
結論を先に
USDJPY 60分足のMAクロス戦略144通りを総当たりした。
- フルサンプル最良: Sharpe 0.57、累積リターン +35.45%、MaxDD -10.13%
- 一見すると悪くない戦略に見える
そもそも144候補のフルサンプルSharpe分布を見ると、中央値は -0.277、25%点は -1.245 で、大半の候補は負のSharpeである。Sharpe 0.57は「分布の右端」を後出しで拾った数字に過ぎない。
CSCV風に検証するとさらに状況は厳しい。
- IS最良戦略の平均Sharpe: 0.75 → 0.12(差分 -0.63、ISの約84%が消える)
- IS-OOS回帰: slope = -0.556, Pearson r = -0.258, Spearman ρ = -0.339
- OOS損失確率: 35.7%(95% Wilson信頼区間 25.4% – 47.5%、参考値)
- 平均OOS順位: 32位 / 144
- 簡易PBO: 4/70 = 5.71%(95% Wilson信頼区間 2.2% – 13.8%、参考値)
PBOは低めだが、これは「安全」を意味しない。PBOは「選んだ戦略が候補群の中で下位半分に落ちるか」を見るrank-basedな指標であり、OOS損失確率は「絶対リターンがマイナスか」を見る経済的な指標である。両者は別物であり、候補群全体の質が低ければ、OOS順位が上位でも絶対リターンはマイナスになり得る。
Bailey, Borwein, López de Prado, Zhu (2014) のフレームワークが指摘するのは、まさにこの点である。
以下、論文の要点と実験の詳細を整理する。
論文URL: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2326253
1. 問題設定:AI時代のエッジ探索は「簡単」になった
近年、AI、Python、クラウド、各種バックテストライブラリの発達により、クオンツトレードにおけるエッジ探索は以前よりもはるかに容易になりました。移動平均、RSI、ボリンジャーバンド、機械学習モデルなど、多数の売買ルールや特徴量を短時間で検証できます。
しかし同時に、大量に試せば試すほど、偶然うまく見える戦略も見つかってしまうという問題が深刻化しています。これは統計でいう 多重検定問題 に近いものです。
論文の著者らは、ランダムウォーク系列に対して移動平均クロス戦略を最適化することで、年率Sharpe 1.27という見かけ上有意な戦略を作り出せることを示しています。エッジがゼロの系列でも、十分試行すれば「勝っているように見える戦略」は必ず見つかります。
クオンツトレードで本当に危険なのは、負ける戦略ではなく、勝っているように見えるだけの戦略です。
2. バックテスト過学習とPBOの定義
バックテスト過学習とは
戦略が市場の本質的な構造を捉えているのではなく、過去データに含まれる偶然のノイズに過剰に適合している状態です。

典型的な症状は次のとおりです。
- ISでは非常に高い成績、OOSでは大きく劣化
- パラメータを少し変えると成績が崩れる
- 別期間・別銘柄・コスト込みで再現しない
PBOの正確な定義

論文の定義に厳密に従うと、PBOは 単一戦略の良し悪し ではなく、「N個の候補から最良を選ぶ」という選択プロセスがOOSで失敗する確率 です。
PBO = N個の候補からISで最良を選んだ戦略が、OOSではN個の中央値以下に転落する確率
したがって、PBOが高いということは、「その選択プロセスから得られた最良戦略は信用しにくい」 ことを意味します。論文ではPBO推定値が0.05を超えるモデル(選択プロセス)を棄却する慣習的運用に触れていますが、これは個々の戦略を否定するものではなく、選択プロセス全体を疑うべきだという主張です。
重要なのは、過学習を「している/していない」の二択で考えず、確率として評価する ことです。
3. 直感に反する事実:選択プロセスにおけるIS Sharpeの解釈

論文で繰り返し示される重要な経験的事実があります。
多数の候補からIS Sharpe最大のものを選ぶプロセスでは、IS Sharpeが高いほどOOS Sharpeが低くなる傾向がある。
論文Figure 2では、IS Sharpeが1〜3の範囲で、回帰直線の傾きが -0.75(R²=0.17)という強い負の関係が示されています。Figure 7(ランダムウォークに対するMAクロス最適化)でも傾きは -0.61 で同様です。
これは「市場でSharpeが高い戦略は将来悪化する」という普遍法則ではありません。そうではなく、「多数候補から最良を後出しで選ぶ」という行為自体が、IS性能を選択バイアス分だけ押し上げるという現象です。
つまり、IS Sharpeの高さは、
- 本物のエッジの強さ
- 選択バイアスの強さ
の 両方 を含んでいます。そして候補数Nが大きいほど、後者の寄与が支配的になります。
実務的な含意は次のとおりです。
- 「Sharpe 2.0の戦略を見つけたから本番投入しよう」という判断は、むしろ選択バイアスの警告サインかもしれない
- IS Sharpeが高いという事実だけでは、OOSでの優位性をまったく保証しない
- 探索プロセスを通じて高Sharpeを得るほど、OOS劣化の期待値は大きくなる
4. PBOだけでは足りない:4つの相補的分析

論文の重要な貢献の一つは、PBOを単独で見るのではなく、4つの相補的な分析を組み合わせて戦略の信頼性を評価する枠組みを提示している点です。
| 分析 | 何を見るか |
|---|---|
| (1) PBO | IS最良戦略がOOS中央値以下に落ちる確率 |
| (2) Performance degradation | IS Sharpeに対するOOS Sharpeの劣化度合い(回帰係数) |
| (3) Probability of loss | IS最良戦略がOOSで損失になる確率 |
| (4) Stochastic dominance | IS最適化選択は、ランダム選択より本当に良いか |
特に (4) Stochastic dominance は見落とされがちですが、極めて重要な視点です。
これは次のような問いです。
「N個の戦略から最良を選ぶ」という選択プロセスのOOS性能分布は、「ランダムに1つ選ぶ」場合のOOS性能分布を確率的に支配しているか?
支配していなければ、その選択プロセスは そもそも価値を生んでいない ことになります。論文Figure 4では、最適化されたOOS Sharpeの累積分布が非最適化(全戦略)のOOS Sharpe分布より左に寄っているケースが示されています。これは「最適化が逆効果」という強い証拠です。
実務上のチェックポイントは次のとおりです。
- PBOが低くてもOOS損失確率が高いことはある(過学習以外の理由で戦略が悪い)
- PBOが低くても、ランダム選択を支配できなければ「選択行為に意味がない」
- IS Sharpeが分布の右端にあっても、OOSでランダム戦略と区別できないなら、それは"見つけた"ことにならない
5. CSCV:Holdoutだけでは不十分
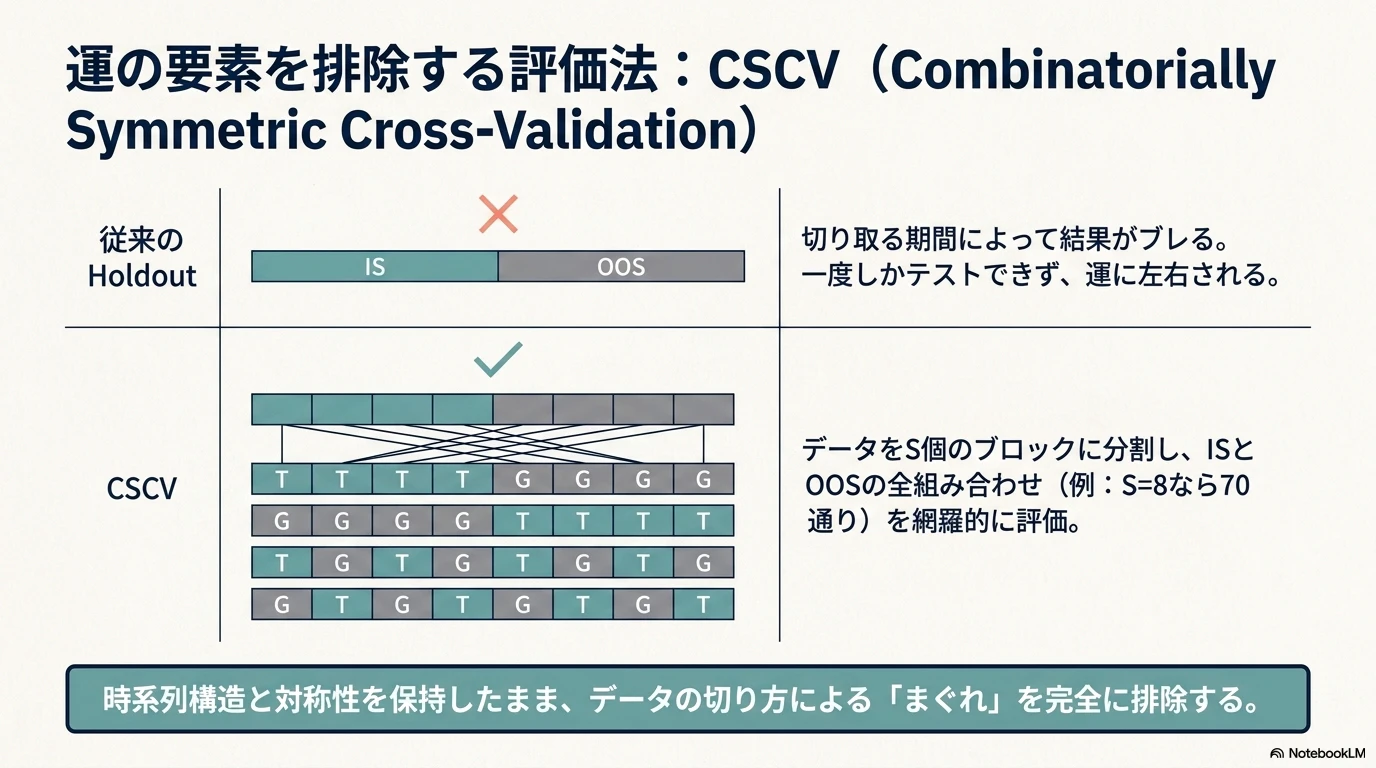
論文では、PBOを推定する方法として CSCV:Combinatorially Symmetric Cross-Validation を提案しています。
通常のHoldoutには弱点があります。どの期間をHoldoutにするかで結果が変わる、サンプルが小さいと評価が不安定、研究者がHoldout期間の特徴を知っている可能性、複数試行による過学習を反映できない、などです。
CSCVでは、データを S個のブロック に分け(論文では S=16 が推奨)、そのうち S/2 ブロックをIS、残りをOOSとする組み合わせを全通り評価します。S=16なら ${}{16}C{8} = 12{,}870$ 通りの組み合わせが生成されます。
CSCVの優位性は次の点にあります。
- IS/OOSが同サイズなので、両者のSharpe推定精度が揃う
- すべての訓練セットが検証セットとしても使われる対称性
- 観測値をランダムに割り当てないので、時系列構造が保持される
- 同じ入力に対して常に同じ結果を返す決定論的な手法
- logitの分散自体が戦略頑健性の情報を持つ
本物のエッジであれば、データの切り方を変えても、ある程度はOOSで優位性が残るはずです。逆に、過去ノイズに最適化された戦略であれば、ISでは強くてもOOSでは中央値以下に落ちやすくなります。
6. 実験:USDJPY 60分足での簡易PBO検証
実験条件
| 項目 | 内容 |
|---|---|
| 対象 | USDJPY 60分足、Bid終値ベース |
| 期間 | 2020-01-01 〜 2026-01-01(約6年) |
| データソース | MT4形式の60分足ヒストリカル(タイムスタンプはサーバー時刻) |
| 週末ギャップ | 補間せず、自然な土日ギャップとして残す(gaps_over_1h_count=318) |
| 戦略ファミリー | 移動平均クロス(短期MA > 長期MA でロング、反対でショート) |
| 短期MA | 5, 10, 20, 30 |
| 長期MA | 50, 100, 150, 200 |
| 損切り | なし / ATR(14) × 1.0 / × 1.5 |
| 利確 | なし / ATR(14) × 1.5 / × 2.0 |
| 候補数 | 4 × 4 × 3 × 3 = 144戦略 |
| 取引コスト | 往復 1.0 pips(片道 0.5 pip)、スワップ・スリッページは未考慮 |
| 約定ルール | 終値確定後にシグナル判定、次足始値で約定 |
| 同足SL/TP優先 | 保守的にSL優先 |
| CSCV分割 | 8ブロック、IS 4ブロック / OOS 4ブロック、全 ${}{8}C{4} = 70$ 通り |
論文の推奨はS=16ですが、6年分のデータで時系列構造を保つことを優先し、今回はS=8としています。
「簡易PBO」の定義
本実験のPBOは、論文の正式CSCV(順位ロジット変換による logit 分布 $f(\lambda)$ から $\phi = \int_{-\infty}^{0} f(\lambda)d\lambda$ を計算する手法)とは異なります。
今回は教育目的で、
簡易PBO = 70通りのIS/OOS分割で、IS最良戦略のOOS順位が下位半分(73〜144位)に落ちた割合
として直接カウントしています。ここで rank 1 = 最良、rank 144 = 最悪と定義しています。正式CSCVの logit ベース推定値とは細部で異なりますが、PBOの本質(IS最良がOOSで中央値より悪い側に転落する確率)は捉えられます。本記事では区別のため一貫して「簡易PBO」と呼びます。
結果1:フルサンプルでの「最良戦略」
全期間(2020-2026)で144戦略を評価したSharpe分布です。
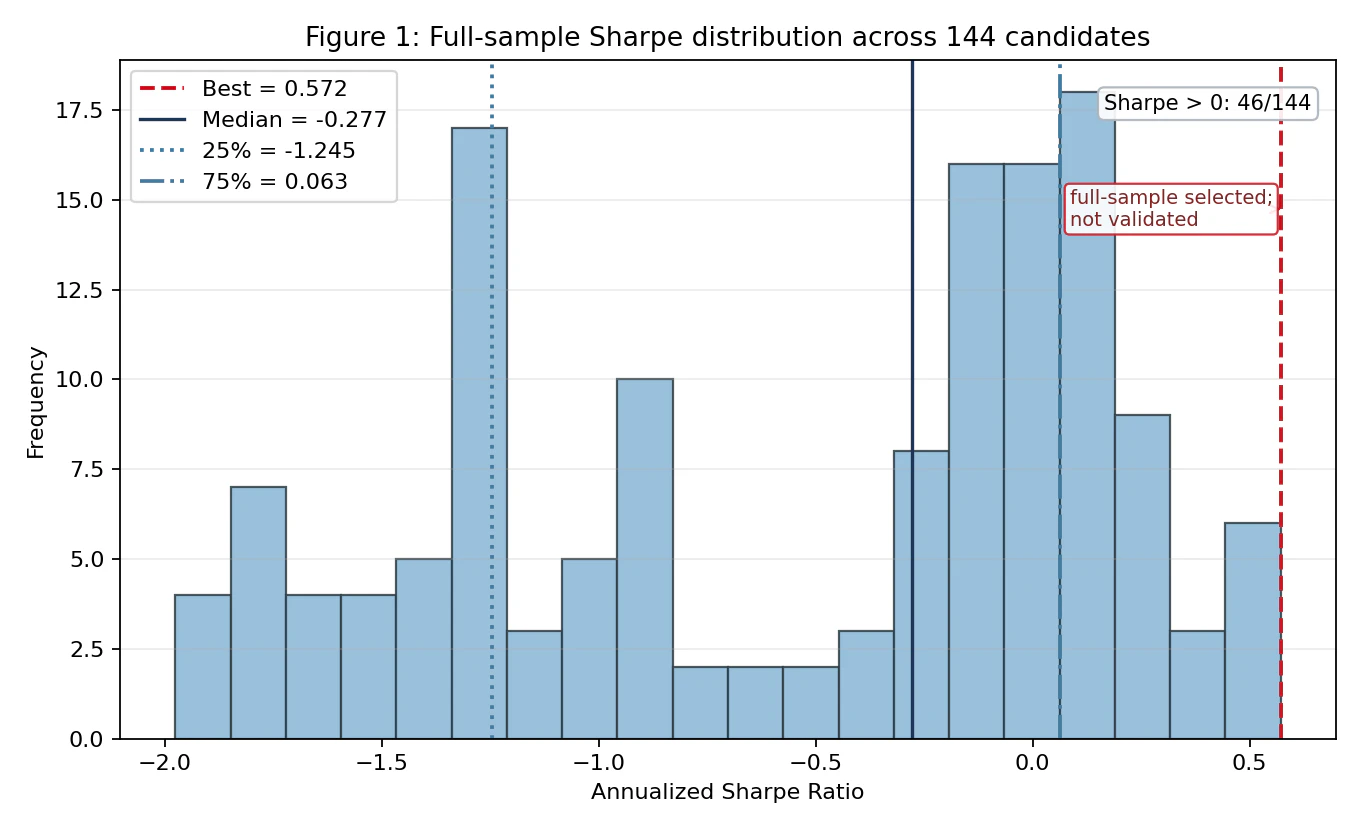
最良戦略のSharpeは 0.572、分布の右端に位置します。ここで注目すべきは、144候補の中央値が -0.277、25%点が -1.245、75%点でようやく +0.063 という分布の形です。Sharpe > 0 の候補は 46/144(約32%)に留まり、144通り試した戦略の3分の2はマイナスSharpe という結果です。
この状況下で「最良の戦略」を選ぶ行為は、本質的に マイナスSharpeが多数を占める分布から、たまたま右端に位置するものを引いてくる ことに近い、と捉えるべきです。フルサンプル最良戦略は分布の右端に位置していますが、これは「フルサンプル選択」であって検証ではない点(図内の "full-sample selected; not validated" 注記)に注意してください。
上位5戦略は以下のとおりです。
| Rank | Strategy | Sharpe | CumReturn | MaxDD | Trades | WinRate |
|---|---|---|---|---|---|---|
| 1 | ma_s20_l50_sl_none_tp_none | 0.5717 | 35.45% | -10.13% | 786 | 38.17% |
| 2 | ma_s20_l50_sl_atr1_5_tp_none | 0.5396 | 31.93% | -10.25% | 1659 | 30.08% |
| 3 | ma_s10_l50_sl_atr1_5_tp_none | 0.5088 | 29.41% | -11.27% | 1715 | 29.15% |
| 4 | ma_s10_l50_sl_none_tp_none | 0.4990 | 29.87% | -17.23% | 938 | 34.97% |
| 5 | ma_s10_l50_sl_atr1_0_tp_none | 0.4543 | 25.32% | -12.27% | 2271 | 24.39% |
最良戦略の累積損益曲線とドローダウンです。最大DD は -10.13% で、2022年後半と2025年に深いドローダウンが発生しています。
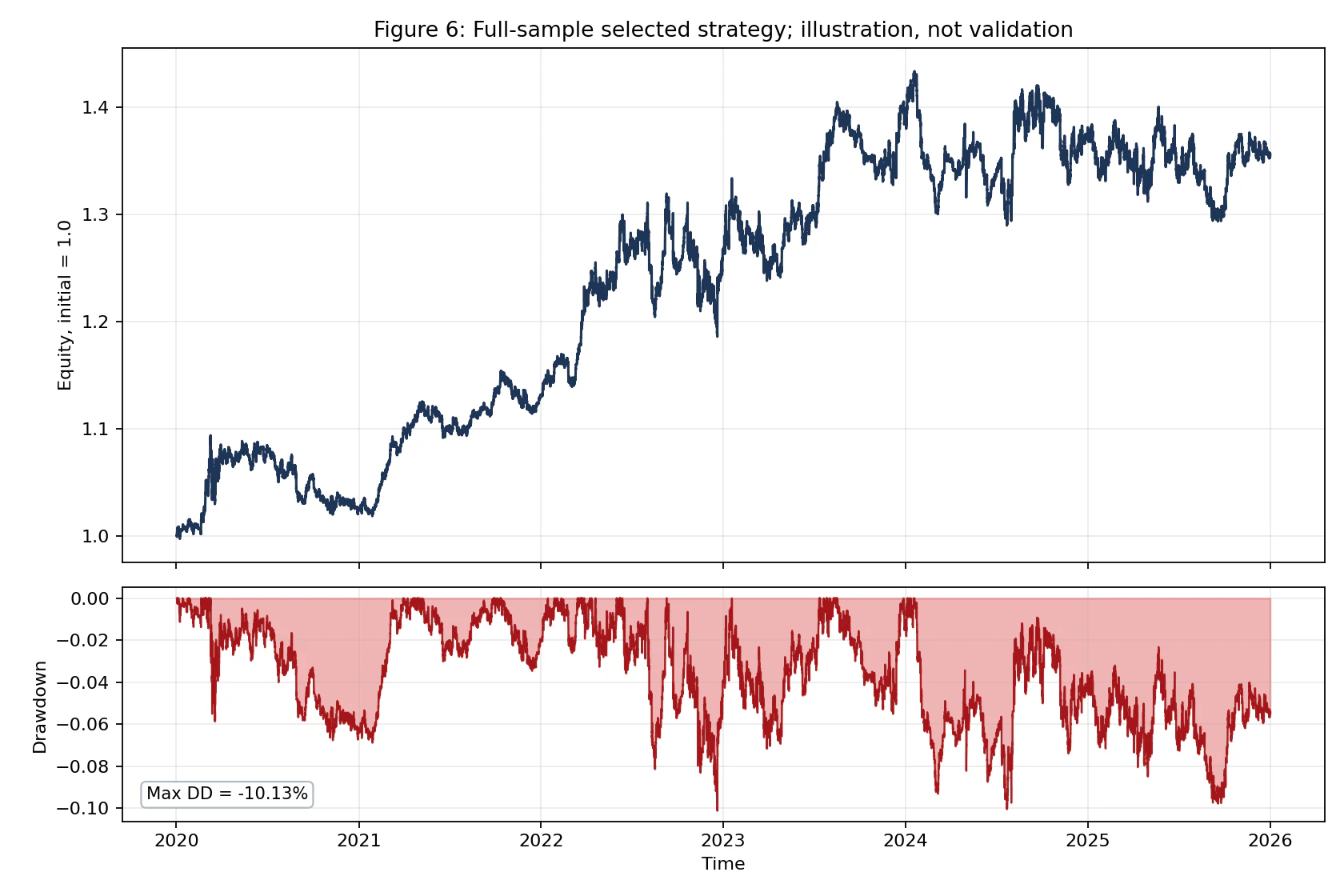
ただし、これは 後出しで最良を選んだ結果の見せ方 であって、戦略の検証ではありません。図のタイトルに "illustration, not validation" と明記しているのはそのためです。「悪くないエクイティカーブが見えた」と判断するのは、まさに論文が警告するバイアスそのものです。
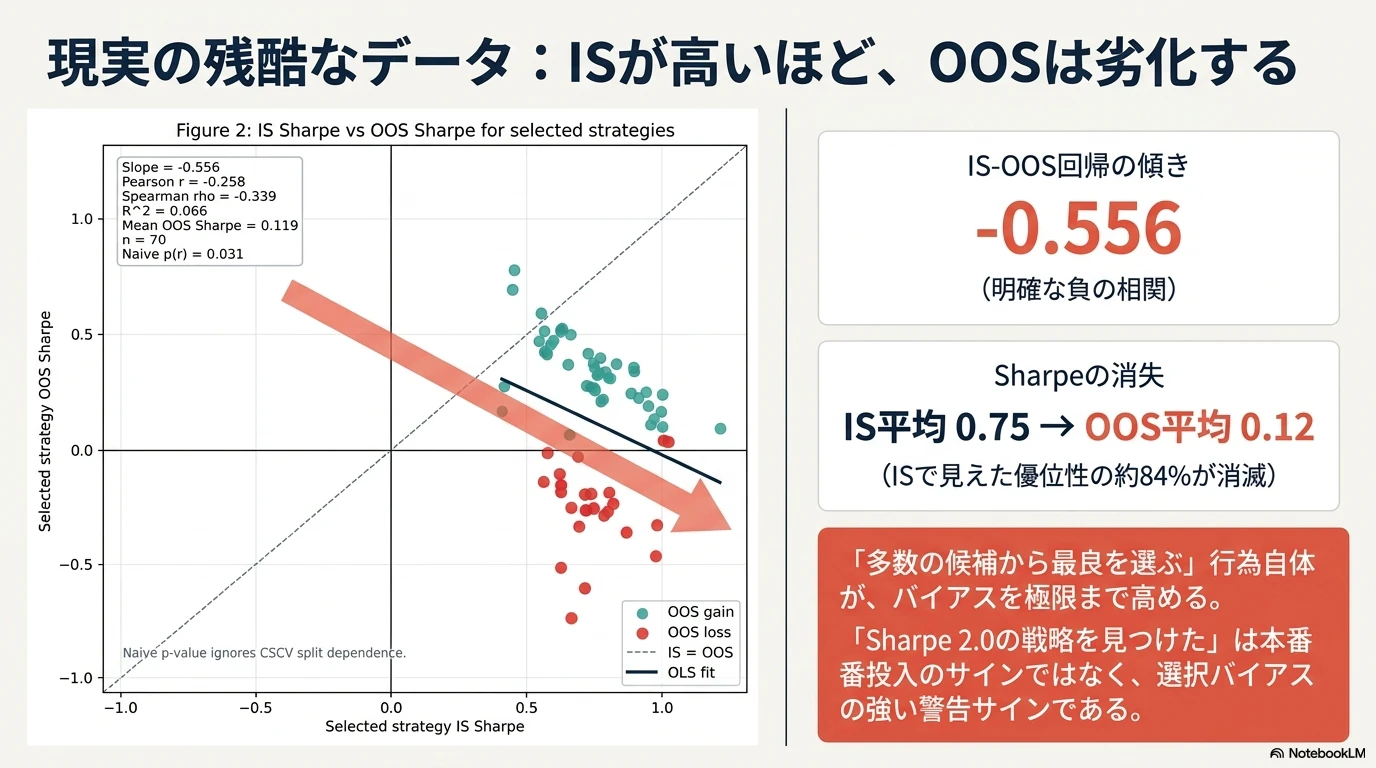
結果2:選択プロセスのCSCV検証
8ブロック分割、70通りのIS/OOS組み合わせを評価します。各組み合わせで「ISでSharpe最良の戦略」を選び、その同じ戦略がOOSでどう振る舞うかを記録します。
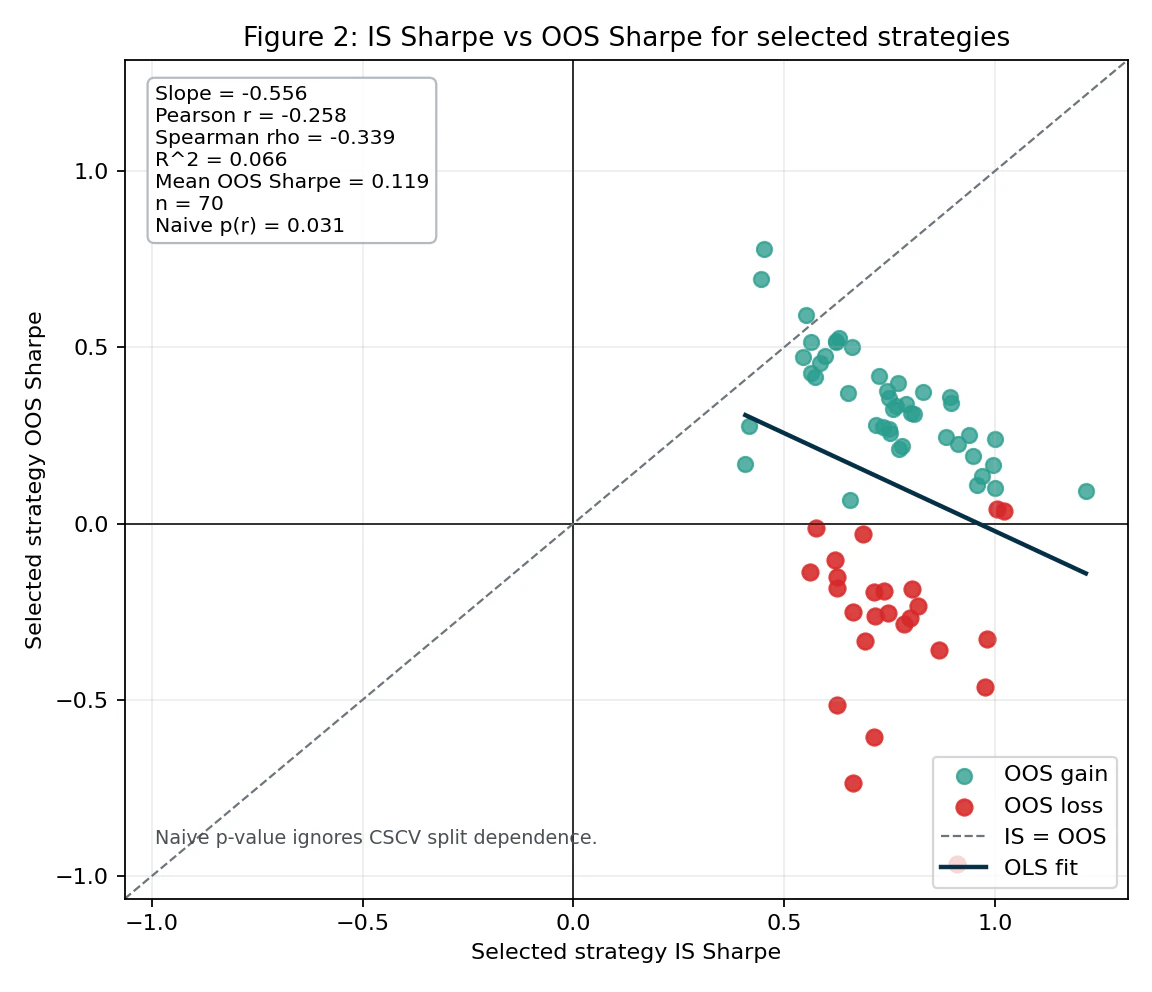
横軸がIS Sharpe、縦軸がOOS Sharpeです。OLSフィットは以下の統計値を示します。
| 統計量 | 値 |
|---|---|
| Slope | -0.556 |
| Pearson r | -0.258 |
| Spearman ρ | -0.339 |
| R² | 0.066 |
| Mean OOS Sharpe | 0.119 |
R²自体は0.066と小さく、IS Sharpeだけでは OOS Sharpeの大半を説明できません。しかし、OLS傾き・Pearson r・Spearman ρのいずれも符号は明確に負であり、
多数候補からIS Sharpeで最良を選ぶプロセスにおいて、IS Sharpeの高さはOOS Sharpeの高さを予測しない(むしろ弱く負相関する)
ことは確認できます。
図中には Pearson 相関の naive p値 = 0.031 も表示されていますが、これは70試行を独立サンプルと仮定した場合の参考値です。CSCV分割は互いに独立ではないため、この p値は厳密な統計検定として読むべきではなく、「相関の方向と大きさを直感的に評価するための補助指標」 として扱うべきです(図内の "Naive p-value ignores CSCV split dependence" 注記参照)。
参考までに、論文Figure 2では同様の回帰で slope = -0.75(R² = 0.17)、Figure 7(ランダムウォークに対するMAクロス最適化)では slope = -0.61(R² = 0.04)が報告されています。今回のUSDJPY 60分足での -0.556 は、論文の事例群と同水準の負相関です。
散布図上で OOS gain(緑)と OOS loss(赤)が分離されている 点にも注目してください。45戦略がOOSプラス、25戦略がOOSマイナス、というのが内訳です。IS Sharpeの高さでこの二群を見分けることはできません。
数字で見ると次のとおりです。
| 指標 | 値 |
|---|---|
| 選択戦略の平均IS Sharpe | 0.7474 |
| 選択戦略の平均OOS Sharpe | 0.1187 |
| 平均IS-OOS劣化幅 | -0.6287 |
| 平均OOS順位 | 32.43 / 144 |
| OOS損失確率 (P[OOS CumRet < 0]) | 35.71% |
ISで平均0.75のSharpeを示した戦略群が、OOSでは平均0.12まで落ちています。劣化幅は約 -0.63 Sharpe、ISの 84% が消えた計算です。さらに選ばれた70戦略のうち 25戦略(35.71%, 95% Wilson信頼区間: 25.4% – 47.5%、参考値) はOOS累積リターンがマイナスでした。

結果3:簡易PBO
IS最良戦略のOOS順位分布です。rank 1 が最良、rank 144 が最悪です。

OOS順位は概ね1〜80位に分布し、下位半分(73〜144位)に落ちるケースは4件のみ です。
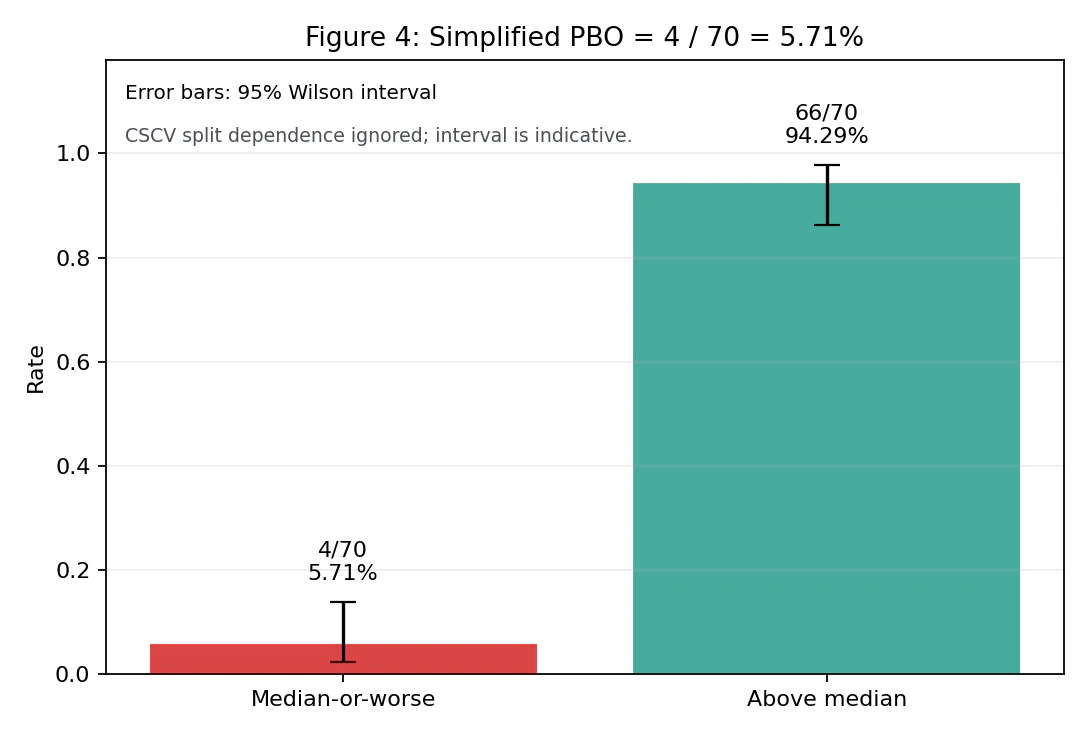
簡易PBOは 4/70 = 5.71%(95% Wilson信頼区間: 2.2% – 13.8%) となりました。点推定値は論文の慣習的閾値(0.05)と概ね同水準ですが、Wilson信頼区間の上限は 13.8% に達しており、サンプルサイズ(70通り)の制約から不確実性は大きい ことに留意すべきです。
Wilson区間に関する注記:Wilson区間は各分割を独立なベルヌーイ試行とみなした場合の参考値です。CSCVでは同じ時系列ブロックを複数の組み合わせで再利用するため、分割間には強い依存があります。したがって、この区間は厳密な信頼区間ではなく、点推定値の不確実性を直感的に示すための補助指標 として読むべきです。OOS損失確率35.7%についても同様です。
論文の推奨S=16ならば ${}{16}C{8} = 12{,}870$ 通りに増え、logit分布や順位分布はより滑らかに推定できます。ただし、組み合わせ数が増えても各分割は独立ではないため、「有効サンプル数が12,870になる」と単純解釈してはいけません。今回の S=8 / 70通りは、時系列構造保持とのトレードオフで選んだものですが、PBO推定の精度の観点では十分とは言えません。
結果4:4指標セットでの読み方
論文のフレームワークに沿って4指標を並べます。
| 分析 | 今回の結果 | 解釈 |
|---|---|---|
| (1) 簡易PBO | 5.71% (95%CI: 2.2% – 13.8%) | 中央値以下への転落は稀。ただしCIは広い |
| (2) Performance degradation | IS 0.75 → OOS 0.12(slope -0.556, R² 0.066) | 負の傾きが明確、劣化は大きい |
| (3) Probability of loss | 35.71% (95%CI: 25.4% – 47.5%) | 3回に1回以上は累積マイナス |
| (4) Stochastic dominance | 未実装(次回) | 今回は未検証 |
(4) のstochastic dominanceは、選択戦略のOOS分布が「ランダムに1戦略選んだ場合のOOS分布」を支配しているかを確認する分析です。今回の実験では未実装ですが、論文の枠組みを完結させるには本来必須の指標です。次回への宿題とします。
Rank-basedと経済的指標は別物である

今回の結果で最も重要なのは、PBOが低いにもかかわらず、OOS損失確率が35.71%ある という点です。これは矛盾ではありません。
- PBO は「選んだ戦略が候補群の中で下位半分に落ちるか」を見る rank-basedな指標
- OOS損失確率 は「絶対リターンがマイナスになるか」を見る 経済的指標
両者は別物です。候補群全体の質が低ければ、OOS順位が上位でも絶対リターンは低い、あるいはマイナスになり得ます。
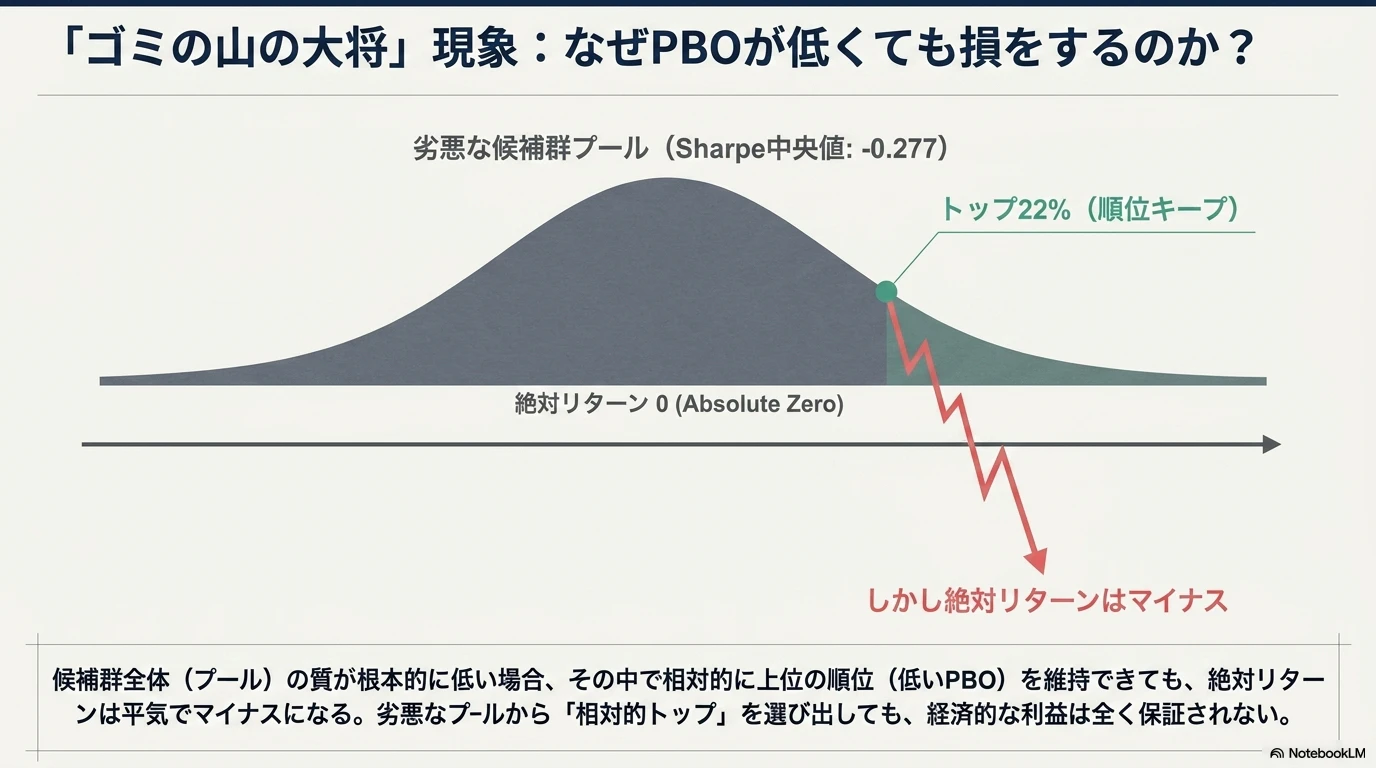
今回の実験はまさにこの状況です。144候補のフルサンプルSharpe中央値は -0.277 で、候補プール自体が劣悪です。この劣悪なプールから「相対的に上位」を選んでも、絶対リターンが安定して正になる保証はありません。「OOS順位が上位(rank 32位)= 安全」ではなく、「上位だが絶対値ではマイナス」が頻繁に発生します。
これは、PBOだけを見ていると見落とす重要な事実です。
数字をどう読むか
ここで誤解しないことが重要です。
「PBO 5.7%だから過学習していない」 とは言えません。
観察された事実を整理すると次のようになります。
- そもそも候補プール自体が悪い:144戦略の中央値Sharpeは -0.277、25%点は -1.245。マイナスSharpeが多数派の分布から右端を後出しで選んでいる
- PBOは低い(点推定5.71%、Wilson CI上限13.8%、参考値):選択プロセスがIS最良戦略をOOSで下位半分(73〜144位)に落とす確率は小さい
- IS-OOSは弱く負相関(slope -0.556, Spearman -0.339, R² 0.066):IS Sharpeの高さはOOS Sharpeの高さを予測しない
- OOS Sharpeは平均0.12まで劣化:ISで見えた優位性の84%が消える
- OOS損失確率は35.71%(参考CI 25.4%–47.5%):選んだ戦略が将来期間で損失になる確率は3回に1回以上
- 平均OOS順位は32位:「ISで最良の戦略」を選んでも、OOSではトップ22%のあたり
- Rank上位 ≠ 経済的に有利:候補プールの質が低いため、OOS順位が上位でも絶対リターンはマイナスになり得る
つまり、このMAクロス戦略ファミリーには「完全な過学習」ほど悪質な構造はないが、「ISのSharpeをそのまま将来に期待してはいけない」 という事実は明確です。
ISでSharpe 0.75を見て小資金で本番投入した場合、現実にはSharpe 0.1前後、しかも3割超の確率で累積マイナス、というのが正直な期待値です。
これは144候補という比較的控えめな探索でも観察される現象です。AIで数千〜数万のルールを生成すれば、PBOおよび他の指標はさらに悪化する可能性が高いでしょう。
ただし、ここで重要なのは 候補数Nそのものではなく、候補間の相関を考慮した「有効試行回数(effective number of trials)」 です。AIが1万ルールを生成しても、全部が似たMAクロスの亜種なら、独立試行数は1万ではありません。逆に、特徴量空間・対象銘柄・時間軸・モデル構造が広がるなら、有効試行回数は大きくなり、選択バイアスはより深刻になります。
「N=10,000ルールを試してSharpe 2.0が出ました」という主張は、
- ほぼ同じロジックの亜種なら、実質的にはN=数十程度の試行と同等
- 多様な特徴量・市場・時間軸を網羅した独立試行なら、本当にN=10,000に近い
の両極端があり得ます。PBOやMinBTLを評価する際には、候補プールの多様性も併せて見る必要があります。
なお、今回の実験は AI探索ではなく、人手定義のグリッドサーチ です。MAクロス144候補は短期MA×長期MA×SL×TPの組み合わせなので、互いに高い相関を持つ亜種群です。有効試行回数は144より明らかに小さいでしょう。AI生成ルールに対するPBO挙動と、有効試行回数の実測は、本来比較すべき重要な論点ですが、本記事では扱いません。これも次回の宿題です。
7. この実験でまだ信用してはいけない点
本記事の実験はPBOの挙動を理解するための 教育的検証 であり、特定のMAクロス戦略を売買推奨するものではありません。プロのクオンツ読者向けに、この実験で 織り込めていない要素 を明示的に開示しておきます。
データ・約定面で未考慮の要素
- データベンダー差:USDJPYの60分足はベンダーによってBid/Ask/Mid基準、丸め方、欠損補完が異なる。同じ戦略を別ベンダーのデータで動かすと結果は変動する
- スプレッド変動:今回は往復1.0 pipsの固定コスト。実際のスプレッドは時間帯・市況・ボラティリティで大きく変動し、東京早朝・ロンドンクローズ・ニュース時には数倍に広がる
- 約定滑り:次足始値約定を仮定したが、実際の成行注文では滑りが発生する。MAクロスのような順張り戦略では特に不利な滑りが出やすい
- スワップ・金利差:USDJPYのキャリーは結果に大きく影響する。長期保有戦略では収益の主要因がスワップになることもあり、本実験はこれを完全に無視している
- 祝日・週末処理:今回は週末ギャップを補間せず自然に残したが、ベンダーや約定環境によっては月曜寄りのギャップ約定が発生する
- バー生成時刻:60分足の区切りがUTC基準かサーバー時刻基準かで、シグナルタイミングが変わる
- ATR定義:今回はATR(14)を使用したが、Wilder平滑か単純移動平均かで値が異なる。SL/TP水準の感度はここに依存する
- ポジションサイズ・レバレッジ:今回は単純な単位取引。実運用ではリスクパリティやKelly的サイジングで結果は大きく変わる
- 税金:日本居住者の場合、店頭FX・くりっく365で課税方式が異なり、税引後リターンは実質的に小さくなる
これらは「無視できる誤差」ではなく、Sharpe推定値そのものを動かす要因 です。今回観察されたフルサンプルSharpe 0.57は、これらを織り込めば容易に0近辺まで縮みうる数字です。
検証手法面の制約
- S=8 / 70通りという少ない組み合わせ数:論文推奨はS=16 / 12,870通り。今回のPBO推定の95% Wilson CIは2.2% – 13.8%と広く、5%と14%を区別できない
- 正式CSCVではない:論文の正式手法はlogit分布 $f(\lambda)$ から $\phi = \int_{-\infty}^{0} f(\lambda)d\lambda$ を計算する。今回は「IS最良のOOS順位が下位半分(73〜144位)に落ちた割合」を直接カウントする簡易実装で、論文値とは細部で乖離する可能性がある
- Stochastic dominance未実装:論文の4指標フレームワークのうち、選択プロセスがランダム選択を確率的に支配するかの検証は行っていない
- 単一資産・単一時間軸:USDJPY 60分足のみ。EURUSD、日足、5分足などで再現性は未検証
- 構造的レジーム変化未考慮:2020-2026には COVID ショック、低金利→高金利転換、円安進行などのレジーム変化が含まれる。これらをまたいだCSCVは「異なる市場環境を混ぜている」とも解釈でき、結果の意味づけには注意が必要
- CSCVは時系列の運用プロセスを模倣しない:CSCVの組み合わせによっては、時系列上の後半ブロックがISに入り、前半ブロックがOOSに入ることがある。したがって、CSCVは「将来を予測するバックテスト」ではなく、「多数候補から最良を選ぶプロセスがデータの切り方にどれだけ脆いか」を診断するための事後検査 である。運用投入前には、別途 Walk-Forward Optimization や完全未使用Holdoutが必要
再現性について
実験コード(run_backtest_overfitting_experiment.py)はNumPyベースで決定論的に動作するよう書かれており、同一CSVを入力すれば同一結果が得られる構成です。乱数は使用していません(MAクロス・ATR・コスト計算はすべて確定的)。ただし、CSCV組み合わせ列挙の順序、Pythonバージョン、丸め誤差などで小数点以下の最終桁が変動する可能性はあります。
要するに、本記事の数値は 「論文のPBOフレームワークがUSDJPY実データでどう振る舞うか」を見るための参考値 であって、実運用に耐える検証ではありません。実運用判断には、上記すべてを織り込んだ追加検証が必要です。
8. 重要な禁じ手:PBOを目的関数にしてはいけない

論文Section 5.2で著者らは強い言葉で警告しています。
"When a measure becomes a target, it ceases to be a good measure." (Strathern, 1997)
(ある指標が目標になった瞬間、それは良い指標ではなくなる。)
具体的には次のような使い方を禁じています。
- ❌ PBOが最も低くなる戦略を探索アルゴリズムで選ぶ
- ❌ CSCVをパラメータチューニングの目的関数として組み込む
- ❌ 複数の戦略候補からPBOで足切りした残りで再最適化する
CSCVを最適化対象にした瞬間、CSCV自体に対する過学習が始まるからです。PBOを最小化するパラメータが見つかっても、それは「PBOというテスト」に過学習しているだけで、本物のエッジを意味しません。
CSCVは 戦略選択プロセスの品質を事後評価するツール であり、戦略を選ぶプロセスの 内部 に組み込んではいけません。
AI時代には特にこの罠が深刻です。AIに「PBOが最小になる戦略パラメータを探して」と指示すると、AIは喜んで探します。しかしその出力は、見かけ上PBOが低いだけで、本番では機能しない戦略になります。
ルールは単純です。
CSCVは検査であって、設計ではない。
9. PBOの兄弟:MinBTLとDeflated Sharpe Ratio
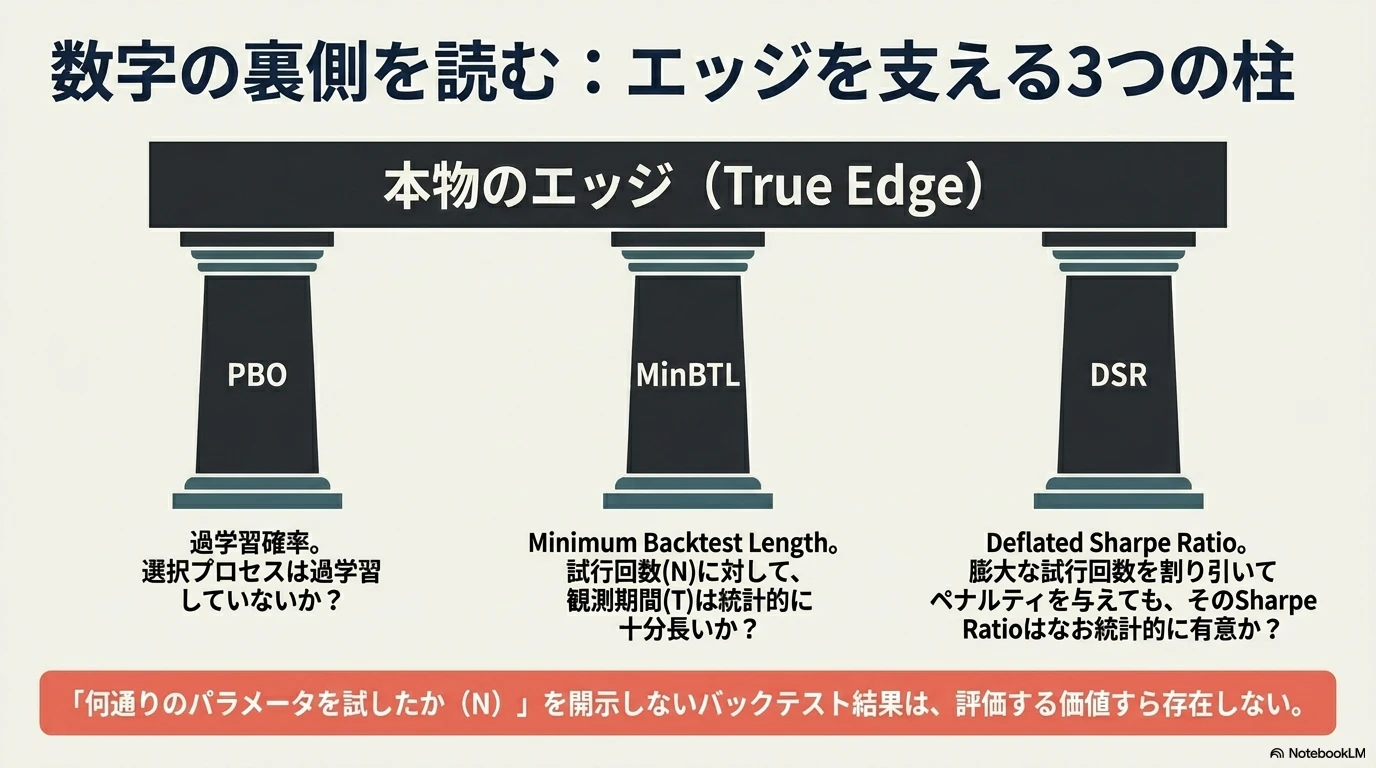
PBOと併せて報告すべき指標として、論文の結論部では MinBTL(Minimum Backtest Length) と DSR(Deflated Sharpe Ratio) が挙げられています。
直感的には次のような考え方です。
- N個の戦略を試したなら、その中の最良Sharpeは「ランダムノイズだけでもこの程度は出てしまう」期待値を超える必要がある
- 試行回数Nが大きいほど、Sharpeが統計的に有意になるために必要な観測期間も長くなる
- 短い期間しか見ていない大量探索の結果は、ほぼ確実にノイズ
実務的には、バックテスト結果を見るとき次の3点をセットで確認する必要があります。
- PBO:選択プロセスが過学習しているか
- MinBTL:観測期間が十分長いか(試行回数Nに対して)
- DSR:試行回数で調整したSharpeが有意か
詳細は López de Prado の関連論文("The Deflated Sharpe Ratio", 2014)を参照してください。
ここでの教訓は単純です。
「Sharpe 2.0」という数字だけを見せられても判断できない。
「何回試した結果のSharpe 2.0か」「何年分のデータか」が揃って初めて議論できる。
10. AI時代のクオンツトレーダーへの示唆
AIを使うことで、次のような作業を効率化できます。
- 売買ルールの候補生成、特徴量の探索
- テクニカル指標の組み合わせ検証、パラメータ最適化
- バックテストの自動化、結果の要約と可視化
これは非常に強力です。しかし、AIによって探索回数が増えるほど、バックテスト過学習の危険性も増えます。
AI時代のクオンツ開発では、次のプロセスが重要になります。
- AIでエッジ候補を生成する
- バックテストで一次検証する
- 取引コスト、スプレッド、スリッページを入れる
- パラメータ周辺の安定性を見る
- Walk-Forward Optimization (WFO) で検証する
- Holdout期間を最後まで触らない
- CSCV的な考え方で過学習リスクを見る(目的関数化しない)
- PBO・performance degradation・loss probability・stochastic dominanceの4点を併せて評価する
- 試行回数Nと観測期間Tの関係(MinBTL)を意識する
- DryRunでリアルタイムに確認する
- 小さな資金で本番投入する
- 成績が劣化したら停止・再評価する
11. 実務で見るべきチェック項目
バックテスト結果を見るときは、最低限以下の点を確認する必要があります。
- 何通りの戦略・パラメータを試したか(試行回数Nの開示は必須)
- 失敗した検証結果も記録しているか(file drawer problem への対策)
- ISとOOSで成績がどれだけ劣化したか(負の傾きが出ていないか)
- OOSで損失になる確率はどれくらいか
- 最適化した戦略は、ランダムに選んだ戦略より本当に優れているか(stochastic dominance)
- パラメータを少し変えても成績が残るか
- 期間・通貨ペア・銘柄を変えても残るか
- スプレッドやスリッページを入れても残るか
- データリーク(将来情報の利用、エントリーと約定価格の時系列ずれ)がないか
特に、クオンツ初心者ほど「最も成績が良かったバックテスト」に目を奪われがちです。しかし実務では、最も良かった結果よりも、なぜその結果が出たのか、どの条件で壊れるのか、どの程度再現性があるのかの方が重要です。
12. 投資家向けに伝えたい本質
投資家にとって重要なのは、華やかなバックテスト成績ではありません。本当に重要なのは、その戦略が将来の不確実性にどれだけ耐えられるかです。
過去データに完璧に合っている戦略ほど、将来には弱い可能性があります。逆に、過去データでほどほどの成績であっても、複数期間、複数条件、複数の検証で安定している戦略の方が、実務上は信頼できることがあります。
良い戦略とは、過去に最も勝った戦略ではなく、未来に壊れにくい戦略である。
AI時代には、見かけ上よいバックテストは簡単に作れるようになります。だからこそ、投資家も開発者も、バックテスト成績そのものではなく、その成績がどのような検証プロセスを通ってきたのかを見る必要があります。
13. まとめ

本記事の論点を整理すると次のとおりです。
- 多数候補から後出しで最良を選ぶプロセスでは、IS Sharpeの高さが選択バイアスの強さを反映している場合がある(負の回帰関係)
- 過学習は二択ではなく確率(PBO)として評価する。PBOは個別戦略ではなく選択プロセスの指標
- PBOはrank-basedな指標、OOS損失確率は経済的指標で、両者は別物。低PBOでも候補プール全体の質が低ければ損失確率は高くなる
- PBOは4つの相補的分析の1つであり、performance degradation、loss probability、stochastic dominanceと併せて見る必要がある
- CSCVは事後検査ツールであって、最適化目的関数にしてはいけない
- 試行回数N・観測期間T・MinBTLをセットで議論しないと数字は意味を持たない。さらに**候補間の相関を考慮した「有効試行回数」**まで踏み込むのが望ましい
今回の簡易実験でも、144候補という控えめな探索で、IS Sharpe 0.75 → OOS Sharpe 0.12(差分 -0.63、slope -0.556)という劣化が観測されました。PBO自体は5.71%(CI上限13.8%、参考値)と低めですが、OOS損失確率は35.71%。「PBOが低い=安全」ではなく、複数の指標を組み合わせて読む必要があります。
良い戦略とは、過去に最も勝った戦略ではなく、未来に壊れにくい戦略である。
バックテストは必要です。しかし、バックテストは証明ではありません。
AI時代のクオンツトレードで重要なのは、良いバックテストを作る力だけではありません。むしろ重要なのは、良すぎるバックテストを疑う力です。
次回への宿題
本記事で扱いきれなかった論点を整理しておきます。
- Stochastic dominanceの実装:選択戦略のOOS分布が、ランダム選択のOOS分布を支配しているかを ECDF とSD1/SD2で確認する
- 正式CSCV(logit分布)の実装:S=16、12,870通りの組み合わせで $\phi = \int_{-\infty}^{0} f(\lambda)d\lambda$ を計算する
- AI生成ルールに対するPBO比較:人手グリッドサーチ vs AI生成特徴量で、PBOおよび4指標がどう変化するかの実証
- 探索回数Nに対するPBO感度:N = 10, 100, 1000, 10000 でPBOがどう悪化するかのスケーリング実験
- MinBTLおよびDSRの自実装:今回のUSDJPYデータで、試行回数Nを織り込んだSharpe有意性を再評価
- 有効試行回数(effective N)の推定:今回の144候補が、相関を考慮すると実質的に何試行に相当するかを推定する。例えば候補間のリターン相関行列の固有値分解から effective N を推定する手法
参考文献
- Bailey, D. H., Borwein, J. M., López de Prado, M., & Zhu, Q. J. (2014). The Probability of Backtest Overfitting. SSRN. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2326253
- Bailey, D. H., & López de Prado, M. (2014). The Deflated Sharpe Ratio: Correcting for Selection Bias, Backtest Overfitting and Non-Normality. Journal of Portfolio Management, 40(5), 94-107.
- López de Prado, M. (2018). Advances in Financial Machine Learning. Wiley.
付録:実験コードとデータ
本実験で使用したPythonコードやデータセット、詳細なグラフにつきましては、下記のGitHubリポジトリよりダウンロードしてご利用ください。(Lab_4の実験)
https://github.com/tikeda123/article_lab
本記事の実験で使用したコード、CSV、図表は以下に整理しています。
-
run_backtest_overfitting_experiment.py: 再現用コード -
candidate_summary.csv: 144戦略候補のフルサンプル評価 -
pbo_results.csv: 70通りのIS/OOS検証結果 -
experiment_summary.xlsx: 結果の統合サマリー
実験図表(実データ)
-
fig1_sharpe_distribution.png: フルサンプルSharpe分布 -
fig2_is_vs_oos_sharpe.png: 選択戦略のIS vs OOS Sharpe散布図 -
fig3_oos_rank_distribution.png: OOS順位分布 -
fig4_simplified_pbo.png: 簡易PBO -
fig5_oos_loss_probability.png: OOS損失確率 -
fig6_best_strategy_equity_curve.png: 最良戦略のエクイティカーブ
概念図(NotebookLM生成)
-
bjp1.png~bjp14.png: 本記事内で使用した概念解説図
Sharpe Ratio 算出仕様
USDJPY 60分足のSharpeは年率換算係数の置き方で印象が変わるため、本実験の算出仕様を明示しておきます。
| 項目 | 仕様 |
|---|---|
| リターン定義 | simple return(価格変化率) |
| 計算単位 | 1バー(60分)あたりのリターン |
| 年率換算係数 | $\sqrt{6048}$(後述) |
| Sharpe公式 | $SR = \mu / \sigma \times \sqrt{6048}$ (無リスク利子率 = 0) |
| ポジション状態 | 単一ポジションのみ。反対シグナルで反転、SL/TP発火後は次バー以降のシグナルで再エントリー可 |
| ノーポジ期間 | リターン = 0 として系列に含める(取引機会のスパースさを反映) |
| 取引コスト控除 | 約定時に往復1.0 pip(= 0.01円)相当の損益を控除 |
| SL/TP判定 | バーのHigh/Lowで判定。同足で両方触れた場合はSL優先 |
| Short約定 | Bidデータのみ使用。Ask-Bidスプレッドは取引コストに内包 |
年率換算係数 $\sqrt{6048}$ の根拠:USDJPYは平日24時間取引、年間営業日約252日、1日24バー = 6,048バー/年。土日・祝日は除外しているため、暦時間ではなく実バー数ベースで換算しています。
この換算は概算であり、実際の取引可能時間(東京・ロンドン・NY市場のクロスオーバー)を厳密に反映したものではありません。ベンダーや市場時間定義によって ±10% 程度の換算係数の差は発生し得ます。