本記事は、ETロボコン&EV3 Advent Calendar 2018 の記事です。
はじめに
こんにちは、関西の方でETロボコンの実行委員をやってる者です。
2012~2015まで選手やってて2016年から実行委員をやっていますが、
いまだにゴリゴリと開発をしています。難所攻略が趣味みたいな状態です。
むしろ選手時代後半よりもやる気があります。会社とかモデル提出とかなくて気楽にできるからでしょうか。
というわけで今年も地区大会のエキシビジョンとして走らせました。
実行委員権限で参加費を払わずに地区大会を走るという職権乱用です。
そもそも参加費払うどころか交通費を頂いてETロボコンやってます。
みなさんも実行委員になりましょう。
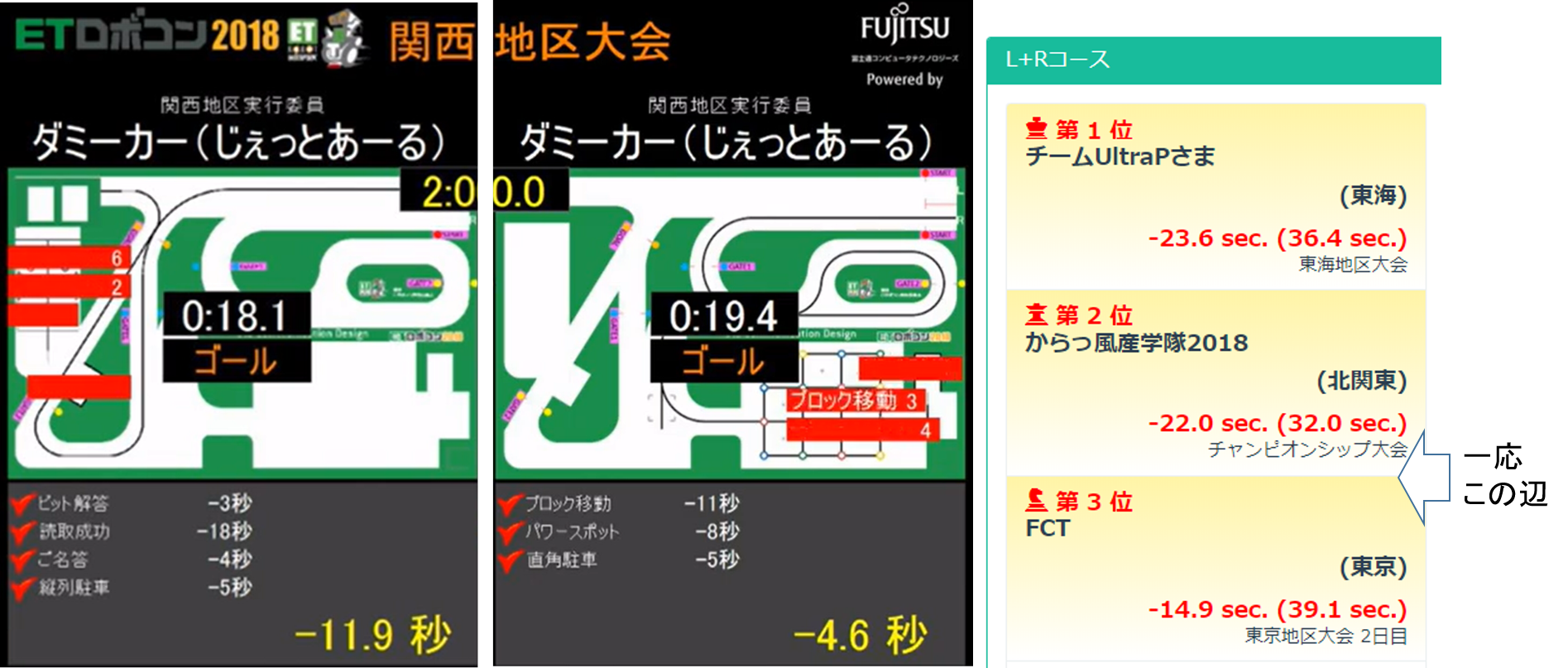
そして今年走った結果は↓のような感じでした。
だいぶ頑張りました。
↓ 4:31:35ぐらいから
https://www.youtube.com/watch?v=5H_pSSI5Qo8
実際、これぐらい出せるポテンシャルあるけど本番コケたというチームは結構あったと思います。
その辺りは地区大会前日の準備日に本番コースを3~4時間ぐらい使用できたという実行委員のアドバンテージです。
本記事は、そこそこ走れたので開発のノウハウを記しておこう、というところです。ETロボコン参加者は半数が企業チームということもあり、なかなか情報を外に出しにくいですからね。
今年は自前でSimulinkを使ったシミュレーション環境を構築したり、技術的なネタになりそうなことやったんですが、結局、汎用的な内容にしました。
ライントレース、駐車場、ブロック並べ、AIアンサーでやったことを広く浅く薄く書いてきます。趣味の活動なので話半分で読んでいただければ。
ライントレース
Lで18秒、Rで19秒台で走行しました。
個人の開発なのでフルコースは持ってなく、調整は地区大会前日の準備日だけでする必要がありました。
そのためできるだけ簡素に調整できるような工夫をしてます。
走行アルゴリズムはよくある普通のPD制御です。I制御は無し、ゲインは直線もカーブも同じです。できるだけ簡素です。
Pゲインはやや強めでぎりぎり振動しない程度にしてます。
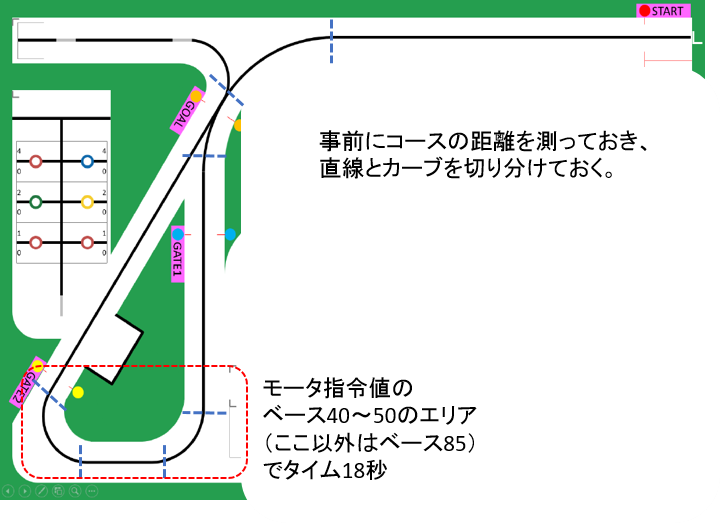
「走行距離」で直線とカーブを区分けし、カーブでは同じ制御ゲインで曲がり切らせるため、単純に減速させています。
直線ではモータへの指令値のベースを85、カーブはLの一番きついカーブでベースを40~50ぐらいです。
カーブは結構減速していることになるので、16秒台を狙うには、カーブで外輪が80~90で走れるよう、ゲインを変えるなり、曲率に応じて左右差をつけるなりが必要そうです。とても手が出ません。
カーブで曲がり切れる速度というのは、実際に走らせて確認しています。
Bluetooth通信で内部の変数をリアルタイムに書き換えるツールを自作しているので、それぞれのカーブの手前に走行体を置いて、速度を少しずつ変えながらのライントレースを繰り返し、曲がり切れる速度と曲がりきれない速度の境目を見つけて設定します。
(効率化の工夫として、暴走しないように、10cm連続で白色を検出したら止まる、というような処理をしてます。)
大会前日だけで調整するために、あらかじめ、自作のシミュレーション環境を使って直線とカーブを区分けするための距離を測定しておき、Cコードで、距離に応じた速度を設定可能にして望んでいます。
<性能がよくなった(?)HackEV>
今年はタイヤがでかくなってライントレース難しくなるかな? と思いましたが、あまり気になりませんでした。
2016,2017とほぼ同じ制御でそのまま走って、速くてより安定になりました。
なぜかなのか考えてみます。
①速度
一般論では、タイヤがでかくなると、最高速が上がる一方、トルクで不利、つまり加減速の応答が悪くなります。
これは指令値がPWM(≒電圧)の場合にあてはまります(NXTはこれでした)。
しかしながらEV3のモータは内部で回転数(回転速度)制御が行われているようで、例えば指令値に50を入力すると
「50%の速度で回転しろ」という意味になっています。たぶん。
そのため、タイヤが大きくなっても、EV3が同じ速度で回転させようとしています。
(バッテリ残量が減っても中~低速域ではほぼ影響がないのもこのためだと思います。)
そのため加減速の応答悪化が殆ど気にならず、最高速向上の恩恵だけ受けている気がします。
②カラーセンサ
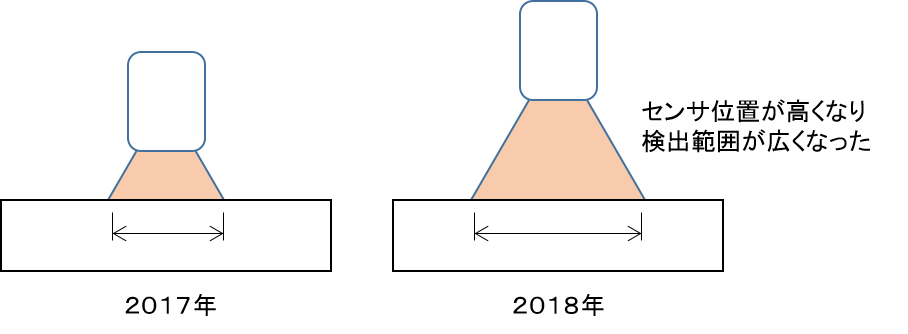
タイヤがでかくなったことで床面とカラーセンサ間の距離が伸びました。
伸びたことがメリットになっていて、従来よりセンシング範囲(センサで光ってる範囲)が広くなっています。
従来直径20mmぐらい→今年30mmぐらい。 横変位がより広く検出できるようになっています。
デメリットとして、これも直感的には、外乱に弱くなるとか検出性能の低下、とか発生しそうですが、外乱はEV3が勝手に補正してくれてます。NXT時代と比べるとほんとに楽ちんです。
検出性能は、輝度モード(床面に赤丸LED)だと非常につらく、黒0白20ぐらいの検出値だった気がします。これで走るとふらふらしてました。
しかし、RGBモード(床面に白丸LED)にすれば黒5白100ぐらいの幅はあるのでトレースするのに十分です。
結局、デカタイヤによって、最高速度が向上して、カラーセンサの検出範囲が広がった、ということで走行体の性能がよくなったといえるのでは、と思います。
駐車場
L,Rともに成功しました。どっちが直角駐車だったかすぐわからなくなります。
開発は、これまでのソフト資産をフル活用し、試走会2の運営中に作り始めてその日のうちに完成しました。
選手の皆さんが試走してるのを監視しながらコードを書いて、シミュレーションして、試走の合間の空き時間に走らせ、完成です。
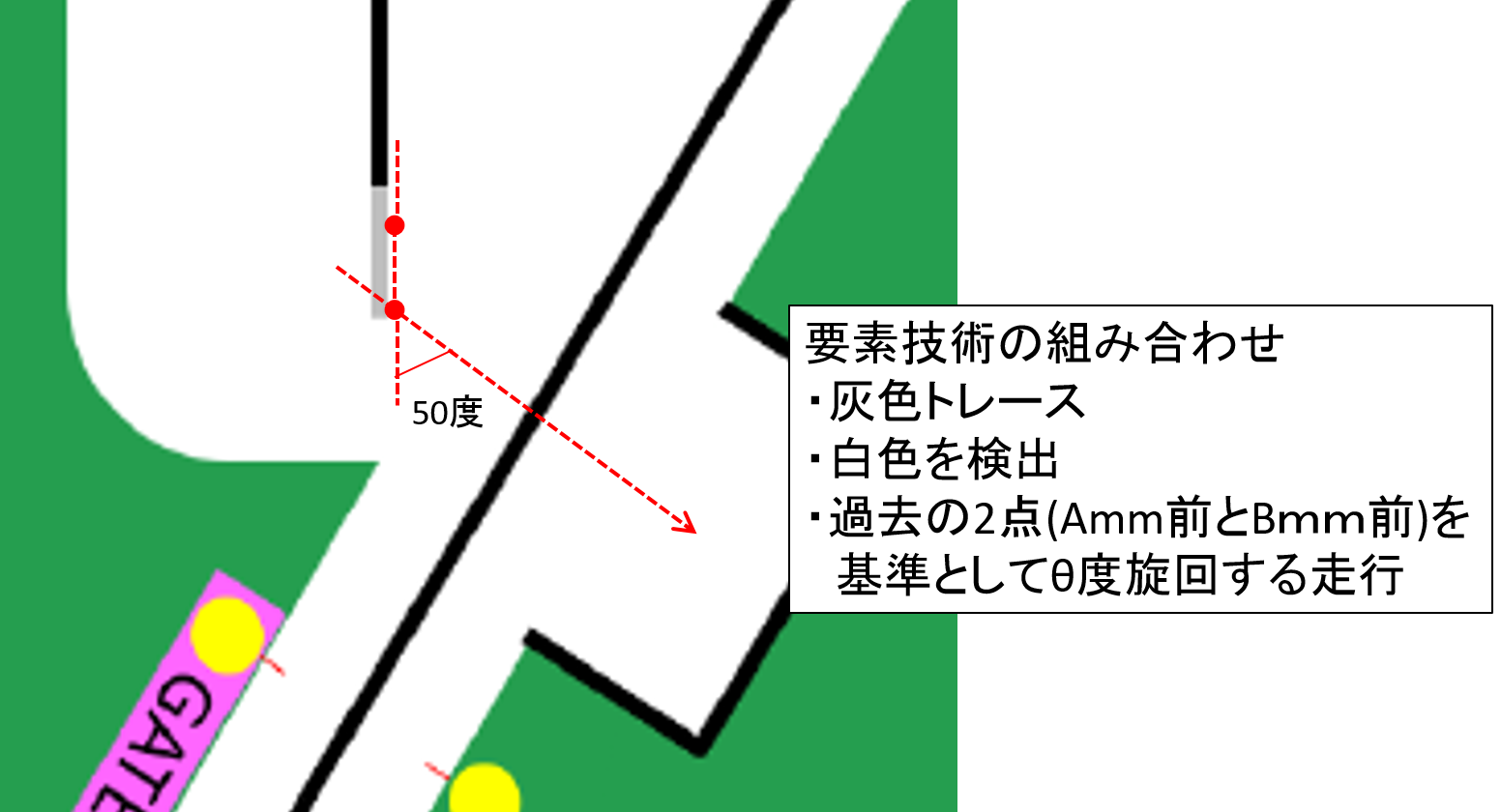
主に下記の要素技術でできています。
①灰色をトレース
②白色を検知
③過去の2点(直線)を基準に、指定した角度の方向へ指定した距離走行する
ブロック並べ
3個有効移動、パワースポット4個でした。1個、練習で経験のない形でミスりました。ブロックの摩擦が開発環境とは違った~、とかでしょうか。
7月ごろから作り始めて8月下旬に探索アルゴリズムができて9月始めに走行制御まで完成しました。8月下旬頃から「ヤバイ間に合わない」という気配がでてきたので本腰入れ始めてます。
アルゴリズムはダイクストラで探索してます。
↓を参考にさせていただきました。コードのベースにさせていただき、コスト条件等を拡張しています。
https://qiita.com/edo_m18/items/0588d290a19f2afc0a84
コストはノード間の距離の他、旋回角度を適当に重みづけして考慮しています。旋回角度は45度を超えてくると精度よく回るのに時間がかかるので高コスト、というような感じです。
ノードはブロック置き場とその間のライン上に設定します。
ノード間のつながりは↓のような感じです。距離と交点の角度で条件を決め、自動的につなげてます。とても手作業では無理です。
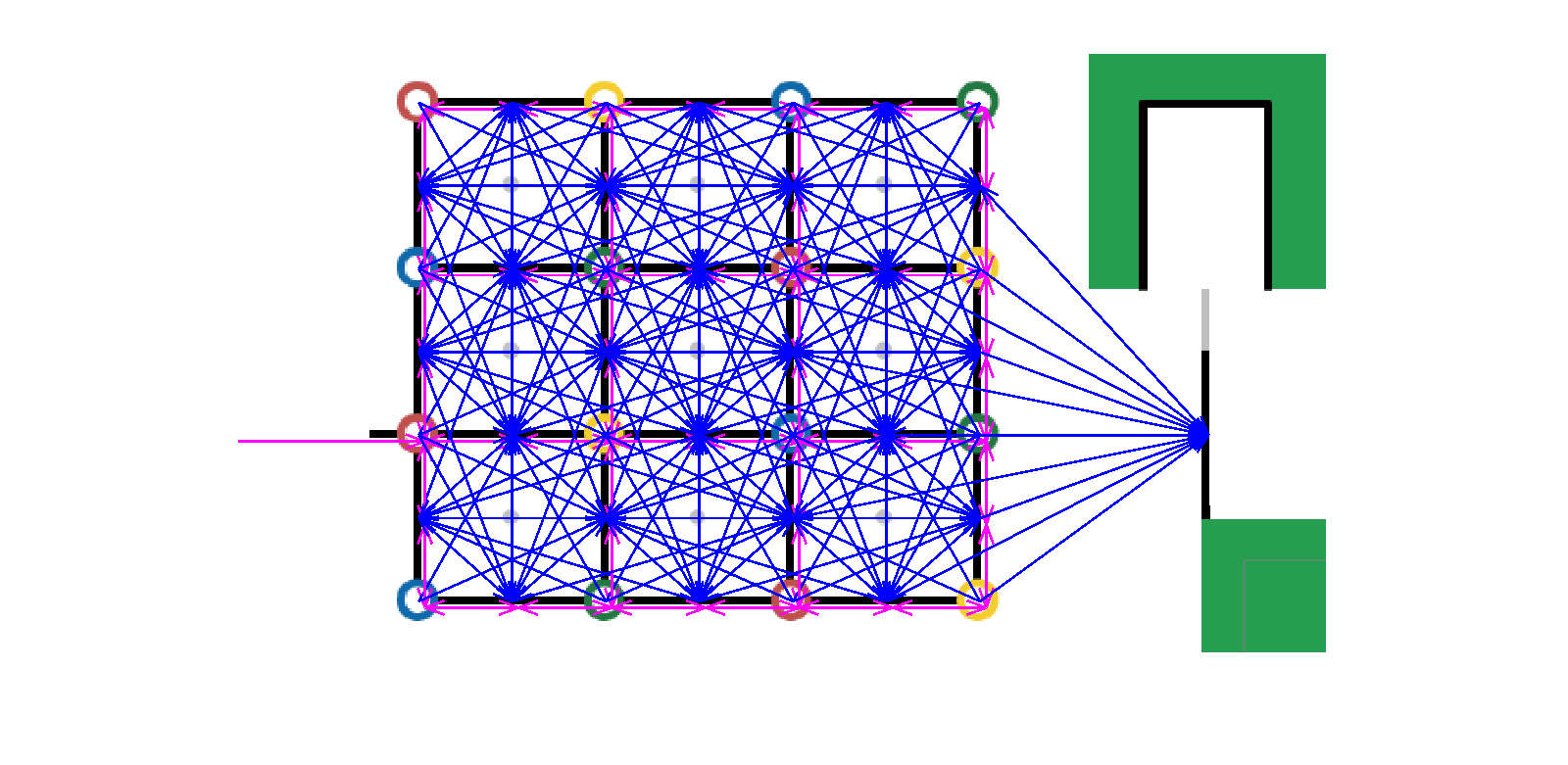
ブロック並べは、まずは探索アルゴリズムを作りますが、そこでいきなり走行体を使って動作確認をしだすととても終わりません。
まずは、Cygwin上のCUI(gcc)で探索の関数を実行して、経路のノードやブロックの位置をprintfやcoutで表示させ、MATLAB(home)で可視化して探索が正しいか確認する、という手順でアルゴリズムを確立させました。
↓はMATLABで作った簡単な可視化ツールで探索経路とブロックの移動を示しています(小四角が初期、大四角が移動後のブロック位置)。
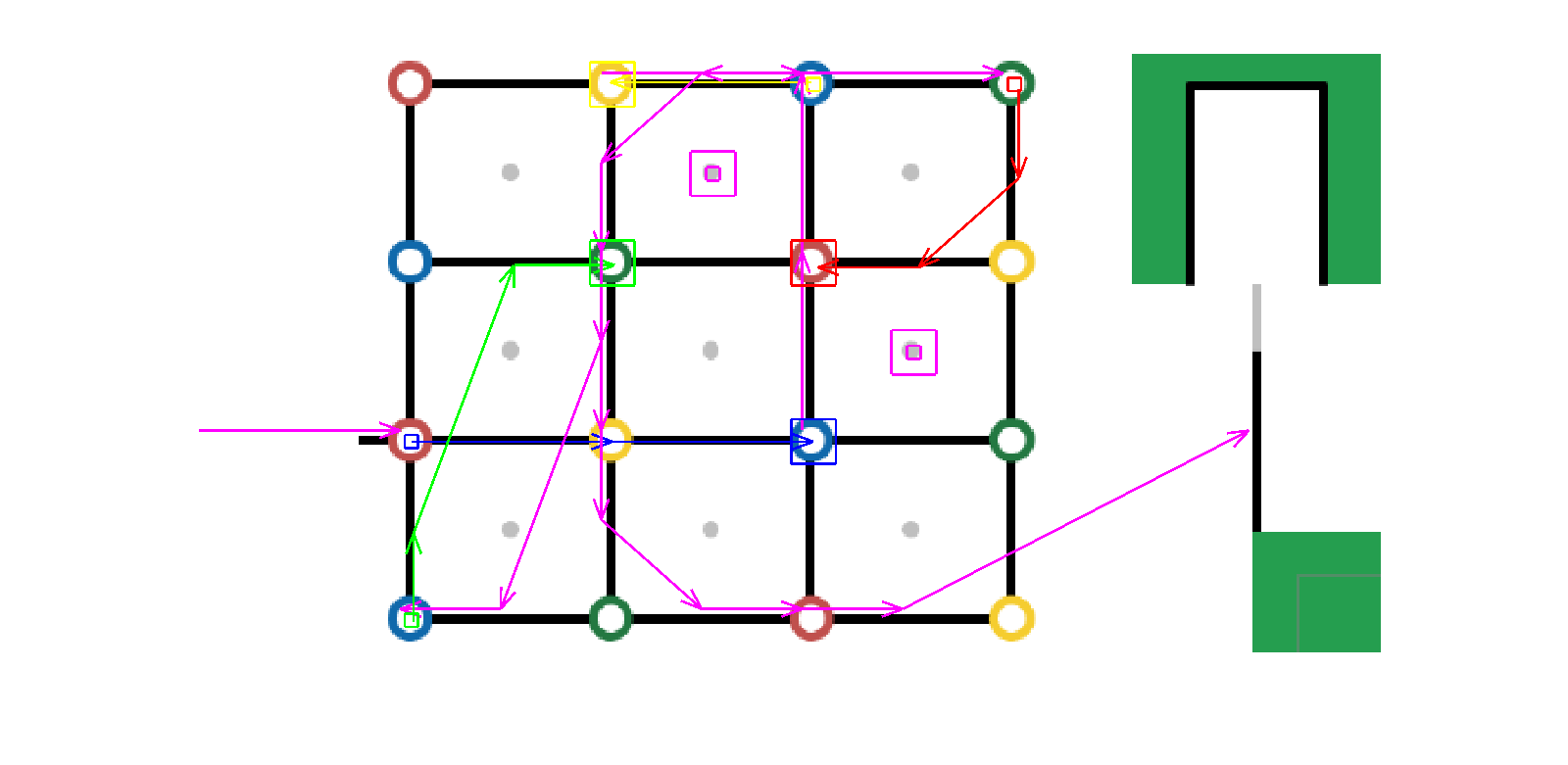
急がば回れで、このような確認ツールがないと、なかなか作りきるのは難しいのではと思います。
探索アルゴリズムができたら走行制御です。コースと走行体が気兼ねなく使える環境ならいいですが、そうでないので、シミュレーションを作りました。走行の軌跡だけですが示しておきます。
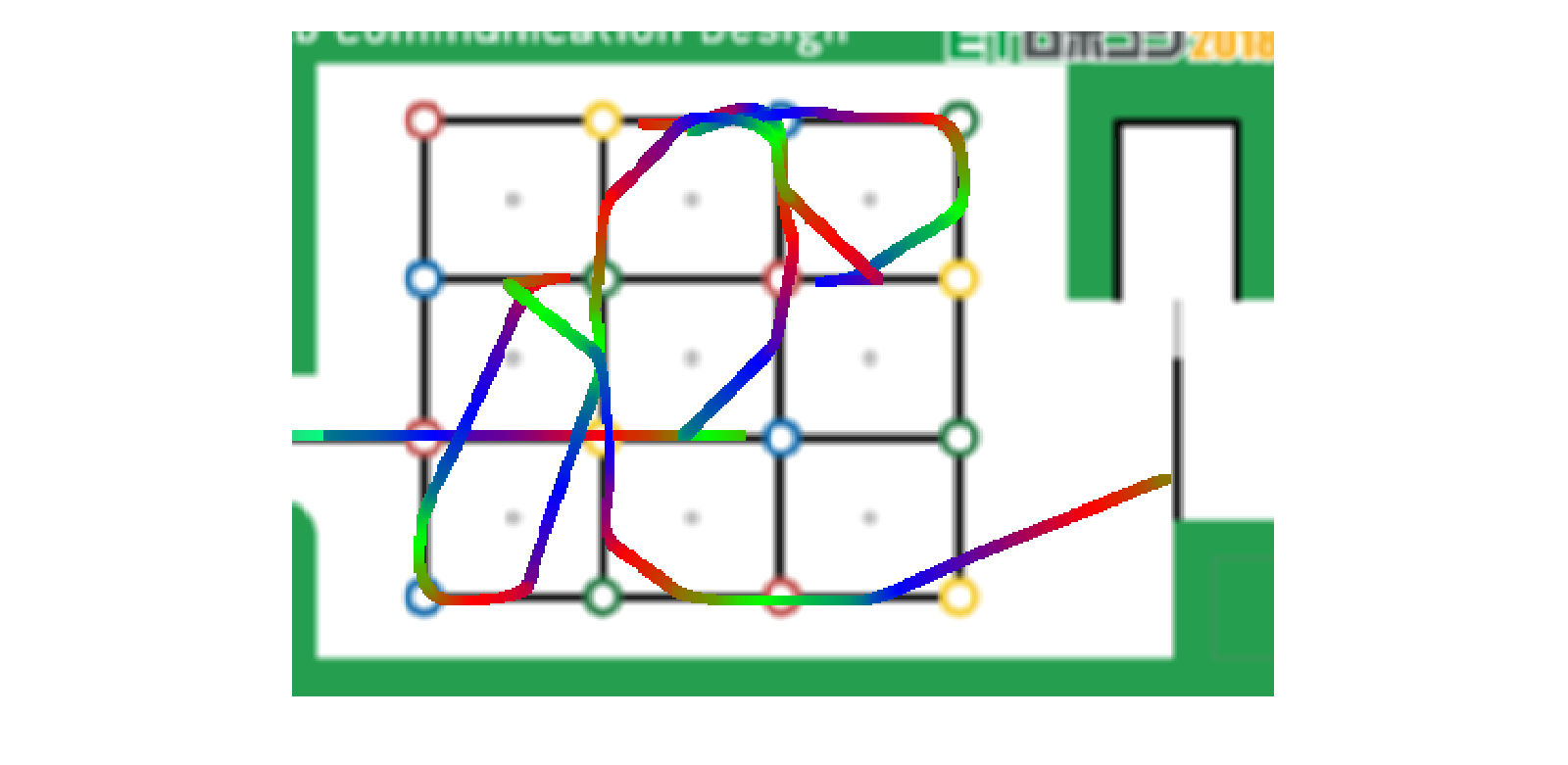
ちなみに上記の動きは↓で動画にしてます。(黒ブロックの置き場が間違ってますが…)
<新要素 カメラについて>
実行委員が消極的で恐縮ですが、以下の理由で使っていません。
-1~2個のブロックの色を見れば他の色が全て確定できてしまう
今年のルールはブロック4個に対して4色Unknownということで、情報処理すると色が推定できます(ちなみに2016年は4個に5色なので無理でした)。
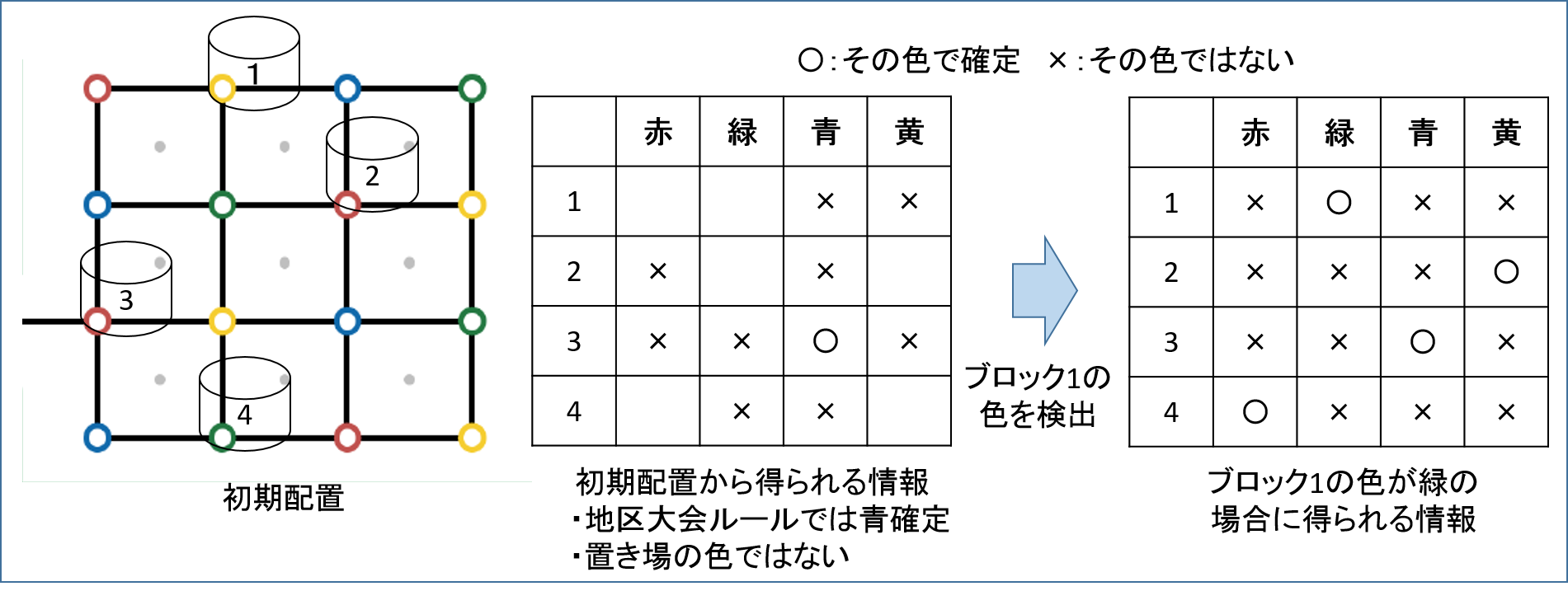
「初期のブロック置き場の色」と「既知のブロックの色」から、特に青色が既知の地区大会では、高い確率(配置が無作為なら9割ぐらい)で、1個の色だけをセンサで確認すれば、4個すべての色を確定できる、という感じだったので、色を検知するための時間コストは小さいと判断しました。
~考え方~
開始時点で、青以外のブロックの色は、
「青色ではない」
「置かれているブロック置き場の色ではない」
ので、置き場が青でなければ、候補は2色に絞られます。あと、1色がわかれば、いろいろ確定しそうな感じなわけです。パワースポットとか考慮するとどこから色を見るかの戦略は多少複雑化しますが、概ねこのような感じです。
-カメラのメリット
使うことのアドバンテージは、走りだす前に色が全てわかるので、初手から駐車場までの経路の全探索が可能になることです。
2017年の探索アルゴリズムがそのまま流用できそう(走り出す前に全ブロックの色が既知のルールでした)で、完全な最短経路が探せるのがメリットです。
しかしながら、カメラを使わない場合、過去資産の流用なら2016年のがだいぶ使えそうですし、全探索せず、逐次ブロックの色を調べながら攻略しても概ね2分に間に合いそうなのであまりメリットがなく・・・。
パワースポットに関してカメラを使わないと厳しい初期配置とか考えられますが、ランダムで難易度に差が出すぎてもダメなので、あまり極端な配置はしないですからね。
-楽をしたい
Bluetooth接続のデバイスを、あえてシステムに組み込むかどうか。フォルトトレラント考えるとやること増し増し。
1人でやってるので楽をしたい。。。
-開発環境
これが一番大きいですが、コースを自作して自宅で開発してましたが、部屋のスペース的にカメラ置き場が確保できませんでした。

というわけで戦略的な観点だけを見るとメリットは小さかったような気がしています。2019年のルールは2018年にカメラ使ったチームにアドバンテージがあるルールだといいですね。
AIアンサー
今年の目玉ですね。ご名答できました。
やはりAIとは何かを考えさせられる課題です。
↓に練習走行の動画を上げています。
https://www.youtube.com/watch?v=VWIUY798MHE
数字認識のアルゴリズムは5月ごろからずーっと頭で考えていて、作り始めたのはブロック並べが完成した9月からでした。
とてもがんばってほぼ1週間で仕上げています。
平日は退社後はフルに開発、実際会社の昼休みもコード書いてました。そもそも着手開始が大会2週間前というのがダメです。
本番環境での調整で一番時間がかかりました。開発環境と本番環境の差異が最も大きい難所でした。
AIアンサーにたどり着いたけれど、認識アルゴリズムではなく、マット上の走行制御で失敗したチームも多からずあったのではないでしょうか。
<環境の違い要因>
-OPP袋が照明で光る?
数字の白枠と緑の間をトレースしてましたが、自宅の開発環境と本番環境で結構挙動が違った気がしています。
横位置が少しずれてたような? 紙の材質の差異かもしれませんが、数字を入れているOPP袋が結構キラキラしてたので影響あったかもです。気のせいかもですが。
-数字の印刷された紙質が良い、そのため黒文字のセンサ値が明るい
関西大会では数字の黒につやがあり、しかも何故か微妙にRGBのGが大きかったです。そのため光沢の無いマットの緑地より、黒文字の方がセンサ値的には緑でした。(ちなみに開発環境では、安い紙に印刷していたので、黒文字は普通に黒でした。)
マットの緑を判別してスキャン走行をしていたため、正直もう無理と思いましたが、なんとか前日中に対応できました。
こういう違いをあらかじめ知るために、公式試走会が重要なわけです。
<数字認識手法>
新難所は、各チームが様々な戦略を考えてくるから面白いです。
何年か経つとベターな手法が定まってきますからね。
自分は以下の戦略を考えました。たぶん1回ぐらいしか試してない数字とかありますが、狙った付近をスキャンできていれば、認識ミスはなく、まあぼちぼちの精度だったと思います。
-スキャン走行
経路の図は下のほうにあります。白の長さも重要視していたのでバックで走りました。
とりあえず、開発工数削減のため2フォントとも同じ位置をスキャンして同じアルゴリズムで処理してます。
(フォントごとに変えてるチーム多かったけど、やること増えて逆に大変では、、。)
-手法 ~概要~
1から考案したので何手法というのか名前はわかりません。
簡単に書くと、スキャンしたデータをベクトルで表し、数字のリファレンスデータもベクトルで表して、ベクトルの距離が一番小さい数字を探す、という感じです。どこかで出てきそうな考え方です。
-手法 ~ベクトル化~
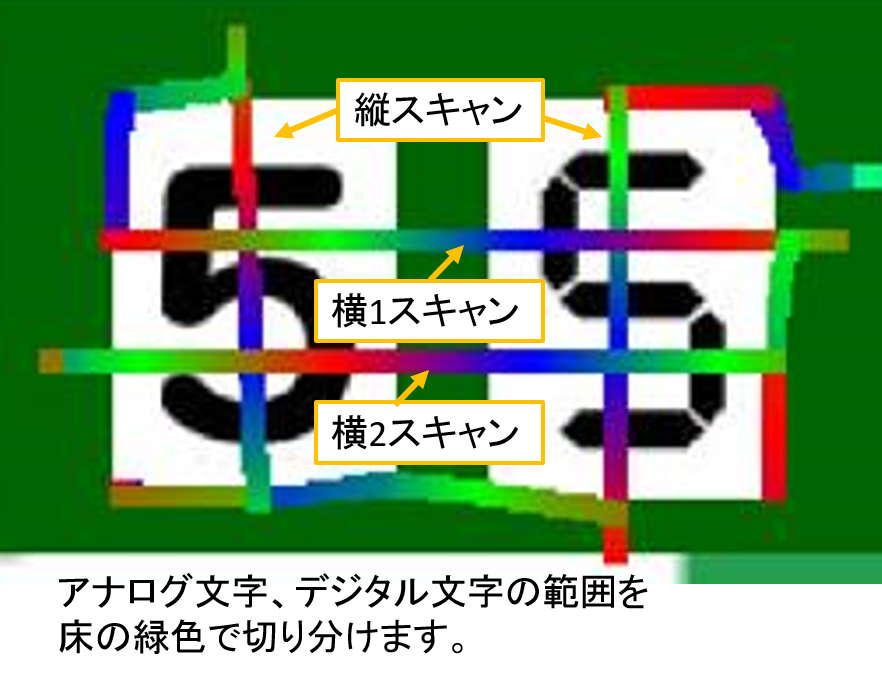
スキャンは端(緑)から端(緑)の直線を走り、カラーセンサとモータのエンコーダで白と黒の長さを取得します。そして読み取りデータに出てくる黒の回数に応じて以下のようにベクトル化します。
ベクトルというと難しそうですが、要は、数値を複数持つ配列データとして扱うようにしているだけです。
黒なし→ ( 白の長さ )1次元
黒1か所→( 白長, 黒長, 白長 )の3次元
黒2か所→( 白長, 黒長, 白長, 黒長, 白長 )の5次元
黒3か所→( 白長, 黒長, 白長, 黒長, 白長, 黒長, 白長 )の7次元
スキャンデータとして横1,2と縦の計3つのベクトルデータを得ます。
次に、同様のベクトル化を数字画像に対してあらかじめ行っておき、0~7の数字それぞれのリファレンスデータとして走行体に保持させます。
↓図のようなイメージで縦横20mmの間隔でベクトル化しました。

-手法 ~ベクトルの比較による数字推定~
スキャンデータのベクトルとリファレンスデータのベクトルを比較して出題数字を推定します。
基本的な考え方は、ベクトルの距離(いわゆる2点間の距離、ユークリッド距離)を計算して、一番距離が小さいリファレンスデータの数字が出題数字だろう、という感じです。

具体的に、スキャンデータと0~7各数字のリファレンスデータを順に比較していきます。
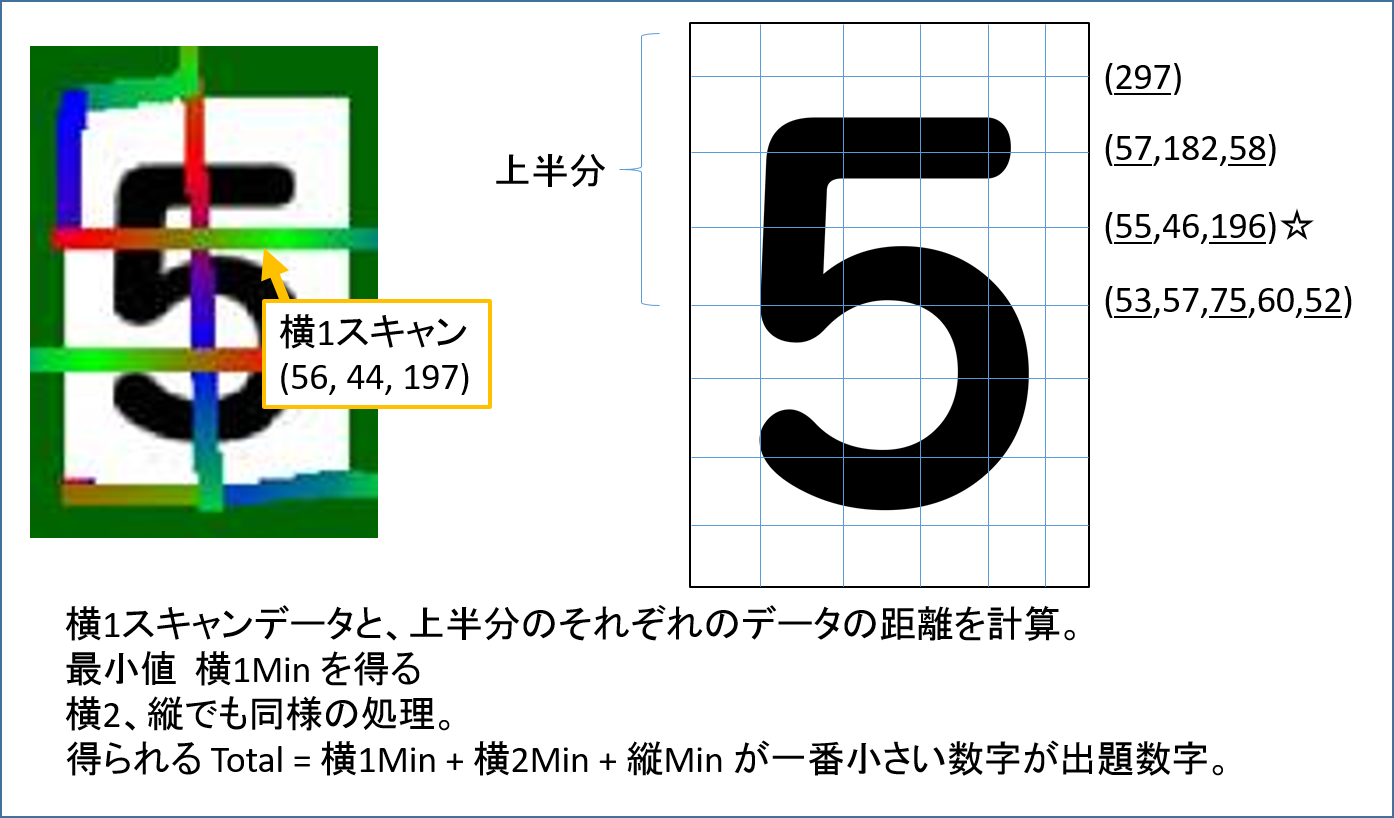
比較の方法として、まず、横1スキャンデータと、各数字の上半分のリファレンスデータで同じ次元のベクトルで距離を比較し、上半分の中で最小の距離、横1Minを得ます。
次に、横2スキャンデータと下半分のリファレンスデータ、縦スキャンデータと縦リファレンスデータで同様に、横2Min、縦Min を得ます。
同じ次元がなかったらその数字は無視します。
数字毎に
Total = 横1Min + 横2Min + 縦Min
を計算し、Totalが最も小さい数字が出題数字と推定する。という感じです。
この手法のメリットとしては
・3領域それぞれで一番距離が近いところを探して比較しているので、スキャンが少しずれても結構ロバスト
・演算コストが制御に気にならない程度に小さい
といったところでしょうか。
定量的な性能評価はまったくしてないです・・・。
おわりに
以上、長々と書いてわかりにくいところも多いと思います。書きたいことを書きなぐった感じです。実行委員なら色々モデルで華麗に表現すべきなのですが、、。
あとはシミュレーションについて書きたかったですが、もう時間的に厳しそうです(追記:書きました)。世の中的にも業界によって結構大事で、やはり効率化が望めます。
2019年のルールがどうなるのか全く存じ上げませんが、お役に立てば幸いです。