kubectl create -f x.yamlでReplication Controllerを作成しコンテナが起動するまでに、各コンポーネントがどのように動作するかまとめてみました。Kubernetes 1.2時点での情報です。各コンポーネントの概要は、Kubernetes: 構成コンポーネント一覧をご覧ください。
シーケンス図
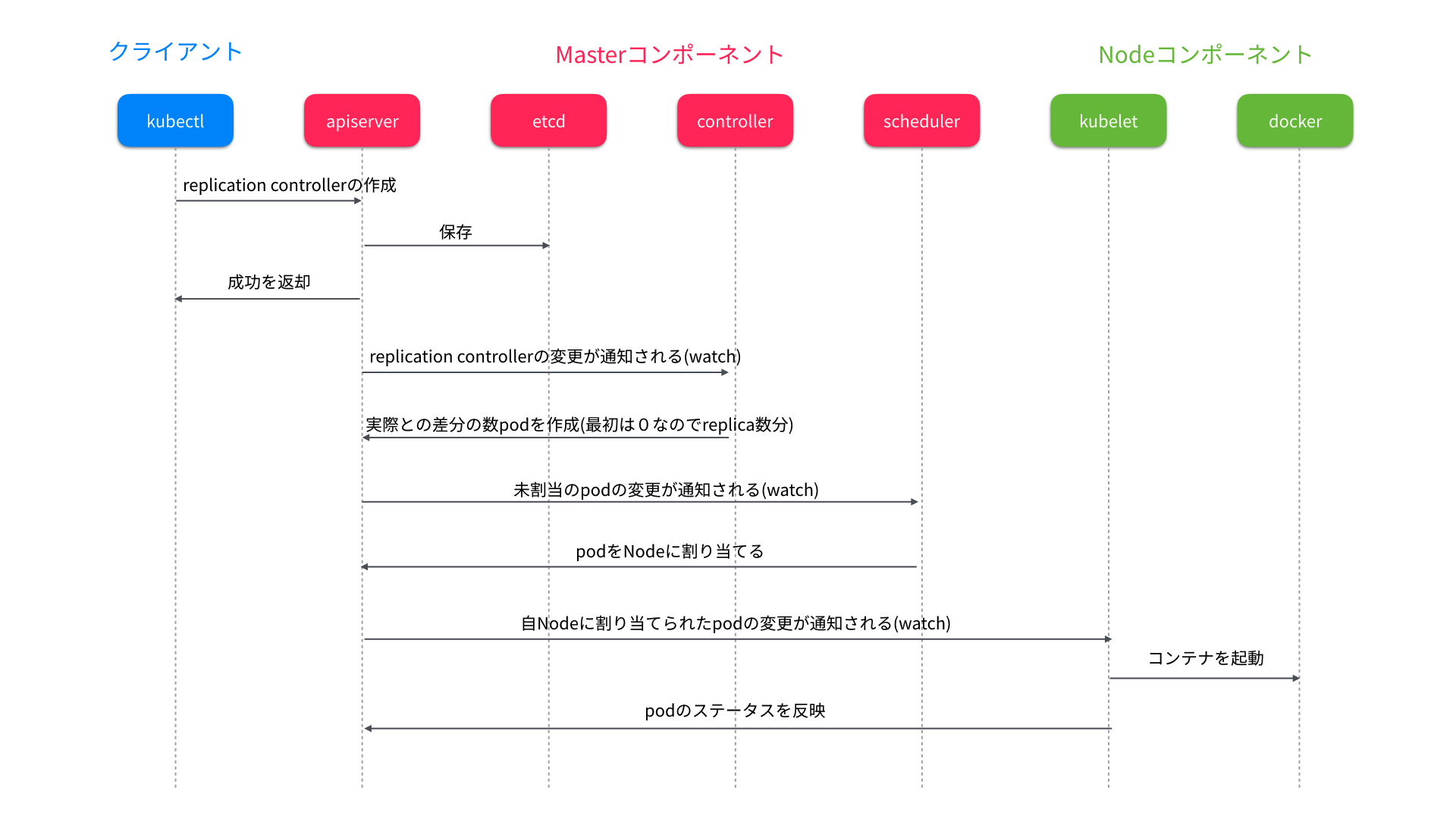
各コンポーネントはAPIサーバーのリソースを監視(watch)して非同期に動作するので、実際のアクセスの方向はコンポーネントからAPIサーバーになります。
kubectl createによるReplication Controller作成
kubectl create -f x.yamlでReplication Controllerを作成を実行すると、内部ではAPIサーバーのPOST /api/v1/namespaces/{namespace}/replicationcontrollersというAPIに対して、Replication Controllerの情報をPOSTします。APIサーバーでReplication Controllerのリソースが作成できた段階(コンテナはまだ起動していない)で完了(created)が表示されます。
ファイルはyaml, json形式の両方が指定できますが、一度内部オブジェクトに変換しバリデーションを行った上でPOST時にJSON形式にエンコードされます。
下記のように--vオプションでログレベルを指定すると、APIへのアクセスをログで追うことができます。
$ kubectl create --v=10 -f frontend-controller.yaml
APIサーバーの処理
APIサーバーは各コンポーネントからリソースの情報を受け取りetcdに保存します。あくまでリソースの情報のみを管理していてAPIサーバーが直接Nodeやcontrollerに命令することはありません。各コンポーネントはAPIサーバーのリソースを監視(watch)しているので、非同期にイベントが通達されます。
controllerの処理
kube-controller-managerの立ち上げるコントローラーの一つに、Replicatoin Controllerを管理するReplication Managerがあります。(ややこしいですがReplication Controllerはリソース名です)
Replication ManagerはAPIサーバーのGET /api/v1/watch/replicationcontrollers、GET /api/v1/watch/podsを使ってReplication Controllerとpodのリソースの変更を監視(watch)しています。
Replication Managerは、指定されたreplica数とアクティブなpod数の差分を計算し、不足または余剰分のPodを生成・削除して調整を行うのが仕事です。
よって、新規でReplication Controllerが作成されると指定されたreplica数分、APIサーバーのPOST /api/v1/namespaces/{namespace}/podsを使ってpodが生成されます。この時点ではあくまでリソースとしてのPodができるだけで、どのノードにも割り当てられていません。
参考: アクティブなPodの条件
func IsPodActive(p api.Pod) bool {
return api.PodSucceeded != p.Status.Phase &&
api.PodFailed != p.Status.Phase &&
p.DeletionTimestamp == nil
}
schedulerの処理
スケジューラーは、APIサーバーのGET /api/v1/podsを使ってノードに未割当のPodを監視しています(割り当て済みPodも監視しています)。このAPIにはfieldSelectorというパラメータでPodのfieldに対する条件が付けることができ、これを使って未割当、割り当て済みのPodを指定しています。
未割当のPodはNodeSelectorなどの条件と優先度を見てNodeが選択され、APIサーバーのPOST /api/v1/namespaces/{namespace}/bindingsを使ってNodeの割り当て(Binding)を行います。
(参考: plugin/pkg/scheduler/generic_scheduler.go)
参考: 未割当のPodのselect条件
// Returns a cache.ListWatch that finds all pods that need to be
// scheduled.
func (factory *ConfigFactory) createUnassignedNonTerminatedPodLW() *cache.ListWatch {
selector := fields.ParseSelectorOrDie("spec.nodeName==" + "" + ",status.phase!=" + string(api.PodSucceeded) + ",status.phase!=" + string(api.PodFailed))
return cache.NewListWatchFromClient(factory.Client, "pods", api.NamespaceAll, selector)
}
参考: POSTするBindingの例
{
"kind": "Binding",
"apiVersion": "v1",
"metadata": {
"name": "frontend-yai9k",
"namespace": "default",
"creationTimestamp": null
},
"target": {
"kind": "Node",
"name": "172.17.4.99"
}
}
Kubelet
kubeletは、APIサーバーのGET /api/v1/podsを使って自Nodeに割り当てられたPod(fieldSelectorパラメータNode名を指定)を監視(watch)しています。そしてPodに定義されたコンテナをdocker(rktも選択可)起動します。Pending, RunningなどのPodのステータスはPUT /api/v1/namespaces/{namespace}/pods/{name}/statusを通して更新します。
また、Node自身の情報をPUT /api/v1/nodes/{name}/statusを使って定期的(デフォルト10秒。kubeletの--node-status-update-frequencyオプションで指定可)に更新します。
参考: 自分のノードに割り当てられたPodの選択
func NewSourceApiserver(c *clientset.Clientset, nodeName string, updates chan<- interface{}) {
// spec.nodeNameが自Nodeのものを選択してwatch
lw := cache.NewListWatchFromClient(c.CoreClient, "pods", api.NamespaceAll, fields.OneTermEqualSelector(api.PodHostField, nodeName))
newSourceApiserverFromLW(lw, updates)
}
Docker, rkt
kubeletは割り当てられたPodのコンテナを、kubeletの起動オプション--container-runtimeで指定したコンテナランタイムで起動します(デフォルトはDocker。rktも選択可)。ここでやっと実際のコンテナが起動します![]() 。Dockerの場合ネットワークネームスペースを保持共有するための仕組みとして、Pauseコンテナも一緒に起動します。
。Dockerの場合ネットワークネームスペースを保持共有するための仕組みとして、Pauseコンテナも一緒に起動します。
参考: Kubernetesコンポーネントのログ
Kubernetesのコンポーネントは共通してglogというログライブラリが使われています(参考: master/docs/devel/logging.md)。どのコンポーネントも--vオプションでログレベルが指定でき、内部の動作を確認するのに便利です。コード中で使われているの最大のログレベルは10でした