1. 前書き
AtCoderBeginnerContest(ABC)の参加結果と内容の整理、および外部の解説記事を参考にした上で、自分なりに解法を整理していきます。
使用言語はPythonで行きます。本業ではJavaかRubyonRailsユーザーですが、計算速度の問題であったり、トレンドに乗っておくという意味でも(こちらが大きい)、Pythonに慣れていきたいと思います。
2. コンテスト内容
- コンテスト名
- AtCoder Beginner Contest 275
- 開催日時
- 2022/11/12(土) 21:00 - 22:40
- 実施区分
- バーチャル参加
- 2022/11/13(日)
3. 結果
| 区分 | 結果 | 所要時間 | 実行時間 |
|---|---|---|---|
| A問題 | AC | 4:02 | 22ms |
| B問題 | AC | 14:39 | 25ms |
| C問題 | 未提出 | - | - |
4. 解説
4-1. A問題
4-1-1. 問題文
(1,2,…,N) を並び替えた数列 P と整数 X が与えられます。 数列 P の i 番目の項の値は Piです。 Pk=X を満たす k を出力してください。
4-1-2. 入力形式
N X
P1 P2 ... PN
4-1-3. 解説
数列Pを配列に格納し、特定の値を検索して格納されているインデックスを出力する「index()」を利用するだけです。
4-1-4. ソースコード
n,x = map(int,input().split())
p = list(map(int, input().split()))
print(p.index(x)+1)
4-1-5. python文法の整理
配列内の特定の値を検索してインデックスを出力 index()
#使用法
[配列オブジェクト].index([検索値])
#使用例
array = ['apple', 'orange', 'peach']
print(array.index('apple')) -> 0
4-2. B問題
4-2-1. 問題文
英大文字および数字からなる 2 文字の文字列が N 個与えられます。i 個目の文字列は Siです。
以下の 3 つの条件をすべて満たすか判定してください。
・すべての文字列に対して、1 文字目は H , D , C , S のどれかである。
・すべての文字列に対して、2 文字目は A , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , T , J , Q , K のどれかである。
・すべての文字列は相異なる。つまり、i≠j ならば Si≠Sjである。
4-2-2. 入力形式
N
S1
S2
...
SN
4-2-3. 解説
各Siに対して以下を判定すれば良い。
各Siのうち1回でも合致したら、結果は「No」となり、全Siに合致しなかった場合のみ「Yes」となる。
- Si[0](1文字目)がH,D,C,Sに該当しない
- Si[1](2文字目)がA,2,3,4,5,6,7,8,9,T,J,Q,Kに該当しない
- 全Siを配列Sに格納し、S.count(Si) > 1となる
4-2-4. ソースコード
n = int(input())
s = []
for i in range(n):
s.append(input())
cond1 = ["H","D","C","S"]
cond2 = ["A","2","3","4","5","6","7","8","9","T","J","Q","K"]
flg = True
for j in s:
if j[0] not in cond1 or j[1] not in cond2 or s.count(j) > 1:
flg = False
break
if flg == True:
print("Yes")
else:
print("No")
4-2-5. python文法の整理
配列内の特定の要素数を検索 count()
#使用法
[配列オブジェクト].count([検索値])
#使用例
array = [1,4,2,6,2,3,5,1,3,2]
print(array.count(1)) -> 2
print(array.count(2)) -> 3
print(array.count(7)) -> 0
配列内に特定の値が含まれるかどうかの判定 in演算子
#使用法
[検索値] in [配列オブジェクト]
#使用例
array = [1,2,3,4]
print(1 in array) -> True
print(5 in array) -> False
配列オブジェクトの代わりに、集合オブジェクト(set())を使うことができる。
配列の場合は要素数に比例して処理時間が増えるが、集合の場合は要素数に依らず処理時間が変わらないため、基本的には集合オブジェクトを使う方が良い。
※特に競技プログラミングの場合は必須。
4-3. C問題
4-3-1. 問題文
109階建てのビルがあり、N 本のはしごがかかっています。
ビルの 1 階にいる高橋君ははしごを繰り返し使って(0 回でもよい)できるだけ高い階へ上りたいと考えています。
はしごには 1 から N までの番号がついており、はしご i は Ai階と Bi階を結んでいます。はしご i を利用すると Ai階から Bi階へ、または Bi階から Ai階へ双方向に移動することができますが、それ以外の階の間の移動は行うことはできません。
また、高橋君は同じ階での移動は自由に行うことができますが、はしご以外の方法で他の階へ移動することはできません。
高橋君は最高で何階へ上ることができますか?
4-3-2. 入力形式
N
A1 B1
A2 B2
...
AN BN
4-3-3. 解説
バーチャル参加時は全く歯が立ちませんでしたので、解説を読みました。
今回の設問のような状況は、「グラフ」という図で表すことができます。
入力例1である以下の場合、グラフは次のような図になります。
4
1 4
4 3
4 10
8 3
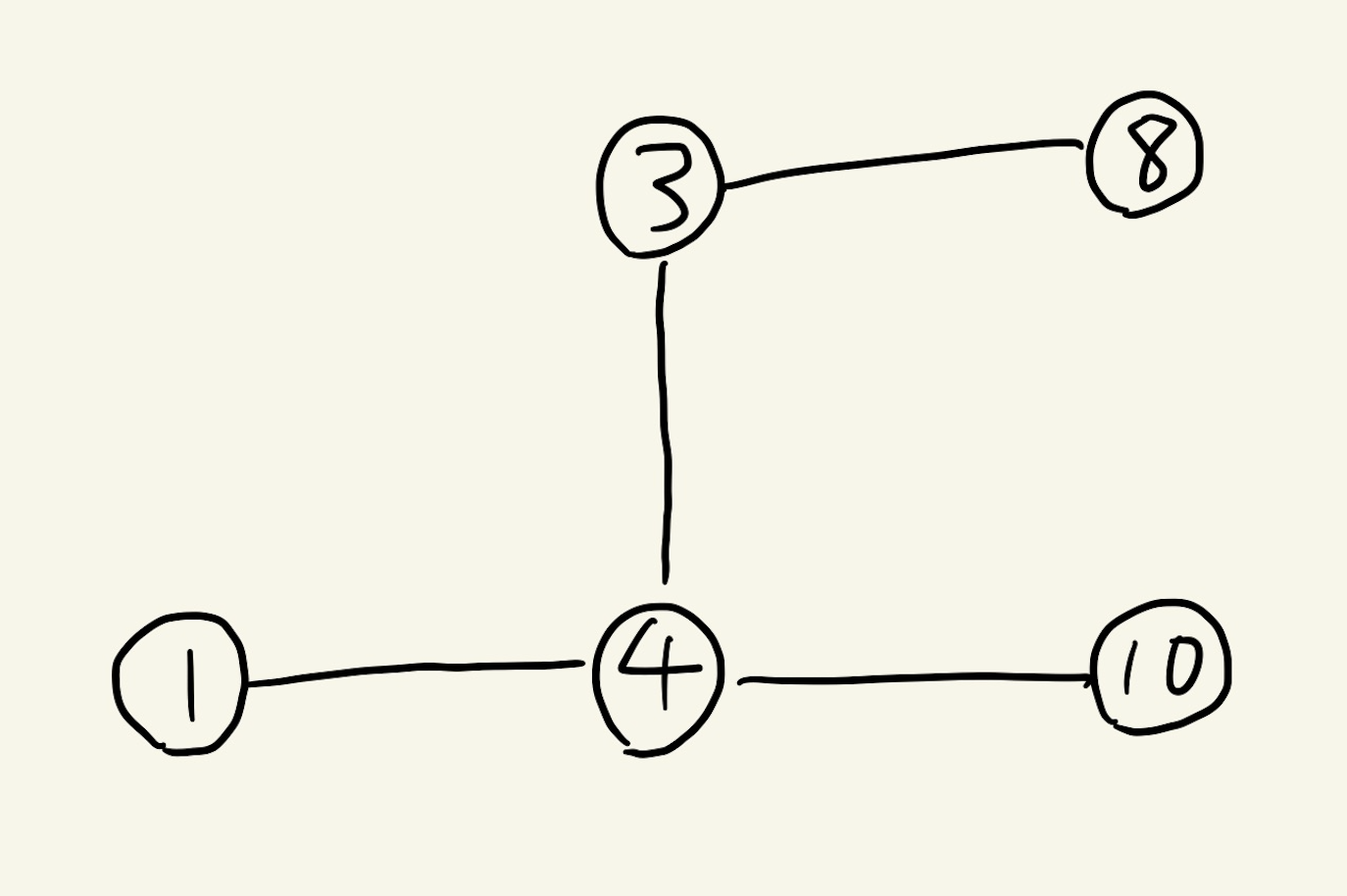
このグラフについて全探索したい場合、「幅優先探索(BFS:Breadth First Search)」というアルゴリズムを使用します。
[BFSの考え方]
準備
- 訪問予定の点の情報を格納する「キュー」を用意する。
- 探索を開始する点(今回の場合は「1」)をキューに格納する。
- 各階がつながっている先の情報を、連想配列形式で保存する。入力値を順に処理すると以下のようになる。
1 4 -> {1:[4],4:[1]}
4 3 -> {1:[4],4:[1,3],3:[4]}
4 10 -> {1:[4],4:[1,3,10],3:[4],10:[4]}
8 3 -> {1:[4],4:[1,3,10],3:[4,8],10:[4],8:[3]}
- 訪問済かどうかの情報を、連想配列形式で保存する。ただし、0:未訪問、1:訪問済とする。
探索の手順
- キューの先頭を取り出し、その点を訪問する。今回の場合は①に訪問する。訪問済み用連想配列は「{1:1}」となる。
- 訪問した点から接続している点で、かつ未訪問の点をキューに格納する。今回の場合は④をキューに格納する。
- 現時点での最高階数を上回っていれば、答えを更新する。
上記を繰り返します。
[参考URL]
4-3-4. ソースコード
from collections import defaultdict, deque
#はしごの数
n = int(input())
#つながっている階数の情報を連想配列で保存
connect = defaultdict(list)
for _ in range(n):
a,b = map(int, input().split())
connect[a].append(b)
connect[b].append(a)
#答えの階数
#初期位置である1階をセット
ans = 1
#キューを定義
que = deque()
#訪問済チェックを連想配列で保存
#0:未訪問、1:訪問済
visited = defaultdict(int)
#初期位置を1階とするため、queに1をセット
que.append(1)
#1階を訪問済とする
visited[1] = 1
#キューが空になるまでループ
while 0 < len(que):
#キューの先頭を取り出し、現在位置にセット
now = que.popleft()
#現時点での最高階数と現在位置をうち、大きい方を答えにセット
ans = max(ans,now)
#現在位置とつながっている階を全てでループ
for to in connect[now]:
#現在位置が未訪問の場合のみ、後続処理を実行
if visited[to] == 0:
#現在位置を訪問済みに変更
visited[to] = 1
#現在位置をキューへ追加
que.append(to)
print(ans)
4-3-5. python文法の整理
連想配列 collections.defaultdict()
辞書型dictを利用する際は、キーが存在しない場合を考慮して、しっかりハンドリングする必要がある。そんな時に、defaultdictを使うと、キーが存在しない場合でも初期値を設定してくれる。
from collections import defaultdict
dd = defaultdict(int)
print(dd[1]) -> 0
キューを扱う collections.deque()
dequeは先頭/末尾から要素を取り出す操作を高速に行うことができる。配列の場合、先頭要素に対する操作は、要素数が大きくなるほど、比例して時間がかかる。
#使用例
from collections import deque
d = deque()
d.append(1) -> deque([1])
d.appendleft(2) -> deque([2,1])
d.pop() -> deque([2])
d.popleft() -> deque([])