はじめに
OpenAI の GitHub に Question answering using embeddings-based search というコード例があります。GPTは学習したデータに関するトピックにしかうまく答えることができませんが、それ以外のトピックに関する質問についても的確に回答するための手法が紹介されています。
題して "a two-step Search-Ask method"と呼んでいますが、Retrieval Augmented Generation (RAG: 検索により強化した文章生成) という呼び名が一般的ではないでしょうか。
プロンプトにGPTが回答する際の条件や追加的な情報を含めることによって回答の精度を高めるテクニック( =プロンプトエンジニアリング)の一手法だと考えればいいと思います。
この手法は、参照用テキストのライブラリをあらかじめ用意しておいて
- 検索する:テキストのライブラリを検索して、関連するテキストセクションを探します。
- 質問する:検索されたテキストセクションをGPTへのメッセージに挿入し、質問します。
という工夫を行うことによって、より正しい回答を得ることができます。
ファインチューニングは、特殊なタスクやスタイルを教えるのに適していますが、事実の想起に関してはあまり信頼できません。一方、この手法はノートを開いて試験を受けるようなものだと書いてあります。ノートが手元にあれば、モデルは正しい答えにたどり着く可能性が高くなるという訳です。
ただし、GPTに渡すことのできる情報(トークン数)には制限があるため、質問に対する回答に関して最も関連のあるテキストを選んでメッセージに挿入する必要があります。
そうした要件を満たすためにベクトルデータベースを利用します。参照用テキストをベクトルに変換 (= embedding) してデータベースに保管しておきます。ベクトルデータベースはベクトル間の距離を計算することによって意味的に近いテキストを検索することができます。
実践:Autonomous Database に関する質問に答える
OCI資料活用集のページにある「Autonomous Database 技術FAQ」を参照テキストにして、精度の高い回答が GPT でできるか試してみたいと思います。
上記のページをスクレイピングして、質問と回答のセットを準備します。
FAQコンテンツを準備する
最初に pip で必要なライブラリをインストールして下さい。今回試したライブラリのバージョンは以下の通り。
- requests 2.31.0 (HTTPクライアント)
- beautifulsoup4 4.12.2 (スクレイピング)
- chromadb 0.4.2 (ベクトルデータベース)
- openai 0.27.8 (OpenAIクライアント)
- cohere 4.20.2 (Cohereクライアント)
- pandas 2.0.3 (Pandasライブラリ)
以降、Jupyter Notebook での実行を前提に話を進めていきます。
実際の Notebook はこちら で参照できます。
では必要なライブラリを import しておきましょう。
import os
import requests
import bs4
import chromadb
from chromadb.utils import embedding_functions
import openai
import pandas as pd
それから OpenAI と Cohere の API を使うので、環境変数 OPENAI_API_KEY COHERE_API_KEY に各々 OpenAI, Cohere で取得したキーの値を設定しておいてください。
スクレイピング用ライブラリ BeautifulSoup を使ってFAQ のコンテンツを取り出します。
faq_url = "https://oracle-japan.github.io/ocidocs/faq/services/autonomous/autonomous-database-faq/"
response = requests.get(faq_url)
soup = bs4.BeautifulSoup(response.text, 'html.parser')
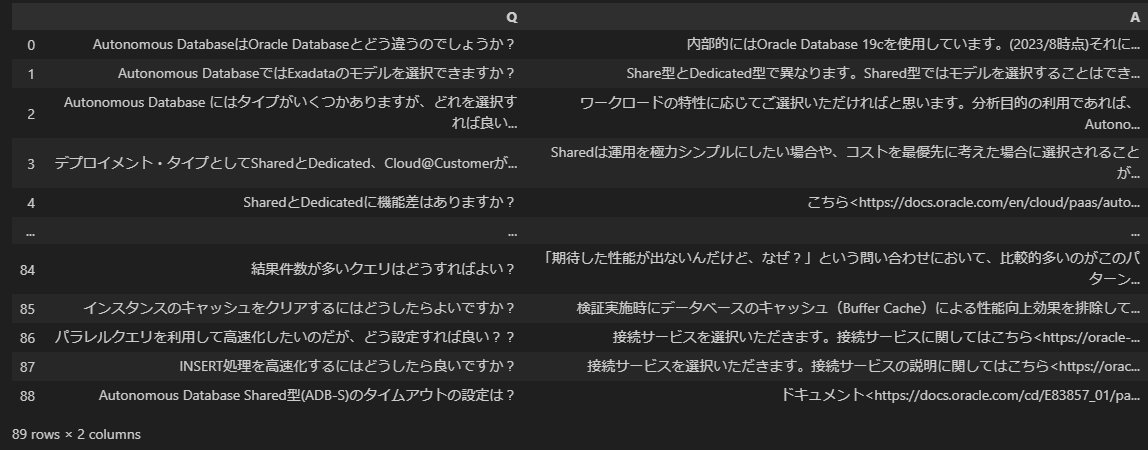
df = pd.DataFrame(columns=['Q', 'A'])
for h2 in soup.findAll('h2'):
question = h2.text.strip()
l = []
for n in h2.next_siblings:
if type(n) is bs4.element.Tag:
if n.name == 'h2':
answer = (''.join(l)).replace('\n', '').strip()
qa = pd.DataFrame({'Q': [question], 'A' : [answer]})
df = pd.concat([df, qa], ignore_index=True)
break
if n.name == 'p':
for d in n.contents:
if d.name == 'a':
l.append(f"{d.text}<{d.get('href')}>")
else:
l.append(str(d.text))
# df.to_csv('./adb-faq.csv', index=False) # save to csv file
df
Pandas の DataFrame に FAQを格納しました。89個のFAQが取り出せました。
ベクトルデータベースに FAQ を保存する
FAQ のテキストをベクトルに変換 (=enbedding) してベクトルデータベースに格納します。
今回ベクトルデータベースには Chroma を使います。
Chroma には、あらかじめ embedding 用の関数を指定することによって、ドキュメントを渡すと自動的に embedding して一緒に保存してくれる機能があります。
embedding 用の関数には、OpenAI・Cohere・Google PaLM・HuggingFace 等のAPIベースのものやローカルで稼働する SentenceTransformers のようなものがあります。
## embedding function の定義
# OpenAI embedding
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
api_key = os.getenv("OPENAI_API_KEY"),
model_name="text-embedding-ada-002"
)
# Cohere https://docs.cohere.com/docs/supported-languages
cohere_english_ef = embedding_functions.CohereEmbeddingFunction(
api_key = os.getenv("COHERE_API_KEY"),
model_name="embed-english-v2.0"
)
cohere_multilingual_ef = embedding_functions.CohereEmbeddingFunction(
api_key = os.getenv("COHERE_API_KEY"),
model_name="embed-multilingual-v2.0"
)
# Chroma default embedding - Sentence Transformers all-MiniLM-L6-v2
default_ef = embedding_functions.DefaultEmbeddingFunction()
embedding のモデルによってベクトルの次元数も値も異なりますので、当然ながら最初から最後まで一貫した embedding モデルを使用する必要があります。Chroma では Collection を作成する際に embedding 関数を指定します。
persist_directory="./chromadb-faq" # chromadb データベースファイルを保存するディレクトリ
embedding_function=openai_ef # ここでは OpenAI の embedding を使用
# faq コレクションの作成
client = chromadb.PersistentClient(path=persist_directory)
client.delete_collection("faq")
collection = client.get_or_create_collection(name="faq", embedding_function=embedding_function)
今回は、OpenAI の embedding を使って、"faq" という名前の collection を作成しました。
では、この collection に FAQ を格納します。
# FAQのテキストは "Q:...\nA:..." のフォーマットにして embedding する
documents = ("Q: " + df['Q'] + "\nA: " + df['A']).to_list()
# FAQの各テキストに付与する id - 001, 002, 003...
ids = list(map(lambda x: f"adb-{x:03d}", df.index))
# FAQの各テキストに付与する メタデータ - 全レコード {"category" : "adb"}
metadatas = list(map(lambda x: {"category" : "adb"}, df['Q']))
# collection に FAQ を追加 embedding (FAQ のベクトル表現) の生成は自動的に行われる
collection.add(documents=documents, metadatas=metadatas, ids=ids)
検索対象のテキスト (documents) には単に「質問」ではなく「質問+回答」を格納することにしました(試行錯誤の結果、こちらの方が回答の精度が高そうだったので)。
この collection にクエリをかけてみます。
「バックアップの方式は?」に意味的に近い 5 つのFAQ項目を抽出してみましょう。
query = "バックアップの方式は?"
results = collection.query(
query_texts = question,
where = {"category" : "adb"},
n_results = 5,
)
results
結果
{'ids': [['adb-028', 'adb-030', 'adb-027', 'adb-029', 'adb-035']],
'distances': [[0.2932670083381172,
0.33005908800307415,
0.330656490608154,
0.3330326989339843,
0.33692546481586033]],
'metadatas': [[{'category': 'adb'},
{'category': 'adb'},
{'category': 'adb'},
{'category': 'adb'},
{'category': 'adb'}]],
'embeddings': None,
'documents': [['Q: 自動バックアップはどこに取得されるのでしょうか。任意のオブジェクト・ストレージに取得することはできますか?\nA: オラクル社が管理するオブジェクト・ストレージに取得されます。取得先に任意のオブジェクト・ストレージを指定することはできません。自動バックアップが取得されるオブジェクト・ストレージはユーザがアクセスすることはできず、課金対象外(ユーザーが指定するストレージ容量には含まれません)になります。',
'Q: 自動バックアップからのリストア時間はどれくらいでしょうか?\nA: データ量、更新量に依存するため変動する可能性はありますが、サービスレベル目標についてはこちら<https://docs.oracle.com/en-us/iaas/autonomous-database-shared/doc/availability-slo.html>を参照ください。',
'Q: バックアップは開始時点でスナップショットが取得されるのでしょうか?その場合、バックアップの完了を待たずともDDL/DML/起動停止等の操作は可能ですか。\nA: Autonomous Database は、ストレージ装置のスナップショット機能によるバックアップは採用しておらず、RMANを利用して60日ごとにフルバックアップ、週次で累積バックアップ、日次で増分バックアップを取得しております。増分バックアップの間の更新についてはアーカイブ・ログが取得されております。 これらのバックアップとアーカイブ・ログを利用することで、バックアップ保持期間の60日の間であれば任意のタイミングに戻すことが可能です(Point-In-Timeリカバリ)。従いまして、バックアップの断面を気にしていただく必要はありません。 ただし、Autonomous Database のリカバリは秒指定で行うため、断面でのリカバリが必要な場合は、アプリケーション側で静止点を確保し、その時間を指定してリカバリを行ってください。参考マニュアル Autonomous Databaseのバックアップおよびリストア<https://docs.oracle.com/cd/E83857_01/paas/autonomous-database/adbsa/backup-restore.html#GUID-9035DFB8-4702-4CEB-8281-C2A303820809>',
'Q: Autonomous Database Shared型の自動バックアップのタイミングは指定できますか?\nA: 現時点でタイミングを指定することはできません。なお、取得したバックアップの情報は下記SQLで確認いただくことが可能です。TAG列の先頭の値でバックアップタイプが判断できます。',
'Q: ソースADBがあるリージョンと異なるリージョンのバックアップ(リモート・バックアップ)を取ることは可能ですか?\nA: ADBの自動バックアップ機能では遠隔地(別リージョン)へバックアップすることはできません。ADBにおけるDR対応は下記の方法がございます。 ・Autonomous Data Guardを使用し、スタンバイDBを構成する ・バックアップベースのディザスタ・リカバリのクロスリージョン・バックアップ・コピーを構成する ・別リージョンにクローンを作成する(平時はインスタンスを停止することでOCPUの課金は抑えることが可能です) ・Data Pumpで Object Storageに論理バックアップを取得し、Object Storageのリージョン・コピー機能で別リージョンに複製する']]}
後述しますが、OpenAI の embedding を使った場合がこの結果です。当然ながら違う embedding モデルを使うと結果も異る場合があります。
意味的な類似性は distances つまり2つの embedding されたベクトル間の距離で表され、距離が近いほど意味的に近いということになります。
質問すると「こんなFAQがありました...」って返してくるチャットボットがありますが、それであれば embedding とベクトルデータベースで実現できますね。
質問に関連するFAQをプロンプトに埋め込んで GPT に質問する
ベクトルデータベースの準備はできたので、いよいよ GPT を使った FAQ の実装に移っていきたいと思います。
# 学習済の知識を使ってOpenAIが質問内容に回答する
def chat_completion(message):
messages = [
{"role": "system", "content": "Autonomous Database に関する質問に対する回答を行います。"},
{"role": "user", "content": message},
]
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages,
temperature=0
)
return response["choices"][0]["message"]["content"]
# chat_completion_with_query() で使う FAQ 項目を埋め込んだプロンプトを返す
def create_message(question, query_results):
examples = []
for n in range(0, len(query_results['documents'][0])):
examples.append(f"\n{query_results['documents'][0][n]}\n")
message = f"""
以下は Q&A です。
---
{''.join(examples)}
---
これまでの知識を使わず与えられた Q&A の情報だけを使って質問に回答して下さい。
回答できない場合は、"情報が不足しているためその質問に回答することができません。"と回答して下さい。
Q: {question}
A:
"""
return message
# 質問内容に関連するFAQを参照しながらOpenAIが回答する
def chat_completion_with_query(question, n_results=5, show_prompt=True):
query_results = collection.query(
query_texts = question,
where = {"category" : "adb"},
n_results = n_results,
)
message = create_message(question, query_results)
if show_prompt: print(message)
return chat_completion(message)
chat_completion() と chat_completion_with_query() という二つの関数を作成しました。それぞれ「生のOpenAPI呼び出しバージョン」と「FAQプロンプト埋め込みバージョン」になります。
二つの出力の違いを見てみましょう。
まずは、普通の OpenAI API呼び出し chat_completion()
print(chat_completion("接続数の制限はありますか?"))
### 出力
はい、Autonomous Databaseには同時接続数の制限があります。制限は、データベースのエディションによって異なります。
Autonomous DatabaseのStandardエディションでは、最大100個の同時接続が許可されます。
Autonomous DatabaseのEnterpriseエディションでは、最大200個の同時接続が許可されます。
ただし、これらの制限はデータベースのパフォーマンスに影響を与える可能性があるため、適切な接続数を管理することが重要です。
おっと、Autonomous Database の Standard Edition/Enterprise Edition って何でしょう?それらしいことを返してくるが実は間違っている "Hallucination" ってやつですね。
次に chat_completion_with_query()
print(chat_completion_with_query("接続数の制限はありますか?"))
### 出力
以下は Q&A です。
---
Q: 一部の重たいクエリによるリソースの大量消費を防ぐ仕組みはありますか?
A: Runaway Queryの管理で、SQLの実行時間やIO量の上限を設定することができます。セッションは接続されたまま、上限を超えるクエリは強制キャンセルされます。参考:Runaway Query マニュアル<https://docs.oracle.com/en/cloud/paas/autonomous-database/adbsa/manage-sql-statements.html#GUID-4861BA7F-F9FA-4909-8DC0-4F46AFF80706>ページトップに戻る<#>
Q: Autonomous Databaseの同時接続セッション数はいくつでしょうか。また同時接続セッション数を超えて接続しようとした場合はエラーになりますか?
A: 同時接続セッション数は1OCPUあたり300セッションです。Autonomous Databaseの初期化パラメータSESSIONSとして設定されます。この値は接続サービスをまたいで有効であり、例えば、OCPU=1のAutonomous Transaction Processingにおいて、TPURGENTで100、TPで200セッションが接続している場合、新たにセッションを作成することはできません。セッション数を超えた場合は 「ORA-00018: 最大セッション数を超えました」というエラーとなり、セッションの作成に失敗します。なお、Autonomous DatabaseはOracle MultitenantのPluggable Databaseであるため、バックグランドプロセスや再帰セッション分のセッション数を考慮する必要はありません。
Q: パラレルクエリを利用して高速化したいのだが、どう設定すれば良い??
A: 接続サービスを選択いただきます。接続サービスに関してはこちら<https://oracle-japan.github.io/ocitutorials/database/adb201-service-names/>を参照ください。
Q: INSERT処理を高速化するにはどうしたら良いですか?
A: 接続サービスを選択いただきます。接続サービスの説明に関してはこちら<https://oracle-japan.github.io/ocitutorials/database/adb201-service-names/>を参照ください。ページトップに戻る<#>
Q: ストレージの最大容量はどのように制御されているのでしょうか、また指定できる最大容量はいくつでしょうか?
A: 指定した容量に基づいてデータベースのプロパティで設定がされます。設定は以下で確認できます。指定できる最大容量は128TBです。それ以上のサイズが必要な場合は別途お問い合わせください。
---
これまでの知識を使わず与えられた Q&A の情報だけを使って質問に回答して下さい。
回答できない場合は、"情報が不足しているためその質問に回答することができません。"と回答して下さい。
Q: 接続数の制限はありますか?
A:
A: 同時接続セッション数は1OCPUあたり300セッションです。Autonomous Databaseの初期化パラメータSESSIONSとして設定されます。この値は接続サービスをまたいで有効であり、例えば、OCPU=1のAutonomous Transaction Processingにおいて、TPURGENTで100、TPで200セッションが接続している場合、新たにセッションを作成することはできません。セッション数を超えた場合は 「ORA-00018: 最大セッション数を超えました」というエラーとなり、セッションの作成に失敗します。
ちゃんと FAQ をベースに回答してくれました。
ちなみに全く関係ない質問をしてみるとどうなるか?
print(chat_completion_with_query("地球と月の間の距離は?"))
### 出力
以下は Q&A です。
---
Q: OCPU、ストレージの課金は時間単位でしょうか?
A: 価格表<https://www.oracle.com/jp/cloud/price-list.html#adw>にはストレージはTB/月、CPUはOCPU数/時で記載されていますが、 実際はどちらも秒単位の請求となります。OCPU、ストレージ共に最低1分から秒単位での利用が可能です。
Q: 自動バックアップからのリストア時間はどれくらいでしょうか?
A: データ量、更新量に依存するため変動する可能性はありますが、サービスレベル目標についてはこちら<https://docs.oracle.com/en-us/iaas/autonomous-database-shared/doc/availability-slo.html>を参照ください。
Q: 一時表領域のサイズは決められますか?
A: ストレージサイズの30%が最大サイズで自動拡張され、ユーザーは変更不可です。ページトップに戻る<#>
Q: ヒントは利用できますか?
A: おすすめの検証手順としては、まずはそのままの状態で計測してください。その後、予期した性能が出ない場合に限り、ヒントの効果を確認してください。
Q: SYSDATEのタイムゾーンがUTCですが、JSTに変更は可能でしょうか?
A: はい、SYSDATE_AT_DBTIMEZONEを使用することで可能です。以下の記事に手順が記載されていますのでご確認ください。[OCI]Autonomous Database:SYSDATE_AT_DBTIMEZONEを使用してsysdateが日本時間を返すようにしてみた<https://qiita.com/500InternalServerError/items/d741a7144de7b35e04ed>ページトップに戻る<#>
---
これまでの知識を使わず与えられた Q&A の情報だけを使って質問に回答して下さい。
回答できない場合は、"情報が不足しているためその質問に回答することができません。"と回答して下さい。
Q: 地球と月の間の距離は?
A:
情報が不足しているためその質問に回答することができません。
FAQ には該当する回答がなかったので回答を諦めました。
今回の実装では、FAQとしてそのまま類似性の高いスコアの5件をプロンプトに入れましたが、実際の検索結果のスコア(Chroma では distances)は
[0.45287324178215976, 0.45992961033736374, 0.466180370147696, 0.4672439786447652, 0.47008613973923435]
と相対的に類似性が低い値となっていますので、distances が一定値を超えるものはそもそもプロンプトに入れないという実装の仕方もあると思います。
参考:embedding モデルと semantic search
ところで気になるのは、embedding モデルによってどのくらい semantic search の結果が異なるのか?ってところですよね。
ということで バックアップの方式は? というテキストで検索した各モデルの結果が以下にありますので参考にして下さい。
** OpenAI text-embedding-ada-002 **
['adb-028', 'adb-030', 'adb-027', 'adb-029', 'adb-035']
Q: 自動バックアップはどこに取得されるのでしょうか。任意のオブジェクト・ストレージに取得することはできますか?\nA: オラクル社が管理するオブジェクト・ストレージに取得されます。取得先に任意のオブジェクト・ストレージを指定することはできません。自動バックアップが取得されるオブジェクト・ストレージはユーザがアクセスすることはできず、課金対象外(ユーザーが指定するストレージ容量には含まれません)になります。
Q: 自動バックアップからのリストア時間はどれくらいでしょうか?\nA: データ量、更新量に依存するため変動する可能性はありますが、サービスレベル目標についてはこちら<https://docs.oracle.com/en-us/iaas/autonomous-database-shared/doc/availability-slo.html>を参照ください。
Q: バックアップは開始時点でスナップショットが取得されるのでしょうか?その場合、バックアップの完了を待たずともDDL/DML/起動停止等の操作は可能ですか。\nA: Autonomous Database は、ストレージ装置のスナップショット機能によるバックアップは採用しておらず、RMANを利用して60日ごとにフルバックアップ、週次で累積バックアップ、日次で増分バックアップを取得しております。増分バックアップの間の更新についてはアーカイブ・ログが取得されております。 これらのバックアップとアーカイブ・ログを利用することで、バックアップ保持期間の60日の間であれば任意のタイミングに戻すことが可能です(Point-In-Timeリカバリ)。従いまして、バックアップの断面を気にしていただく必要はありません。 ただし、Autonomous Database のリカバリは秒指定で行うため、断面でのリカバリが必要な場合は、アプリケーション側で静止点を確保し、その時間を指定してリカバリを行ってください。参考マニュアル Autonomous Databaseのバックアップおよびリストア<https://docs.oracle.com/cd/E83857_01/paas/autonomous-database/adbsa/backup-restore.html#GUID-9035DFB8-4702-4CEB-8281-C2A303820809>
Q: Autonomous Database Shared型の自動バックアップのタイミングは指定できますか?\nA: 現時点でタイミングを指定することはできません。なお、取得したバックアップの情報は下記SQLで確認いただくことが可能です。TAG列の先頭の値でバックアップタイプが判断できます。
Q: ソースADBがあるリージョンと異なるリージョンのバックアップ(リモート・バックアップ)を取ることは可能ですか?\nA: ADBの自動バックアップ機能では遠隔地(別リージョン)へバックアップすることはできません。ADBにおけるDR対応は下記の方法がございます。 ・Autonomous Data Guardを使用し、スタンバイDBを構成する ・バックアップベースのディザスタ・リカバリのクロスリージョン・バックアップ・コピーを構成する ・別リージョンにクローンを作成する(平時はインスタンスを停止することでOCPUの課金は抑えることが可能です) ・Data Pumpで Object Storageに論理バックアップを取得し、Object Storageのリージョン・コピー機能で別リージョンに複製する
** Cohere embed-multilingual-v2.0 **
['adb-034', 'adb-035', 'adb-030', 'adb-024', 'adb-045']
Q: 60日以上バックアップを保存する方法はありますか?\nA: 長期バックアップを利用すれば、最低3カ月最長10年間バックアップを保存可能です。ただし、長期バックアップはリストア不可、そのバックアップをソースとしたクローン作成のみ可能となっている点、保存先はExadataストレージになるのでExadataストレージ分の課金が発生する点にご注意ください。(2023/3時点)詳しくはこちら<https://docs.oracle.com/en/cloud/paas/autonomous-database/adbsa/backup-long-term.html#GUID-BD76E02E-AEB0-4450-A6AB-5C9EB1F4EAD0>をご参照ください。もしくは先述のData Pumpを利用した論理バックアップを取っておくことで、60日以上のバックアップを保存することが可能です。
Q: ソースADBがあるリージョンと異なるリージョンのバックアップ(リモート・バックアップ)を取ることは可能ですか?\nA: ADBの自動バックアップ機能では遠隔地(別リージョン)へバックアップすることはできません。ADBにおけるDR対応は下記の方法がございます。 ・Autonomous Data Guardを使用し、スタンバイDBを構成する ・バックアップベースのディザスタ・リカバリのクロスリージョン・バックアップ・コピーを構成する ・別リージョンにクローンを作成する(平時はインスタンスを停止することでOCPUの課金は抑えることが可能です) ・Data Pumpで Object Storageに論理バックアップを取得し、Object Storageのリージョン・コピー機能で別リージョンに複製する
Q: 自動バックアップからのリストア時間はどれくらいでしょうか?\nA: データ量、更新量に依存するため変動する可能性はありますが、サービスレベル目標についてはこちら<https://docs.oracle.com/en-us/iaas/autonomous-database-shared/doc/availability-slo.html>を参照ください。
Q: ディザスタリカバリ(DR/Disaster Recovery)は可能でしょうか?\nA: 可能です。Autonomous Data Guardをリージョン内(ローカル)、クロス・リージョンで構成することができます。また、バックアップベースのディザスタ・リカバリというオプションもございます。リモート・リージョンにバックアップのコピーを保持しておくことが可能です。
Q: ハッキングや、ウィルス対策はどの様になっていますでしょうか?\nA: オラクル社にて対策を十分に講じております。セキュリティ・ポリシーに関してはセキュリティガイド<https://docs.oracle.com/cd/E97706_01/Content/Security/Concepts/security_guide.htm>を参照ください。
** Cohere embed-english-v2.0 **
['adb-023', 'adb-027', 'adb-034', 'adb-044', 'adb-031']
Q: 一時表領域のサイズは決められますか?\nA: ストレージサイズの30%が最大サイズで自動拡張され、ユーザーは変更不可です。ページトップに戻る<#>
Q: バックアップは開始時点でスナップショットが取得されるのでしょうか?その場合、バックアップの完了を待たずともDDL/DML/起動停止等の操作は可能ですか。\nA: Autonomous Database は、ストレージ装置のスナップショット機能によるバックアップは採用しておらず、RMANを利用して60日ごとにフルバックアップ、週次で累積バックアップ、日次で増分バックアップを取得しております。増分バックアップの間の更新についてはアーカイブ・ログが取得されております。 これらのバックアップとアーカイブ・ログを利用することで、バックアップ保持期間の60日の間であれば任意のタイミングに戻すことが可能です(Point-In-Timeリカバリ)。従いまして、バックアップの断面を気にしていただく必要はありません。 ただし、Autonomous Database のリカバリは秒指定で行うため、断面でのリカバリが必要な場合は、アプリケーション側で静止点を確保し、その時間を指定してリカバリを行ってください。参考マニュアル Autonomous Databaseのバックアップおよびリストア<https://docs.oracle.com/cd/E83857_01/paas/autonomous-database/adbsa/backup-restore.html#GUID-9035DFB8-4702-4CEB-8281-C2A303820809>
Q: 60日以上バックアップを保存する方法はありますか?\nA: 長期バックアップを利用すれば、最低3カ月最長10年間バックアップを保存可能です。ただし、長期バックアップはリストア不可、そのバックアップをソースとしたクローン作成のみ可能となっている点、保存先はExadataストレージになるのでExadataストレージ分の課金が発生する点にご注意ください。(2023/3時点)詳しくはこちら<https://docs.oracle.com/en/cloud/paas/autonomous-database/adbsa/backup-long-term.html#GUID-BD76E02E-AEB0-4450-A6AB-5C9EB1F4EAD0>をご参照ください。もしくは先述のData Pumpを利用した論理バックアップを取っておくことで、60日以上のバックアップを保存することが可能です。
Q: ウイルスソフトは導入できますか?\nA: OSレイヤーは解放していないため、ウィルスソフトのインストールはできません。オラクル社にて対策を十分に講じておりますので、お客様側で対応いただく必要はございません。
Q: バックアップを任意の場所にリストアすることや、BaseDBなど別のサービスに展開することは可能ですか?\nA: できません。Autonomous Database のバックアップは、同じデータベースにリストアしてデータを復元する目的にのみ使用できます。バックアップからではなく、Data Pump でオブジェクト・ストレージにエクスポートし、別のサービスへインポートを行うことや、クローン機能でクローンやリフレッシュ可能なクローンを別のコンパートメントに作成することをご検討ください。
** Sentence Transformers all-MiniLM-L6-v2 **
['adb-023', 'adb-027', 'adb-034', 'adb-044', 'adb-031']
Q: 一時表領域のサイズは決められますか?\nA: ストレージサイズの30%が最大サイズで自動拡張され、ユーザーは変更不可です。ページトップに戻る<#>
Q: バックアップは開始時点でスナップショットが取得されるのでしょうか?その場合、バックアップの完了を待たずともDDL/DML/起動停止等の操作は可能ですか。\nA: Autonomous Database は、ストレージ装置のスナップショット機能によるバックアップは採用しておらず、RMANを利用して60日ごとにフルバックアップ、週次で累積バックアップ、日次で増分バックアップを取得しております。増分バックアップの間の更新についてはアーカイブ・ログが取得されております。 これらのバックアップとアーカイブ・ログを利用することで、バックアップ保持期間の60日の間であれば任意のタイミングに戻すことが可能です(Point-In-Timeリカバリ)。従いまして、バックアップの断面を気にしていただく必要はありません。 ただし、Autonomous Database のリカバリは秒指定で行うため、断面でのリカバリが必要な場合は、アプリケーション側で静止点を確保し、その時間を指定してリカバリを行ってください。参考マニュアル Autonomous Databaseのバックアップおよびリストア<https://docs.oracle.com/cd/E83857_01/paas/autonomous-database/adbsa/backup-restore.html#GUID-9035DFB8-4702-4CEB-8281-C2A303820809>
Q: 60日以上バックアップを保存する方法はありますか?\nA: 長期バックアップを利用すれば、最低3カ月最長10年間バックアップを保存可能です。ただし、長期バックアップはリストア不可、そのバックアップをソースとしたクローン作成のみ可能となっている点、保存先はExadataストレージになるのでExadataストレージ分の課金が発生する点にご注意ください。(2023/3時点)詳しくはこちら<https://docs.oracle.com/en/cloud/paas/autonomous-database/adbsa/backup-long-term.html#GUID-BD76E02E-AEB0-4450-A6AB-5C9EB1F4EAD0>をご参照ください。もしくは先述のData Pumpを利用した論理バックアップを取っておくことで、60日以上のバックアップを保存することが可能です。
Q: ウイルスソフトは導入できますか?\nA: OSレイヤーは解放していないため、ウィルスソフトのインストールはできません。オラクル社にて対策を十分に講じておりますので、お客様側で対応いただく必要はございません。
Q: バックアップを任意の場所にリストアすることや、BaseDBなど別のサービスに展開することは可能ですか?\nA: できません。Autonomous Database のバックアップは、同じデータベースにリストアしてデータを復元する目的にのみ使用できます。バックアップからではなく、Data Pump でオブジェクト・ストレージにエクスポートし、別のサービスへインポートを行うことや、クローン機能でクローンやリフレッシュ可能なクローンを別のコンパートメントに作成することをご検討ください。
まとめ
専門的なことを聞くと本当っぽいけど間違ったことを回答されることが多いので GPT で正確性を求められるアプリケーションを作るのは難しいなぁと感じていましたけど、この手法でかなり現実性が増すのではないかと思います。それと、プロンプトに回答するLLMはあんまり知識を持っていないほうがむしろ好都合なのかなとも考えました。日本語対応でオープンソースの小さなLLMと組み合わせて試してみようかな...。
今回はベタにコーディングしましたが、次回はこのあたりをまるっとやってくれる LangChain や LlamaIndex を使ってもう少し抽象化したバージョンにしてみたいと思います。