png out -l jpn
と実行すると、out.txtというファイルに結果が書き込まれます。
笑顔が一番 ! れにちや ん
小さい「ゃ」が大きい「や」になってますが、概ね認識できています。
小文字の概念は他の英語とかにないので、そこは難しいのでしょうか。
pyocrの導入
pythonで使えるように、pyocrというラッパーライブラリを使います。
インストールは、
$ pip install pyocr
で終わりです。
しかしながら、ソースからインストールしたtesseractに対応しておらず、テスト用に以下のerror.pyを実行させると、うまくいきません。
import pyocr
tools = pyocr.get_available_tools()
Traceback (most recent call last):
File "error.py", line 12, in <module>
tools = pyocr.get_available_tools()
File "/usr/local/lib/python2.7/site-packages/pyocr/pyocr.py", line 74, in get_available_tools
if tool.is_available():
File "/usr/local/lib/python2.7/site-packages/pyocr/libtesseract/__init__.py", line 152, in is_available
version = get_version()
File "/usr/local/lib/python2.7/site-packages/pyocr/libtesseract/__init__.py", line 179, in get_version
upd = int(version[2])
ValueError: invalid literal for int() with base 10: '02dev'
エラーを読むと、"02dev"という文字列をintに変換しようとして怒られています。ソースからインストールしたバージョンが、tesseract 3.04.02devで、devパッケージを想定していないようです。
なので、このソースを変更してあげます。
変更するソースは、virtualenv使用の場合は、適当に置き換えてください。
if len(version) >= 3:
upd = int(version[2].replace('dev', ''))
# upd = int(version[2])
これでうまくいくはずです。
OCRを試してみる
色々なOCRの仕組みがあるので、試してみます。
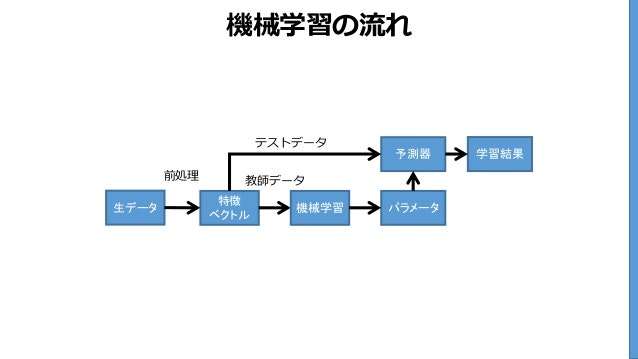
この画像で試してみます。
Text
もっともシンプルなOCRです。画像から文字を読み取り、文字列として返します。
import pyocr
import pyocr.builders
import argparse
from PIL import Image
parser = argparse.ArgumentParser(description='tesseract ocr test')
parser.add_argument('image', help='image path')
args = parser.parse_args()
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
# The tools are returned in the recommended order of usage
tool = tools[0]
res = tool.image_to_string(Image.open(args.image),
lang="jpn",
builder=pyocr.builders.TextBuilder(tesseract_layout=6))
print res
結果
機鵬習の卿
テス 卜ヲータ
扉 叫隣 史習給果
縄
隻デーヮ ^~璽属~ 慣賭史習 バ『メーヮ
難しい単語のせいか、結果はひどいです。
WordBox
単語がどこにあるのか、boxを返してくれます。openCVで結果を可視化してみます。(openCVはこちらでインストール)
import pyocr
import pyocr.builders
import argparse
import cv2
from PIL import Image
parser = argparse.ArgumentParser(description='tesseract ocr test')
parser.add_argument('image', help='image path')
args = parser.parse_args()
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
# The tools are returned in the recommended order of usage
tool = tools[0]
res = tool.image_to_string(Image.open(args.image),
lang="jpn",
builder=pyocr.builders.WordBoxBuilder(tesseract_layout=6))
# draw result
out = cv2.imread(args.image)
for d in res:
print d.content
print d.position
cv2.rectangle(out, d.position[0], d.position[1], (0, 0, 255), 2)
cv2.imshow('image',out)
cv2.waitKey(0)
cv2.destroyAllWindows()
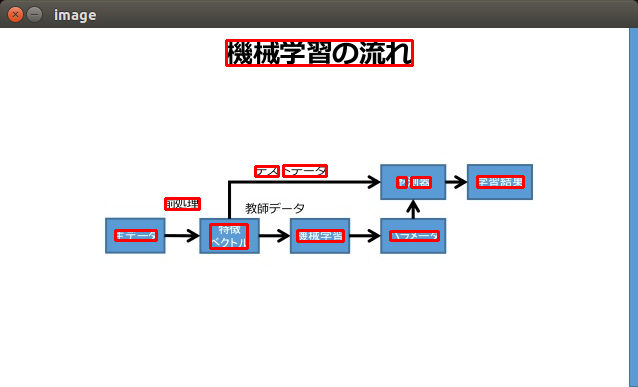
機鵬習の卿
((226, 12), (412, 37))
テス
((255, 138), (278, 148))
卜ヲータ
((283, 137), (326, 148))
扉
((397, 149), (406, 159))
叫隣
((411, 149), (430, 159))
史習給果
((477, 148), (523, 159))
縄
((165, 170), (199, 181))
隻デーヮ
((115, 202), (156, 212))
^~璽属~
((210, 196), (247, 220))
慣賭史習
((297, 202), (343, 213))
バ『メーヮ
((390, 203), (438, 212))
領域はそこそことれていますが、認識した単語は相変わらずひどいです。
LineBox
WordBoxによるものは、単語ごとでしたが、LineBoxでは、同じ行にある単語をまとめてくれるようです。
先ほどのWordBoxのソースを一部だけ変えます
WordBoxBuilder→LineBoxBuilder にするだけです。
res = tool.image_to_string(Image.open(args.image),
lang="jpn",
builder=pyocr.builders.LineBoxBuilder(tesseract_layout=6))
結果
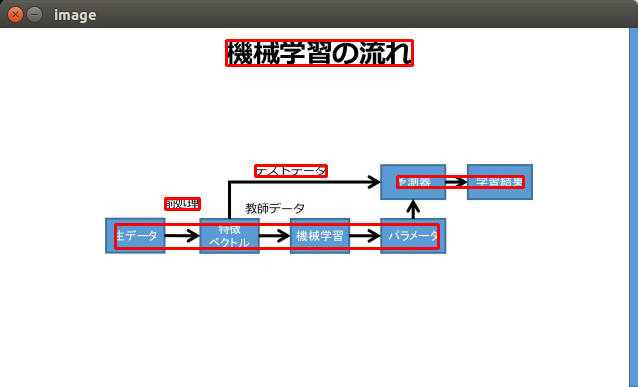
機鵬習の卿
((226, 12), (412, 37))
テス 卜ヲータ
((255, 137), (326, 148))
扉 叫隣 史習給果
((397, 148), (523, 159))
縄
((165, 170), (199, 181))
隻デーヮ ^~璽属~ 慣賭史習 バ『メーヮ
((115, 196), (438, 220))
この画像は同じ行にまとめてくれなくてもよいですが、複数行の文章のときに使えそうです。
tesseract_layoutについて
それぞれのbuilderで、tesseract_layout=6
と設定していました。この数字は、どのような方針で画像に対してOCRを行うか設定するものらしく、
こちらのかたがまとめてくださっています。
http://tanaken-log.blogspot.jp/2012/08/imagemagick-tesseract.html
pagesegmode values are:
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
学習データについて
見ての通り、既存の日本語データを使うと、精度がよろしくないようです。
自分で学習データを作成すれば、もっとまともになるとのことです。
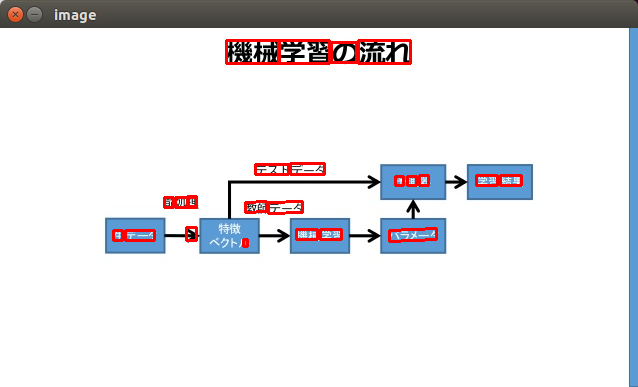
おまけ Google Cloud Vision
Google Cloud Vision API のTEXT_DETECTを利用すると、こんな感じになります。
機械
学習
の
流れ
テスト
データ
予
測
器
学習
結果
前
処理
教師
データ
生
データ
機械
学習
パラメータ
L
理
A
やっぱり精度いいですね。そんなにたくさんリクエストを投げず、手軽に処理したい場合は、Vision API使った方がいいですね。