はじめに
ETLツールであるAWS Glueについて、業務で使用することがあり、この記事で調べたことをまとめます。
Glueについては様々な機能があり、全てをこの記事で説明することは難しいので、この記事ではGlueのジョブに焦点を当てて説明していきます。
Glueのジョブは実行環境としてSparkやRayがあり、データエンジニアリング初学者の筆者としてはそもそもSparkやRayとはどういったもので、何が違うのかといったところから分かっていなかったため、そのあたりの話を含めて説明していきます。
AWS Glueとは
AWS Glue は、フルマネージドかつサーバーレスなETLサービスです。様々なソースからのデータの抽出、変換、ロードを効率的に行うことができます。
以下のページを参照すると、Glueのコンポーネントは以下のようになります。
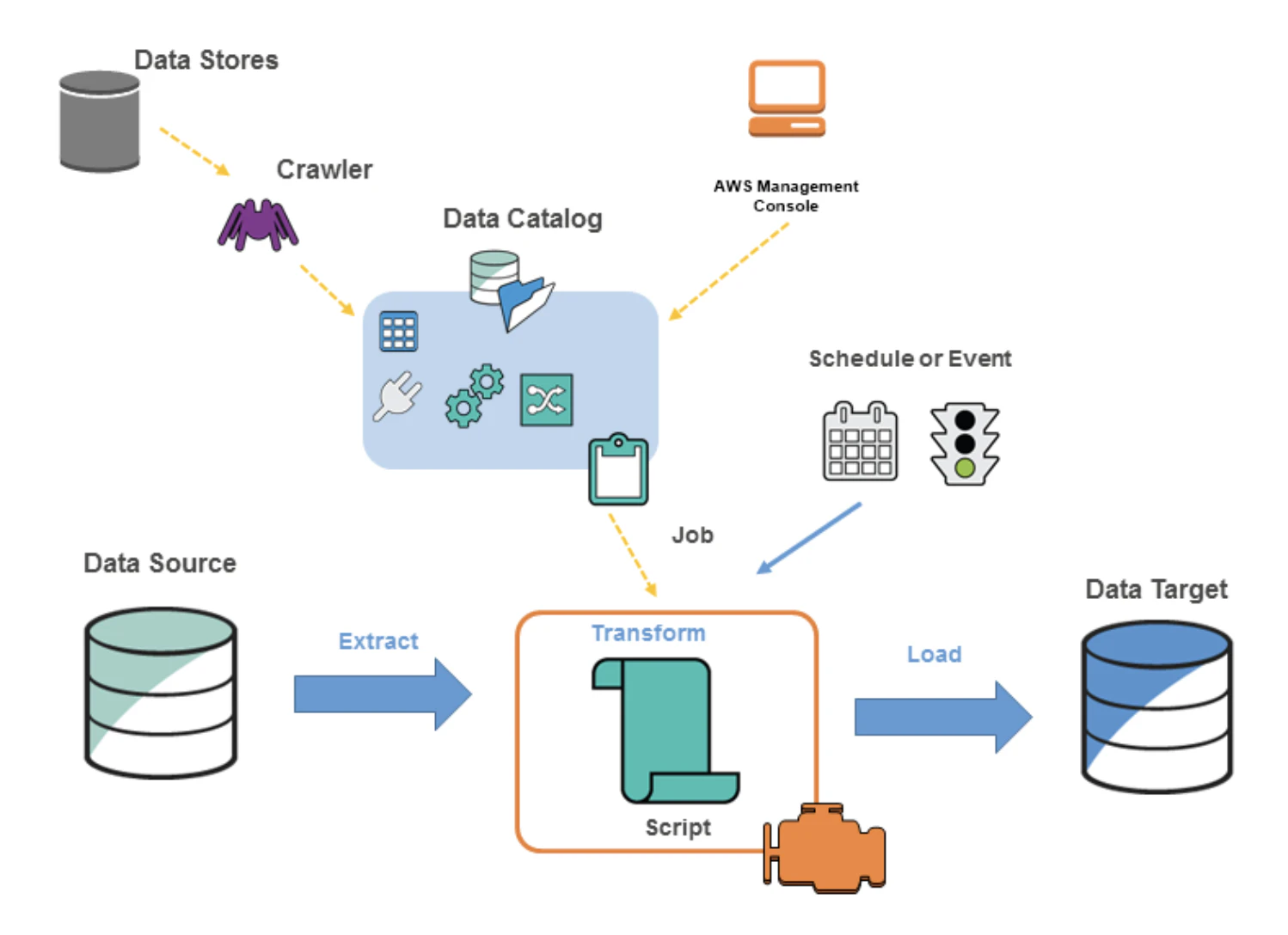
クローラー
クローラーにデータストアを指定することで、自動的にスキーマを検出してメタデータをデータカタログに作成します。
データカタログ
データカタログでは、ETL処理したいデータのメタデータを管理しています。
また、ETLのジョブやワークフローに関するデータもここで管理します。
メタデータは、元データ(データストア)からGlueのクローラーで抽出してきたものになります。
ETLジョブ
データの抽出、変換、ロードを行うプロセス。PythonまたはScalaで記述され、Glueのサーバーレスエンジンにて実行されます。
トリガー
スケジュールやイベントに基づいて機械的にジョブを実行することができます。
ジョブの部分が個人的には理解が難しく、かつ重要であると思われたため、自分のアウトプットのためにも、この記事では以下でGlueのジョブについて詳しく説明していきます。
Glueのジョブについて
Glueのジョブは、実行環境として以下があります。
- Spark
- PySpark(PythonでSparkを利用するためのAPI)を使ったPythonスクリプトなど、Spark向けのコードを用意することで、Sparkシステム上で分散処理ができる。PysparkをAWSが拡張したawsglueライブラリもある。Scalaでの実装も可能。
- Ray
- 2023/5提供の新しい機能。Sparkと同様Pythonで並列処理を実現できる。Sparkと比べ学習コストが低く、Pandasなどよく使われているライブラリを組み合わせることができる
- Python Shell
- 単純に、Pythonのスクリプトを実行するだけのジョブ。並列実行はできないため、大量のデータの処理には不向き
Python Shellは最も単純だが複雑な処理ができない(シングルノードでの処理しかできない)、一方でSparkは複雑な処理が可能だが実装が難しく学習コストがかかる。Rayはその中間で実装がしやすくかつパフォーマンス面もある程度良い、といったようなイメージをしています。
上記3つについて、大量データ処理時にも問題なく並列でスケーリングできるSparkもしくはRayが選択されることが多いと考えられるため、SparkとRayに焦点を当てて以下でそれぞれについて説明していきます。
Spark
Sparkは、Hadoop技術をベースとして、その課題点を解決するためにApache Sparkプロジェクトによって作られた分散並列処理のフレームワークです。
Apache Sparkプロジェクトは、Spark本体以外にも様々なライブラリを提供されており、これらはGlueでも使用できるものも多いため、関連するApache Sparkの知識が必要になることがあります。
ただ、GlueではSparkのサーバーを自分で構築しなくても、PySparkを使いPythonスクリプトを用意することで、SparkによるETLを実現できます。
より詳細に言うと、Sparkの実行環境の管理はGlueサービスが実施するので、利用者は直接制御することなく、利用したい環境の指示(処理スペック、並列度、リトライ回数など)をするだけで利用できます。
実装手段としては、PySpark、PysparkをAWSが拡張したawsglueライブラリ、Scalaがあります。
Ray
Sparkと同じ分散並列処理のフレームワークですが、Pythonでシンプルに記述できるように設計されており、またPandasなどよく使われるライブラリと組み合わせで使用できます。
これまでのPythonでの分散並列処理の実装は難しいものであったが、Rayの登場によってPythonによる分散並列処理が容易に実装できるようになった、そういった立ち位置にあるものがRayであると理解しています。
Ray Core (分散処理機能)、Ray Dataset (データの格納) 、Modin (pandas をRayで実行するためのもの) が利用できる環境がGlueによって提供されています。
SparkとRayの違い
Rayは、タスク指向であり、一連の独立したタスクを同時に実行するタスクの並列処理に優れています。
一方Sparkはデータ指向で、大規模なデータの対しての並列処理(ETL、データ分析、ストリーミング)に優れています。
どちらが優れているということではなく、タスク指向であるRayとデータである指向Sparkはそれぞれ別々で、用途に応じて使い分けることになりそうです。
最後に
本記事ではAWS Glueについて、その概要について触れた後、ジョブの実行環境について簡単に説明しました。SparkとRayのそれぞれの特徴や違いについては、実際実装してみたりしないと理解が進まないところもあるかと思いますので、次回以降の記事で実装踏まえてその詳細について説明できればと思います。