TL;DR
- 最近話題のDETRを使って車線検出を作った
- End to Endで後処理がほぼいらない検出器ができた
- 効率良く学習、推論させるためにはまだまだ工夫が必要そう
きっかけ
知り合いから「車線認識のアルゴリズムを作って欲しい」と謎の依頼を受けたのがきっかけです。画像をグリッドに分けて各グリッドでの区画線の存在確率を学習させるような感じで、ラベルが1種類しかないsegmentationに近い方法を最初に試してみました(過去に投稿した自動車の検出とほぼ同じ手法を使っているので、手法が気になる方はそちらをご参照ください)。学習させた結果がこちら。
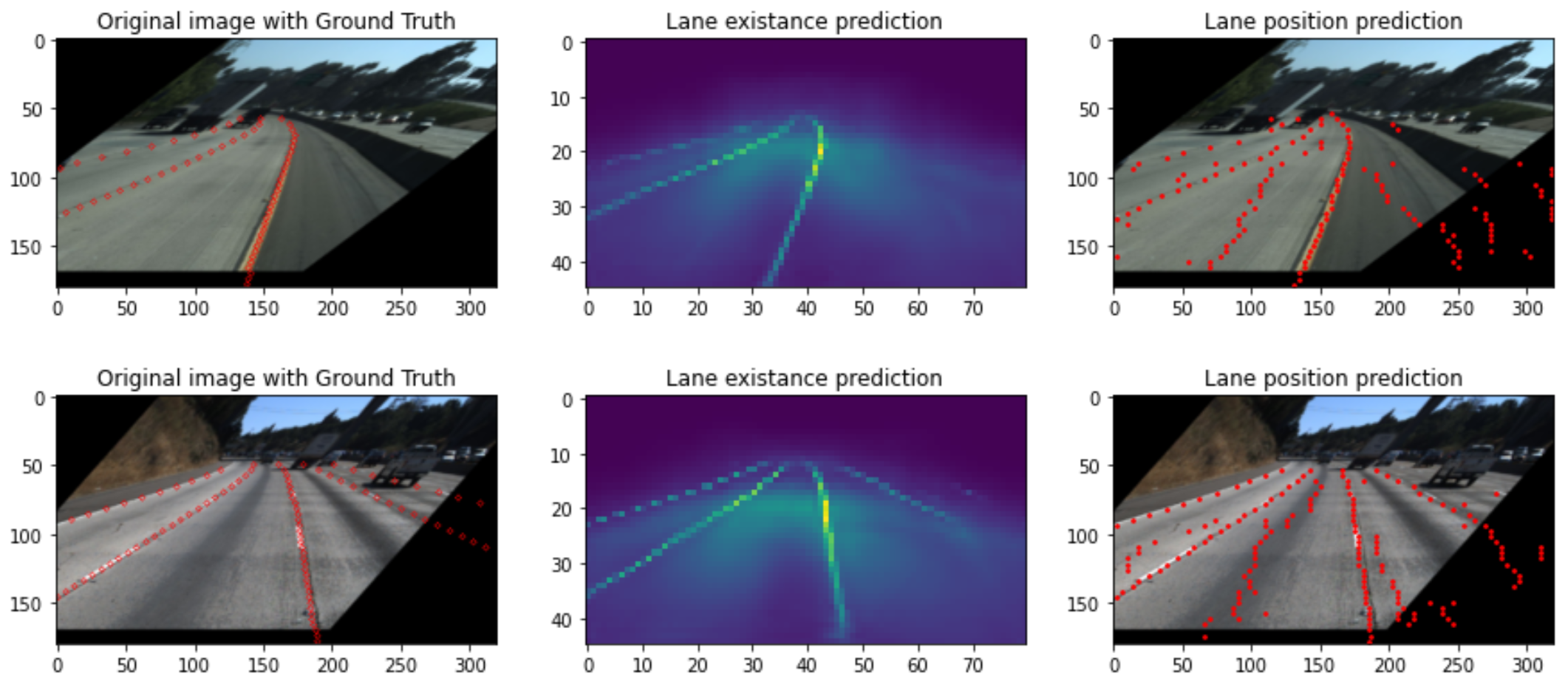
左の列が学習に使った画像(Ground Truth付き。学習させる時は当然Ground Truthが付いていない画像を使っています)、真ん中の列が各グリッドでの区画線の存在確率です。思っていた以上に、区画線のありそうな場所を綺麗に推測してくれています。が、この後の後処理がかなり面倒で・・・例えば区画線の存在確率に対し、x方向に極大値を取っているグリッドを抜き出したのが一番右の列です。区画線以外のゴミを多く拾っておりこのままでは到底使い物にならないですね。と、いろいろと後処理のやり方は思いつくものの、この区画線検出の問題に特化した地味で面倒な作業になりそう・・・なんかEnd to Endでもっとうまいことやってくれる方法ないのかなーと考えていたところで思い出したのがDETRです。
DETR
DETRとはシンプルな構成でEnd to Endな物体検出を行う手法です。一般的なBounding boxを使う物体検出においても、NMS等を省略した超シンプルな仕組みを実現しています。
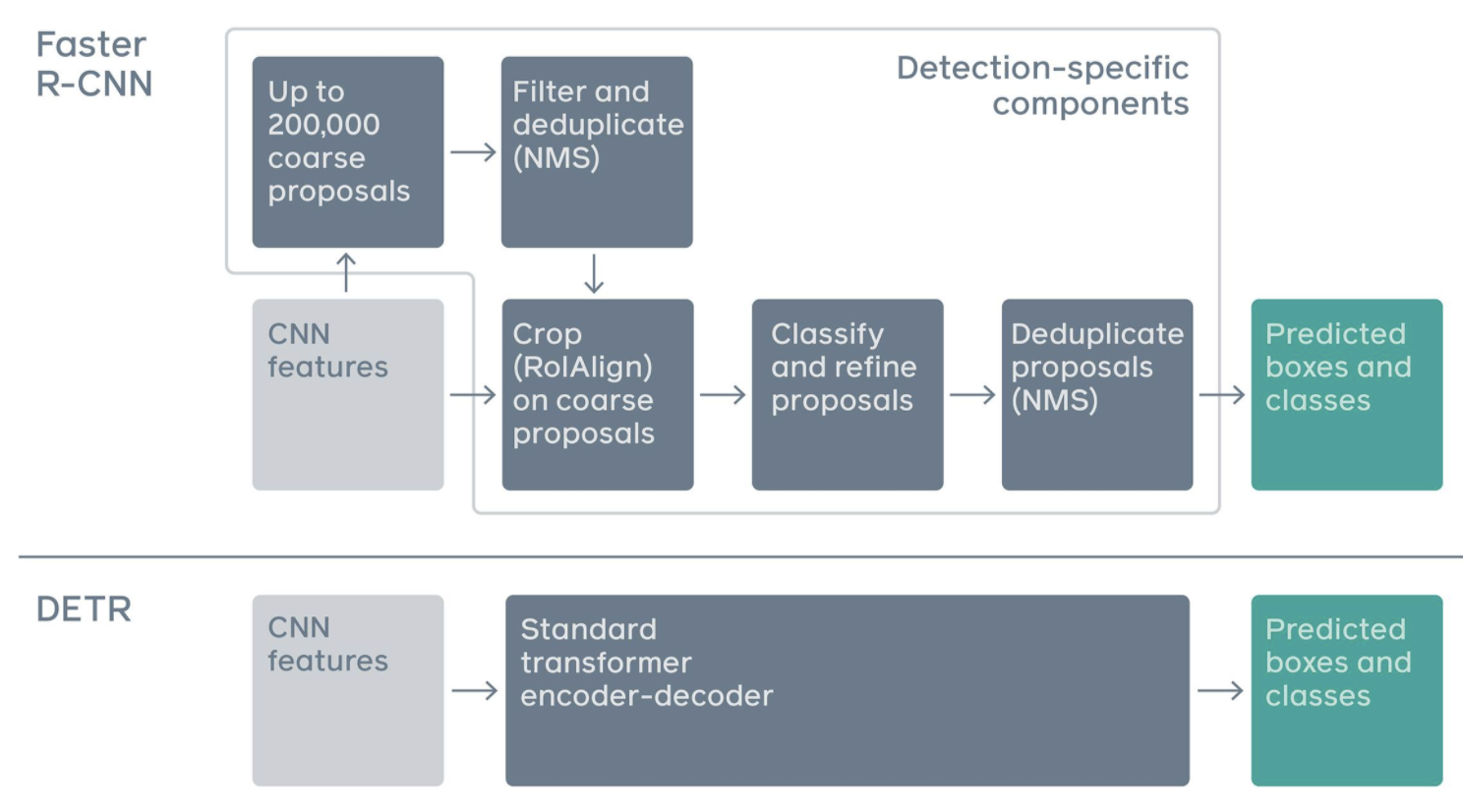
https://ai.facebook.com/blog/end-to-end-object-detection-with-transformers/
私自身が他の人に教えられるほど理解していないため、ここではDETR自体の説明は行いません。DETRの概要を理解している方向けの内容となっています。そもそものDETERについては他のページ、記事を参考にしてください。
車線認識用のDETR
今回車線認識のために作ったネットワークの全体像です。オリジナルのDETRとの差異について一つずつ説明します。
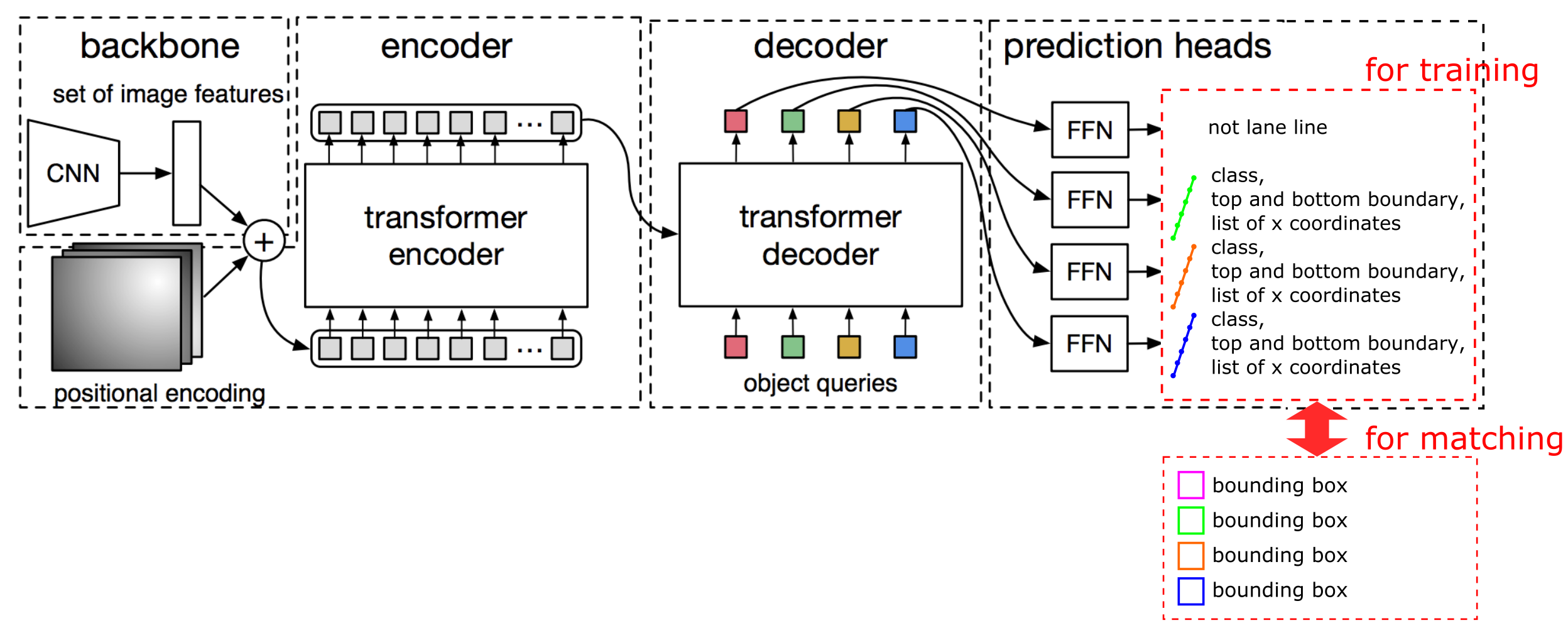
FFN
出力が以下になるようにFFNの構成を変更しました。
- classラベル:オリジナルと同じく(class数+1)次元の出力になります。今回は区画線か背景かのみの判定を行ったため2次元の出力です。
- 区画線の上端、下端:画像内で対象の区画線が写っているy座標です。上端、下端の2次元の出力です。
- 区画線のx座標列:区画線を"等間隔に区切られた点列"と捉え、各点のx座標を格納した配列を出力させます。区画線がない高さには無効値を設定しています。配列長は任意です。今回は22としています。
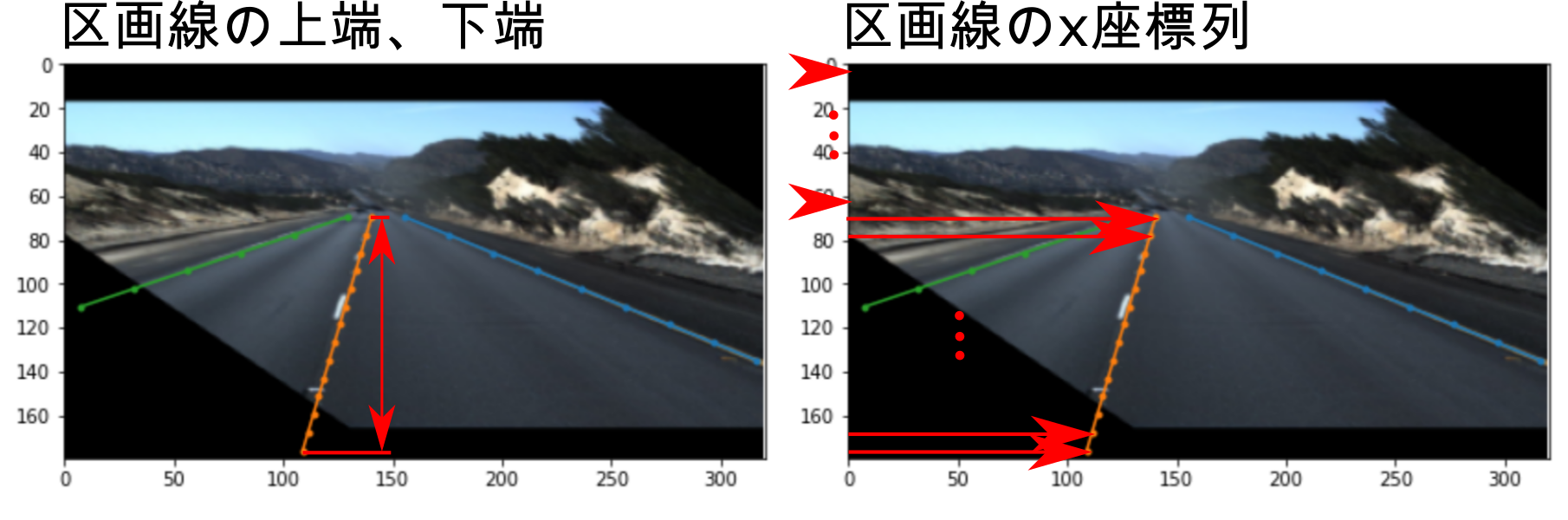
区画線の上端、下端および区画線のx座標列は下図のようなイメージです。
num_queries
ネットワークから出力させるObject候補の数です。任意ですが10としています。オリジナルの論文では"画像あたりのObjectの数<<num_queries"が望ましいと書かれています。画像あたりの区画線は3~5のはずなので、10では十分に大きいとは言えないと思いますが・・・ここは後ほど。
matching
DETRでは、どの出力がどのObjectなのかをHungarian matchingにより判定しその判定結果を元に学習させる正解ラベルを設定します。DETR同等のマッチングを行うため、区画線の点列をその点列を包含するbounding boxに変換し、bounding boxでのマッチングを計算しています。左が点列で表した区画線、右がそれを変換したbounding boxです。
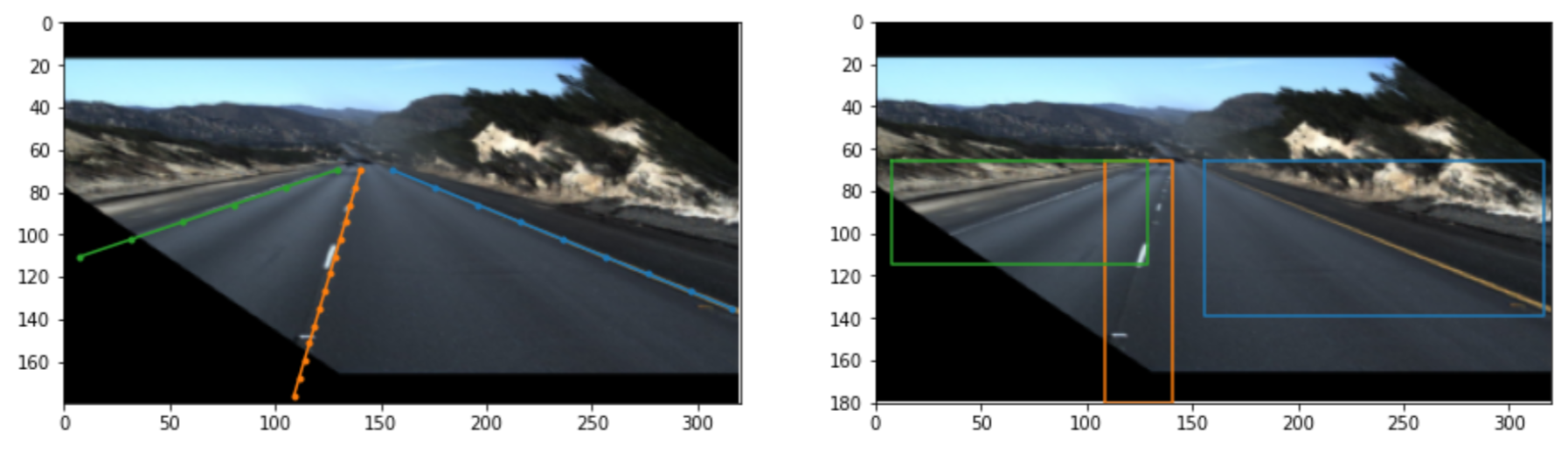
区画線のようなものにおけるマッチング判定にこの手法が適しているのかは色々と検討の余地がありますが、既存のコードを最大限に活用する方針を取りました。
誤差関数
classラベルをcross entropy、区画線の上下端、区画線のx座標列をL1誤差で計算しました。特に考えがあるわけではありませんがそれぞれの重みづけを1として画像内の区画線数で割り、誤差関数を計算しました。
学習
tusimpleの車線データセットを使い、左右反転、上下左右の拡大縮小、水平方向のせん断によるdata augmentationを行いました。学習データとしてここまでに示したものが一例です。
学習済みパラメータを使い、backboneであるresnet以外を(学習率は2e-5から開始し、100epoch目で2e-6に下げています)300epochまで学習させました。
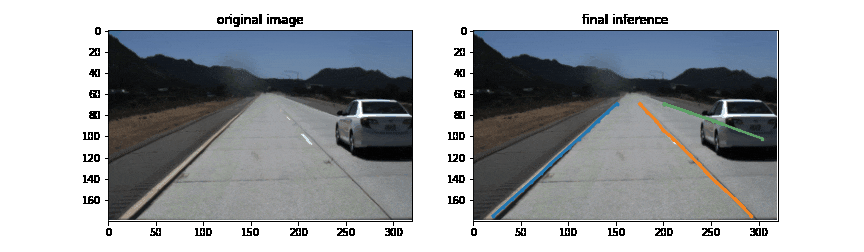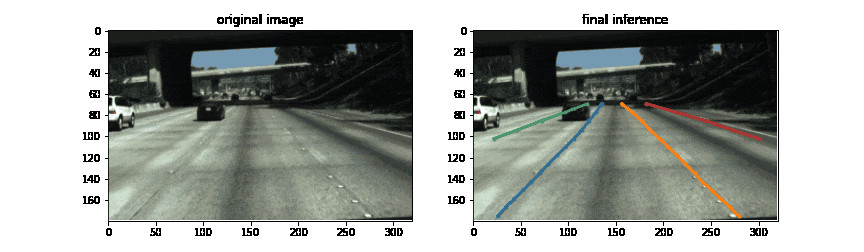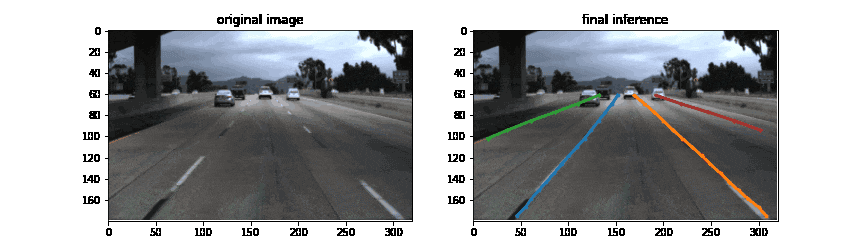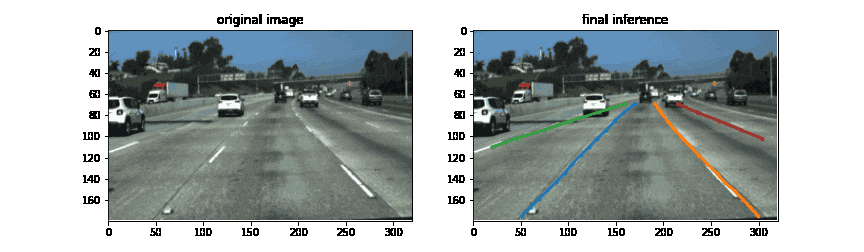
結果
300epochまで学習させた際にvalidationの結果が最も良かったepochにおける推論結果がこちらです。DETRの出力のうち、区画線と判定されたものに対して上下端でcropした結果が一番右の列です。データセットのスコア計算はしていませんが、定性的にはかなりの精度で区画線を検出できているように感じます。

作ってみて思ったこと
区画線のようにbounding boxでない問題においても、DETRと同等の方法で学習、認識させることができました。後処理がほとんど必要なく、ネットワーク構造の設計と学習に専念できそうです。Encoder/Decoder部分を理解していなくともそれなりの認識が作れるシンプルさもかなり良いです。
区画線のx座標列に対し極端な増減を抑制するような誤差関数は設定していませんが、区画線が左右にnoisyにならず、滑らかな出力がなされるように自然に学習される結果となりました。TuSimpleのデータセットに対する推論結果を見ているとほとんど問題は見当たらない一方で、区画線が大きく曲がっているシーン、分岐のように区画線が角張っているシーンでおかしな出力をする原因にならないか、検証が必要そうです。
今回DETRが出力するObject候補数は10としました。実は最初は20で試していたのですが、20候補のうち5~6のみが学習される結果となり(結果の章の右から2番目の列)計算時間短縮のために10としました。今回の学習対象である区画線がおおよそ決まった場所にあるためにこのような結果になったのだと推測しています。全てのObject候補を満遍なく学習させて汎用性の高い学習をさせるためには、
- より複雑なシーンを含んだデータで学習させる
- より効果的なdata augmantationを行う
- 適切なパラメータをFFSの初期値として使い、ネットワークの出力が画像上で満遍なく配置される状態から学習を開始する
などの方法が考えられる気がします。実際にこれらの方法でうまく行くという確証はありませんし、特に3つ目はそもそもそのようなことが可能なのかもよく分かっていません。ただここをきちんと理解して上手く学習させないとDETRを使うことの恩恵が大幅に減ってしまうはずです。ここのあたりの知見のある方がいれば解決方法を教えていただけると非常に助かります。
最後に
どこに需要があるのか良く分からない自己満足の内容になってしまいまいしたね・・・
今回書いたコードはかなり汚く他の人に見せられるレベルではありませんが、もし要望があれば多少整理してどこかで公開してみます。