はじめに
1. 製造業におけるAI導入について
製造業においてよくあるAIの導入例として、良品と不適合品からAIに機械学習をさせ、カメラに自動検知させるというのがあります。
人間による目視で外観検査を行っていた部分を、機械に行わせるというものです。
人件費の削減につながること。また、ヒューマンエラーによる不適合品の見逃し等もなくなり、客先への信頼という観点でのメリットが存在します。
また、自社製品の画像は比較的入手しやすいことから、大量の画像をパターン分析することが可能であり、導入しやすいとも言えます。
しかしながら、導入までのコストの観点から、まだまだ目視による外観検査を行っている会社が多いのが実情です。
日本企業のAIシステム導入について
2. 筆者の経験
私は現在、自動車部品メーカーにて設計開発を行っているのですが、製造ラインの検討時に外観検査上で問題が生じた経験があります。画像測定器による外観検査を行うのですが、組み立ての構造上、人の手による組立てが必ず必要となります。その際、ゴム手袋に付着した素材の粉や油等により、良品までもNGにしてしまうとのことでした。
もちろんコストをかければ人の手を使わず、全自動でできる設備を導入することもできるのですが、実際はそうはいきません。設計段階で諸々協議しながら製品を作れれば良いが、時間の制約により開発が進み、後工程にて問題が生じることはよくあることです。品質がよく、利益がでるように開発するというのは如何に難しいものか日々痛感させられます。
以上のような経験から、機械学習を用いたカメラによる自動検査システムを導入できれば、画像による検査ミスがなくなるのではないかと考えました。
3. 分析データについて
自社データの公開や利用は難しいため、kaggleに挙げられている以下の題材を使用しました。
鋳造で作られた水中ポンプ用インペラ画像の分類となります。
[casting product image data for quality inspection]
(https://www.kaggle.com/ravirajsinh45/real-life-industrial-dataset-of-casting-product)
データの確認
1. ライブラリのインポート
import os
import cv2
import random
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import keras
import keras.preprocessing.image as Image
import sklearn.metrics
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
from sklearn.metrics import classification_report
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import preprocessing, layers, models, callbacks
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import ModelCheckpoint
from keras.preprocessing.image import load_img, save_img, img_to_array, array_to_img
2. データ数の確認
分析に使用できる画像は何枚程度あるのか、どういったデータが入っているのかを最初に確認します。画像の枚数が少なすぎると、画像分析へのアプローチ手法が変わってくる可能性がある為です。
# train data数
print("ok_front :", len(os.listdir("./archive/casting_data/casting_data/train/ok_front")))
print("def_front :", len(os.listdir("./archive/casting_data/casting_data/train/def_front")) )
# test data数
print("ok_front :", len(os.listdir("./archive/casting_data/casting_data/test/ok_front")))
print("def_front:", len(os.listdir("./archive/casting_data/casting_data/test/def_front")))
ok_front : 2875
def_front : 3758
ok_front : 262
def_front: 453
本データは、予め訓練データとテストデータに分けられており、それぞれにOK写真とNG写真が分割して入っているようです。
os.listdir でファイル・ディレクトリ内の一覧を取得し、len()でディレクトリ 内のファイル数を数えました。
トレーニングデータが約6500枚、テストデータが約700枚あることが分かります。
3. 画像のチェック
img_ok = "./archive/casting_data/casting_data/train/ok_front"
lsdir = os.listdir(img_ok)
imgs = []
for i in lsdir:
target = os.path.join(img_ok, i)
img = cv2.imread(target)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
imgs.append(img)
count = 10
plt.figure(figsize=(15, 6))
for i, l in enumerate(random.sample(imgs, count)):#ランダムに複数の要素を選択(重複なし)
plt.subplot(2,5, i+1)
plt.axis('off')
plt.title("img"+str(i))
plt.imshow(l)

ディレクトリへのパスと画像の名前をos.path.join()で結合し、OpenCVのimreadで各画像を読み込んでいます。その後、リストに保存した画像からcountで指定した枚数をmatplotlibを用いて表示させるようにしました。
データの分割と正規化について
本頁では、データの分割と正規化について記載します。
1. データを分割とは
CNNで学習を行う際、以下のデータセットが必要となります。
-
訓練データ:実際にニューラルネットワークの重みを更新する学習データ。 -
検証データ:ニューラルネットワークのパラメータの良し悪しを確かめるためのデータ。 -
テストデータ:学習後に汎化性能を確かめるテストデータ。
新たに計測した画像に対して学習したモデルがうまく汎化できているかを評価するために、テストデータを用意します。モデルの構築で使用した訓練データは、正確にラベルの判別ができてしまう為テストデータに含めることはできません。そこで、モデルの性能を評価するためにこれまでに見せていないデータ(テストデータ)が必要になります。
また、モデルの過学習を防ぐ為に、訓練データからデータ分離した検証データを用意します。モデルを検証データで予測し、精度を計測する際に用います。
データ分割によく使用される方法ではホールドアウト、クロスバリデーション、ジャックナイフ法などが有名です。
2. データの正規化とは
計算・解析において扱いやすいように、データをある規則に従って整形することを言います。
画像分析においては、学習コストを下げるために[0,1]の範囲に収まるよう255.0で割ることで正規化を行うのが、一般的なようです。
[正規化、標準化について]
(https://nine-num-98.blogspot.com/2019/12/ai-normalization.html#:~:text=%E6%AD%A3%E8%A6%8F%E5%8C%96%E3%81%A8%E3%81%AF%E3%80%81%E8%A8%88%E7%AE%97,%E6%89%8B%E6%B3%95%E3%81%8C%E7%94%A8%E3%81%84%E3%82%89%E3%82%8C%E3%81%BE%E3%81%99%E3%80%82)
3. ImageDataGenerator
kerasのImageDataGeneratorを用いることで、上述したデータ分割や正規化を実装します。
本モジュールは、画像の水増しにもよく使われ、画像の反転、ずらし、複数の加工の組み合わせを行うこともできます。
# ImageDataGeneratorクラスのインスタンスを作成
datagen = Image.ImageDataGenerator(
rescale=1/255,
validation_split = 0.1
)
# flow_from_directory()でディレクトリへのパスを受け取り、そこから自動でデータを読み取って加工したデータのバッチを生成
train_generator = datagen.flow_from_directory("./archive/casting_data/casting_data/train/",
class_mode='binary',
batch_size=32,
target_size=(300,300),
color_mode='grayscale',
classes={'ok_front':0, 'def_front':1},
shuffle=True,
subset = "training"#はじめに書いたvalidationかtrainのデータかを指定する。
)
val_generator = datagen.flow_from_directory("./archive/casting_data/casting_data/train",
class_mode='binary',
batch_size=32,
target_size=(300,300),
color_mode='grayscale',
classes={'ok_front':0, 'def_front':1},
shuffle=True,
subset = "validation"
)
# ImageDataGeneratorクラスのインスタンスを作成(テストデータ用)
test_datagen = image.ImageDataGenerator(
rescale = 1/255
)
n_test = sum([len(files) for curDir, dirs, files in os.walk("./archive/casting_data/casting_data/test")])
test_generator = test_datagen.flow_from_directory("./archive/casting_data/casting_data/test",
class_mode='binary',
batch_size=n_test,
target_size=(300,300),
color_mode='grayscale',
classes={'ok_front':0, 'def_front':1},
shuffle = False
)
【ImageDataGeneratorパラメーター】
-
rescale:読み込まれた各画素のRGB値を0.0〜1.0の間に収まるように正規化。 -
validation_split:訓練データを9:1の割合で検証用データと分割。
【flow_from_directoryパラメーター】
-
class_mode:学習に使われる正解ラベルが2値(0か1)の判定になる為、binaryを選択。 -
batch_size:ミニバッチ学習に使われるバッチのサイズ。一度に読み込むデータの数。 -
target_size:指定した大きさに自動的にリサイズされて読み込まれる。 -
color_mode:"grayscale"or"rbg"を設定。チャンネル数が1or3のどちらに変換するか。 -
classes:分類させたいデータのクラス名。 -
shuffle=True:データをシャッフルするかどうか(真偽値)。学習に使用するデータに偏りを持たせないために使用。
CNNの実装
CNNは何段もの深い層を持つニューラルネットワークで、以下のように層を複数組み合わせて使用していきます。
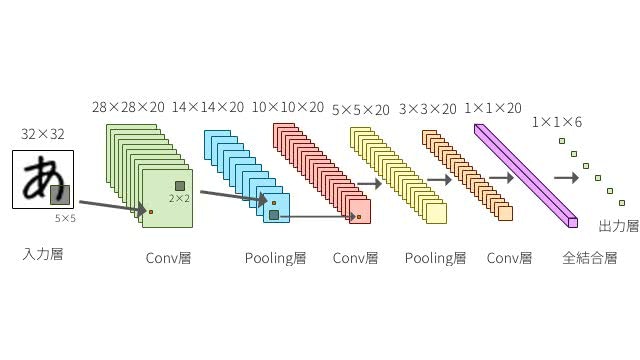
今回設定したCNNの構造は以下の通りです。
-
畳み込み層:入力データの一部分に注目し、その部分画像の特徴を調べる層。 -
プーリング層:畳み込み層の出力を縮約し、データの量を削減する層。 -
Flatten():データを一次元に平滑化。 -
全結合層:各プーリング層からの出力を指定したノードの数に結合し、活性化関数によって特徴変数を出力。 -
Dropout():出力された結果をランダムに間引く。 -
出力層:全結合層からの出力を基に、sigmoid関数によって確率に変換しクラス分類。
from tensorflow.keras.layers import Activation, Conv2D, Dense, Flatten, MaxPooling2D
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.utils import to_categorical
# モデルの定義
model = Sequential()
# 畳み込み層+プーリング層
model.add(Conv2D(filters=16,kernel_size=(7,7),strides=(2,2),padding='same',activation='relu',input_shape=(300,300,1)))
model.add(MaxPooling2D(pool_size=(2,2),strides=(2,2)))
model.add(Conv2D(filters=32,kernel_size=(3,3),activation='relu',padding='same'))
model.add(MaxPooling2D(pool_size=(2,2),strides=(2,2)))
model.add(Conv2D(filters=64, kernel_size=(3,3), activation="relu", padding="same"))
model.add(MaxPooling2D(pool_size = (2,2), strides =(2,2)))
model.add(Conv2D(filters=128, kernel_size=(3,3), activation="relu", padding="same"))
model.add(MaxPooling2D(pool_size = (2,2), strides =(2,2)))
model.add(Conv2D(filters=256, kernel_size=(3,3), activation="relu", padding="same"))
model.add(MaxPooling2D(pool_size = (2,2), strides =(2,2)))
model.add(Flatten())
model.add(Dense(units=64,activation='relu'))
model.add(Dropout(rate=0.2))
model.add(Dense(units=1,activation='sigmoid'))
# コンパイル→ニューラルネットワークモデルの生成終了
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'])]
# ニューラルネットワークの構造確認
model.summary()
# モデルの学習
model.fit_generator(train_generator, validation_data=val_generator, epochs=10)
【パラメーターについて】
ハイパーパラメータの設定値は、分析速度や結果に影響しますのでここの設定は重要です。
-
filters:生成する特徴マップの数。小さすぎて必要な特徴が抽出できないと精度に影響します。大きすぎると過学習しやすい。
→2の累乗値がとられることが多い。フィルター数が多いほど計算量が増え時間がかかる。 -
kernel_size:カーネル(畳み込みに使用する重み行列)の大きさ。小さすぎると、ごく小さな特陵も検出できなくなる。大きくしすぎてもよくない。
→あまり意識せず、全て(3,3)に設定した場合、解析時間が長くなりすぎてしまいました。そこで、畳み込み層の一層目のみ(7,7)に設定。 -
strides:特徴を検出する間隔、つまりカーネルを動かす距離のことを言います。小さいほど細かく抽出する為よい。
→デフォルト設定の(1,1)で解析した際、時間がかかりすぎてしまった為、(2,2)に変更。 -
padding:畳み込んだときの画像の縮小を抑える為、入力画像の周囲にピクセルを追加。
→デフォルト設定を使用 -
pool_size:一度にプーリングを適用する領域のサイズ。基本的に(2,2)
→デフォルト設定を使用
2.モデルの学習
%%time
filepath = "./model/model-{epoch:02d}.h5"
# エポックごとにモデルを保存するかチェック
checkpoint = ModelCheckpoint (
filepath=filepath,
monitor='val_loss', #評価をチェックする対象
verbose=1,
save_best_only=True, # 精度が向上した場合のみ保存する。
mode='min',
period=1 )
H = model.fit(
train_generator,
validation_data=val_generator,
epochs=20,
callbacks=[checkpoint],
)
モデル学習する際に、model.fit()のcallbacksにModelCheckpointを指定することで、Epochごとにモデルを監視し保存してくれます。save_best_onlyをTrueにすることで評価対象のVal_lossが向上した場合にのみ、モデルを保存するようにしています。
これにより、適当にEpoch数を決めて過学習となってしまった場合でもVal_lossが最小の時のモデルが保存されているので便利です。
今回はEpoch1,2,3,4,6,10,11,20が保存されていました。
学習自体は21min程度終わっております。
初めての分析だったことから、パラメーターのノウハウや指標がなく、設定値は何度も変更しました。7~8hかけて精度が全く出なかったこともあり、ハイパーパラメーターの設定は大事だと気付かされました。
3. グラフのプロット
fig = plt.figure(figsize=(8, 6))
plt.plot(H.history['accuracy'], label='acc', ls='-', marker='o')
plt.plot(H.history['val_accuracy'], label='val_acc', ls='-', marker='x')
plt.plot(H.history['loss'], label='loss', ls='-', marker='o')
plt.plot(H.history['val_loss'], label='val_loss', ls='-', marker='x')
plt.title('Model Evaluaton')
plt.xlabel('epoch')
plt.ylabel('')
plt.legend(['acc', 'val_acc', 'loss', 'val_loss'])
plt.grid(color='gray', alpha=0.2)
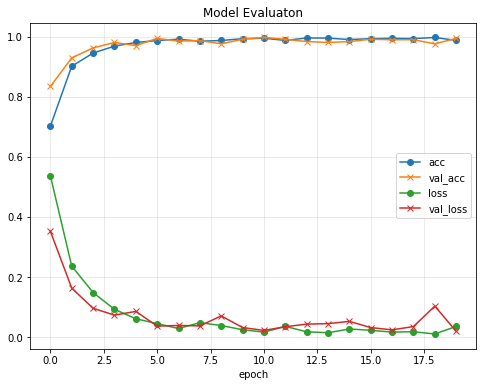
ニューラルネットワークの学習では損失関数の値を小さくするように学習が進んでいくため、一般には損失値が小さいほど良いモデルであると考えられます。
グラフより訓練データとテストデータの両方に対してほぼ同等な性能を発揮できていると思われるので、良い感じに学習できていそうです。
検証
1. モデルの検証
テストデータに対する精度を評価していきます。識別指標には以下のようなものがあります。
正解率 (Accuracy)精度 (Precision)検出率 (Recall)F値 (f1-score)
scikit-learnのclassification_reportを使用することで、簡単に確認できます。
1/1 [==============================] - 3s 3s/step
precision recall f1-score support
0 0.98 1.00 0.99 262
1 1.00 0.99 0.99 453
accuracy 0.99 715
macro avg 0.99 0.99 0.99 715
weighted avg 0.99 0.99 0.99 715
2. 混同行列
2クラス分類の評価結果を表現する方法で、最も包括的な方法の一つとして混同行列があります。sklearnのconfusion_matrix関数を使用して、分類の精度を視覚的に確認することができるので、便利です。
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
best_model = models.load_model("./cnn_casting_inspection3.hdf5")
y_pred_proba = best_model.predict(test_generator, verbose=1)
threshold = 0.5
y_pred = y_pred_proba >= threshold
cmd = ConfusionMatrixDisplay(confusion, [0,1])
cmd.plot(cmap=plt.cm.Blues)
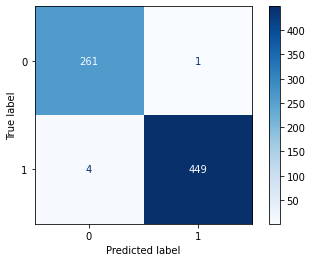
- 混同行列の主対角成分の要素 :正確にクラス分類されたサンプルの個数
- それ以外の要素 :実際とは違うクラスに分類されたサンプルの個数
結果を確認すると、分類はできていそうですが精度が100%とはいきませんでした。
同様のモデルを使用して何度か学習をやり直したのですが、必ず1~5枚程度は正しく分類できていないため、この構造ではこれが限界値だと思われます。
考察とまとめ
初めてCNNを用いた画像分析を行ってみました。今回使用したデータはきれいに成形されていたことから、複雑な前処理等を行わなくても比較的良い精度で分類を行うことができました。実際はここまできれいに成形された画像ばかりでなく、ノイズが多いものもあると思われるので、精度を出すことが難しくなると思います。
精度が100%に至らなかった原因として、多少なりともぼやけているものや、明るさが暗いものも含まれている為、そこが精度に影響したのではないかと考えています。画像を使って学習させるにも、良質な画像の入手が必要になると思いました。
実際に本システムを運用していくとなると、誤検出によるミスは顧客との大きな信頼損失につながりますので、完全に機械だけに任せるのはまだまだ精度を上げる必要があります。現状だと、精度が100%ではないので、検査員を支援するツールや省力化手法のひとつとしては使用できると思います。
今後は、別の手法で画像を正規化(白色化、標準化)したり、画像を加工し水増した場合どうなるのか等を確認してみたいと考えています。
更に精度を上げる手法として、何かございましたらアドバイスをいただければと思います。
最後までご精読ありがとうございました。
画像の引用
[Convolutional Neural Networkをゼロから理解する]
(https://deepage.net/deep_learning/2016/11/07/convolutional_neural_network.html)