この度、データ分析基盤SaaSである trocco を触る機会がありましたので、ご紹介させていただきます。

1. troccoとは
primeNumber社が提供するETL/ELTを中心としたデータ分析基盤のマネージドサービスです。
内部ではembulkを利用しているようです。
詳細は以下を参照ください。
1-1.契約プランについて
契約プランがいくつかありますが、今回はフリープランを使ってデータの連携を試しました。
プランによって利用できるサービスが異なったり制限等がありますので、まずはどのプランを利用すればご自身のやりたいことができるかをご確認ください。
このプラン毎の制限で勘違いしやすいものだけ紹介させていただきます。
1-2. コネクタについて
フリープランではコネクタ数が2種類までと制限されておりますが、この「コネクタ」の考え方を勘違いしやすいです。
コネクタとは転送元・転送先に指定するサービス数です。
転送設定を作成するにあたり、まず初めに設定する項目が転送元・転送先のサービスです。
これがコネクタと呼ばれ、フリープランだと2種類までの制限となっております。
また、この転送元・転送先のサービスとは別に接続情報という項目があります。
設定方法は後述しますが、データ転送元、転送先に対しての接続設定を接続情報という項目で作成することになります。
ここで注意していただきたいのが、接続情報の設定数はコネクタ数ではないということです。
以下例として記載しますが、まず接続情報を6つ作成しているものと仮定します。
| No | コネクタ | 接続情報 |
|---|---|---|
| A | S3 | アカウント 1 |
| B | S3 | アカウント 2 |
| C | S3(parquet) | アカウント 1 |
| D | SQLserver | SQLserver #1 |
| E | SQLserver | SQLserver #2 |
| F | RedShift | RedShift #1 |
①転送元、転送先が別のコネクタ・接続情報の場合
| No | 転送元 | 転送先 |
|---|---|---|
| 1 | A:S3アカウント1 | D:SQLserver #1 |
この場合、転送元コネクタ数が1、転送先コネクタ数が1となり、合計コネクタ数は2となります。
②転送元、転送先がそれぞれ同じコネクタ・別の接続情報の場合
| No | 転送元 | 転送先 |
|---|---|---|
| 1 | A:S3アカウント1 | D:SQLserver #1 |
| 2 | B:S3アカウント2 | E:SQLserver #2 |
この場合、転送元コネクタ数が1、転送先コネクタ数が1となり、合計コネクタ数は2となります。
接続情報は関係なく、転送元・転送先毎のコネクタ種別の数がコネクタ数となります。
③転送元、転送先が全く同じコネクタ・別の接続情報の場合
| No | 転送元 | 転送先 |
|---|---|---|
| 1 | D:SQLserver #1 | A:S3アカウント1 |
| 2 | A:S3アカウント1 | F:RedShift #1 |
この場合、転送元コネクタ数が2、転送先コネクタ数が2となり、合計コネクタ数は4となります。
転送元・転送先に同じS3コネクタを利用していますが、別のコネクタとしてカウントされています。
このように、同一のサービスを転送元コネクタ・転送先コネクタのどちらにも利用する場合、それらは別々のコネクタとして利用数にカウントされます。
以上のことを踏まえたうえで契約するプランを考え、設定をおこなっていく必要があります。
2. 検証
前置きが長くなりましたが、ここから検証内容をご紹介していきます。
今回はS3バケットに配置したcsvファイルをparquetファイルに変換し、別のS3バケットへ配置する構成で設定していきます。
また、troccoではデータカタログにテーブルを作成する機能もあり、これも利用して最終的にredshiftから外部スキーマ・テーブルを参照したいと思います。

2-1.登録
まずはtroccoのアカウント登録を行いましょう。
以下のページの「無料で始める」を押下します。

必要事項を入力します。

すると、申し込み完了画面が表示されます。

また、アカウント登録確認用のメールが届きます。このメールに記載されている通り、アカウント作成には1営業日以内の期間が必要となります。
私の場合は割とすぐに発行できました。

また、メール内で紹介されている「trocco入門セミナー」は設定の仕方がわかりやすく紹介されておりましたので、一度見ておいたほうが良いかと思います。
アカウント登録が完了したら、アカウント発行のお知らせメールが届きます。
まずは、メールに記載のリンクからログインページへ行き、パスワードを設定します。
設定が完了すると、コンソール画面が表示されます。
2-2.接続用IAMロール作成
転送設定の前に、まずは接続用IAMロール作成を行っていきます。
troccoからの接続にはIAMユーザ、もしくはIAMロールを利用しますが、ここではIAMロールを使った接続を行います。
trocco側のAWSアカウントIDと外部IDを確認するために、troccoにて接続情報の作成を進めてみます。
左ペインから「接続情報」を選択し接続情報画面を表示させ、「新規作成」を押下します。

今回はS3への接続を行うため、一覧から「Amazon S3」を選択します。

すると、以下のような入力画面が表示されます。
ここには入力欄のほかに、troccoからアクセスする際のグローバルIPアドレスや、trocco側のAWSアカウントID等も記載されています。

ここに記載されている「troccoのAWSアカウントID」と「外部ID」を使用して自アカウントでIAMロールを作成していきます。
なお、IAMロールを作成した後に接続設定の続きを行いますので、この画面は閉じずにおいてください。
まず新規でポリシーを作成します。ここからは転送元・先のS3バケットが存在するAWSアカウントでの作業となります。
IAMロールに付与するポリシーは以下となります。
今回転送元・先ともにS3を利用するため、ListBucket、GetObject、PutObjectのResourceには転送元・先の両バケットを指定します。また、S3を転送元としてのみ利用する場合はPutObjectの権限は不要となります。
- ListAllMyBuckets
- s3:GetBucketLocation
- s3:ListBucket
- s3:GetObject
- s3:PutObject
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "RequiredByToolsLikeWinscpAndDataSpiderForConnection",
"Effect": "Allow",
"Action": [
"s3:ListAllMyBuckets",
"s3:GetBucketLocation"
],
"Resource": [
"arn:aws:s3:::*"
]
},
{
"Sid": "AllowAllS3ActionsToSpecificS3Path",
"Effect": "Allow",
"Action": [
"s3:Get*",
"s3:List*",
"s3:Put*"
],
"Resource": [
"arn:aws:s3:::{連携元バケット名}",
"arn:aws:s3:::{連携先バケット名}",
"arn:aws:s3:::{連携元バケット名}/*",
"arn:aws:s3:::{連携先バケット名}/*"
]
}
]
}
ポリシーが作成出来たらロールを作成します。
「ステップ1:信頼されたエンティティを選択」にて「別のAWSアカウント」に「troccoのAWSアカウントID」、「外部ID」に「外部ID」を入力してtroccoアカウントからの接続を許可する設定を行います。

許可設定では先ほど作成したポリシーを付与します。また、今回はtroccoでデータカタログの更新も行いたいので、マネジメントポリシー:AWSGlueConsoleFullAccessも付与します。
2-3.trocco接続設定
IAMロールを作成出来たらtrocco側の接続設定をおこなっていきます。
2-2で「troccoのAWSアカウントID」と「外部ID」を確認した画面の続きから設定していきます。
「名前」に任意の名前を入力、接続情報で「IAMロール」を選択し、AWSアカウントID、2-2で作成したIAMロールを指定します。

入力が完了したら、「接続を確認」を押下して以下画面が表示されたらOKです。「保存」を押下して設定を完了してください。

2-4.データ転送設定
接続設定が完了したら、いよいよデータ転送を作成します。
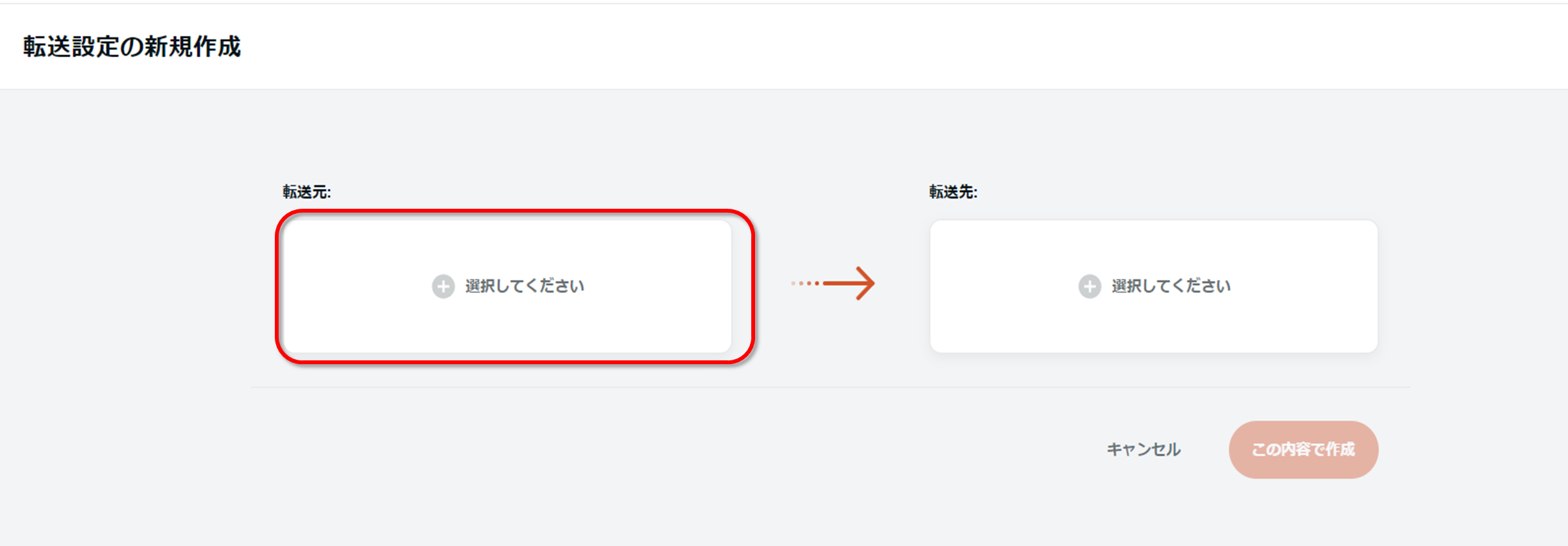
左ペインから「データ転送」の「転送設定」を選択し転送設定一覧画面を表示させ、「新規転送設定作成」を押下します。

以下の画面が表示されるため、転送元を選択し、「ファイル・ストレージサービス」から「Amazon S3」を選択します。

続いて転送先を選択し、「ファイル・ストレージサービス」から「Amazon S3 Parquet」を選択します。
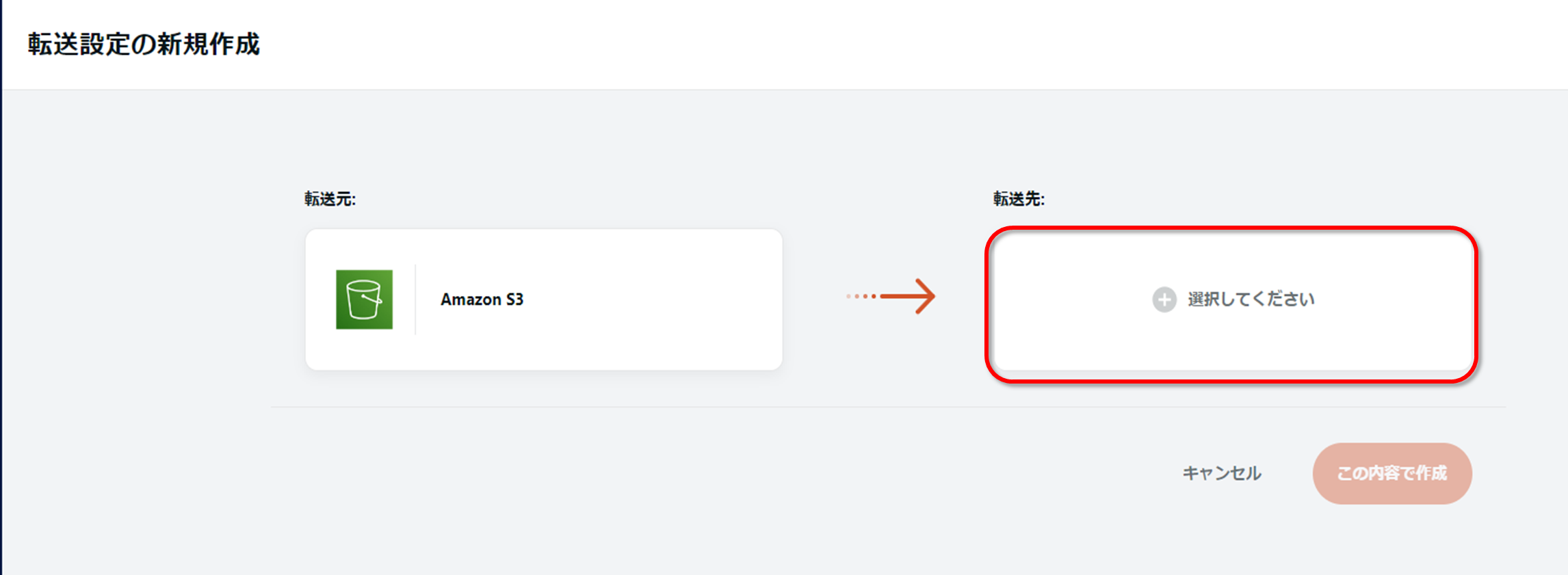
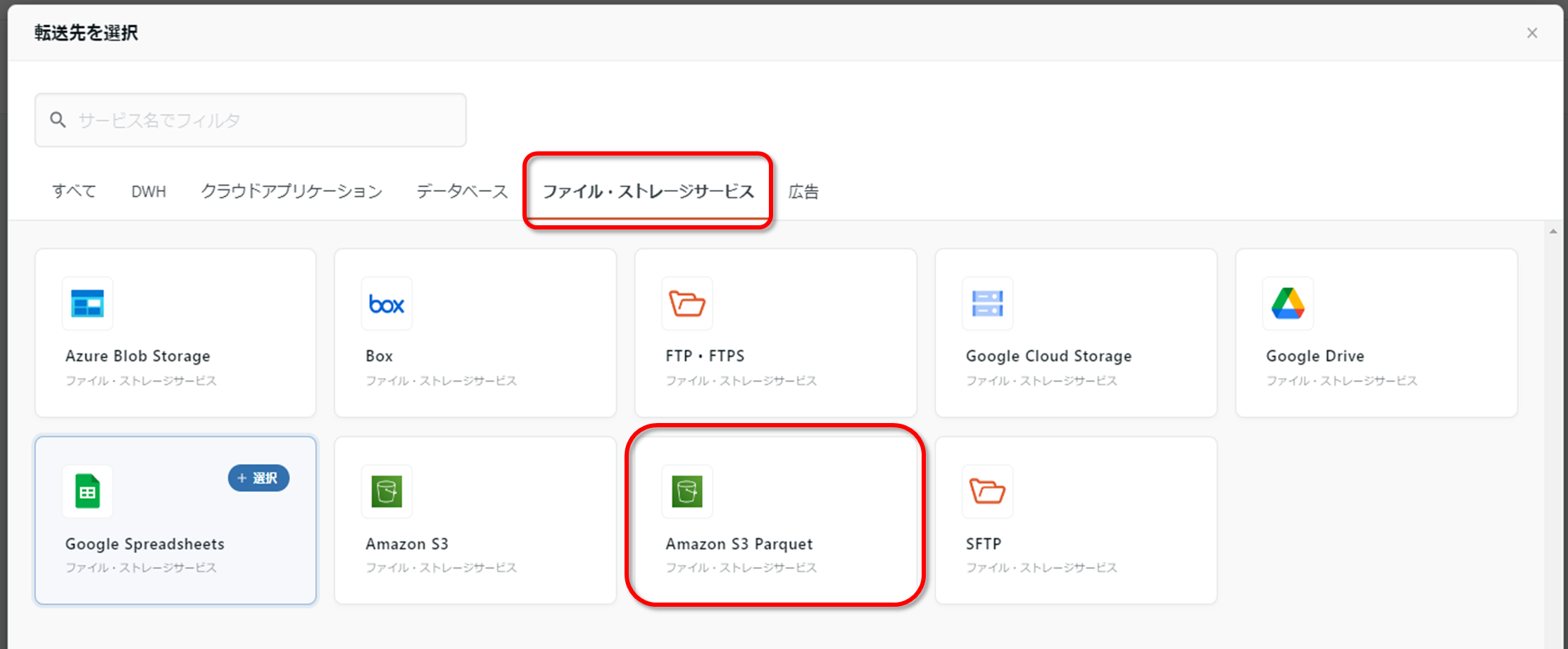
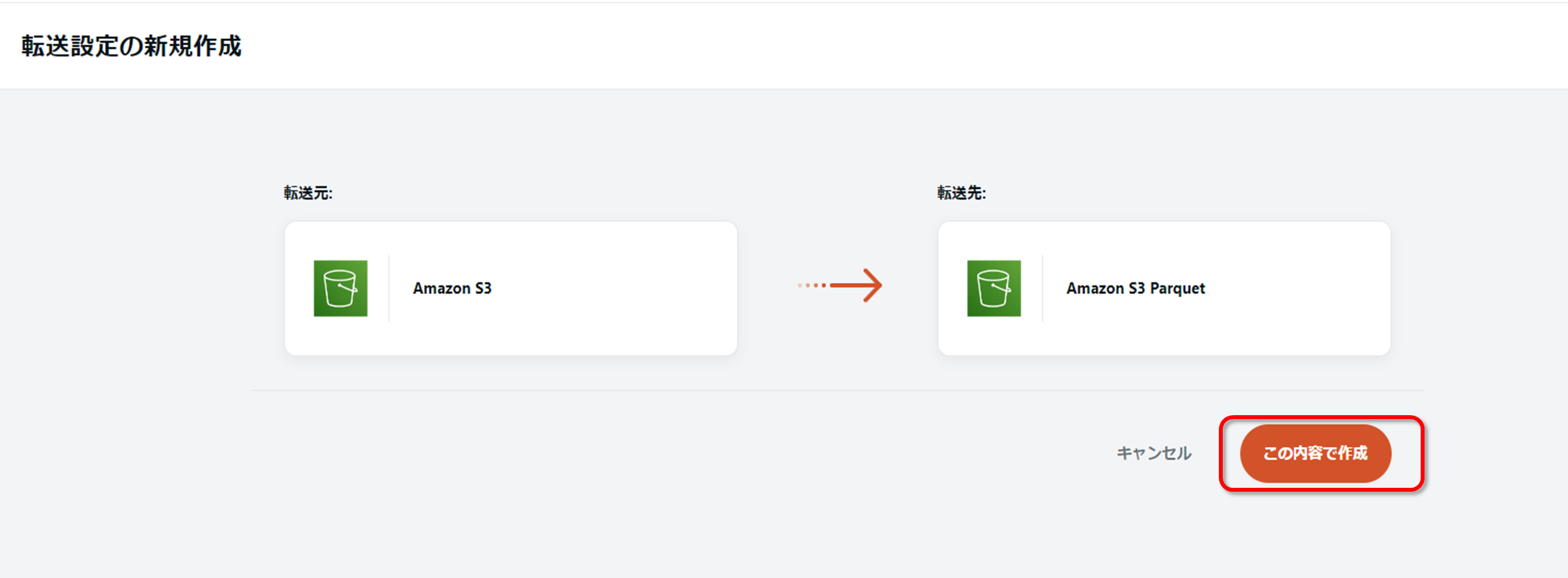
転送元・転送先が問題なく選択されていることを確認したら、「この内容で作成」を押下します。
概要設定では任意の名前を付けます。

続いて、転送元 Amazon S3の設定、転送先 Amazon S3 Parquetの設定を行います。
各入力項目については以下の通り設定してください。
また、転送元 Amazon S3の設定、転送先 Amazon S3 Parquetの各項目の最後に「接続確認」の項目がありますので、こちらを使って接続に問題ないことを確認してください。
| 項目 | 入力内容説明 |
|---|---|
| Amazon S3接続情報 | 2-3で作成した接続情報 |
| リージョン | 接続元・先バケットが存在するリージョン |
| カスタム変数 | ジョブ実行時に指定の値に置き換得たい場合に入力 |
| バケット | 接続元・先バケット名 |
| パスプレフィックス | 接続元・先のパスパスプレフィックス ※連携元に指定する場合:ここで指定したプレフィックス配下でパスが分かれていたとしても、そのすべてのパスに存在するファイルが対象となります |
| パスの正規表現 | 指定したパスプレフィックス配下に対象外のファイルが存在する場合に入力 |
| 自動データ設定・カラム定義の再読み込み・スキーマ変更検知で使用するファイル | 転送元の設定に基づいて自動抽出 |
| 解凍形式 | 圧縮有無によって選択 |
| 入力ファイル形式 | 連携ファイル形式によって選択 |
| 転送方法 | 全件・増分データ連携のいずれかで選択 |
| 指定のパスにファイルが存在しなかった場合に転送を続行するか | 転送対象が無い場合にエラーにするか否かを選択 |
| 圧縮方式 | 変換後のファイルを圧縮する際に選択 |
今回の検証でおこなった設定は以下画像の通りです。

入力が完了したら「次のSTEPへ」を押下し、データプレビュー・詳細設定へ進みます。
この際以下の画面が出てきますので、「自動データ設定を実行」を選択してください。

すると、以下の通り「自動データ設定を実行中です」という画面となります。これは、サンプルデータをS3から取得して自動でプレビューしてくれるのですが、表示されるのにある程度の時間がかかります。
読み込みが完了すると以下の通りスキーマとデータのプレビューが表示されます。
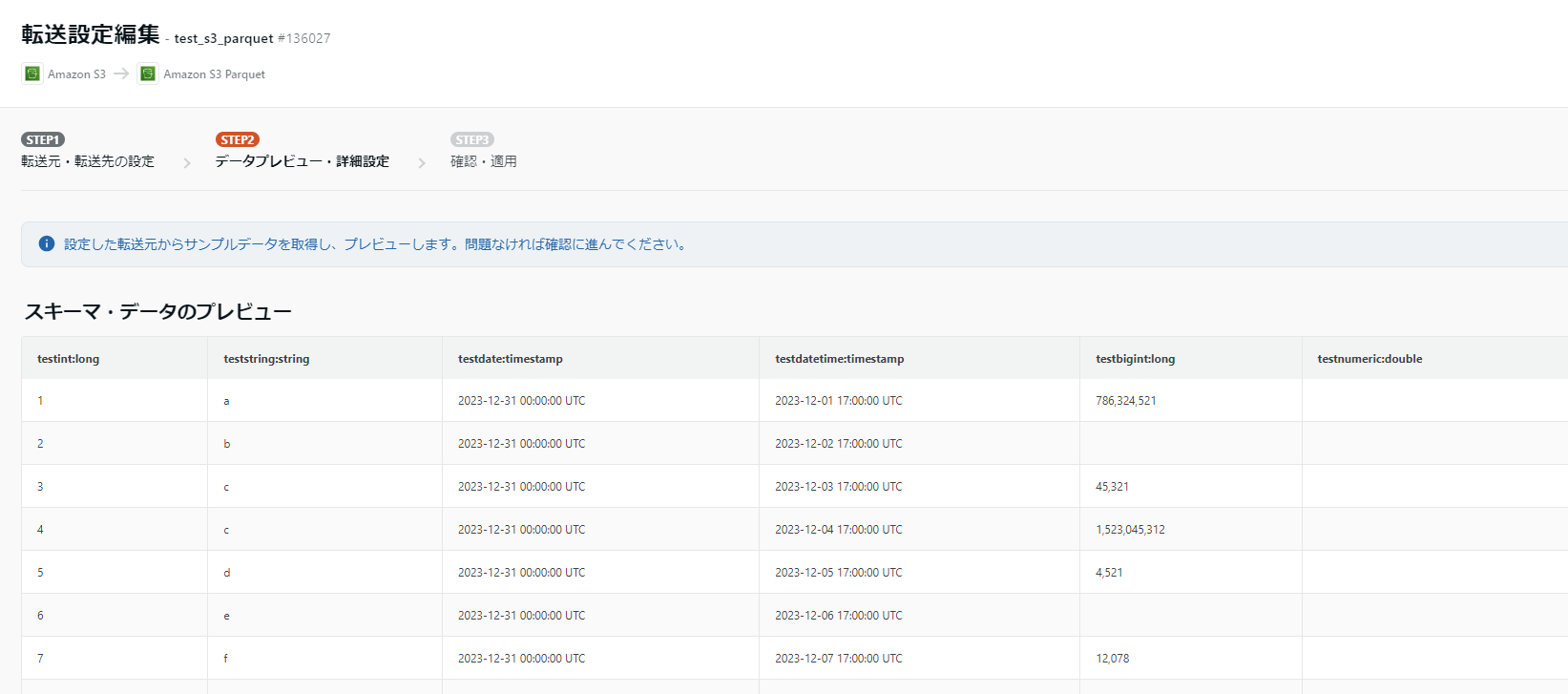
プレビューに問題なければ次の工程に進みます。
プレビューの画面を下にスクロールすると詳細設定画面が表示されます。
まずはデータ設定を見ていきます。
この画面ではETLの詳細を設定できます。
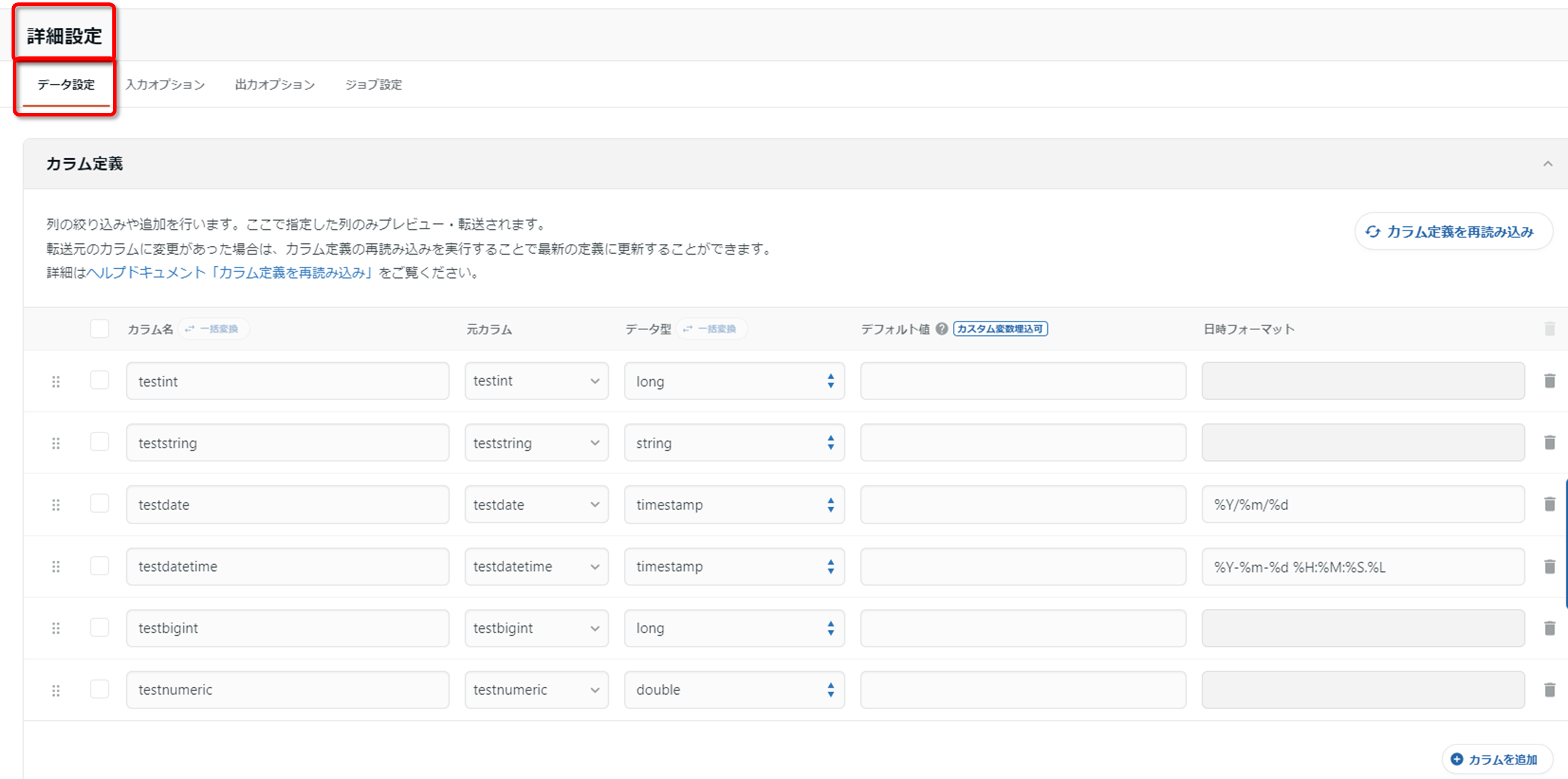
今回は「自動データ設定を実行」を行ったため、変換後のカラム名やデータ型等をtrocco側で自動で推測したものが表示されています。
データ型については[string,long,timestamp,double,boolean,json]から選択できます。
今回は「testdate」を「timestamp」から「string」に変更します。

また、カラムの追加も可能です。今回は「testname」というカラムを追加します。
まずは「カラムを追加」を押下し、任意のカラムを追加します。
なお、追加するカラムのデータは一律で「デフォルト値」の値が入力されます。レコードによって別の値を入力することはできません。

その他設定については以下の通りとなっております。
- フィルター設定
- マスキング設定
- 転送日時カラム設定
- 文字列正規表現置換
- カラムハッシュ化
- 文字列変換
- UNIX時間変換
今回は「転送日時カラム設定」のみ設定します。

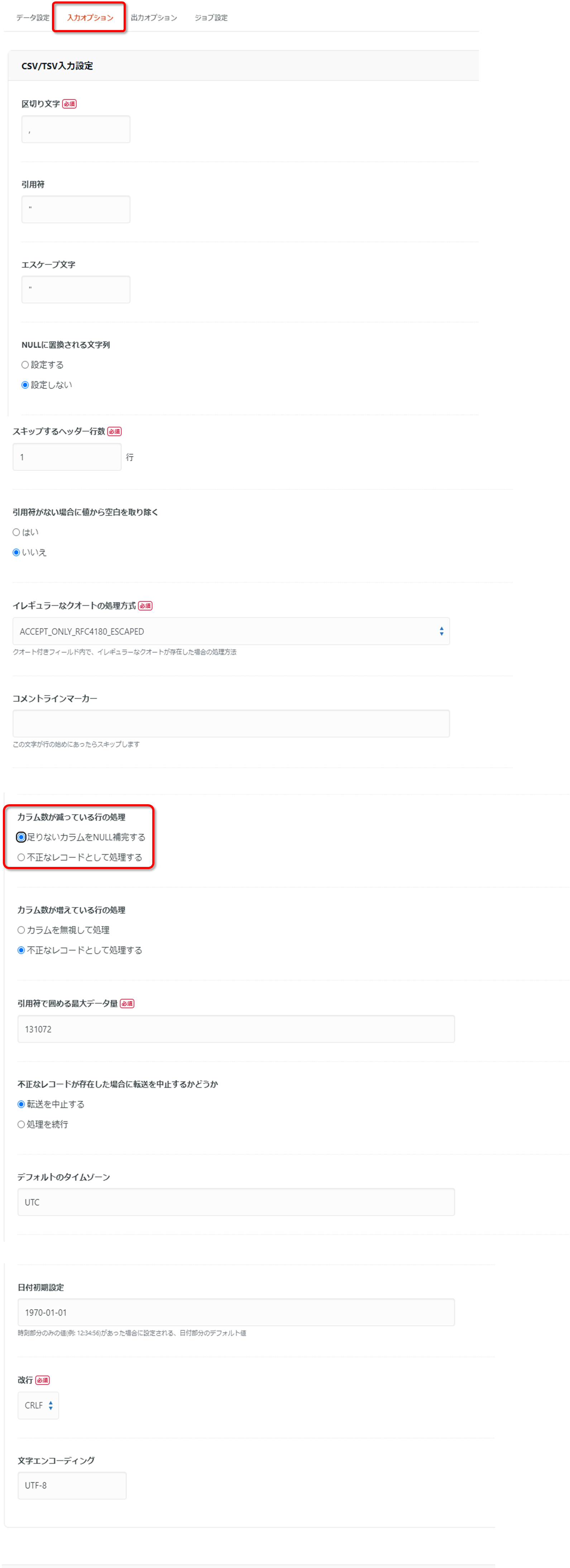
続いて「入力オプション」を設定していきます。
この設定は、取得するデータについてのオプション設定となっています。
当検証はCSVファイルからparquetに変換するという構成のため、主にCSVファイルについての設定になります。
今回は「カラム数が減っている行の処理」を「足りないカラムをNULL補完する」に変更した以外はデフォルトの設定としています。
続いて「出力オプション」を設定していきます。
この設定は、parquetへの出力時のオプション設定となっています。
ここではデータカタログへの登録と、カラムのデータ型の変換を行います。
データカタログへの登録を行う際は、先にglueのデータカタログにデータベースを作成しておきましょう。

最後に「ジョブ設定」です。
この設定はembulkのジョブについての設定となっています。
今回はデフォルトのまま変更せずにおきます。

設定が完了したら「確認画面へ」を押下します。
すると、以下の通りyamlで記述されたembulk設定ファイルの内容が表示されます。
問題なさそうであれば、「保存して適用」を押下します。
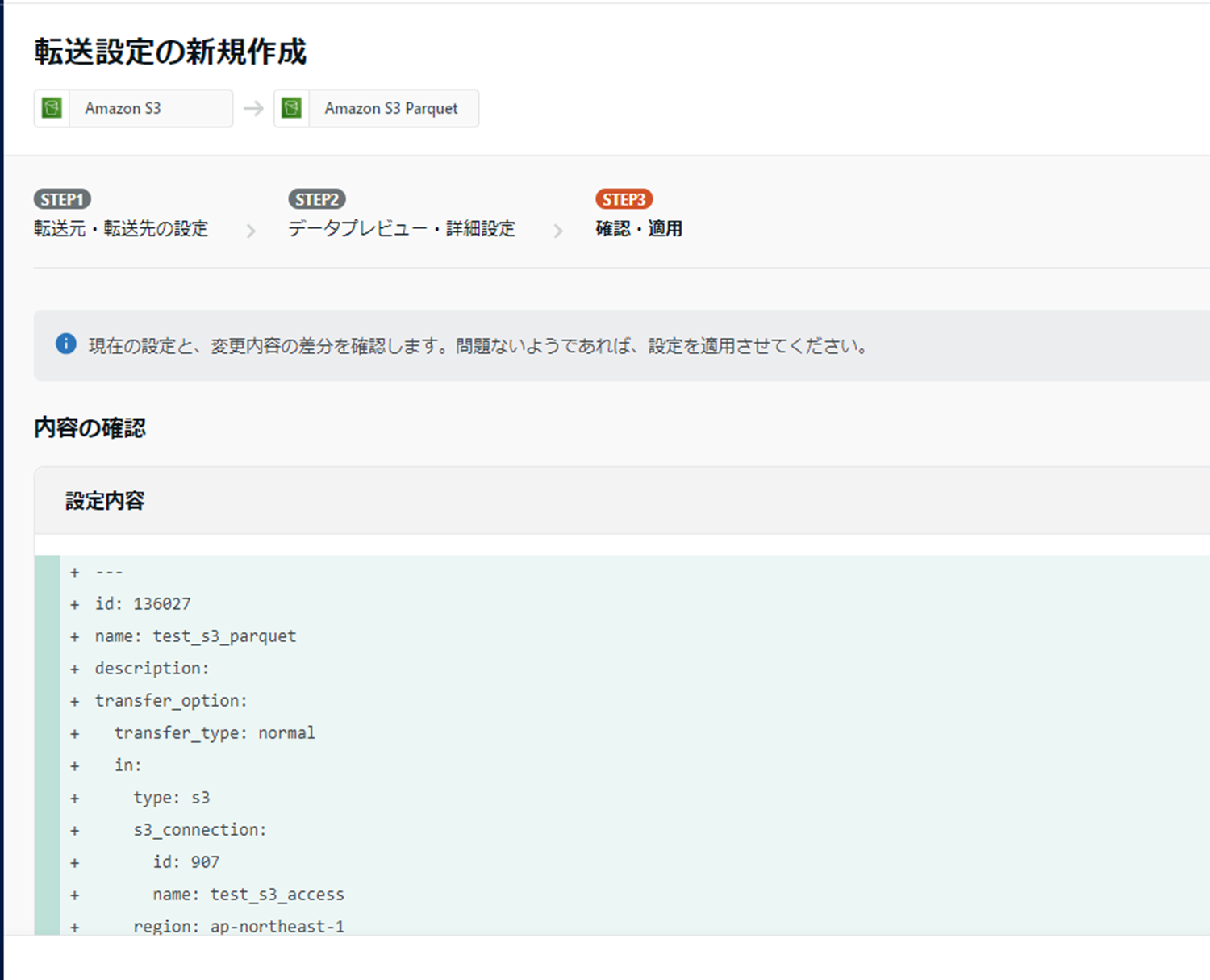
変更内容を入力するウィンドウが表示されますので、今回は「新規作成」と入力し「保存して適用」を押下します。

これで設定完了です。
2-5.実行
設定が完了すると、2-4で作成したジョブの設定概要画面が表示されます。
この画面の右上に「実行」ボタンがありますので、こちらを押下します。

実行メモを入力するウィンドウが表示されますので、今回は特に入力せずに「実行」を押下します。

すると、実行が開始されますので完了するまで待ちます。
この際、以下のようにembulkの実行ログがリアルタイムに表示されます。
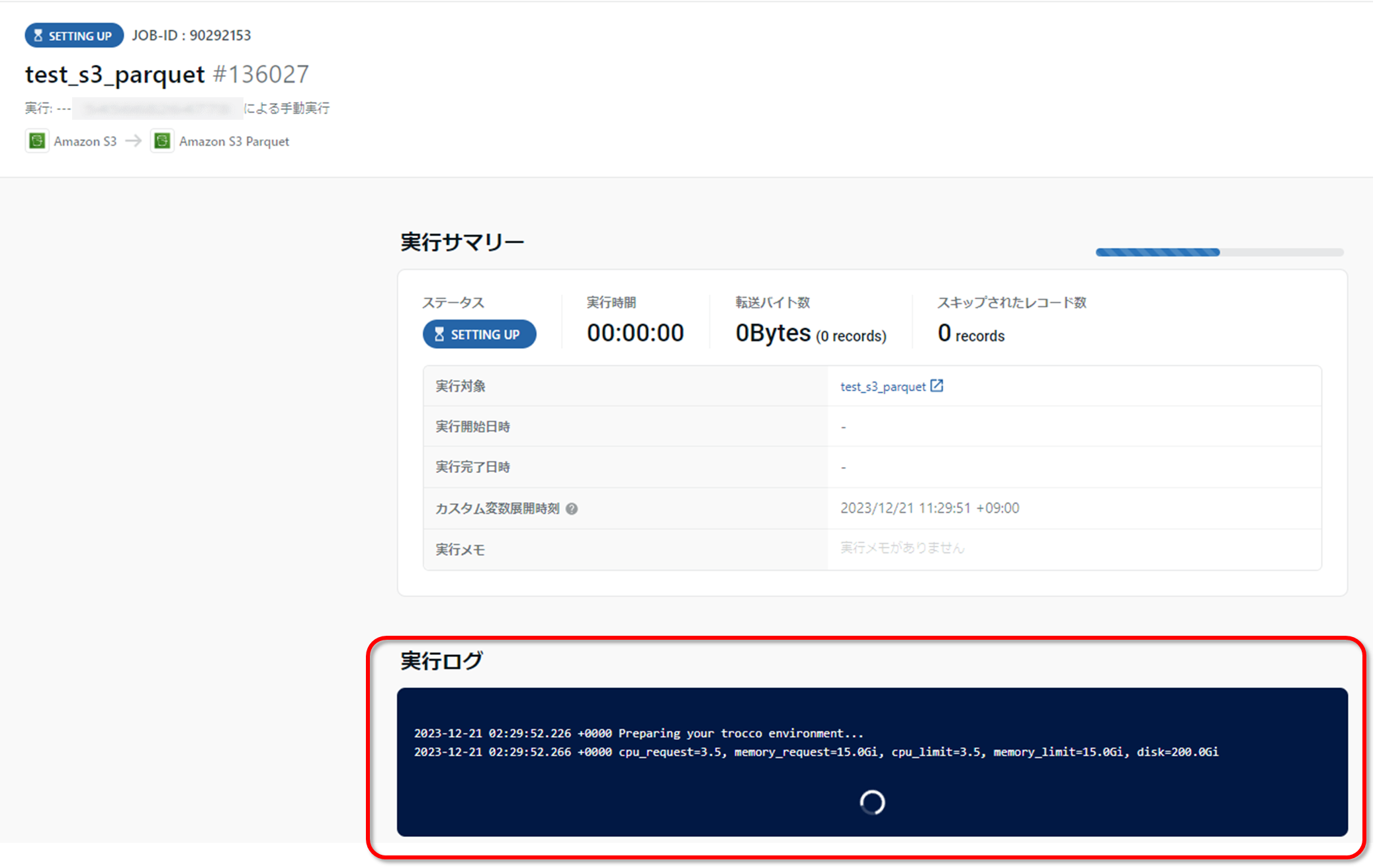
しばらく待つと実行が完了します。
以下の通りステータスが「success」になったら問題なく完了、失敗すると「error」が表示されることになります。
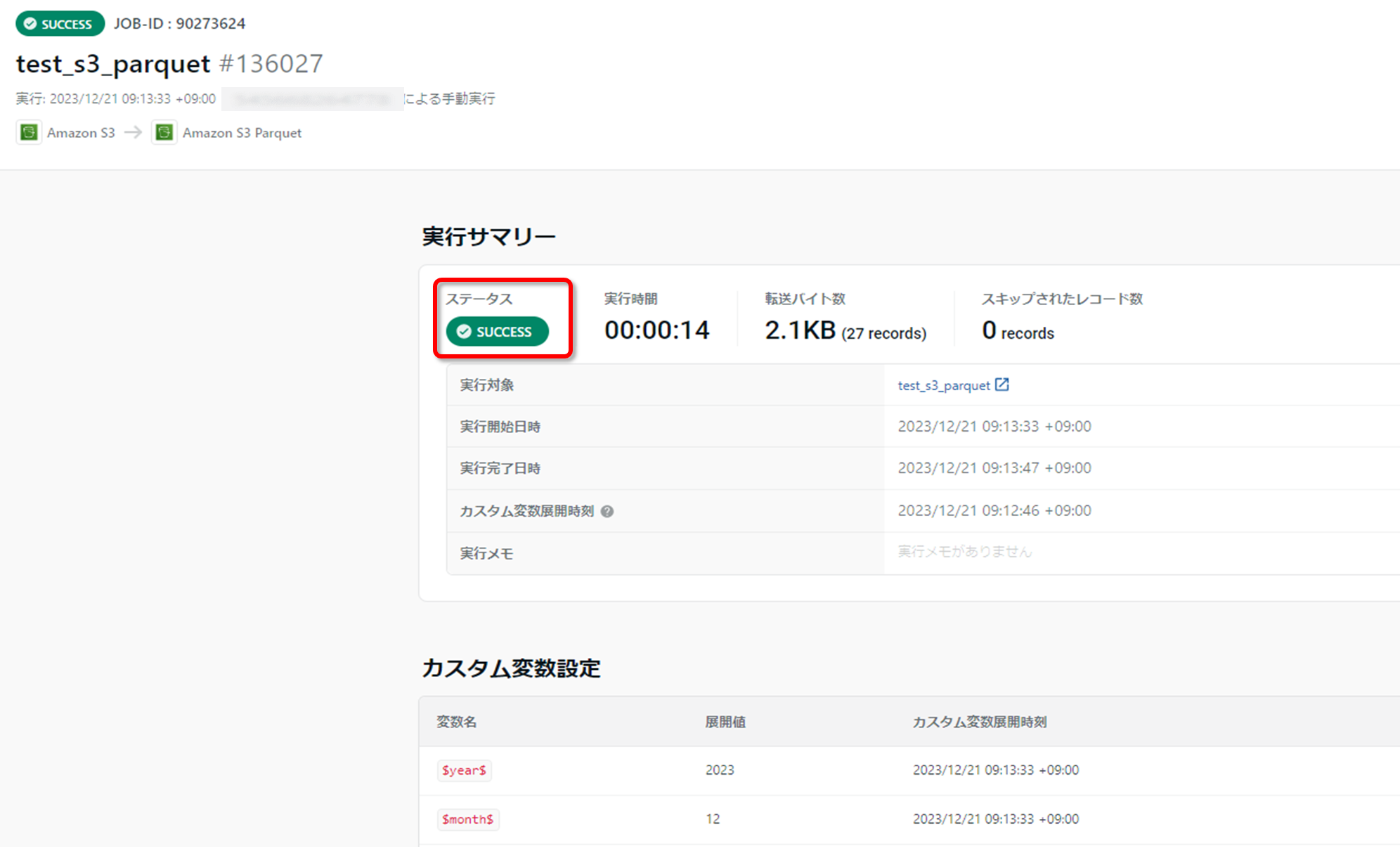
2-6.確認
troccoのジョブが完了しましたので、S3バケット、glueデータカタログを確認します。
まずはS3バケットですが、転送先の設定で指定したバケット、プレフィックスのバケットを確認します。
今回はプレフィックスに転送日付の変数を指定していますので、転送日のプレフィックスが作成され、その配下にparquetファイルが作成されていることを確認します。
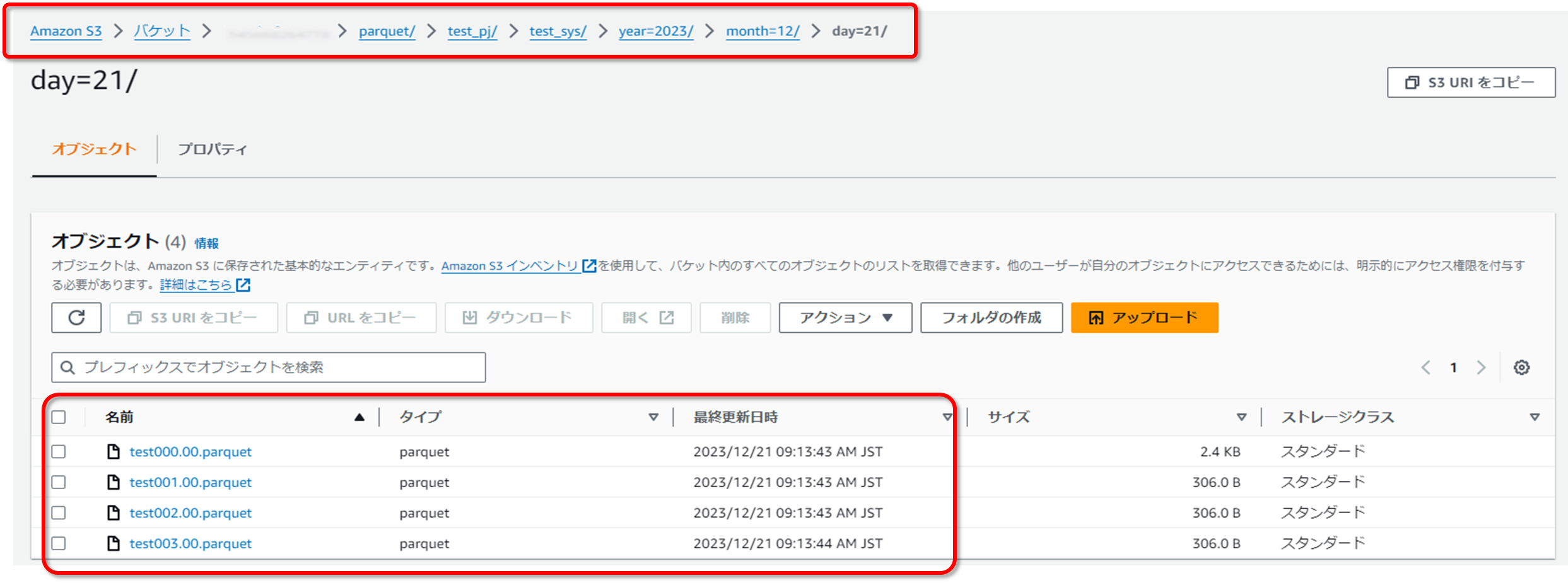
次にglueデータカタログを確認します。
ここでは「出力オプション」で指定したテーブル名が作成されていることを確認します。

内容を確認すると、以下の通り概要とカラムの情報が確認できます。
troccoでデータ型を変換したカラム、追加したカラムも問題ないようです。
また、「Location」を見ると転送日のプレフィックスまでがソースとして登録されていることが確認できます。

もしソースとして登録するのは「test_sys」までとし転送日はパーティションとしたいという希望がある場合は、troccoでのカタログ追加はせず、手動でテーブルを作成し、定期的にクローラを回してパーティションを認識させる等の対応をとったほうが良いかと思います。

続いて実際にredshiftから連携データを確認してみます。
まずはredshift spectrumでglueデータカタログを確認するために、外部スキーマを作成します。
CREATE EXTERNAL SCHEMA trocco_test_db
FROM
DATA CATALOG DATABASE 'trocco_test_db' IAM_ROLE 'arn:aws:iam::アカウントID:role/ロール名'
CREATE EXTERNAL DATABASE IF NOT EXISTS;
作成出来たら実際にデータを確認します。
select * from trocco_test_db.trocco_test_table;
見れました。

3.まとめ
本記事では、troccoを使用してS3間でデータを変換・連携する方法を紹介しました。
すべて日本語のため直感的に操作でき、プラグラミングやSQLのわからない初心者でも利用できるくらい簡単な手順で連携できました。
今回はS3間でのデータ連携をおこないましたが、troccoはたくさんのデータソースからの連携が可能です。
また、データ連携以外でもデータマートやdbt連携、ワークフロー等の機能もあります。
データ分析したいけどデータの集め方がわからないであったり、ETLしたいけどプラグラミングが書けないというかたは、フリープランもありますので一度利用してみてはいかがでしょうか。