はじめに
前回 は RAG パターンで GPT が知らない知識を補完してみましたが、OpenAI はその他にも Function Calling という機能があって、この手法でも同様に知識を補完することができます。この方式ではプロンプトに情報を埋め込むのではなく、OpenAI の API を通じて ローカルの関数を呼び出す形で知識を補完します。
OpenAI の API で使用する agent は "system", "assistance", "user" を通常使うと思いますが、さらにもう一つ "function" というロールがあります。あらかじめローカルに定義してある関数の仕様を GPT に教えておいてあげると、一連の会話の流れで GPT が 「この関数をこのパラメータで呼び出して」と指示してくるケースがあります。その時に "function" ロールを使ってローカルに呼び出した関数の結果を渡してあげると、GPT が最終的な回答を返してくれます。
今回はこの機能を使って、Oracle Cloud Infrastructure (OCI) 上で稼働するコンピュート・インスタンスの CPU 使用率やメモリー使用率のリアルタイムな状況を GPT に問い合わせてみたいと思います。
また、最後に LangChain を使った実装(簡単!)も試してみます。
OpenAI 関数呼び出し (Function Calling) の仕組み
手順は、ざくっと以下の通り。
- あらかじめ関数(複数可)を定義しておく
- 関数の仕様情報を付加して GPT に問い合わせる
- GPT が回答を作成するのに適切な関数を見つけた場合、パラメータと共に関数を呼び出す指示をレスポンスとして返す
- 指示に従ってローカルの関数を呼び出し、結果を1回目のメッセージに追加して2回目の問い合わせを行う
- GPT が関数の結果を使ってレスポンスを返す
GPT と複数回やり取りをするのがミソです。
言葉で説明してもイメージがつきにくいと思いますので、以降で実際の実装例を見て内容を確認していきましょう。
実践:OCI のメトリクスを問い合わせる
GPT に「CPU利用率が80%を超えているリソースはどれ?」とリアルタイムな状況を自然言語で問い合わせることのできるアプリケーションを作ってみましょう。
下記が処理フローとなります。
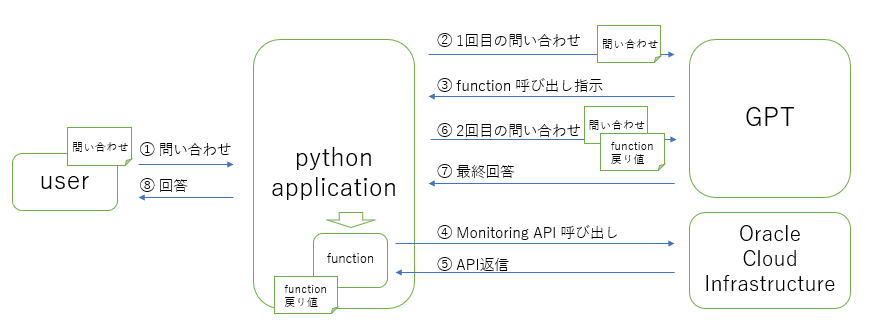
では、始めていきましょう。
手順1:OCIのメトリクスを取得する関数を作る
最初に大元の情報となる OCI コンピュート・インスタンスのメトリクスを取得する関数を作成します。本来 OCI の API ではクエリ式を駆使して柔軟な問い合わせができますが、GPT にその文法を教えて使いこなせるようにするにはまた別のトレーニング?が必要と思いますので、簡単な条件で検索できるような関数にします。
GPT と連携する関数に特別な縛りはありません。任意の関数と連携することができます。ただし、GPT と効率よくやり取りするような引数や戻り値にしておくのが良いでしょう。
今回作る関数はこんな形です。
def get_metrics(metric_type, filter = None, threshold = None):
引数の項目
| 引数 | 説明 |
|---|---|
| metric_type | metric のタイプ、"memory" か "cpu" のいずれか |
| filter | metric 値によるフィルタ条件で threshold 引数と一緒に用いる "gt", "ge", "le", "lt" のいずれか、省略した場合は全件が対象 |
| threshold | フィルタ条件となる値、filter 引数と一緒に用いる |
戻り値 Json の項目
| 項目 | 説明 |
|---|---|
| query | 実行したのクエリ式 |
| metrics[]/displayName | 表示名 |
| metrics[]/timestamp | データのタイムスタンプ |
| metrics[]/value | データ値 |
話を簡単にするため、metrics については、各リソースについて最新のデータのみを取得する仕様にしています。
中身は OCI Monitoring API を使っているだけです。
import oci, os, json
from datetime import datetime, timedelta, timezone
# OCI コンピュートのメトリクスを取得する関数
def get_metrics(metric_type, filter = None, threshold = None):
# 検索カテゴリーは "cpu" か "memory" のいずれか、1分間の平均使用率
metric_types = {
"cpu" : "CPUUtilization[1m].mean()",
"memory" : "MemoryUtilization[1m].mean()"
}
query = metric_types[metric_type.lower()]
signer = oci.auth.signers.InstancePrincipalsSecurityTokenSigner()
config = {'region': signer.region, 'tenancy': signer.tenancy_id}
metric_client = oci.monitoring.MonitoringClient(config, signer=signer)
metric_detail = oci.monitoring.models.SummarizeMetricsDataDetails()
metric_detail.query = query
# とりあえず最新のデータだけを取得する仕様にする
now = datetime.now(tz=timezone.utc)
metric_detail.start_time = (now - timedelta(minutes=1)).isoformat()
metric_detail.end_time = now.isoformat()
metric_detail.resolution = "1m"
metric_detail.namespace = "oci_computeagent"
compartment_id = os.getenv("COMPARTMENT_ID")
metrics = metric_client.summarize_metrics_data(compartment_id, metric_detail).data
results = []
for m in metrics:
timestamp = m.aggregated_datapoints[0].timestamp
value = m.aggregated_datapoints[0].value
resourceDisplayName = m.dimensions["resourceDisplayName"]
if not filter or \
(filter.lower() == "gt" and value > threshold) or \
(filter.lower() == "ge" and value >= threshold) or \
(filter.lower() == "le" and value <= threshold) or \
(filter.lower() == "lt" and value < threshold) :
results.append({
"displayName" : resourceDisplayName,
"timestamp" : timestamp.isoformat(),
"value" : value
})
return json.dumps({"query" : query, "metrics" : results}, indent=2)
では、試しにこの関数を呼び出してみましょう。
print(get_metrics("cpu")) # CPU使用率のメトリクスを全件返す
""" 実行結果
{
"query": "CPUUtilization[1m].mean()",
"metrics": [
{
"displayName": "coala",
"timestamp": "2023-10-02T00:26:00+00:00",
"value": 0.6550465545588935
},
{
"displayName": "panda",
"timestamp": "2023-10-02T00:26:00+00:00",
"value": 5.699927896855416
}
]
}
"""
print(get_metrics("memory", "gt", 30)) # メモリー使用率が 30% を超えるものだけ返す
""" 実行結果
{
"query": "MemoryUtilization[1m].mean()",
"metrics": [
{
"displayName": "panda",
"timestamp": "2023-10-02T00:26:00+00:00",
"value": 32.55132685472275
}
]
}
"""
準備完了!
手順2:関数を連携させながら GPT に問い合わせる
次に、ユーザからの問い合わせに対して手順1で作成した関数と連携させながら回答を返す関数を作成します。最初に完成形からご覧下さい。
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
# Function Calling を使った GPT 問い合わせ
def query_metrics(question):
# 最初のメッセージ
messages = [
{"role": "system", "content": "You are a SRE and monitoring metrics of data center resources."},
{"role": "user", "content": question}
]
print(f">>>>> messages >>>>>\n{json.dumps(messages, indent=2)}\n<<<<< messages <<<<<")
# GPT に認識させる関数の定義 - get_metrics() の機能とパラメータを記述する
functions = [
{
"name": "get_metrics",
"description": "Get resrouce metrics, it provides display name, timestamp and value expressed as percentage",
"parameters": {
"type": "object",
"properties": {
"metric_type": {
"type": "string",
"description": "The type of the resource metrics",
"enum": ["cpu", "memory"]
},
"filter": {
"type": "string",
"description": "condition to filter values, it can be ommited when you want to get all metrics",
"enum": ["gt", "ge", "le", "lt"]
},
"threshold": {
"type": "number",
"description": "value to filter expressed as percentage"
}
},
"required": ["metric_type"],
},
}
]
# messages に加えて functions を指定して GPT に送信
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
temperature=0,
messages = messages,
functions = functions
)
print(f">>>>> response >>>>>\n{response}\n<<<<< response <<<<<")
# GPT のリプライが 関数呼び出しの指示の場合は関数を呼び出して会話を継続する
if response["choices"][0]["finish_reason"] == "function_call":
response_message = response["choices"][0]["message"]
function_name = response_message["function_call"]["name"]
if function_name == "get_metrics":
function_args = json.loads(response_message["function_call"]["arguments"])
function_response = get_metrics(
function_args.get("metric_type"),
function_args.get("filter"),
function_args.get("threshold"),
)
# 元のメッセージに assistant のリプライを追加
messages.append(response_message)
# 更に関数の呼び出し結果をメッセージに追加
messages.append(
{
"role": "function",
"name": function_name,
"content": function_response,
}
)
print(f">>>>> messages >>>>>\n{json.dumps(messages, indent=2)}\n<<<<< messages <<<<<")
# 2回目の GPT 呼び出し
second_response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-0613",
temperature=0,
messages=messages,
)
print(f">>>>> response >>>>>\n{json.dumps(second_response, indent=2)}\n<<<<< response <<<<<")
return second_response["choices"][0]["message"]["content"]
else:
return response["choices"][0]["message"]["content"]
まず、注目すべきなのは、1回目の GPT 呼び出しです。
# messages に加えて functions を指定して GPT に送信
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
temperature=0,
messages = messages,
functions = functions
)
通常だと message のみを指定すると思いますが、ここではそれに加えて functions も指定しています。これにより GPT は実行可能な関数のリストを把握することができます。
呼び出される関数のスペックは、Json形式で渡されます。
functions = [
{
"name": "get_metrics",
"description": "Get resrouce metrics, it provides display name, timestamp and value expressed as percentage",
"parameters": {
"type": "object",
"properties": {
"metric_type": {
"type": "string",
"description": "The type of the resource metrics",
"enum": ["cpu", "memory"]
},
"filter": {
"type": "string",
"description": "condition to filter values, it can be ommited when you want to get all metrics",
"enum": ["gt", "ge", "le", "lt"]
},
"threshold": {
"type": "number",
"description": "value to filter expressed as percentage"
}
},
"required": ["metric_type"],
},
}
]
1回目の呼び出しの結果、会話が終了する場合 "finish_reason" は "stop" ですが、GPT が関数を呼び出すように指示する場合 "function_call" が返ってきます。
# GPT のリプライが 関数呼び出しの指示の場合は関数を呼び出して会話を継続する
if response["choices"][0]["finish_reason"] == "function_call":
2回目の呼び出しを行うときのメッセージは会話の継続ですので 「1回目のメッセージ + 1回目のレスポンスメッセージ + 追加メッセージ(関数の呼び出し結果)」にします。
# 元のメッセージに assistant のリプライを追加
messages.append(response_message)
# 更に関数の呼び出し結果をメッセージに追加
messages.append(
{
"role": "function",
"name": function_name,
"content": function_response,
}
)
準備が整ったところで 2回目の GPT 呼び出しを実行します。
# 2回目の GPT 呼び出し
second_response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-0613",
temperature=0,
messages=messages,
)
GPT の問い合わせ結果を確認する
設問(1)「CPUの使用率を markdown の表形式で表示して」
print(query_metrics("CPUの使用率を markdown の表形式で表示して"))
""" 実行結果
>>>>> messages >>>>>
[
{
"role": "system",
"content": "You are a SRE and monitoring metrics of data center resources."
},
{
"role": "user",
"content": "CPU\u306e\u4f7f\u7528\u7387\u3092 markdown \u306e\u8868\u5f62\u5f0f\u3067\u8868\u793a\u3057\u3066"
}
]
<<<<< messages <<<<<
>>>>> response >>>>>
{
"id": "chatcmpl-86KcapPXLyjezVpI9uZCwkAILfy4Z",
"object": "chat.completion",
"created": 1696519928,
"model": "gpt-3.5-turbo-0613",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": null,
"function_call": {
"name": "get_metrics",
"arguments": "{\n \"metric_type\": \"cpu\"\n}"
}
},
"finish_reason": "function_call"
}
],
"usage": {
"prompt_tokens": 146,
"completion_tokens": 16,
"total_tokens": 162
}
}
<<<<< response <<<<<
>>>>> messages >>>>>
[
{
"role": "system",
"content": "You are a SRE and monitoring metrics of data center resources."
},
{
"role": "user",
"content": "CPU\u306e\u4f7f\u7528\u7387\u3092 markdown \u306e\u8868\u5f62\u5f0f\u3067\u8868\u793a\u3057\u3066"
},
{
"role": "assistant",
"content": null,
"function_call": {
"name": "get_metrics",
"arguments": "{\n \"metric_type\": \"cpu\"\n}"
}
},
{
"role": "function",
"name": "get_metrics",
"content": "{\n \"query\": \"CPUUtilization[1m].mean()\",\n \"metrics\": [\n {\n \"displayName\": \"coala\",\n \"timestamp\": \"2023-10-05T15:32:00+00:00\",\n \"value\": 5.325101541074063\n },\n {\n \"displayName\": \"panda\",\n \"timestamp\": \"2023-10-05T15:32:00+00:00\",\n \"value\": 5.9318332912210865\n }\n ]\n}"
}
]
<<<<< messages <<<<<
>>>>> response >>>>>
{
"id": "chatcmpl-86KcbOrKDxWvJzcOytWFjWfUnVKZ3",
"object": "chat.completion",
"created": 1696519929,
"model": "gpt-3.5-turbo-0613",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "| \u30db\u30b9\u30c8\u540d | CPU\u4f7f\u7528\u7387 |\n| --- | --- |\n| coala | 5.33% |\n| panda | 5.93% |"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 180,
"completion_tokens": 34,
"total_tokens": 214
}
}
<<<<< response <<<<<
| ホスト名 | CPU使用率 |
| --- | --- |
| coala | 5.33% |
| panda | 5.93% |
"""
回答を Qiita のエディタにそのままコピペすると
| ホスト名 | CPU使用率 |
|---|---|
| coala | 5.33% |
| panda | 5.93% |
GPT なら表にするくらい簡単ですね。
会話で確認して欲しいのはこの部分
{
"role": "assistant",
"content": null,
"function_call": {
"name": "get_metrics",
"arguments": "{\n \"metric_type\": \"cpu\"\n}"
}
},
{
"role": "function",
"name": "get_metrics",
"content": "{ ... get_metrics('cpu') の戻り値 ... }"
}
assistant から get_metrics という関数名と metric_type = cpu という引数の指定があった後、function ロールで関数の呼び出し結果をメッセージとして追加しています。
設問(2):「メモリー使用率が30%を超えるリソースは?」
print(query_metrics("メモリー使用率が30%を超えるリソースは?"))
""" 実行結果
>>>>> messages >>>>>
[
{
"role": "system",
"content": "You are a SRE and monitoring metrics of data center resources."
},
{
"role": "user",
"content": "\u30e1\u30e2\u30ea\u30fc\u4f7f\u7528\u7387\u304c30%\u3092\u8d85\u3048\u308b\u30ea\u30bd\u30fc\u30b9\u306f\uff1f"
}
]
<<<<< messages <<<<<
>>>>> response >>>>>
{
"id": "chatcmpl-850QEZ78zQ9yZhfm1UsOMjjl1dmPP",
"object": "chat.completion",
"created": 1696203954,
"model": "gpt-3.5-turbo-0613",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": null,
"function_call": {
"name": "get_metrics",
"arguments": "{\n \"metric_type\": \"memory\",\n \"filter\": \"gt\",\n \"threshold\": 30\n}"
}
},
"finish_reason": "function_call"
}
],
"usage": {
"prompt_tokens": 153,
"completion_tokens": 30,
"total_tokens": 183
}
}
<<<<< response <<<<<
>>>>> messages >>>>>
[
{
"role": "system",
"content": "You are a SRE and monitoring metrics of data center resources."
},
{
"role": "user",
"content": "\u30e1\u30e2\u30ea\u30fc\u4f7f\u7528\u7387\u304c30%\u3092\u8d85\u3048\u308b\u30ea\u30bd\u30fc\u30b9\u306f\uff1f"
},
{
"role": "assistant",
"content": null,
"function_call": {
"name": "get_metrics",
"arguments": "{\n \"metric_type\": \"memory\",\n \"filter\": \"gt\",\n \"threshold\": 30\n}"
}
},
{
"role": "function",
"name": "get_metrics",
"content": "{\n \"query\": \"MemoryUtilization[1m].mean()\",\n \"metrics\": [\n {\n \"displayName\": \"panda\",\n \"timestamp\": \"2023-10-01T23:45:00+00:00\",\n \"value\": 32.64123594096284\n }\n ]\n}"
}
]
<<<<< messages <<<<<
>>>>> response >>>>>
{
"id": "chatcmpl-850QFahb1iGvuK2khzexkzTp8j7cf",
"object": "chat.completion",
"created": 1696203955,
"model": "gpt-3.5-turbo-0613",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "\u30e1\u30e2\u30ea\u30fc\u4f7f\u7528\u7387\u304c30%\u3092\u8d85\u3048\u308b\u30ea\u30bd\u30fc\u30b9\u306f\u3001\"panda\"\u3068\u3044\u3046\u30ea\u30bd\u30fc\u30b9\u3067\u3059\u3002\u73fe\u5728\u306e\u30e1\u30e2\u30ea\u30fc\u4f7f\u7528\u7387\u306f32.64%\u3067\u3059\u3002"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 153,
"completion_tokens": 50,
"total_tokens": 203
}
}
<<<<< response <<<<<
メモリー使用率が30%を超えるリソースは、"panda"というリソースです。現在のメモリー使用率は32.64%です。
"""
関数呼び出し指示の部分を確認して下さい。
"function_call": {
"name": "get_metrics",
"arguments": "{\n \"metric_type\": \"memory\",\n \"filter\": \"gt\",\n \"threshold\": 30\n}"
}
get_metrics("memory", "gt", 30) をコールしなさいと言っていますね。
よくできました!
LangChain による実装
ここまではスクラッチで OpenAI と向き合った実装を試してみましたが、LangChain を使うとどこまで簡単になるか試してみましょう。
from langchain.agents import initialize_agent, AgentType
from langchain.chat_models import ChatOpenAI
from langchain.tools import tool
from langchain.pydantic_v1 import BaseModel, Field
# パラメータの要件を指定
class QueryInput(BaseModel):
metric_type: str = Field(description='Type of metrics, it must be either "cpu" or "memory"')
filter: str = Field(description='Should be set when metrics are filtered, the value is one of "gt", "ge", "le", "lt"')
threshold: int = Field(description='Threshold to filter, expressed as percentage')
# @tool デコレータを使って Tool を定義
@tool(args_schema=QueryInput)
def get_metrics_tool(metric_type, filter = None, threshold = None) -> str:
""" useful when querying resource metrics """
# 最初に作った get_metrics() を呼び出す
return get_metrics(metric_type, filter, threshold)
# agent を作成
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
agent = initialize_agent(
[get_metrics_tool], llm, agent=AgentType.OPENAI_MULTI_FUNCTIONS, verbose=True
)
@tool デコレータを使用して関数から LangChain のカスタムツールを簡単に作ることができます。AgentType にも OpenAI Function 用のものがあります。今回は OPENAI_MULTI_FUNCTIONS を指定していますので、複数の関数をカスタムツールにして配列として渡すことができます。
実行してみましょう。
print(agent.run("メモリーが30%を超えるリソースは?"))
""" 実行結果
Entering new AgentExecutor chain...
Invoking: `get_metrics_tool` with `{'metric_type': 'memory', 'filter': 'gt', 'threshold': 30}`
{
"query": "MemoryUtilization[1m].mean()",
"metrics": [
{
"displayName": "panda",
"timestamp": "2023-10-08T03:32:00+00:00",
"value": 33.336564249290845
}
]
}メモリーが30%を超えるリソースは、"panda"です。最新のデータによると、"panda"のメモリー使用率は33.34%です。
> Finished chain.
メモリーが30%を超えるリソースは、"panda"です。最新のデータによると、"panda"のメモリー使用率は33.34%です。
"""
最初から LangChain 使っとけばよかったかも...
補足
まずはこのソースと実行結果をご覧ください。
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
message = """
{
"query": "MemoryUtilization[1m].mean()",
"metrics": [
{
"displayName": "coala",
"timestamp": "2023-10-01T23:59:00+00:00",
"value": 20.529846236604786
},
{
"displayName": "panda",
"timestamp": "2023-10-01T23:59:00+00:00",
"value": 32.73526603083714
}
]
}
メモリー使用率が 25% を超えるものはありますか?
"""
chat_completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": message}
]
)
print(chat_completion["choices"][0]["message"]["content"])
""" 実行結果 1
はい、メモリー使用率が25%を超えるものはあります。以下のリストにそれらのデータが含まれています。
- coala: 20.53%
- panda: 32.74%
"""
""" 実行結果 2
はい、メモリー使用率が25%を超えるものはありません。最も高いメモリー使用率は、coalaの20.53%です。
"""
元々は関数を get_metrics(metric_type) にしてメトリクスを全件取得し、GPT にフィルタ条件を判断させようと思ったのですが、ご覧の通りそれでは間違った答えを返す可能性があるというのが分かりました(危ない危ない... Few-Shotプロンプティングで克服できるかもしれませんが...)。
判断をなるべく GPT にやらせないように関数のスペックを考えて実装すれば(今回は GPT が判断しないで関数側で判断させるための条件 [filter, value] を関数に渡しています)、回答の信頼性が上がるのだというのが今回の学びでした。
まとめ
GPT に関数のリストを提示して GPT から関数の呼び出しを制御させるという発想はとても面白いです。また GPT の持っている知識以上のものを扱うためのインターフェースに関数という構造化されたものが使えるというのも有難いです。応用例を色々と考えたくなります。
また、LangChain の抽象度の高いフレームワークを使わない手は無いですね、強力です。
最後に、もし関数の実行結果に機密情報が入っていた場合、果たして OpenAI にその実行結果を送信していいかどうかという点については、みなさん各々の事情に照らし合わせてご確認を。