Kubernetes ではすべての API オブジェクトは kube-apiserver を通して etcd に保存されています。etcd にはデータサイズの制限(クォータ)がありますが、compaction 前の履歴データや断片化のサイズも含むなど、いくつか留意すべき点があります。この記事では etcd の容量管理について知っておくと良さそうな情報をまとめました。etcd のバージョンは 3.2.24 で確認しています。
etcd の容量制限 (クォータ)
etcd はデフォルトで 2GB のクォータ が設定されています。これを超過すると etcd が Alarm があがった状態となり、アラームを解除 (disarm) しない限り、etcd にデータの書き込みができない状態になります。容量超過の場合は mvcc: database space exceeded というエラーメッセージが表示されます。クォータサイズは --quota-backend-bytes オプションで最大 8GB まで指定可能です。
クォータのサイズに含まれるもの
クォータのサイズは etcd がバックエンドとしてつかっている BoltDB (etcd-io/bbolt) の物理的なサイズになります。サイズには以下のように履歴データや断片化による隙間も含まれるため、注意が必要です。
-
現在のデータ(キーと値)
- Kubernetes の場合、API オブジェクトごとにキーができ、protocol buffer でエンコードされている
-
履歴データ
- etcd の compaction のタイミングで指定した revision 以下の履歴は消える
-
断片化による隙間
- etcd の defrag のタイミングで解消する
物理サイズと論理サイズ
etcd のデータサイズには物理サイズと論理サイズがあります。これらのサイズは以下の Prometheus のメトリクスで見ることができます。
-
etcd_mvcc_db_total_size_in_bytes断片化による隙間を含む、物理的な DB のサイズ- クォータの対象となるサイズ
- defrag を行ったときのみサイズが減る
-
etcd_mvcc_db_total_size_in_use_in_bytes断片化による隙間を含まない、論理的な DB のサイズ- compaction で履歴データを消したときにサイズが減る
実際の動作を見てみる
以下のグラフは kube-apiserver を通して 1MB の ConfigMap を 1 秒間に一回変更し、履歴データを書きこんでいった際のメトリクスになります。同一の ConfigMap の更新であるため、kube-apiserver からは見ると約 1MB の増加しかないはずですが、etcd のデータ量は増えていっていることがわかります。
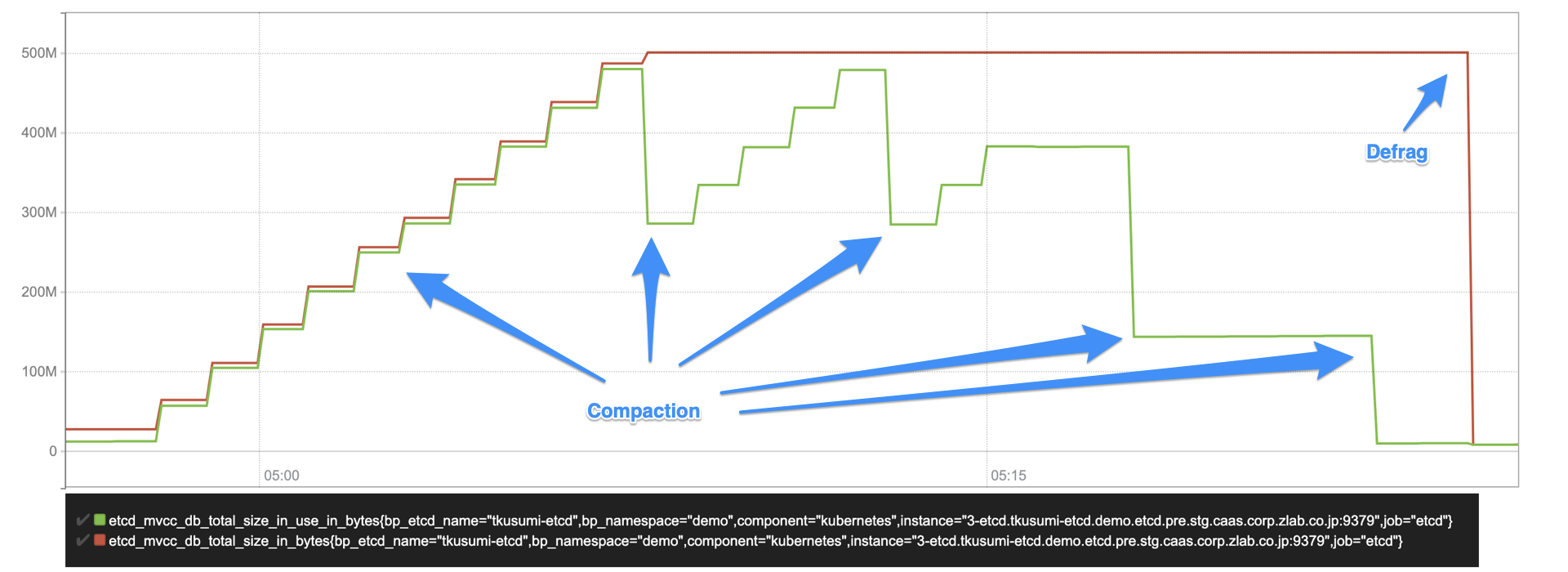
グラフは赤が物理サイズ、緑が論理サイズのメトリクスになります。上記グラフから以下の動作が伺えます。
- ConfigMap の更新を開始すると etcd の論理サイズ(緑)、物理サイズ(赤)ともに増えていく
- 履歴データによってサイズが増えていく
- 論理サイズ(緑) は定期的にサイズが小さくなる
- 5分ごとに kube-apiserver によって compaction が走って履歴データが消えるため
- 一定以上データが消えていないのは、compaction の revision 指定の仕様 (後述)
- 一方物理サイズ(赤) は一度上がったサイズはそのまま
- 最後に手動で defrag を実行したタイミングで初めてサイズが下がる
実際に行った操作は以下になります。etcd に負荷をかける操作のため、試す際はご注意ください。
# 1MB のダミーファイルを作成
$ dd if=/dev/urandom of=random.bin bs=1024 count=1024
# ダミーファイルを入れた ConfigMap を作成
$ kubectl create cm dummy-config --from-file random.bin
# 1秒ごとにパッチを当てて、履歴データを etcd に書いていく
$ while true; do
kubectl patch configmap dummy-config \
-p "{\"metadata\":{\"annotations\":{\"dummy-for-update\":\"`date +%s`\"}}}"
sleep 1
done
# 適当なタイミングで止める
# defrag だけ手動実行
$ sudo ETCDCTL_API=3 etcdctl --endpoints=... defrag
履歴データと compaction
etcd は変更の操作があったときに、過去のデータは残して新しいデータを作成する仕組みになっています。内部的には revision という連番が振られています。compaction という操作が行われたときに指定された revision より過去のデータを削除します。
etcd には自動で compaction を行う機能がありますが、Kubernetes では kube-apiserver の機能で compaction を定期的に行うことがデフォルトの動作になっています。compaction の間隔は kube-apiserver の --etcd-compaction-interval という引数で指定でき、デフォルトでは 5分になっています。(kubernetes v1.14.0)
kube-apiserver のコンパクションの処理 では compactRevKey という特別なキーに、最後に compaction を行った revision を記録し、次回の処理でその revision まで compaction を行い、それを繰りかえすという処理を行っています。つまりデフォルトでは2区間分の 10 分間履歴のデータが残ることになります。
データの隙間と defrag
etcd がバックエンドに使っている BoltDB (etcd-io/bbolt) の仕様上、データを削除しても DB サイズは小さくなりません(参考: Question: Shrink BoltDB File? #423)。また DB の断片化が起こる場合もあり、場合によっては defrag を行うことが必要です。しかし defrag の処理中はデータの書き込みや読み込みに失敗する可能性があるため、不必要に行うのは避けたほうがよいでしょう。
etcd の defrag はシンプルに新しく BoltDB のファイルを作り、そこにすべてデータを書き込んで rename で切り替えるという実装になっているようです。
Tips: API オブジェクト数を知る
Kubernetes の API オブジェクト数は kube-apiserver の etcd_object_counts という Prometheus のメトリクスで現在の数を知ることができます。resource のラベルがついているのでどのリソースの数が多いかがすぐに分かります。履歴の情報はありませんが、etcd にどのオブジェクトが多いかを簡単に確認することができます。
以下のコマンドではオブジェクト数の多いリソース順でソートしています。
$ kubectl get --raw /metrics | grep etcd_object_counts | sort -k2 -n
...
etcd_object_counts{resource="clusterroles.rbac.authorization.k8s.io"} 76
etcd_object_counts{resource="secrets"} 118
etcd_object_counts{resource="pods"} 162
etcd_object_counts{resource="events"} 647
Kubernetes での etcd のクォータの注意点
Compaction の間の履歴データに注意する
- デフォルトだと約10分の履歴が保持される
- 特にレプリカ数の大きな Deployment のローリングアップデートには注意
- Pod ごとにオブジェクトが作られ、ローリングアップデートの最中に複数回アップデートされる
- 大きなファイルサイズのオブジェクト (ConfigMap, Secret) の更新にも注意
Event オブジェクトに注意する
- Event オブジェクトには TTL (デフォルト 1時間) はあるものの、障害などで大量のイベントが発生する可能性がある
- Deployment のローリングアップデート時には Event が増えることも留意
まとめ
etcd にはクォータがあり、Bolt DB の物理サイズがその対象になります。物理サイズには compaction 前の履歴や断片化も含まれています。Kubernetes では kube-apiserver が定期的(デフォルト 5分)に compaction を実行しますが、10 分間は履歴が保持されるため、大規模なローリングアップデートを行う場合などは注意が必要です。