執筆にあたって
弊社では、S3に保存されているデータをRDS(MySQL)にimportする際に、LambdaやECSを用いておりました。
この作業をAWSのサービスの一つである「Glue」で行うように変更することが決まりました。
それに伴って情報のキャッチアップを行なっていたのですが、Stepfinctionsと合わせて運用されている記事で、lambdaを使って実装されていたり(今回は直接実行をしたい)、古めの記事や内容のものが多かったので、新しい情報を纏めようと思いました。
また、これらの記事の全肯定はGlue crawlerの作成→実行、Connectorの作成、Jobの作成→実行の全行程を網羅的に記述していくつもりです。
初心者でもGlueの実行までができるようになることを目標としています!
コンソール上でJob実行まで出来ればいいよーって人は2章から読んでもらえたらと思います!
※現在は検証段階なので、記事の内容が「全て正しい」、あるいは「ベストプラクティスである」というわけではありません。
※以下、本記事においては、RDSはMySQLと同義とします。
この記事におけるGlue活用の目標
S3に保存されているデータをRDSにimportする際に、lambdaやECSを使わずに、GlueとStepfunctionsだけを用いて完了させることを目標としています。
以下、具体的にimportに必要なGlueの操作をまとめます。
・Glue crawlerの作成
・Glue crawlerの実行
・Glue jobの作成
・Glue jobの実行
Glue crawlerはS3のファイルとRDSに対して実行するものであり、データの構造等の情報を取得し、データカタログを作成することです。crawlerの作成はコンソール画面やLambdaでも行うことができますが、今回はコンソール上で作成し、それをStepfunctionsでinputを渡し、直接実行していく方法をとります。
Glue jobの実行は、crawlerの作業で作成されたデータカタログをもとにS3ファイルを直接RDS内にimportします。crawler同様、jobはコンソール画面で作成・設定後、Stepfunctionsで直接実行していく形式を取ります。
Stepfunctions上の設計図
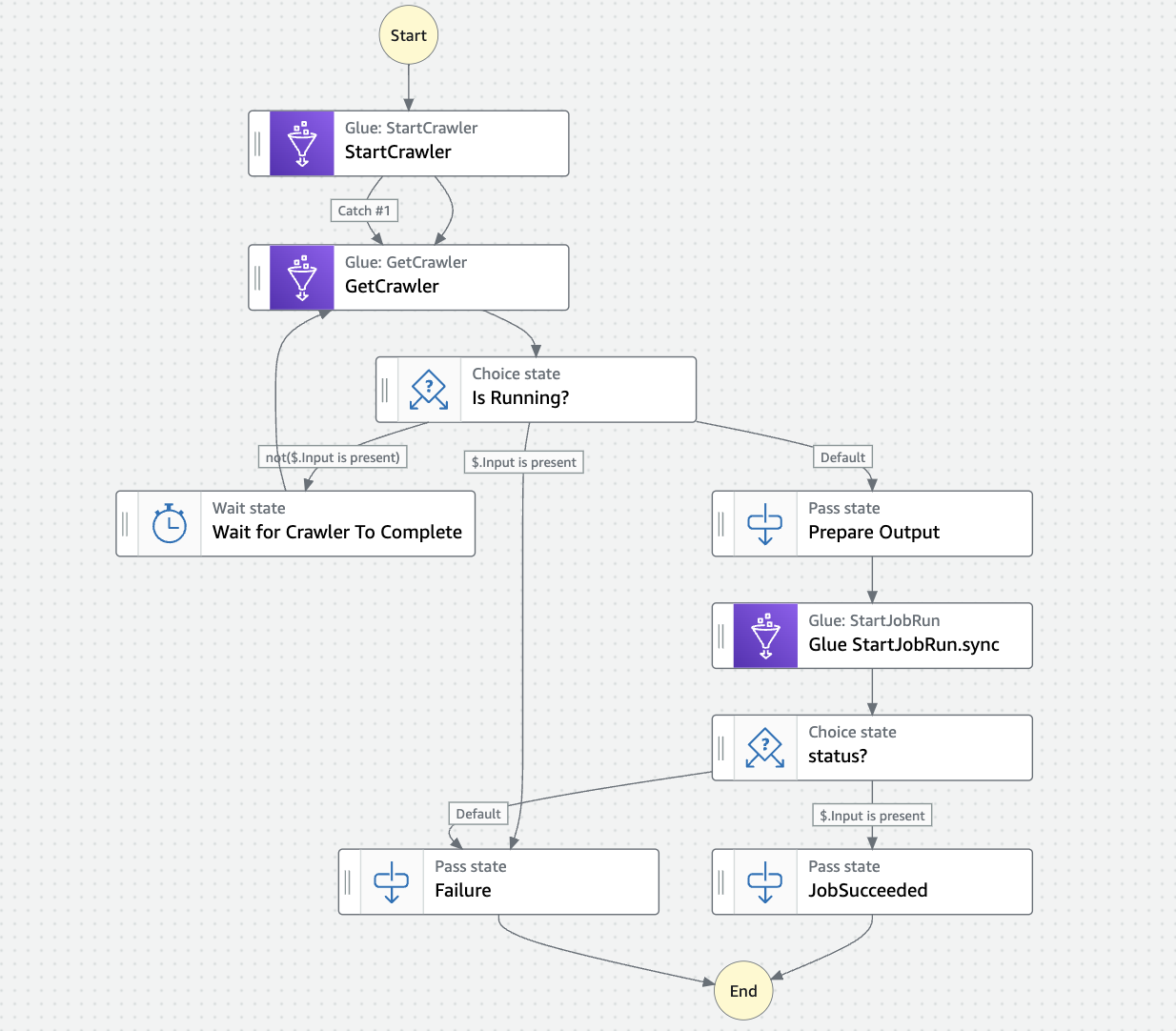
上記は想定のイメージ図です。(実際はエラー時の切り分けを行いやすくするために、ちょこちょこ条件を追加します)
PassStateの部分は適宜変更を加えていきます。
以下、この設計に至った解説を行います。
・startCrawler→GetCrawler→is Runnning?→Wait for Crawler To Complete
すでに作成してあるcrawlerにinputを与え、startCrawlerで実行します。
それに対して、GetCrawlerで処理状況を確認していきます。
2023/07現在では、crawler作業は非同期でしか実行することができないため、処理中か否かで条件分岐を行い、「〜分待って、再び処理状況を確認する」の処理を加えます。
・Glue StartJobRun.sync→status
crawlerのoutput(データカタログ)を受け取り、GlueJobの実行を行います。
こちらは同期実行、非同期実行のどちらでも行うことができます。
(同期実行を行いたい時は、コードスニペットの"Resource": "arn:aws:states:::glue:startJobRun"の最後に「.sync」を加えれば良いです)
今回は同期実行で、Jobが終了したら処理を進めるように設計しています。
同期実行なので、timeoutの設定は忘れずに。
また実行ステータスはSTARTING、RUNNING、STOPPING、STOPPED、SUCCEEDED、FAILED、ERROR、WAITING、TIMEOUTがあります。
参考:https://aws.amazon.com/jp/blogs/news/orchestrating-aws-glue-crawlers-using-aws-step-functions/
実行ステータスについて:https://docs.aws.amazon.com/ja_jp/glue/latest/dg/job-run-statuses.html
また、余談ですが同期実行と非同期実行で処理遅延時間が異なってくるそうです。
詳しくは下記のQiita記事が参考になります。
【AWS】.syncを使わずにStep FunctionsからGlueJobを実行してみた【性能改善】
https://qiita.com/toru_yamashita/items/a2ecc1f29fbbce5e4344
非同期だと平均6sの処理が、同期だと平均41sぽいです。
次章では、Glue自体の検証や仕様についてのあれこれをまとめていきたいと思います。