ETL・パイプライン(+モニタリング)
フロー:DataLake → Glue → Data Ware House

DataLake(S3)に蓄積した(CSV)ファイルを、Glueで加工・修正し、Data Ware House(Athena/Redshift)へ連携します。
※Athena/Redshiftと記載しているのは、初期はAthenaで構築し、将来的にRedshiftに切り替える想定のためです。Redshiftの利用コストが高いためです。
最後に、Athena/Redshiftで抽出・集計したテーブルデータをQuickSightで可視化します。
順に紹介していきます。
DataLake(S3)
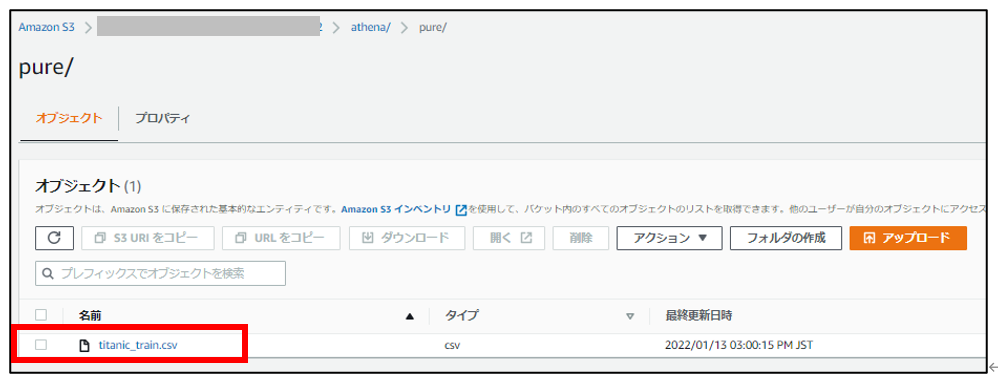
S3バケットにkaggleのタイタニックのデータセット(訓練データ)をアップロードします。
# ----------------------------------
# S3 private bucket3 for data
# ----------------------------------
resource "aws_s3_bucket" "s3-private-bucket-data" {
bucket = "${var.project}-${var.enviroment}-private-bucket-data "
acl = "private"
# Manege version of S3 source
versioning {
enabled = false
}
# Encryption
server_side_encryption_configuration {
rule {
apply_server_side_encryption_by_default {
sse_algorithm = "AES256"
}
}
}
# Delete rule
lifecycle {
prevent_destroy = false
}
}
# Create directry
resource "aws_s3_bucket_object" "s3-private-bucket-data-object1" {
key = "athena/tmp/"
bucket = aws_s3_bucket.s3-private-bucket3.id
force_destroy = true
}
resource "aws_s3_bucket_object" "s3-private-bucket-data-object2" {
key = "athena/pure/"
bucket = aws_s3_bucket.s3-private-bucket-data.id
force_destroy = true
}
resource "aws_s3_bucket_object" "s3-private-bucket-data-object3" {
key = "athena/missing_proc/"
bucket = aws_s3_bucket.s3-private-bucket-data.id
force_destroy = true
}
resource "aws_s3_bucket_object" "s3-private-bucket-data-object4" {
key = "athena/cleansing_proc/"
bucket = aws_s3_bucket.s3-private-bucket-data.id
force_destroy = true
}
resource "aws_s3_bucket_object" "s3-private-bucket-data-object5" {
key = "athena_result/cleansing_proc/"
bucket = aws_s3_bucket.s3-private-bucket-data.id
force_destroy = true
}
# Access block
resource "aws_s3_bucket_public_access_block" "s3-private-bucket-data" {
bucket = aws_s3_bucket.s3-private-bucket-data.id
block_public_acls = true
block_public_policy = true
ignore_public_acls = true
restrict_public_buckets = true
}
resource "aws_s3_bucket"で、S3バケットの設定を定義します。
resource "aws_s3_bucket_object"で、構築したS3バケット内のフォルダ名を定義します。
※自動でフォルダを作成してくれます。
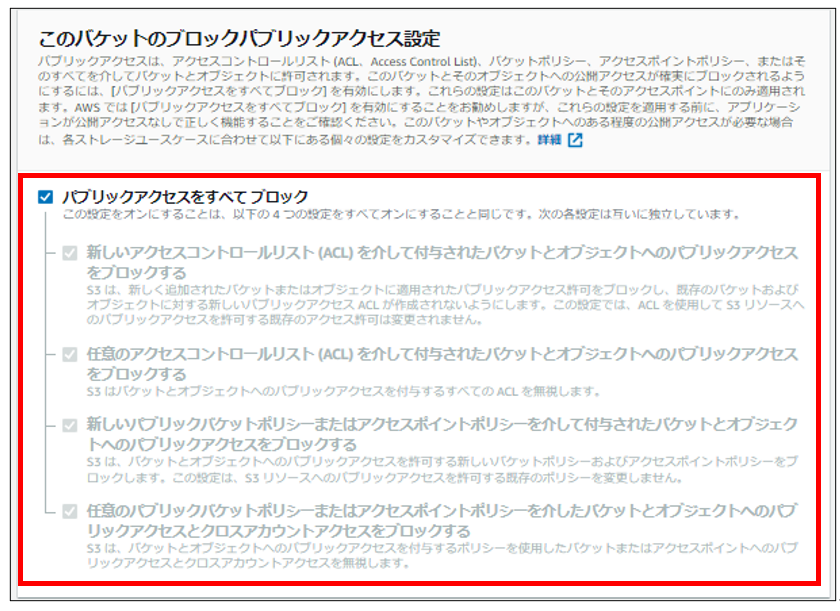
resource "aws_s3_bucket_public_access_block"で、パブリックアクセスのブロック設定をします。
コンソール画面の下記に該当します。
Glue(Glue DataCatalog & Job)
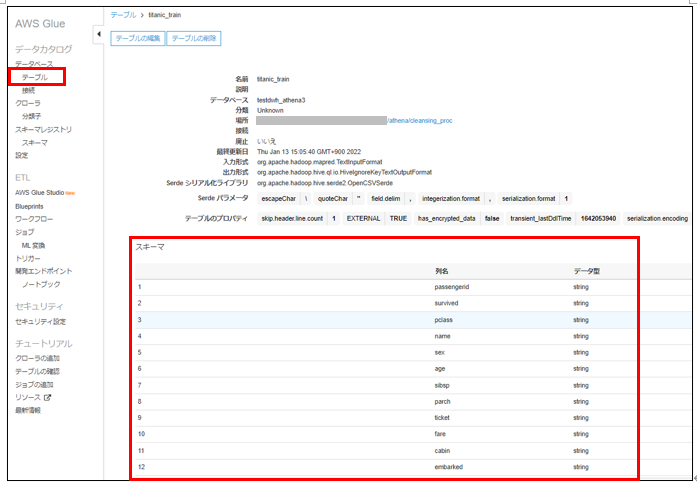
Glueテーブルは、Glue内で保持するスキーマ、インデックスなどを指しています。
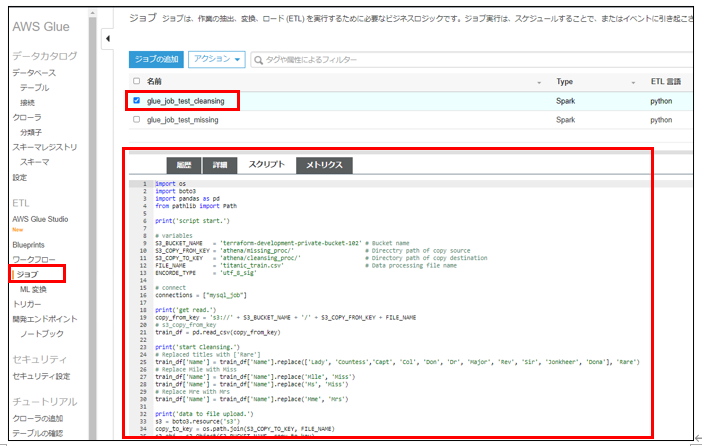
GlueのETLジョブの作成と監視に使用します。
ETLジョブの中身は、上記のスクリプトです。
今回はPythonで記載しています。
S3上にプッシュした「cleansing_proc.py」を(Terraformで)読み込ませています。
ETLジョブの実行状況も確認することができます。
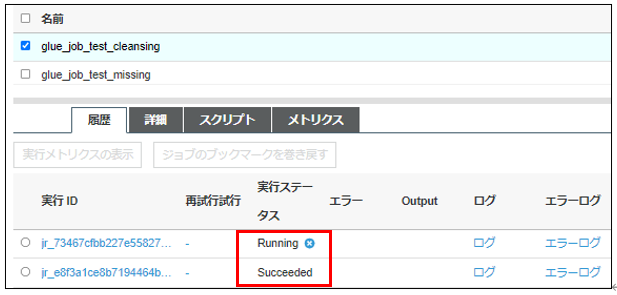
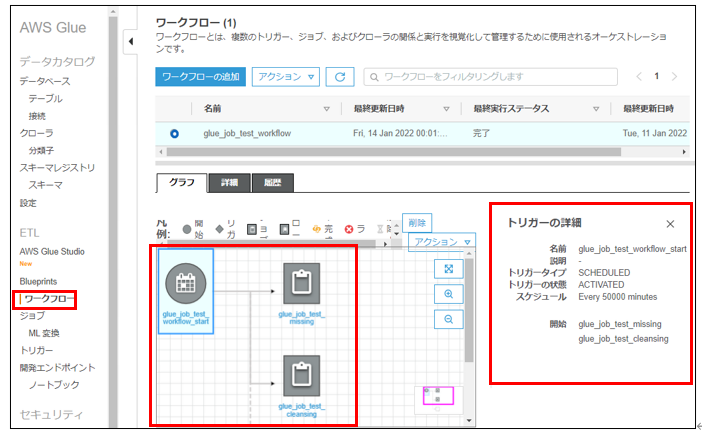
ワークフローへは、トリガーを設定し決められた条件で、先ほどの各ETLジョブが実行するよう設定しています。
# ----------------------------------
# IAM role
# ----------------------------------
resource "aws_iam_role" "role_glue" {
name = "role_glue"
assume_role_policy = <<-EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "glue.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
EOF
}
resource "aws_iam_instance_profile" "instance_profile_glue" {
name = "instance_profile_glue"
role = aws_iam_role.role_glue.name
}
# ----------------------------------
# IAM policy
# ----------------------------------
resource "aws_iam_policy_attachment" "glue_lambda_exe" {
name = "AWSLambda_FullAccess"
policy_arn = "arn:aws:iam::aws:policy/AWSLambda_FullAccess"
roles = ["${aws_iam_role.role_glue.name}"]
}
resource "aws_iam_role_policy" "role_policy_glue" {
name = "role_policy_glue"
role = aws_iam_role.role_glue.id
policy = <<-EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"glue:*",
"s3:GetBucketLocation",
"s3:ListBucket",
"s3:ListAllMyBuckets",
"s3:GetBucketAcl"
],
"Resource": [
"*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:CreateBucket"
],
"Resource": [
"arn:aws:s3:::aws-glue-*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::aws-glue-*/*",
"arn:aws:s3:::*/*aws-glue-*/*"
]
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
"logs:CreateExportTask",
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
"logs:CreateExportTask",
"logs:DescribeLogGroups"
],
"Resource": [
"arn:aws:logs:*:*:/aws-glue/*"
]
}
]
}
EOF
}
Glueを実行する際のロールの設定定義部分です。
(だいぶ大雑把な設定ですが)主にGlueから接続するS3バケットに対するロールと、実行ログをCloudWatchへ吐き出すためのロールを設定しています。
# ----------------------------------
# Data catalog create
# ----------------------------------
resource "aws_glue_catalog_database" "database_glue_test" {
name = "database_glue_test"
}
# ----------------------------------
# Data catalog table for athena
# ----------------------------------
resource "aws_glue_catalog_table" "titanic_train" {
database_name = aws_glue_catalog_database.glue_catalog_database_name.name
name = var.glue_catalog_table_name
table_type = "EXTERNAL_TABLE"
storage_descriptor {
location = "s3://${var.glue_job_bucket}/athena/cleansing_proc/"
input_format = "org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat"
output_format = "org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat"
ser_de_info {
serialization_library = "org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe"
parameters = {
"serialization.format" = "1"
}
}
columns {
name = "PassengerId"
type = "string"
}
columns {
name = "Survived"
type = "string"
}
columns {
name = "Pclass"
type = "string"
}
columns {
name = "Name"
type = "string"
}
columns {
name = "Sex"
type = "string"
}
columns {
name = "Age"
type = "string"
}
columns {
name = "SibSp"
type = "string"
}
columns {
name = "Parch"
type = "string"
}
columns {
name = "Ticket"
type = "string"
}
columns {
name = "Fare"
type = "string"
}
columns {
name = "Cabin"
type = "string"
}
columns {
name = "Embarked"
type = "string"
}
}
partition_keys {
name = "orderdate"
type = "string"
}
}
Data catalogのデータベースとテーブルの定義部分です。
resource "aws_glue_catalog_database"が、データベースの定義部分です。
resource "aws_glue_catalog_table"で、テーブルの細かな設定をしています。
※参考(Terraform公式)
# ----------------------------------
# ETL job missing value process
# ----------------------------------
resource "aws_glue_job" "glue_job_test_cleansing" {
name = "glue_job_test_cleansing"
role_arn = aws_iam_role.role_glue.arn
command {
script_location = "s3://${var.s3_bucket_2}/python_shell/cleansing_proc.py"
python_version = 3
}
}
ETLジョブの設定定義です。
ARNは、先ほど定義した「aws_iam_role.role_glue」を付与しています。
script_locationで、S3にプッシュした「cleansing_proc.py」を取り込む設定しています。
python_versionで、python3を指定しています。
※参考(Terraform公式)
# ----------------------------------
# ETL job workflow
# ----------------------------------
resource "aws_glue_workflow" "glue_job_test_workflow" {
name = "glue_job_test_workflow"
}
resource "aws_glue_trigger" "trigger" {
name = "glue_job_test_workflow_start"
schedule = "cron(0/60 * * * ? *)"
type = "SCHEDULED"
workflow_name = aws_glue_workflow.glue_job_test_workflow.name
actions {
job_name = aws_glue_job.glue_job_test_missing.name
}
actions {
job_name = aws_glue_job.glue_job_test_cleansing.name
}
}
ワークフローと、ワークフロー内のトリガーの設定定義です。
トリガーは、スケジュール起動モードで、1時間(60分:cron(0/60 * * * ? *))ごとの起動設定にしています。
※参考(Terraform公式)
Data Ware House(Athena/Redshift)
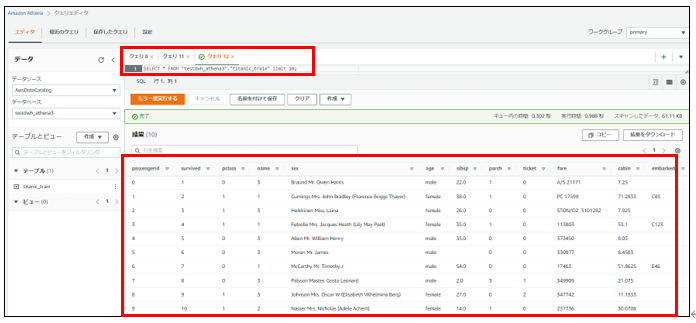
Glueで加工・修正したtitanic_trainテーブルのデータを、Athenaで抽出します。
kaggleのタイタニックのデータセットが表示されていることがわかります。
# ----------------------------------
# Athena database
# ----------------------------------
resource "aws_athena_database" "athena_glue_test" {
name = var.athena_database_name
bucket = var.log_bucket_name
}
# ----------------------------------
# Athena workgroup
# ----------------------------------
resource "aws_athena_workgroup" "glue_test_athena_workgroup" {
name = "glue_test_athena_workgroup"
configuration {
enforce_workgroup_configuration = true
publish_cloudwatch_metrics_enabled = false
result_configuration {
output_location = "s3://terraform-development-private-bucket-data/athena_result/cleansing_proc/"
}
}
}
# ----------------------------------
# Athena query
# ----------------------------------
data "template_file" "create_table_sql" {
template = file("./src/queries/create_table.sql")
vars = {
athena_database_name = aws_athena_database.athena_glue_test.name
athena_table_name = var.athena_table_name
log_bucket_name = var.athena_log_bucket_name
}
}
resource "aws_athena_named_query" "create_table" {
name = "Create table"
workgroup = aws_athena_workgroup.glue_test_athena_workgroup.id
database = aws_athena_database.athena_glue_test.name
query = data.template_file.create_table_sql.rendered
}
resource "aws_athena_database"は、Athenaのデータベース定義です。
resource "aws_athena_workgroup"は、Athenaのワークグループの定義です。
クエリ実行時、事後の設定や、クエリ自体の設定をしています。
data "template_file"で、S3にプッシュしたsqlファイルを取り込む設定をしています。
resource "aws_athena_named_query"で、ワークグループ・データベース・クエリを結びつけ、保存する設定をしています。よく使うクエリは保存しておくとよいでしょう。
※参考(Terraform公式)
QuickSight(BI)
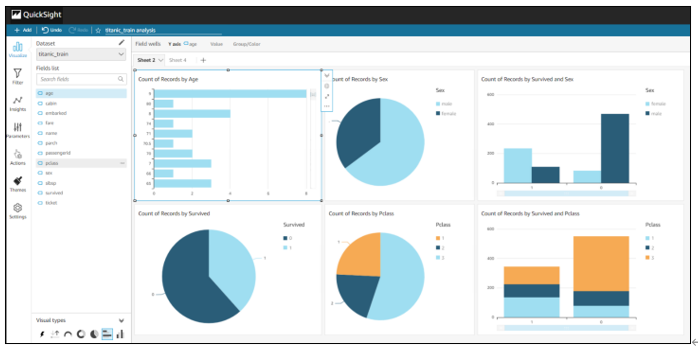
最後にAthenaのデータを読み込み、QuickSightでグラフ描画しています。
画面上でグラフを作成しています。
※Terraformでも設定等はできるのですが、今回は管理対象外とした為、詳細は割愛させていただきます。
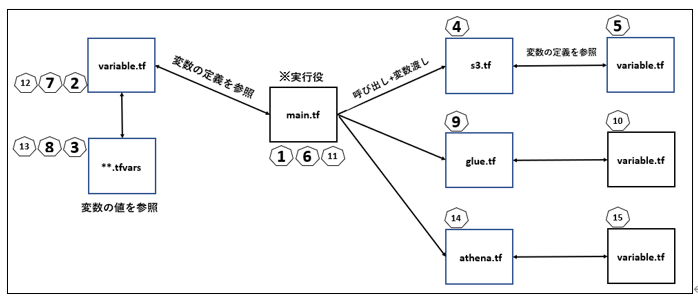
●実行ファイルとフロー
上記のフローで(main.tfを起点として)terraform apllyコマンドを実行します。
# ----------------------------------
# S3
# ----------------------------------
module "S3" {
source = "./modules/s3"
project = var.project
enviroment = var.enviroment
region = var.region
}
# ----------------------------------
# Glue
# ----------------------------------
module "glue" {
source = "./modules/glue"
glue_catalog_database_name = var.glue_catalog_database_name
glue_catalog_table_name = var.glue_catalog_table_name
athena_result_bucket_name = var.athena_result_bucket_name
connect_athena_password = var.connect_athena_password
connect_athena_username = var.connect_athena_username
glue_job_python_bucket = var.glue_job_python_bucket
s3_bucket_2 = var.s3_bucket_2
s3_bucket2_path = var.s3_bucket2_path
glue_job_bucket = var.glue_job_bucket
python_dir_name = "var.python_dir_name"
}
# ----------------------------------
# Athena
# ----------------------------------
module "athena" {
source = "./modules/athena"
athena_database_name = var.athena_database_name
athena_table_name = var.athena_table_name
log_bucket_name = var.log_bucket_name
athena_result_bucket_name = var.athena_result_bucket_name
athena_log_bucket_name = var.athena_log_bucket_name
}
「S3, Glue, Athena」の各モジュールを呼び出しています。
呼び出し時にそれぞれ引数を渡しています。
引数の実体(値)は、terraform.tfvars等から参照しています。
索引ページ
下記でTerraformに関するテーマをまとめて紹介しています。