この記事はKubernetes Advent Calendar 2016の13日目の記事です。ちょうどこの記事の投稿日(12/13)に Kubernetes v1.5.0がリリースされました ![]()
日夜、進化し機能が増えているKubernetesについて、開発中のものも含めv1.5時点での主な機能の一覧をまとめてみました。
スケーラビリティ関連
クラスタリング機能
Kubernetesのクラスタリング機能はマスターコンポーネント(kube-apiserver,etcd,kube-scheduler,kube-controller-manager)とNodeコンポーネント(kubelet,kube-proxy)から構成されます。
クラスタが対応するノード数に関してはKubeCon 2016でMarek Grabowskiさんが発表した2000 Nodes and Beyond: How We Scaled Kubernetes to 60,000-Container Clusters and Where We're Going Nextというセッションの資料がまとまっています。
Kubernetesの構造上、各種コンポーネントはAPIサーバーを参照して処理を行うため、スケーラビリティの向上は主にAPIサーバーを中心に行われています。
2000 Nodes and Beyond のスライドより引用
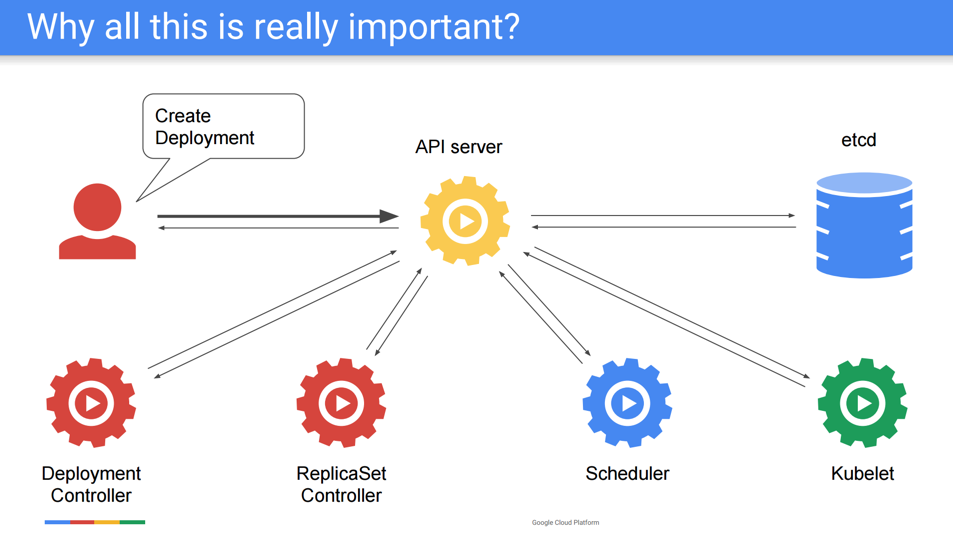
2000 Nodes and Beyondのスライドによると、Kubernetesのバージョンごとの対応するノード数は下記のようになっています。
| バージョン | 対応ノード数 | 主な取り組み |
|---|---|---|
| v1.0 | 100 | 内部の型変換(versioned -> unversioned)をreflectからコード生成にした |
| v1.1 | 250 | APIサーバーのetcdのwatchを1キーにつき1watchにまとめるようにした(cacher層) |
| v1.2 | 1,000 | kubemarkというベンチマークができた |
| v1.3 | 2,000 | APIサーバーの通信で内部クライアントはjsonからprotobufを使うようになった |
| v1.4 | 2,000 | |
| v1.5 | ? | etcd v2からv3への移行が予定されていたが見送りに |
参考
- Kubernetes architecture
- 2000 Nodes and Beyond: How We Scaled Kubernetes to 60,000-Container Clusters and Where We're Going Next
- etcd v3 as storage backend for APIServer #44
- Kubernetes: 構成コンポーネント一覧
- Kubernetes: コンテナが起動するまでの各コンポーネントの流れ
複数クラスタ連携 (Federated Kubernetes)
Federated Kubernetesは複数のKubernetesを連携させる機能です。Ubernetes("uber-"は"超える"の意味の接頭辞)とも呼ばれます。AWS, GCPなどのクラウドプロバイダーやAvaiability Zoneをまたがってクラスタを連携させることで、可用性の向上やクラスタサイズの拡張を実現することができます。鋭意開発が進められており、v1.5でもDeployment, ConfigMapなどのリソースが対応されました。
@toshitanianさんが書かれたKubernetes Federationの今とこれからという記事が素晴らしくまとまっています。
参考
アプリケーションの水平オートスケール (HorizontalPodAutoscaler)
HorizontalPodAutoscalerという機能によりアプリケーションの水平(horizontal)オートスケールがサポートされます。アプリケーション(Pod)の数がCPU使用率等の計測値を用いて自動的に調整される機能です。計測値はデフォルトで用意されるCPU使用率の他、alpha機能で独自のメトリクスを使用することができます。
将来的にはアプリケーションの垂直(Vertical)スケールの機能も考えられているようです。垂直スケールの必要性に関してはKubeCon 2016でKubernetesのコア開発者であるTim Hockinさんが発表したEverything You Ever Wanted To Know About Resource Scheduling... Almostが詳しいです。
参考
アプリケーションのデプロイ・実行
アプリケーションの単位の提供 (Pod)
PodはKubernetesでアプリケーションを動かす最小単位で、Kubernetesの一番基本となるリソースです。同じプロセス空間、ネットワーク、ストレージを共有する1つ以上のコンテナから構成されます。これによりログコレクタのような補助プロセスを含めて1つのアプリケーションとしてデプロイすることができます。
アプリケーションのレプリカ数管理 (ReplicationController / ReplicaSet)
ReplicationController及びReplicaSetはアプリケーション(Pod)のレプリカ数を管理するための仕組みです。クラスタで動くPodの数をユーザーが望むレプリカ数(desired state)に近づける形で動作します。オートヒーリングの仕組みもこの機能で実現しています。
ReplicationControllerとReplicaSetの違いは現状ほとんどなく、ReplicationControllerという名前が長く、リソース名にcontrollerとついて紛らわしいといったことからReplicaSetが作られました。
参考
- What is a replication controller?
- What is a Replica Set?
- Create ReplicaSet #3024
- Kubernetes: コンテナが起動するまでの各コンポーネントの流れ
ローリングアップデートなどのデプロイ管理 (Deployment)
Deploymentはデプロイを管理する仕組みでローリングアップデートやロールバックの機能を提供します。内部的にはReplicaSetを使用しており、ローリングアップデートは新旧2つのReplicaSetを作って切り替えていく形を取っています。
参考
ステートフルアプリケーションの管理 (StatefulSet)
StatefulSet(v1.4まではPetSet)はステートフルアプリケーションをサポートするための機能です。ReplicaSetと違って管理するPodの1つづつがそれぞれの名前と状態を持てることになります。具体的にはetcdやzookeeperのようにそれぞれのメンバー(Pod)が状態を持ち識別が必要なアプリケーションをデプロイする場合が想定されています。
なおPetSetからStatefulSetに名前が変更された経緯はPlease consider changing the name of PetSet before General Availability #27430というissueで議論されていました。
参考
ノード毎のデーモンのデプロイ管理 (DaemonSet)
DaemonSetはクラスタの各ノードで特定のデーモンを実行する機能です。例えばcephのようなストレージのデーモンや、fluentdのようなログコレクタ、linkerdのような透過プロクシーなどをノードごとに動かす場合に利用します。
参考
ジョブ・バッチ処理 (Job)
Jobは単独のジョブ処理(明示的な終了がある処理)を行うための機能です。
スケジュールジョブ (CronJob)
CronJob(v1.4まではScheduledJob)を使うとcronのようなスケジュールに基づく処理を実行することができます。
@koudaiiiさんのCronJob(ScheduledJob)の記事がとてもよくまとまっています。
ネットワーク・サービス提供
サービスディスカバリ & ロードバランシング (Service / KubeDNS / kube-proxy)
Serviceはクラスタ内のサービスディスカバリとロードバランシングを提供する機能です。ServiceはPodをLabelとSelectorという仕組みで選択し、配下のPod群に対してロードバランスする仮想的なIPアドレス(ClusterIP)を提供します。また内部のDNS(KubeDNS)に自動的にドメインの登録を行いサービスディスカバリの機能を提供します。
ロードバランシングはノード毎にデーモンとして動くkube-proxyがServiceの情報をiptablesに設定することで実装されています(デフォルトの挙動)。そのため通常の構成ではClusterIPはクラスタの外部から通信を受けることはできません。 クラスタ外部からの通信を受けるには通常Serviceのtype=LoadBalancerの指定か、IngressリソースによるL7ロードバランサなどの設定が必要になります。
クラウドプロバイダのL4ロードバランサとの連携(Service.Type=LoadBalancer)
Serviceのtype=LoadBalancerの指定により外部のL4ロードバランサによってサービスを公開することができます。この指定がなされると、自動的にServiceに連携したクラウドプロバイダ(AWS, GCPなど)ごとのロードバランサが作られます。
参考
L7ロードバランサとの連携 (Ingress)
Ingressはクラスタ外部(主にインターネット)からの通信を受けるL7ロードバランサに必要となる設定情報をリソースとして表現する機能になります。
internet
|
[ Ingress ]
--|-----|--
[ Services ]
Service.Type=LoadBalancerとの主な違いは下記になります
- L7ロードバランサであること(
Service.Type=LoadBalancerはL4)- ホスト名やパスによるルーティング、TLS終端が可能
-
Ingress自体はリソースとしてL7ロードバランサの情報をリソースとして表現するだけのもの- 実際のロードバランサの設定はIngress ControllerというIngressリソースを監視する別の仕組みで行われる
- これによりロードバランサの情報と具体的なロードバランサが分離される
Ingress Controllerの実装としては下記のようなものがあります
- nghttpx Ingress Controller
- Nginx Ingress Controller
- HTTP Load Balancer (Google Container Engine)
参考
プラガブルなネットワーク機能 (CNI)
KubernetesのネットワークはContainer Network Interface(CNI)というコンテナネットワークの共通インタフェースをプラグインとしてサポートしています。Canal(Calico, Flannel), Weave Netなどのネットワークプラグインが存在します。
参考
ネットワークポリシーの制御 (NetworkPolicy)
NetworkPolicyはNamespaceごとのネットワーク設定や、Podのアクセス制御の機能を提供します。KubernetesのネットワークがNetworkPolicyをサポートしない場合はこの設定は無視されます。
マニュアルの例(Namespaceごとのネットワーク設定)
kind: Namespace
apiVersion: v1
metadata:
# アノテーションで分離の設定をいれる
annotations:
# 全てのPod外からの通信を拒否する。1.5時点でのサポートはDefaultDenyだけ
net.beta.kubernetes.io/network-policy: |
{
"ingress": {
"isolation": "DefaultDeny"
}
}
マニュアルの例(NetworkPolicy)
kind: NetworkPolicy
apiVersion: extensions/v1beta1
metadata:
name: access-nginx
spec:
# 制限する対象
podSelector:
matchLabels:
run: nginx
ingress:
# 許可する対象
- from:
- podSelector:
matchLabels:
access: "true"
参考
リソース管理
Podのリソース制御 (requests, limits)
spec.containers[].resourcesのrequests, limitsの指定によってPodのリソース(現状はCPUとメモリ)の制御が行えます。requestsは最低限確保して欲しい値を指定し、limitsは使用できる最大の値を指定します。
以下はマニュアルの例より
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: db
image: mysql
# リソース制御の指定
resources:
# 最低限確保してほしいCPU、メモリ
requests:
memory: "64Mi"
# 0.25コア分
cpu: "250m"
# 使用できる最大の値
limits:
# メモリの場合はこれを超えるとターミネートされる
memory: "128Mi"
cpu: "500m"
# 以下省略
Namespaceのリソース制御 (ResourceQuota)
ResourceQuotaはNamespace単位でのリソース制御の仕組みを提供します。CPU、メモリのリソースの他に、オブジェクトの数(PodやServiceの数)をNamespaceごとに設定することができます。
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
spec:
hard:
# リソース数の制限(ここではPod数)
pods: "4"
# 最低限確保してほしいCPU、メモリ
requests.cpu: "1"
requests.memory: 1Gi
# 使用できるCPU、メモリの最大値
limits.cpu: "2"
limits.memory: 2Gi
利用状況はkubectl describe ns NAMESPACEで以下のように確認することができます。
$ kubectl describe ns myspace
Name: myspace
Labels: <none>
Status: Active
Resource Quotas
Name: compute-resources
Resource Used Hard
-------- --- ---
limits.cpu 0 2
limits.memory 0 2Gi
pods 0 4
requests.cpu 0 1
requests.memory 0 1Gi
No resource limits.
参考
設定管理
シークレット管理 (Secret)
Secretはパスワードや秘密鍵といった秘密情報を扱うための機能です。Secretを使うことでアプリケーションの定義に秘密情報を含まなくてよくなります。またアプリケーションからAPIサーバーにアクセスするためのServiceAccountのクレデンシャルにもSecretが使われており、これはVolumeとして自動的にマウントされるようになっています。
設定情報管理 (ConfigMap)
ConfigMapはアプリケーションの定義と別に設定情報を管理するための機能です。設定情報はPodに対して環境変数、、ファイル(Volume)、コンテナ引数といった形で渡すことができます。
認証・認可
認証
Kubernetesは下記のようないろいろなユーザ認証方式を提供しています。Kubernetes自体はユーザは管理しておらず(ServiceAccountは除く)、認証方法ごとに取得するユーザ名をそのまま利用する形を取っています。
| 方法 | 備考 |
|---|---|
| X509 Client Certs | クライアント証明書。CNがユーザ名、Oがグループになります。例: /CN=jbeda/O=app1/O=app2
|
| Static Token File | トークン認証。CSVで定義します。Authorization: Bearer $TOKENヘッダで認証。 |
| Static Password File | Basic認証。CSVで定義します。 |
| Service Account Tokens | ServiceAccountのJWT形式のトークン認証。 |
| OpenID Connect Tokens | OIDCのID Tokenによる認証。 |
| Webhook Token Authentication | 外部のWebAPIによる認証。 |
| Authenticating Proxy | 認証プロクシーを前段においてヘッダでユーザ名が渡される方式 |
| Keystone Password | Openstack Keystoneを使ったBasic認証。 |
参考
認可
Kubernetesでは認可も下記のように複数の方式が提供されています。認証されたユーザが何ができるかを管理する機能です。
| 方法 | 備考 |
|---|---|
| AlwaysDeny | 全て否認。テスト用です。 |
| AlwaysAllow | 全て承認。AlwaysAllowの設定です。認可が不要な場合に使います |
| ABAC | Attribute-Based Access Control。属性によるアクセス制御。Policyファイルによる静的な定義になるため、反映には再起動が必要です |
| RBAC | Roles-Based Access Contro。ロールによるアクセス制御。リソースを使った動的な管理が可能です |
| Webhook | 外部のWebAPIによる認可。 |
参考
ヘッドレスアカウント (ServiceAccount)
Kubernetesでは人に対する認証の他に、アプリケーションなど人を介さない(ヘッドレス)場合の認証としてServiceAccountという仕組みが用意されています。例えばKubernetes DashboardのようなアプリケーションがAPIサーバーとやり取りする場合にServiceAccountが使われています。
NamespaceごとにdefaultというServiceAccountが作られている他、kubectl create serviceaccountで独自のServiceAccountを作ることができます。
参考
APIサーバーのリクエスト制御 (AdmissionControl)
Admission ControlはKubernetesのAPIサーバーのリクエスト制御の機能です。APIリクエストに対して認証、認可を行ったあとのフェーズで、別途そのリクエストを受け入れるか制御を行います。また場合によって、リクエストの変更や別の操作を行います。
プラグイン形式で複数の制御の方法が用意されており、APIの起動オプション--admission-controlで有効にしたいものをカンマ区切りで指定します。
v1.5では下記のプラグインが用意されています。
- AlwaysAdmit
- AlwaysDeny
- AlwaysPullImages
- DefaultStorageClass
- DenyEscalatingExec
- DenyExecOnPrivileged
- ImagePolicyWebhook
- InitialResources
- LimitPodHardAntiAffinityTopology
- LimitRanger
- NamespaceAutoProvision
- NamespaceExists
- NamespaceLifecycle
- OwnerReferencesPermissionEnforcement
- PersistentVolumeLabel
- PodNodeSelector
- PodSecurityPolicy
- ResourceQuota
- SecurityContextDeny
- ServiceAccount
参考
セキュリティ
セキュリティ設定(SecurityContext)
SecurityContext, PodSecurityContext はContainer、Podに対して下記のセキュリティの設定を可能にします。
Podに対する設定 (PodSecurityContext)
- seLinuxOptions SELinuxのオプション
- runAsUser 実行するユーザのUID
- runAsNonRoot rootで動かさないことを保証する (デフォルトfalse)
- seLinuxContext SE Linuxのコンテキスト
- supplementalGroups Supplemental Groupの指定
- fsGroup ファイルシステムのGroupの指定
コンテナに対する設定 (SecurityContext)
- capabilities Linuxのcapabilitiesの設定
- privileged 特権モードで動かすかどうか (デフォルトfalse)
- seLinuxOptions SELinuxのオプション
- runAsUser 実行するユーザのUID
- runAsNonRoot rootで動かさないことを保証する (デフォルトfalse)
- readOnlyRootFilesystem read-onlyのルートファイルシステムかどうか (デフォルトfalse)
参考
Podのセキュリティポリシーの強制 (PodSecurityPolicy)
PodSecurityPolicyはPodに対してセキュリティポリシーを強制する機能です。AdmissionControlでPodSecurityPolicyプラグインを有効にすることで、下記のようなポリシーを全てのPodに強制することができます。
- runAsUser 実行するユーザのUID
- seLinuxContext SE Linuxのコンテキスト
- supplementalGroups Supplemental Groupの指定
- fsGroup ファイルシステムのGroupの指定
- volumes 使えるボリュームの種別の制限
参考
コンテナイメージのポリシー制御 (ImagePolicyWebhook)
ImagePolicyWebhookはKubernetesクラスタ上で動かすコンテナイメージを独自に制御したい場合に使える仕組みです。下記のようなユースケースが想定されているようです。
- 既知の脆弱性を含まないことを確認されたイメージだけを動かしたい
- 特定のベースイメージを使ったイメージだけを動かしたい
- レビュー済みのコードでビルドされたイメージだけを動かしたい
- 署名されたイメージだけを動かしたい
Image Policy Webhookは、ユーザが定義するWebAPIに対してそのPodに含まれるコンテナイメージの情報を渡し、実行可否をチェックする仕組みです。コンテナイメージ制御自体は自前のWebAPIで行う必要があります。Admission ControllerプラグインImagePolicyWebhookとして実装されています。
参考
外部システムとの連携
クラウドプロバイダの対応 (cloudprovider)
Kubernetesはクラウドプロバイダ(AWS, GCPなど)のロードバランサやインスタンス情報と連携する機能を持っています。v1.5時点では下記のクラウドプロバイダの実装が用意されています。
- Amazon Web Services
- Microsoft Azure
- CloudStack
- Google Compute Engine
- Mesos
- OpenStack
- oVirt
- Photon
- Rackspace
- vSphere
cloudproviderには下記のインタフェースが定義されており、プロバイダごとにこれを実装する形になっています。サポート状況はプロバイダによって異なります。
// Interface is an abstract, pluggable interface for cloud providers.
type Interface interface {
// LoadBalancer returns a balancer interface. Also returns true if the interface is supported, false otherwise.
LoadBalancer() (LoadBalancer, bool)
// Instances returns an instances interface. Also returns true if the interface is supported, false otherwise.
Instances() (Instances, bool)
// Zones returns a zones interface. Also returns true if the interface is supported, false otherwise.
Zones() (Zones, bool)
// Clusters returns a clusters interface. Also returns true if the interface is supported, false otherwise.
Clusters() (Clusters, bool)
// Routes returns a routes interface along with whether the interface is supported.
Routes() (Routes, bool)
// ProviderName returns the cloud provider ID.
ProviderName() string
// ScrubDNS provides an opportunity for cloud-provider-specific code to process DNS settings for pods.
ScrubDNS(nameservers, searches []string) (nsOut, srchOut []string)
}
永続ストレージ連携(PersisntentVolume / PersisntentVolumeClaim)
PersistentVolumeは永続ストレージとの連携する機能を提供します。Kubernetes v1.5時点では下記のストレージに対応しています。
- awsElasticBlockStore
- azureDisk
- azureFile
- cephFS
- cinder (OpenStack block storage)
- fc (Fibre Channel)
- flexVolume
- flocker
- gcePersistentDisk
- glusterfs
- hostPath (Nodeのホストのパス)
- iscsi
- nfs
- photonPersistentDisk
- quobyte
- rbd (Ceph Block Device)
- vsphereVolume
参考
拡張性
独自のリソース定義(ThirdPartyResource)
ThirdPartyResourceはユーザが独自のKubernetesのリソースを定義できる機能です。Kubernetesのリソース管理の仕組みをそのままフレームワークとして利用することができます。高度なアプリケーションの運用を実現するCoreOSのOperatorや、同じくCoreOSのOpenID Connect Provider dexのデータストアなど活用例が増えてきました。
ThirdPartyResourceの詳細については @shmurata さんのフレームワークとしての Kubernetesという記事がよくまとまっています。
おわりに
機能をまとめてみて改めてKubernetesの機能の多さに驚かされました。引き続きKubernetesの発展に注目していきたいと思います。 ![]()