はじめに
Transformers 、Gemma などを使って、生成 AI プログラミングを試してみました。
LLM(大規模言語モデル)で質問に文章で回答させることができました。
ただし公開されている作成済のモデルを使って・・です。これではモデルを作成したときに学習させたデータに基づいた内容しか回答できません。
独自のデータ、例えば仕事なら議事録やメールなど、プライベートなら自分のメモなどを読んでおいて、その内容に対して回答できる AI プログラムが、以前から欲しいと思っていました。
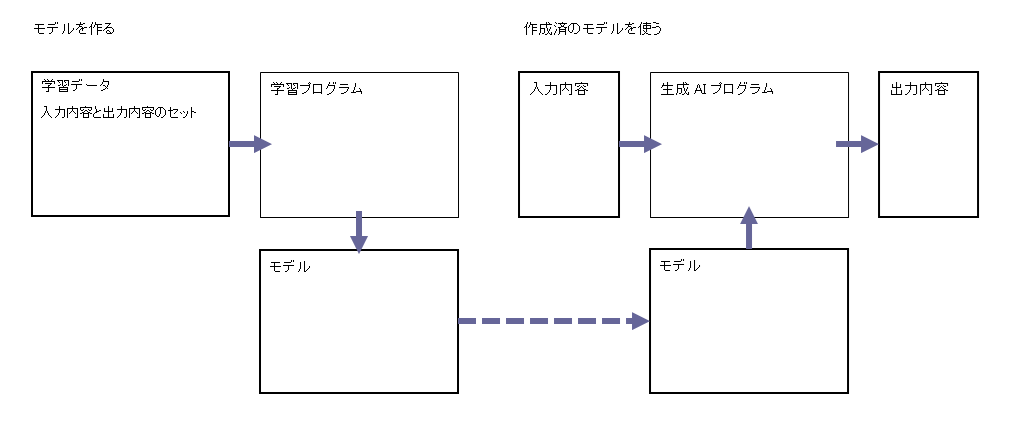
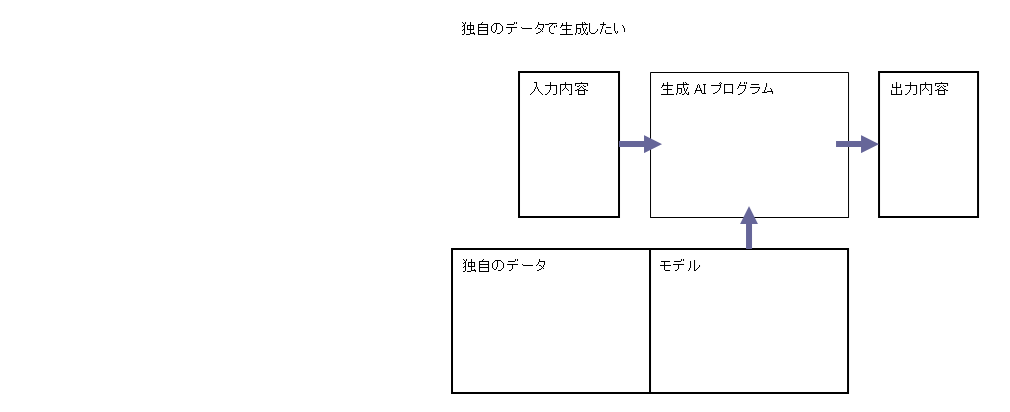
作成済のモデルにない内容を生成させる方法
作成済のモデルにない内容を生成させる方法は幾つかあるようです。
-
ファインチューニング(精密調整)
作成済のモデルに独自のデータを追加で学習させ、新たな知識を持ったモデルを作る。
作成済の部分も含めて調整することもあれば、作成済の部分は調整しないで追加だけすることもある。 -
LoRA(Low-Rank Adaptation(低ランク適応)
大規模なモデルを効率よく=少ない計算量でファインチューニングする。
元のモデルのパラメータは直接変更しないで、追加パラメータの差分を学習させたアダプタを追加する。 -
RAG(Retrieval-Augmented Generation(検索拡張生成)
入力内容に応じて独自のデータを検索して取得して、それを入力内容に加えてモデルを呼出する。


RAG を試してみる
RAG(Retrieval-Augmented Generation(検索拡張生成)の基本的な流れは以下の通り。
①検索したい対象を読込する。必要に応じて分割する
②読込した内容を保存しておく
③保存したデータを入力内容に従って検索する
④検索した内容を入力内容に加えてモデルを呼出する
参考:RAG(Retrieval-Augmented Generation:検索拡張生成)とは?:AI・機械学習の用語辞典 - @IT
LangChain で RAG を試してみる
RAG を実装するために便利な機能が LangChain ライブラリに用意されています。LangChain を使って RAG を試してみます。
以下の記事を参考にしました。
Transformers, LangChain & Chromaによるローカルのテキストデータを参照したテキスト生成 - noriho137’s diary
LangChain とは
LangChain は、Python などから呼出すライブラリの一つで、「言語系の生成 AI を使ったアプリケーション開発に便利なツールの詰合せ」のようなもの。
参考:LangChain完全入門 生成AIアプリケーション開発がはかどる大規模言語モデルの操り方 - インプレスブックス
実行環境を用意する
AI プログラムの実行環境は、高速な計算するために大きなメモリや GPU を使います。そのため高額なマシンが必要になります。
高機能なマシンを時間利用できるクラウドサービスが用意されています。
その中の Google Colab を使ってみます。別の環境でも構いません。
Google Colab は、ホスト型 Jupyter Notebook サービスです。Jupyter Notebook は、プログラムの対話型実行環境です。
以下のコード例は、Google Colab あるいは Jupyter Notebook で実行するものです。
必要なライブラリをインストールする
Transformers ライブラリを使うのでインストールします。モデルを量子化するためのライブラリも併せてインストールしておきます。
! pip install transformers accelerate sentencepiece
! pip install bitsandbytes
LangChain ライブラリを使うのでインストールします。
! pip install langchain langchain_community
言語モデルを準備する
LangChain を使ったコードのサンプルの多くが、OpenAI 社の ChatGPT API サービスを使用しています。
import langchain
llm = langchain.OpenAI()
これは便利でいいのですが、クラウドサービスを呼出します。
そうでなくて、実行環境にモデルをロードして使用したいと思います。
以下の例は Gemma を使用しています。他のモデルでも構いません。
参考:生成 AI プログラムを試してみた #AI - Qiita
import transformers
import torch
import bitsandbytes
# トークナイザとモデルの準備
tokenizer = transformers.AutoTokenizer.from_pretrained(
"google/gemma-2b-it"
)
model = transformers.AutoModelForCausalLM.from_pretrained(
"google/gemma-2b-it",
device_map="auto",
quantization_config=transformers.BitsAndBytesConfig(load_in_8bit=True) # 量子化の指定する
)
上記のトークナイザとモデルを LangChain で使用するために、パイプラインを準備します。
参考:huggingfaceのモデルをlangchainで使う + 量子化とストップワード(停止文字列)の設定
import langchain.llms
# パイプラインを準備
pipe = transformers.pipeline(
'text-generation',
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
torch_dtype=torch.float16
)
llm = langchain.llms.HuggingFacePipeline(
pipeline=pipe
)
RAG を使わないで実行してみる
まず、RAG 機能を使わないで実行してみます。
プロンプトを準備する
ChatGPT API サービスを使用したモデルはいいのですが、そうでないモデルを使用するときはプロンプトが必要なようです。
import langchain.prompts
# プロンプトを準備
template = """
<bos><start_of_turn>user
{query}
<end_of_turn><start_of_turn>model
"""
prompt = langchain.prompts.PromptTemplate.from_template(template)
プロンプトはモデルごとに有効なものがあるようです。
参考:Gemma のフォーマットとシステムの手順 | Google for Developers
チェーンを準備する
準備したモデルを LangChain で使用するのに、チェーン機能を使えます。
# チェーンを準備
chain = (
prompt
| llm
)
参考:LangChain の新記法「LangChain Expression Language (LCEL)」入門
チェーンを実行して回答する
query = "なごや個人開発者の集いとは何ですか。"
# 推論を実行
answer = chain.invoke({'query':query})
print(answer)
結果は↓
<bos><start_of_turn>user
なごや個人開発者の集いとは何ですか。
<end_of_turn><start_of_turn>model
なごや個人開発者の集いは、個人開発やスキルアップを向上させるための団体やコミュニティのことです。なごは、個人開発やスキルアップを支援するための団体として、さまざまなイベントやワークショップを開催しています。個人開発者の集いは、さまざまな分野で活動しており、技術、ビジネス、デザイン、コミュニケーションなど、様々な分野で参加することができます。
それらしいことは回答していますが、よく読むと正しくありません。↑
独自のデータを読込する
RAG に使用する独自のデータを読込します。
LangChain にローダが用意されています。読込したい対象に合わせて使用します。
今回はウェブページを読込しようと思います。UnstructuredURLLoader が使えます。
必要なライブラリをインストールします。
! pip install unstructured
検索したいウェブページを指定して読込します。
import langchain_community.document_loaders
urls = [
'https://758indies.connpass.com/',
]
# ウェブページの内容を読込する
loader = langchain_community.document_loaders.UnstructuredURLLoader(
urls=urls
)
docs = loader.load()
上記のウェブページは「403 Forbidden」が返ってきました。代わりに SeleniumURLLoader を使います。
! pip install selenium
中略
loader = langchain_community.document_loaders.SeleniumURLLoader(
urls=urls
)
docs = loader.load()
読込した内容は必要に応じて分割します。
import langchain.text_splitter
# 読込した内容を分割する
text_splitter = langchain.text_splitter.RecursiveCharacterTextSplitter(
chunk_size=100,
chunk_overlap=10,
)
docs = text_splitter.split_documents(docs)
参考:LangChainによる「特定のウェブページを学習させる方法」
読込した内容を保存する
読込した内容を、検索できるようにデータベースに保存しておきます。
ベクトル化するための準備する
読込した文章や画像などのデータは、AI モデルが処理しやすいようベクトル表現に変換した上で保存します。そのための準備します。
! pip install sentence-transformers
import langchain.embeddings
# ベクトル化する準備
embedding = langchain.embeddings.HuggingFaceEmbeddings(
model_name="intfloat/multilingual-e5-base"
)
参考:LangChain の Embeddings を試す|npaka
読込した内容を保存する
読込した内容を保存するのに Chroma DB を使うことにします。
Chroma DB は、LLM(大規模言語モデル)アプリケーションを開発するために設計されたオープンソースのデータベースで、ベクトル埋込を格納します。
! pip install chromadb
import langchain.vectorstores
# 読込した内容を保存
vectorstore = langchain.vectorstores.Chroma.from_documents(
documents=docs,
embedding=embedding
)
参考:LangChainのChromaの使い方メモ - 佐藤百貨店
保存したデータを検索する
保存してあるデータを入力内容に従って検索します。
query = "なごや個人開発者の集いとは何ですか。"
# 検索する
docs = vectorstore.similarity_search(query=query, k=5)
for index, doc in enumerate(docs):
print("%d:" % (index + 1))
print(doc.page_content)
結果は↓
1:
「なごや個人開発者の集い」は、毎週日曜日に開催する定例オフライン開発会です。
ソフト・ハードのエンジニアだけでなく、デザイナー、クリエイター、マーケターの方々が集い
もくもく作業するもよし
2:
後略
保存したデータから入力内容に関連する箇所が検索されています。↑
検索した内容をプロンプトに加えて回答させる
検索した内容をプロンプトに加えて回答するように、既存のコードを修正します。
プロンプトを準備する
import langchain.prompts
# プロンプトを準備
template = """
<bos><start_of_turn>system
次の文脈を使用して、最後の質問に答えてください。
{context}
<end_of_turn><start_of_turn>user
{query}
<end_of_turn><start_of_turn>model
"""
prompt = langchain.prompts.PromptTemplate.from_template(template)
{query} だけでなく {context} を加えます。↑
チェーンを準備する
# チェーンを準備
chain = (
prompt
| llm
)
ここは変更なし。
保存したデータを検索する
query = "なごや個人開発者の集いとは何ですか。"
# 検索する
docs = vectorstore.similarity_search(query=query, k=5)
保存したデータを入力内容に従って検索するコードを持ってきます。↑
チェーンを実行して回答する
content = "\n".join([f"Content:\n{doc.page_content}" for doc in docs])
# 推論を実行
answer = chain.invoke({'query':query, 'context':content})
print(answer)
検索した内容を context にセットしてチェーンを実行します。↑
結果は↓
<bos><start_of_turn>system
次の文脈を使用して、最後の質問に答えてください。
Content:
「なごや個人開発者の集い」は、毎週日曜日に開催する定例オフライン開発会です。
ソフト・ハードのエンジニアだけでなく、デザイナー、クリエイター、マーケターの方々が集い
もくもく作業するもよし
Content:
中略
<end_of_turn><start_of_turn>user
なごや個人開発者の集いとは何ですか。
<end_of_turn><start_of_turn>model
なごや個人開発者の集いは、毎週日曜日に開催する定例オフライン開発会です。
回答が、検索した内容に基づいたものに変わりました。↑
他のクラスでチェーンを作る
LangChain には質疑応答のために用意されたチェーンがあります。これを使ってみます。
import langchain.chains
# チェーンを準備
qa = langchain.chains.RetrievalQA.from_chain_type(
llm=llm,
retriever=vectorstore.as_retriever(),
chain_type='stuff',
)
# 推論を実行
answer = qa.run(query)
print(answer)
結果は↓
Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
「なごや個人開発者の集い」は、毎週日曜日に開催する定例オフライン開発会です。
ソフト・ハードのエンジニアだけでなく、デザイナー、クリエイター、マーケターの方々が集い
もくもく作業するもよし
中略
Question: なごや個人開発者の集いとは何ですか。
Helpful Answer: なごや個人開発者の集いとは、毎週日曜日に開催する定例オフライン開発会です。
プロンプトを準備する、保存したデータを入力内容に従って検索するコードが、予めセットされているようです。