この記事はプロトアウトスタジオ アドベントカレンダー2019 3日目です
プロトアウトスタジオ一期生のおのです!
はじめに
以前投稿した記事の 「しらける」を「ホワイトキック」に自動変換したかったストーリーの改善を考えたときにword2vecを使用しようと思ってました。
word2vecやらなきゃなぁって考えてたところ、別の話で「ナダルリバースエボリューション」(懐かしい)の話が出て…
あ、これ、再現できるかも。
と思ってしまったのでやるしかないのかなこれは。
ということでnodejsを使って勉強がてらやってみました。
アドベントカレンダーのネタにもなるし…
ナダルリバースエボリューションって?
https://matome.naver.jp/odai/2145175669028461001
https://matome.naver.jp/odai/2145762091988093801
まとめられてますねぇ
例えば
- 「えんぴつ」→「シャーペン」
- 「松本人志」→「ボブサップ」
word2vec的に考えると
- 「えんぴつ」→「シャーペン」は、なんか近代的に?機能が追加された感じですかね
- 「松本人志」→「ボブサップ」は、松本人志の特徴の筋肉部分をもっと増やした感じで、他の部分はほぼほぼ考えられてない感じ
これを整理する前は、進化前のwordのネガティブ部分をポジティブに変えればいいかなと考えてたがそうじゃなく、進化前の特徴をより強調させたり、増やしたり、ベテランにしたり、えらくしたりっぽいですね
これをword2vecを利用して再現できるのか
環境
- mac 10.14.6
- node 12.3.1
- node-word2vec 1.1.4
実装
モデルデータの用意
データを作るところからやるのもできますが、自分は以下のサイトからお借りいたしました。
http://www.cl.ecei.tohoku.ac.jp/~m-suzuki/jawiki_vector/
モデル読み込みテスト
npm i word2vec
でライブラリをインストール
上記のサイトからダウンロードしたモデルを同じディレクトリに入れ、
const w2v = require("word2vec");
console.log("モデル読み込み開始");
w2v.loadModel("./entity_vector/entity_vector.model.txt", (error, model) => {
console.log("モデル読み込み完了");
console.log(model);
});
どうでしょう
自分はここでエラーが起きました。
エラーをガッツリ載せますが
<--- Last few GCs --->
[49239:0x10284f000] 16619 ms: Mark-sweep 1991.1 (2087.8) -> 1981.1 (2090.2) MB, 135.4 / 0.0 ms (average mu = 0.163, current mu = 0.135) allocation failure scavenge might not succeed
[49239:0x10284f000] 16862 ms: Mark-sweep 1993.9 (2090.2) -> 1984.3 (2091.8) MB, 220.8 / 0.0 ms (average mu = 0.125, current mu = 0.092) allocation failure scavenge might not succeed
<--- JS stacktrace --->
==== JS stack trace =========================================
0: ExitFrame [pc: 0x100e0b7a6]
Security context: 0x2f707e39a2f1 <JSObject>
1: ondata [0x2f7098fad841] [readline.js:~169] [pc=0xcbb89e0fa1f](this=0x2f7098fad8f9 <ReadStream map = 0x2f70bfdcdc09>,0x2f70d8f5fa29 <Uint8Array map = 0x2f70bfda56b9>)
2: emit [0x2f707e3d35d9] [events.js:~149] [pc=0xcbb89e030bd](this=0x2f7098fad8f9 <ReadStream map = 0x2f70bfdcdc09>,0x2f707e3806f9 <String[#4]: data>)
3: arguments adaptor frame: 2->1...
FATAL ERROR: Ineffective mark-compacts near heap limit Allocation failed - JavaScript heap out of memory
1: 0x1000760ab node::Abort() [/Users/takayuki/.nvm/versions/node/v12.3.1/bin/node]
2: 0x1000767ec node::errors::TryCatchScope::~TryCatchScope() [/Users/takayuki/.nvm/versions/node/v12.3.1/bin/node]
3: 0x100161327 v8::Utils::ReportOOMFailure(v8::internal::Isolate*, char const*, bool) [/Users/takayuki/.nvm/versions/node/v12.3.1/bin/node]
4: 0x1001612bc v8::internal::V8::FatalProcessOutOfMemory(v8::internal::Isolate*, char const*, bool) [/Users/takayuki/.nvm/versions/node/v12.3.1/bin/node]
5: 0x10053fc25 v8::internal::Heap::FatalProcessOutOfMemory(char const*) [/Users/takayuki/.nvm/versions/node/v12.3.1/bin/node]
6: 0x100540d13 v8::internal::Heap::CheckIneffectiveMarkCompact(unsigned long, double) [/Users/takayuki/.nvm/versions/node/v12.3.1/bin/node]
7: 0x10053e713 v8::internal::Heap::PerformGarbageCollection(v8::internal::GarbageCollector, v8::GCCallbackFlags) [/Users/takayuki/.nvm/versions/node/v12.3.1/bin/node]
8: 0x10053c3cf v8::internal::Heap::CollectGarbage(v8::internal::AllocationSpace, v8::internal::GarbageCollectionReason, v8::GCCallbackFlags) [/Users/takayuki/.nvm/versions/node/v12.3.1/bin/node]
9: 0x100546eb5 v8::internal::Heap::AllocateRawWithLightRetry(int, v8::internal::AllocationType, v8::internal::AllocationAlignment) [/Users/takayuki/.nvm/versions/node/v12.3.1/bin/node]
10: 0x100546f2f v8::internal::Heap::AllocateRawWithRetryOrFail(int, v8::internal::AllocationType, v8::internal::AllocationAlignment) [/Users/takayuki/.nvm/versions/node/v12.3.1/bin/node]
11: 0x100518ac5 v8::internal::Factory::NewRawTwoByteString(int, v8::internal::PretenureFlag) [/Users/takayuki/.nvm/versions/node/v12.3.1/bin/node]
12: 0x1005183df v8::internal::Factory::NewStringFromUtf8(v8::internal::Vector<char const>, v8::internal::PretenureFlag) [/Users/takayuki/.nvm/versions/node/v12.3.1/bin/node]
13: 0x1001841c5 v8::String::NewFromUtf8(v8::Isolate*, char const*, v8::NewStringType, int) [/Users/takayuki/.nvm/versions/node/v12.3.1/bin/node]
14: 0x1000f897d node::(anonymous namespace)::MakeString(v8::Isolate*, char const*, unsigned long, node::encoding) [/Users/takayuki/.nvm/versions/node/v12.3.1/bin/node]
15: 0x1000f88f3 node::StringDecoder::DecodeData(v8::Isolate*, char const*, unsigned long*) [/Users/takayuki/.nvm/versions/node/v12.3.1/bin/node]
16: 0x1000f910d node::(anonymous namespace)::DecodeData(v8::FunctionCallbackInfo<v8::Value> const&) [/Users/takayuki/.nvm/versions/node/v12.3.1/bin/node]
17: 0x100e0b7a6 Builtins_CallApiCallback [/Users/takayuki/.nvm/versions/node/v12.3.1/bin/node]
18: 0xcbb89e0fa1f
19: 0xcbb89e030bd
20: 0x100e03c3c Builtins_ArgumentsAdaptorTrampoline [/Users/takayuki/.nvm/versions/node/v12.3.1/bin/node]
21: 0xcbb89e0cbda
[1] 49239 abort node app.js
実行時にメモリが足りないそうです。
https://qiita.com/shohei_ot/items/5fbc7641fa2ebae9c911
なので実行を
node --max_old_space_size=8192 app.js
にしてます。4096でも足りなかったでした…
おすすめはこの実行コマンドをpackage.jsonのscriptsに入れておくことをおすすめします。
https://qiita.com/minase_tetsuya/items/986feac7150ed74e13d8
しかも自分はmacbookproなのですが、1分弱は読み込みにかかりますね。
進化させよう
word2vecの機能を見てみよう
技術はなんとなく使えそうになりました。
ここを参考にnode-word2vecでできることをまとめてみます。
loadModel後に取得できるmodelデータのメソッドには
- .similarity( word1, word2 ) 単語と単語の近さを取得
- .mostSimilar( phrase[, number] ) 引数の単語に近い単語を取得
- model.analogy( 'woman', [ 'man', 'king' ], 10 ); word2vecらしいやつ。下で説明
- .getVector( word )
vecterデータを取得 - .getNearestWord( vec )
vecterデータから単語取得
vecterデータのプロパティとメソッドは
- .word 単語がはいってる
- .values vecterのデータが配列で
- .add( wordVector ) vecterの足し算 あとでも記述するが、単語の意味の足し算にはならなそう
- .subtract( wordVector ) vecterの引き算
analogyですが、よく「王様 - 男 + 女性 = 女王」という例がありますが、
こちらでは、「男性における王様は女性における〇〇」として表現してます。
進化前の単語をユーザー入力に
実行のたびにモデルを読み込むので時間がかかる!
ので、実行後にユーザー入力に受け取ってみます。
const rl = require("readline").createInterface(process.stdin, process.stdout);
rl.on("line", (str) => {
console.log("get:" + str);
});
これをもとに
const w2v = require("word2vec");
console.log("モデル読み込み開始");
w2v.loadModel("./entity_vector/entity_vector.model.txt", (error, model) => {
console.log("モデル読み込み完了", model);
console.log("進化させたいものを入力してください");
const rl = require("readline").createInterface(process.stdin, process.stdout);
rl.on("line", function(str) {
if (model) {
try {
console.log(model.mostSimilar(str));
} catch (e) {
console.log(e);
}
}
});
});
try catchしている理由は、modelデータにない単語を入力してしまうとエラーで落ちてしまうからです。
そしたらまた1分ロード読み込みまちは嫌なので
これを基礎に、以下に記載していくコードは基本このtry内のことです
鉛筆におけるシャーペンを進化前における進化後
strはユーザーの入力値で、進化前の単語ということです
console.log(model.analogy(str, ["鉛筆", "シャーペン"], 3));
結果
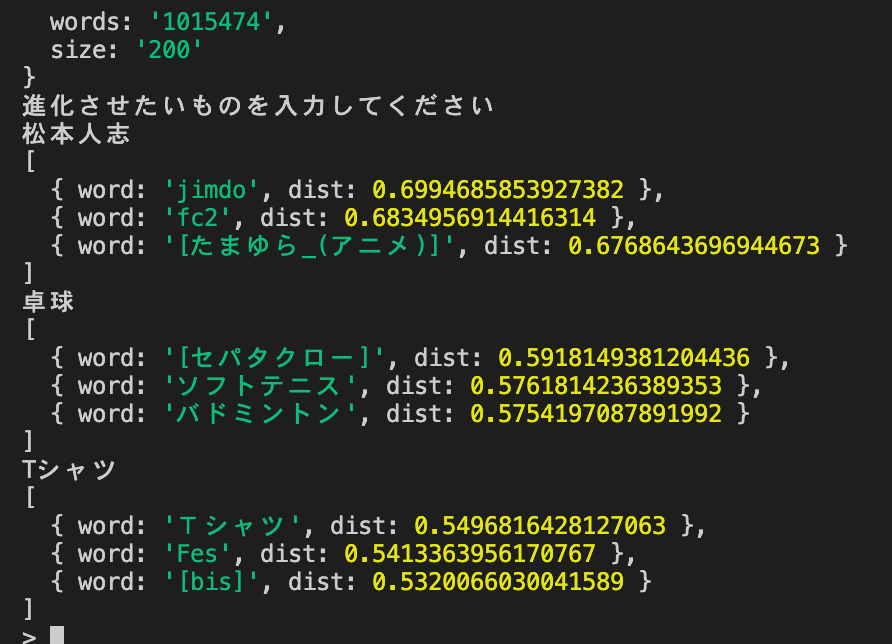
松本人志が難しいのはなんとなくわかりますが、人以外ばかり
卓球はなんとなく…セパタクローとかナダルが言ったらたしかに面白いかも
弱いにおける強いを進化前における進化後
console.log(model.analogy(str, ["弱い", "強い"], 3));
結果
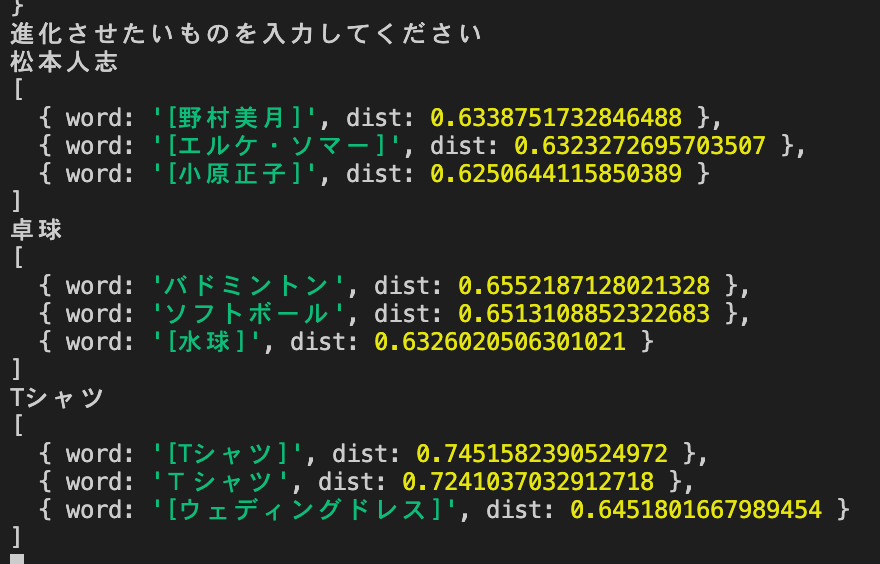
松本人志も人にはなったし、卓球もブレずにスポーツだがセパタクローを超えない。
Tシャツはウェディングドレスってきたら流石に強すぎる。が、面白いかも
弱いではなくて、なにか進化前のものの特徴的な部分をより強くだと考えてたけど、これはこれでいいのかも…
「すごい」のvecterを進化前に足して進化後を作る
let evoVector = model.getVector("すごい");
let vec = model.getVector(str).add(evoVector);
console.log(model.getNearestWord(vec));
結果
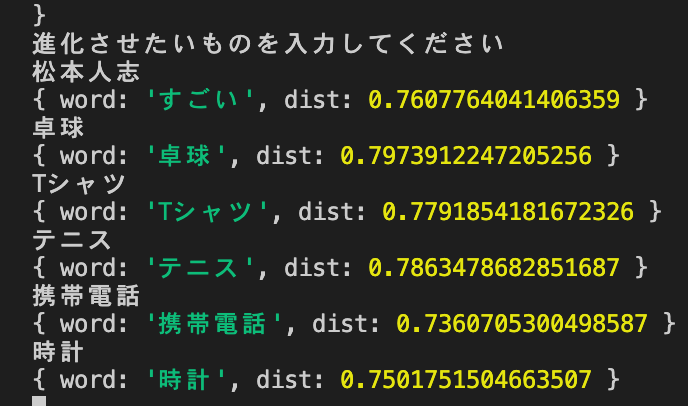
これは失敗です。
vecterの足し算は単語の足し算とは違うのかなぁ多分足し算しちゃって1を超えちゃったりしたのかも
すごい+進化前で進化後を作る
console.log(model.mostSimilar("すごい" + str));
結果

これは自分がアホでした。
「すごい松本人志」なんて単語はあるはずない。
ナダル(人)が思う進化前と進化後のvectorの差で作る
一番最初に試した鉛筆とシャーペン。この2つの単語がもっとたくさんあって、そこから選ぶとか、そもそもそれらの差を求めれば進化とはに迫る検証ができるのかと思いました。
まとめサイトからナダル発言の進化前と進化後を集めてvectorの差を取るぞ!
このvectorデータこそが人が進化するのに必要なデータかもしれない(錯乱)
では、スプレットシートにまとめてみました。

(映っちゃいけない人が…大丈夫でしょう)
ということでやってみたんですが、
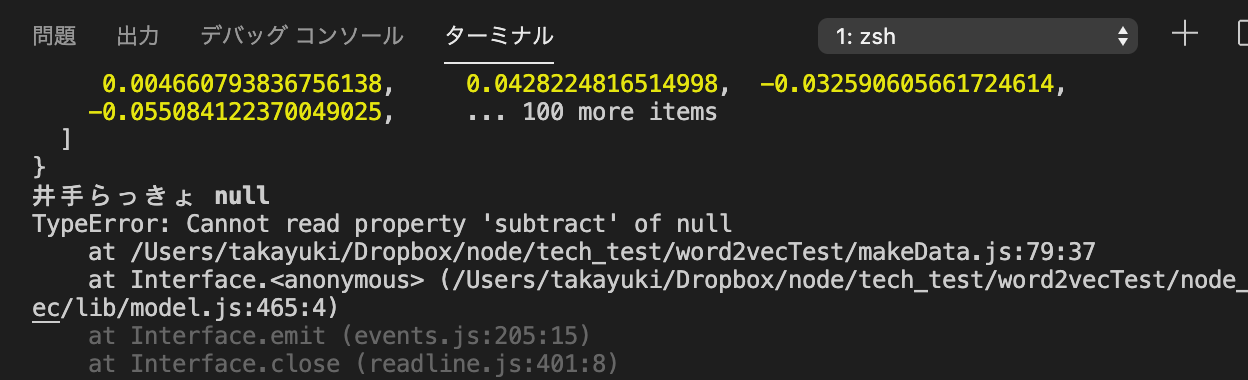
うーん人物を進化させることが多いらしく、単語として登録されていないものばかりであまり有用ではありませんでした。
残念。
たとえこれで進化のvectorデータが取れたとしても、それを進化前の単語に単純に足すのは結局良くないんじゃないのかなぁ…うーむ
まとめ
すごく勉強になったが、簡単に進化はできなかった。
進化で思いついたけど、ヒトカゲ→リザードンとかアグモン→グレイモンとかも出せたらいいね
ちなみにナダルの進化は圧倒的に見た目で決めてますよね。
そりゃこんな結果になるね
次は tseigoさん です。paiza.cloudで何かしてくれるそうです。