前提
- もともと、CUDAはRuntimeとDriverのバージョンのマッチが厳しく、きっちり合わせないと使えないものだった
- nvidia-dockerによってポータビリティは上がったものの、新しいCUDAのバージョンを使うためには当然ホストのカーネルのドライバを上げる必要があった
Forward Compatibilityとは
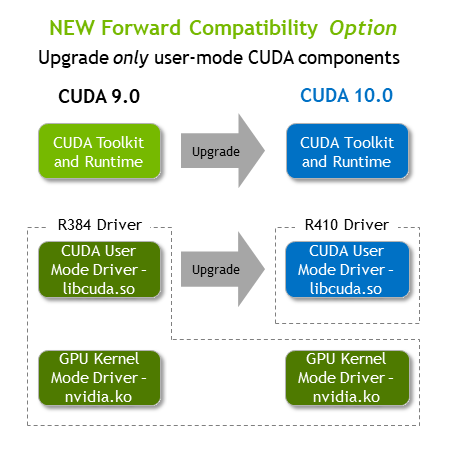
ドライバのうち、カーネル部分はそのままでユーザーランドの部分を入れ替えるだけで新しいCUDAのバージョンが使えるようになる機能である(CUDA 10.0より使用可能)
つまり、これが使えるとホストはそのままでコンテナの中身を新しくするだけで新しいCUDAのバージョンが使える
実際にやってみる
ホスト環境
- Ubuntu 16.04
- Tesla M60
- NVIDIA Driver 384.145
- CUDA 9.0.176
- Docker 18.09.0
- nvidia-docker 2.0.3
$ nvidia-smi
Wed Nov 21 12:30:33 2018
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 384.145 Driver Version: 384.145 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla M60 Off | 00000000:00:05.0 Off | Off |
| N/A 45C P0 38W / 150W | 0MiB / 8123MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
$ ./deviceQuery
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "Tesla M60"
CUDA Driver Version / Runtime Version 9.0 / 9.0
CUDA Capability Major/Minor version number: 5.2
Total amount of global memory: 8124 MBytes (8518238208 bytes)
(16) Multiprocessors, (128) CUDA Cores/MP: 2048 CUDA Cores
GPU Max Clock rate: 1178 MHz (1.18 GHz)
Memory Clock rate: 2505 Mhz
Memory Bus Width: 256-bit
L2 Cache Size: 2097152 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)
Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Supports Cooperative Kernel Launch: No
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 0 / 5
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 9.0, CUDA Runtime Version = 9.0, NumDevs = 1
Result = PASS
見ての通りバリバリのCUDA 9.0環境
コンテナ
建てる
$ docker run --runtime=nvidia -it nvidia/cuda:10.0-devel bash
コンテナ内
# nvidia-smi
Wed Nov 21 12:36:38 2018
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 384.145 Driver Version: 384.145 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla M60 Off | 00000000:00:05.0 Off | Off |
| N/A 45C P0 39W / 150W | 0MiB / 8123MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
当たり前だが、ドライバのバージョンは384.145のまま
# apt update
# apt install cuda-samples-10-0
# /usr/local/cuda/bin/cuda-install-samples-10.0.sh ~/
# cd ~/NVIDIA_CUDA-10.0_Samples/1_Utilities/deviceQuery
# make run
/usr/local/cuda-10.0/bin/nvcc -ccbin g++ -I../../common/inc -m64 -gencode arch=compute_30,code=sm_30 -gencode arch=compute_35,code=sm_35 -gencode arch=compute_37,code=sm_37 -gencode arch=compute_50,code=sm_50 -gencode arch=compute_52,code=sm_52 -gencode arch=compute_60,code=sm_60 -gencode arch=compute_61,code=sm_61 -gencode arch=compute_70,code=sm_70 -gencode arch=compute_75,code=sm_75 -gencode arch=compute_75,code=compute_75 -o deviceQuery.o -c deviceQuery.cpp
/usr/local/cuda-10.0/bin/nvcc -ccbin g++ -m64 -gencode arch=compute_30,code=sm_30 -gencode arch=compute_35,code=sm_35 -gencode arch=compute_37,code=sm_37 -gencode arch=compute_50,code=sm_50 -gencode arch=compute_52,code=sm_52 -gencode arch=compute_60,code=sm_60 -gencode arch=compute_61,code=sm_61 -gencode arch=compute_70,code=sm_70 -gencode arch=compute_75,code=sm_75 -gencode arch=compute_75,code=compute_75 -o deviceQuery deviceQuery.o
mkdir -p ../../bin/x86_64/linux/release
cp deviceQuery ../../bin/x86_64/linux/release
./deviceQuery
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "Tesla M60"
CUDA Driver Version / Runtime Version 10.0 / 10.0
CUDA Capability Major/Minor version number: 5.2
Total amount of global memory: 8124 MBytes (8518238208 bytes)
(16) Multiprocessors, (128) CUDA Cores/MP: 2048 CUDA Cores
GPU Max Clock rate: 1178 MHz (1.18 GHz)
Memory Clock rate: 2505 Mhz
Memory Bus Width: 256-bit
L2 Cache Size: 2097152 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)
Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: No
Supports Cooperative Kernel Launch: No
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 0 / 5
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 10.0, CUDA Runtime Version = 10.0, NumDevs = 1
Result = PASS
以上のようにCUDA 10.0でコンパイルでき、もちろんランタイムもCUDA 10.0で動く
注意点
- TeslaブランドのGPUのみサポート
- 特定バージョンのドライバのみサポート(LTS Driver?)
- 384.111, 384.145 (現状)