はじめに
OpenAI 社の ChatGPT を始めとして、生成 AI を使ったサービスも一般的になってきました。
自分も ChatGPT API サービスを使って独自のチャットアプリを自作してみたりしました。
とはいうものの、サービスの裏側で生成 AI プログラムが、具体的にどう動いているのかが分かりませんでした。
機械学習 (マシンラーニング) とか深層学習 (ディープラーニング) とか自然言語処理 (NLP) とか大規模言語モデル (LLM) とか、概念を説明した記事ばかりか、読んでも分からない数式が羅列された記事で、理解しようとするのは放棄し始めていました。
ところが、会社のチャットルームで、Gemma を使ってみたという投稿ありました。
プライベートの勉強会の知人も、Stable Diffusion で画像生成したりしています。
同僚や知人が AI プログラミングしているのですね。負けていられないなと思いました。
生成 AI プログラムについて、改めて調べ始めました。その結果、自分が納得できる程度に分かってきました。
生成 AI プログラムについて考える
生成 AI プログラムとは
「生成 AI プログラム」は、文章や画像などの入力内容に対して、文章や画像などの出力内容を、AI が生成するプログラムです。
このときプログラムは「モデル」を参照します。
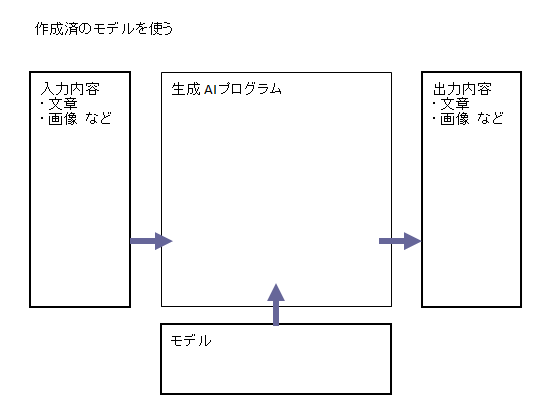
モデルとは、どんな入力内容に対して、どんな出力内容を生成するか、記述したものです。
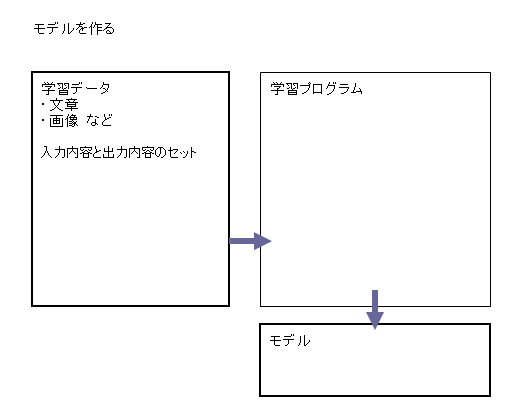
入力内容と出力内容のセットを「学習データ」として用意して、これを読んで学習プログラムでモデルを作成します。
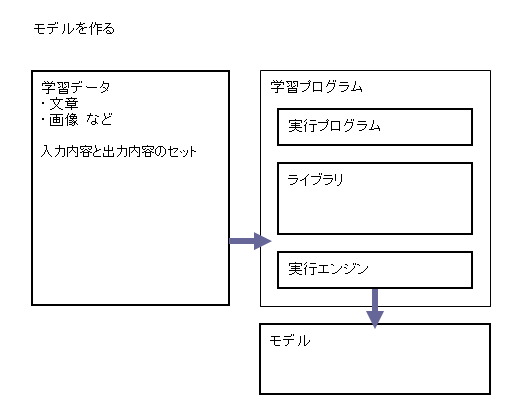
具体的にどう実装されるのか
生成 AI プログラムや学習プログラムは、どう実装されているのでしょうか。
モデルを参照して入力内容から出力内容を生成するプログラムが、ライブラリとして作られています。例えば
・TensorFlow
・Torch(PyTorch)
・JAX/Flax
などがあります。さらに、プログラムを書き易くする上位のライブラリが用意されていたりします。例えば
・Transformers
・Diffusers
入力内容を読んでライブラリに渡し、出力内容をライブラリから貰って出力する、実行プログラムを用意して実行します。

モデルは、それらのライブラリが参照するファイル群です。ライブラリごとに記録形式が違うことになります。
モデルを作成する学習プログラムも、生成プログラムと同様の構成で実行されます。
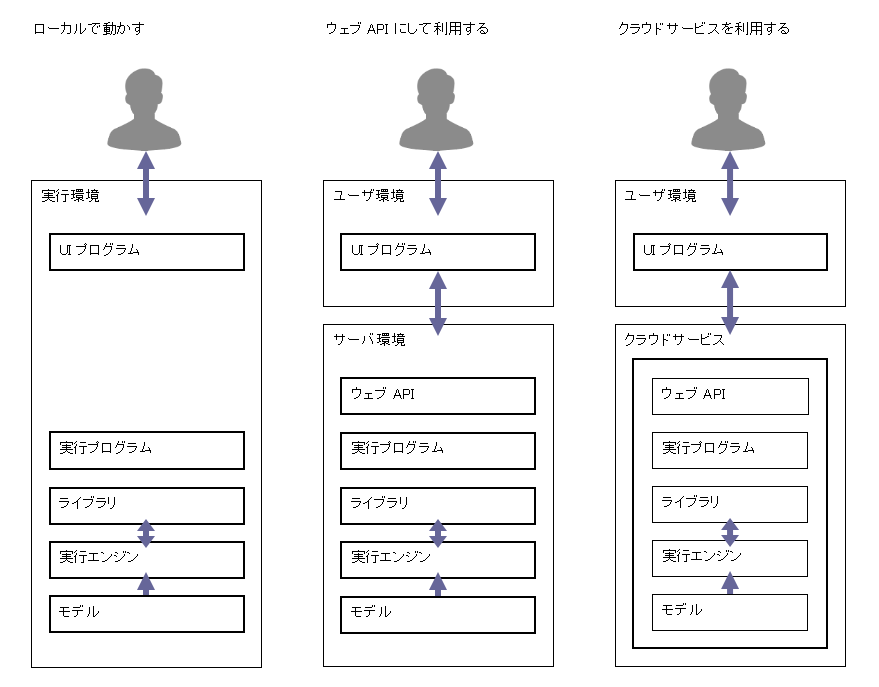
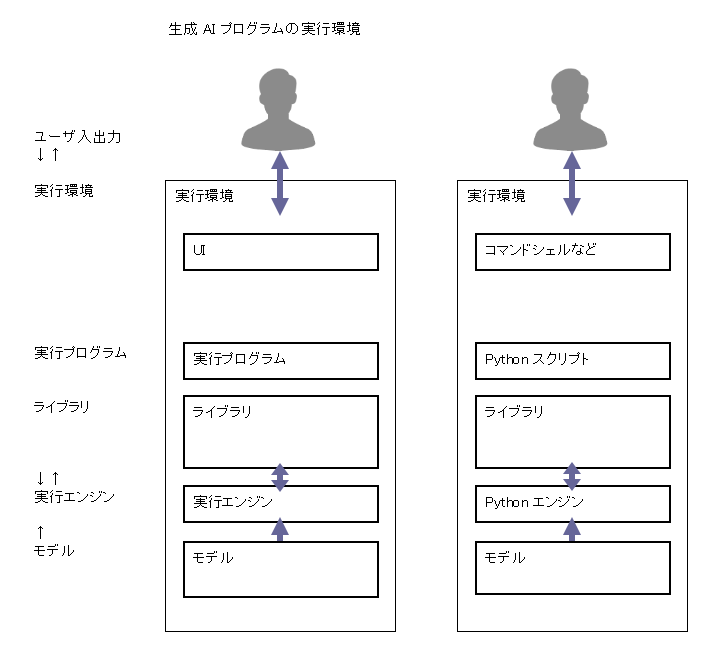
生成 AI プログラムの実行環境
生成 AI プログラムの実行環境は、どう用意すればいいでしょうか。
AI プログラムのライブラリの多くは、Python 用に作られています。プログラムの実行エンジンとして Python をインストールして、その環境にライブラリとモデルをインストールして、Python スクリプトを用意して実行します。
このとき UI のためのプログラムも必要になります。
生成 AI プログラムを試してみる
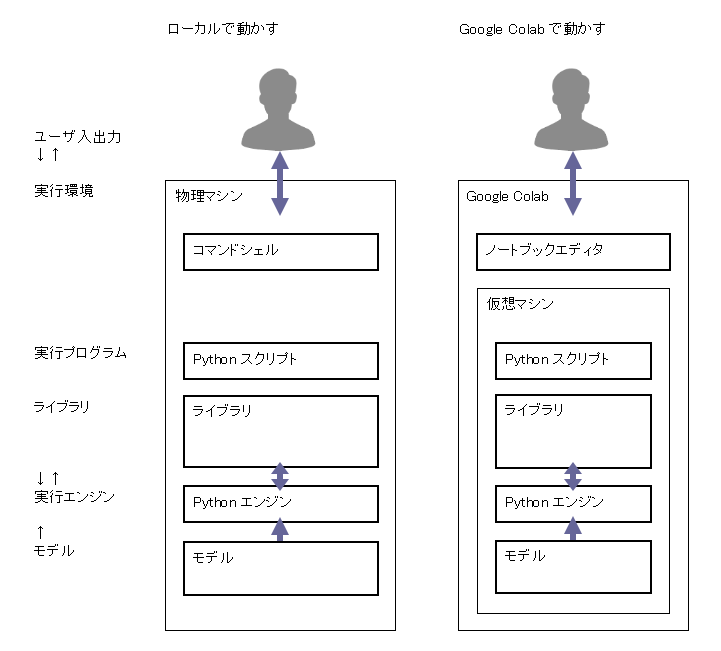
実行環境を用意する
AI プログラムの実行環境は、高速な計算するために大きなメモリや GPU を使います。そのため高額なマシンが必要になります。
高機能なマシンを時間利用できるクラウドサービスが用意されています。例えば
・Google Colab
・AWS Cloud9
Google Colab を使ってみる
AI プログラムの実行環境に、Google Colab を使ってみます。
Google Colab は、ホスト型 Jupyter Notebook サービスです。
Jupyter Notebookを徹底解説!(インストール・使い方・起動・終了方法) - ビジPy
Jupyter Notebook は、プログラムの対話型実行環境です。
セル(入力欄)にコードを記述して、実行ボタン押下でコードを実行できます。
行頭に「!」がある行は、OS のコマンドシェルのターミナルでコマンドを実行するのと同じです。
Google Colab の実体を確認してみる
Google Colab の実体を確認してみます。Google Colab のノートで、以下のコードを実行します。
! whoami
root
! pwd
/content
! cat /etc/*release
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=22.04
(以下略)
Ubuntu OS のマシンが用意されているのだと分かります。↑
文章生成 AI プログラムを試してみる
文章を生成する AI プログラムを試してみます。
以下の記事を参考にしました。
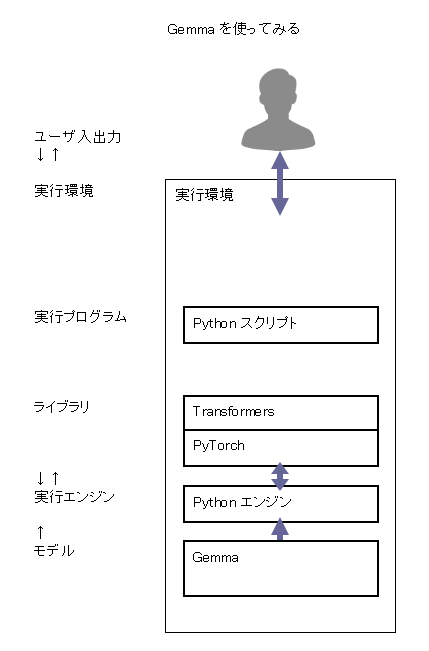
Gemma 、GPT とは
Gemma は、Google 社が作成した無料のオープンソース LLM (大規模言語モデル) のファミリーで、Gemini の軽量バージョンとして機能します。
GPT (Generative Pre-trained Transformer) は、OpenAI 社が作成した言語モデルのファミリーです。
実行環境を用意する
上述の通り Google Colab を使ってみます。別の環境でも構いません。
以下のコード例は、Google Colab あるいは Jupyter Notebook で実行するものです。
ライブラリをインストールする
Transformers ライブラリを使うのでインストールします。
! pip install transformers sentencepiece accelerate
モデルを用意する
モデルはリポジトリサービスから入手します。今回は Hugging Face を使用します。
Hugging Face – The AI community building the future.
そのため、あらかじめ Hugging Face のアカウントを作成して、自作プログラムが Hugging Face のリポジトリを使用するためのアクセストークンを取得しておきます。
Gemma モデルは、Hugging Face を通して Google から入手します。Hugging Face の使用したいモデルのページを開いて、事前に Google の「認証」しておく必要あります。
参考:ユーザー登録が必要なHugging Faceのモデルを利用するための準備 - ガンマソフト
上記で取得した Hugging Face のアクセストークンを、Google Colab の「シークレット」で、環境変数 HF_TOKEN にセットしておきます。
参考:Google Colab のシークレット機能の使い方|npaka
プログラムを実行する
Transformers ライブラリを使う Python プログラムを用意して実行します。
トークナイザとモデルを用意する
import transformers
import torch
# トークナイザとモデルの準備
tokenizer = transformers.AutoTokenizer.from_pretrained(
"google/gemma-2b-it"
)
model = transformers.AutoModelForCausalLM.from_pretrained(
"google/gemma-2b-it",
device_map="auto",
torch_dtype=torch.float16
)
モデルの実体を確認してみる
参考:【🔰Huggingface Transformers入門①】モデルの概要と使い方 - つくもちブログ 〜Python&AIまとめ〜
モデルは、以下のコードを実行すると transformers ライブラリが、リポジトリからダウンロードして Python オブジェクトとして使用できるようにします。
model = transformers.AutoModelForCausalLM.from_pretrained(
"google/gemma-2b-it"
)
このオブジェクトをストレージに保存できます。
model.save_pretrained("./saved_model")
保存したオブジェクトを確認してみましょう。
! ls ./saved_model/ -1
config.json
generation_config.json
model.safetensors.index.json
model-00001-of-00002.safetensors
model-00002-of-00002.safetensors
model-00001-of-00002.safetensors と model-00002-of-00002.safetensors は、サイズが大きいバイナリファイルです。モデルの実態と言っていいでしょう。
リポジトリからダウンロードするのでなく、ストレージに保存したモデルを使用することもできます。
model = transformers.AutoModelForCausalLM.from_pretrained(
"./saved_model"
)
プロンプトを準備して推論を実行する
文章の「プロンプト」を用意して、これを入力内容にして AI プログラムで「推論」させて結果を作成させます。
# プロンプトを指定
prompt = "Fate シリーズで一番おもしろいのは何かな。"
# 推論を実行
input = tokenizer.encode(
prompt,
return_tensors="pt"
).to(model.device)
outputs = model.generate(
input,
do_sample=True,
num_return_sequences=3
)
結果を出力する
作成された結果を出力します。
# 結果を出力
for index, output in enumerate(outputs):
print("%d:" % (index+1))
print(tokenizer.decode(output))
結果の例です。↓
1:
Fateは、自然に残り続けるような力源と、生命を維持するための力源として機能する普遍的な力。 Fate は、さまざまな分野で利用され、歴史、科学、宗教など様々な分野で活用されています。
しかし、 Fate の最も興味深い点は、生命力ではなく、むしろ「想像力」 であることであることだ。想像力は、人間が想像する可能性がある限り、何でも創造できる可能性を持っていると考えられます。
Fate は、人間にとって最も魅力的な力だとされており、多くの小説と映画で活用されています。
2:
Fateシリーズは、様々な形式で展開する物語で、その複雑なストーリー、魅力的なキャラクター、そして興味深いテーマについて想像力を開けるだけでなく、多くのファンを獲得しています。特に、Fate/stay nightのストーリーは、特に注目されています。
Fate/stay nightのストーリーは、主人公と契約者の交流と共存を描いた物語で、その複雑なストーリーは、その複雑なテーマに直接反映されています。また、その魅力的なキャラクターも、この物語で特に特徴的な部分です。
しかし、上記以外にも、Fateシリーズには多くの魅力的なストーリーがあると考えられます。
3:
Fate/Stay Nightmaresのアニメは、Fate/Zeroのアニメとは違って、ストーリーが異なる。 Fate/Stay Nightmaresは、Fate/Zeroとは異なる世界観で、登場人物とともに夢の世界で戦うストーリー。
Fate/Stay Nightmaresは、Fate/Zeroのストーリーよりも壮大で、物語の展開も異なることが多い。
Fate/Stay Nightmaresは、Fate/Zeroとは異なる世界観とストーリーで、物語が魅力的なストーリーであることをぜひ覚えてください。
1 回の実行で 3 つの結果を出すようにしています。
実行するごとに結果が変わります。
モデルを替えてみる
モデルを Gemma から別の GPT-2 に替えてみます。
# トークナイザとモデルの準備
tokenizer = transformers.AutoTokenizer.from_pretrained(
"colorfulscoop/gpt2-small-ja"
)
model = transformers.AutoModelForCausalLM.from_pretrained(
"colorfulscoop/gpt2-small-ja",
device_map="auto",
torch_dtype=torch.float32
)
推論させて結果を出力するプログラムは同じです。出力すると↓
1:
Fate シリーズで一番おもしろいのは何かな。」と話している。2016年5月20日にポニーキャニオンよりリリースされた。前作の「恋のから騒ぎ」から3か月ぶりのリリースとなる。販売形態は通常盤(PCCG-01103)と初回限定盤A(PCCG-01104)の2種リリースで、初回限定盤Aには「恋のから騒ぎ」のPVが収録されたDVDが同梱されている。通常盤の初回プレス分には、「恋のから騒ぎ」のTV SPOT付き応募特典シリアルが封入される(シリアルナンバー封入特典は通常盤の初回プレス分にも封入)。また、通常版特典として2014年3月18日に日本武道館にて行われた『恋のから騒ぎ
2:
Fate シリーズで一番おもしろいのは何かな。」と言われたことで、自分の存在意義と自信を取り戻し、自信を深めていく。「自分の居場所を見つけよう。」と言われ、その方法はどこからも見つからないという状況にもなり、それを機に、自分を見つめ直していく。この2人が出会ったのは、中学時代からの友人である、高校1年生の大熊和也とその弟、和也の父、母、和也の親友。和也には心温まる思いがあるようで、和也が学校を休むと2人の家から「一緒に生活しよう。」と言われ、和也のことが大好きになる。ある日、和也が「和也と和也が
3:
Fate シリーズで一番おもしろいのは何かな。」と、その旨が語られた。2016年7月20日、本作のオフィシャル・トレイラーが公開された。その際、ファンからは「Ringer of an answer」と呼ばれる。本作は批評家から好意的に評価されている。映画批評集積サイトのRotten Tomatoesには30件のレビューがあり、批評家支持率は81%、平均点は10点満点で7.38点となっている。サイト側による批評家の見解の要約は「『アンダーウッド・ガールズ』はファンに、心地よい結末をもたらすためにも、そのエンディングや展開に重点が置かれている。」となっている。また、Metacriticには7件のレビューがあり、加重平均値は69/
プロンプトつまり入力内容が同じでも、モデルが違うと別の結果が作成されることが分かります。
画像生成 AI プログラムを試してみる
画像を生成する AI プログラムを試してみます。
以下の記事を参考にしました。
【Stable Diffusion】Pythonでテキストから画像を生成しよう! - AI Academy Media
Stable Diffusion を Diffusersライブラリで実行する方法 - ガンマソフト
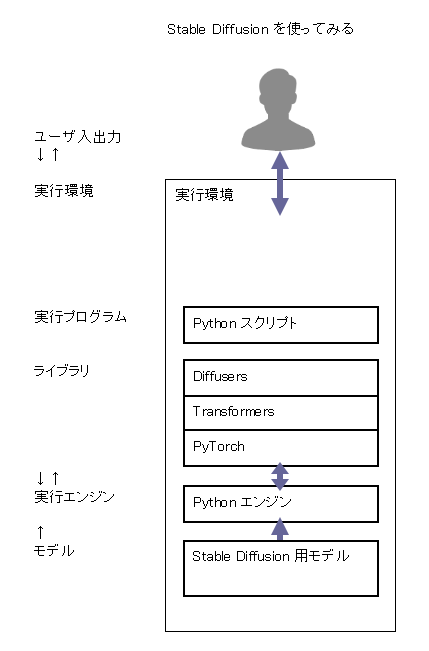
Stable Diffusion とは
Stable Diffusion(ステイブル・ディフュージョン)は、2022 年に公開されたディープラーニング(深層学習)の text-to-image モデルです。
参考:Stable Diffusion - Wikipedia
実行環境を用意する
上述の通り Google Colab を使ってみます。別の環境でも構いません。
以下のコード例は、Google Colab あるいは Jupyter Notebook で実行するものです。
ライブラリをインストールする
Transformers と Diffusers ライブラリを使うのでインストールします。
! pip install transformers accelerate
! pip install diffusers
モデルを用意する
モデルはリポジトリサービスから入手します。今回は Hugging Face を使用します。
Hugging Face – The AI community building the future.
Stable Diffusion のモデルは、Gemma と違って、Hugging Face のリポジトリを使用するためのアクセストークンは不要のようです。
プログラムを実行する
Transformers と Diffusers ライブラリを使う Python プログラムを用意して実行します。
モデルとパイプラインを用意する
import diffusers
import torch
model = "CompVis/stable-diffusion-v1-4" # モデルを指定
device = "cuda"
# モデルのダウンロードとパイプラインの作成
pipe = diffusers.StableDiffusionPipeline.from_pretrained(
model,
torch_dtype=torch.float16
).to(device)
プロンプトを準備して推論を実行して結果を出力する
文章の「プロンプト」を用意して、これを入力内容にして AI プログラムで「推論」させて結果を作成させます。
# 出力先ディレクトリを作成
! mkdir outputs
# プロンプトを指定
prompt = "A whale swimming in the starry sky"
# 数枚の画像を生成して保存する
for i in range(3):
# 画像を生成
result = pipe(
prompt
)
image = result.images[0]
# 画像を保存
image.save(f"outputs/{i+1}.png")
1 回の実行で 3 つの結果を出すようにしています。
実行するごとに結果が変わります。
生成された図の例↓

モデルを替えてみる
モデルを替えてみます。
model = "admruul/anything-v3.0" # モデルを指定
device = "cuda"
# モデルのダウンロードとパイプラインの作成
pipe = diffusers.StableDiffusionPipeline.from_pretrained(
model,
torch_dtype=torch.float16
).to(device)
推論させて結果を出力するプログラムは同じです。出力すると↓

プロンプトつまり入力内容が同じでも、モデルが違うと別の結果が作成されることが分かります。
生成 AI プログラムの実行環境について考える
実行プログラムをコマンドシェルで呼出するのは、一般ユーザには使いづらいものです。そこで、UI プログラムを用意することになります。
生成 AI の実行プログラムを、ウェブ API を通して呼出できるように作ることができます。これをいわゆるバックエンドにして、フロントエンドの UI プログラムを用意しやすくなります。
生成 AI の機能をウェブ API として提供する機クラウドサービスもあります。これを使って UI プログラムを用意することができます。