個人 Slack、はじめました。非常に便利です。
python は完全独学初心者なのでツッコミどころがあればご教授いただけると励みになります。
Meaning
スクレイピングってなんだ?クローリング?
50m くらい泳げばいいの?ん??🤔🤔🤔
それはね
クローリングとは、ロボット型検索エンジンにおいて、プログラムがインターネット上のリンクを辿ってWebサイトを巡回し、Webページ上の情報を複製・保存することである。
-
クローリング
- Web上からリンクを辿って目的のWebページやらを取得する
-
スクレイピング
- Webサイトの HTML から目的の情報を抜き出す
要はクローリングして取得したページからスクレイピングして情報を抜き出す、感じでしょうか。🤔
ちなみに自分、25m 泳げません。
Let's すくれいぴーん
それでは実践!
JRの運行情報を取得して遅延してるかどうかをみてみます。
ライブラリ
定番みたいなので BeautifulSoup を使います。
HTML のパースに lxml ってパーサーを使えるみたいなんですがこれが早いとのこと。
ちなみに urllib2 は使いたくない(めんどくさい)ので Requests を使います。
pip install requests
pip install beautifulsoup4
pip install lxml
実装
まず BeautifulSoup で HTML 要素を取得する準備を。
第二引数でパーサーを指定します。
#!/usr/bin/env python3
import requests
from bs4 import BeautifulSoup
import sys
TARGET_URL = "https://trafficinfo.westjr.co.jp/sp/kinki.html"
res = requests.get(TARGET_URL)
soup = BeautifulSoup(res.text, 'lxml')
どういう情報を抜き出してくるかを決めましょう。
Chrome のデベロッパツールで HTML のエレメントをぼーっと眺めてみると...
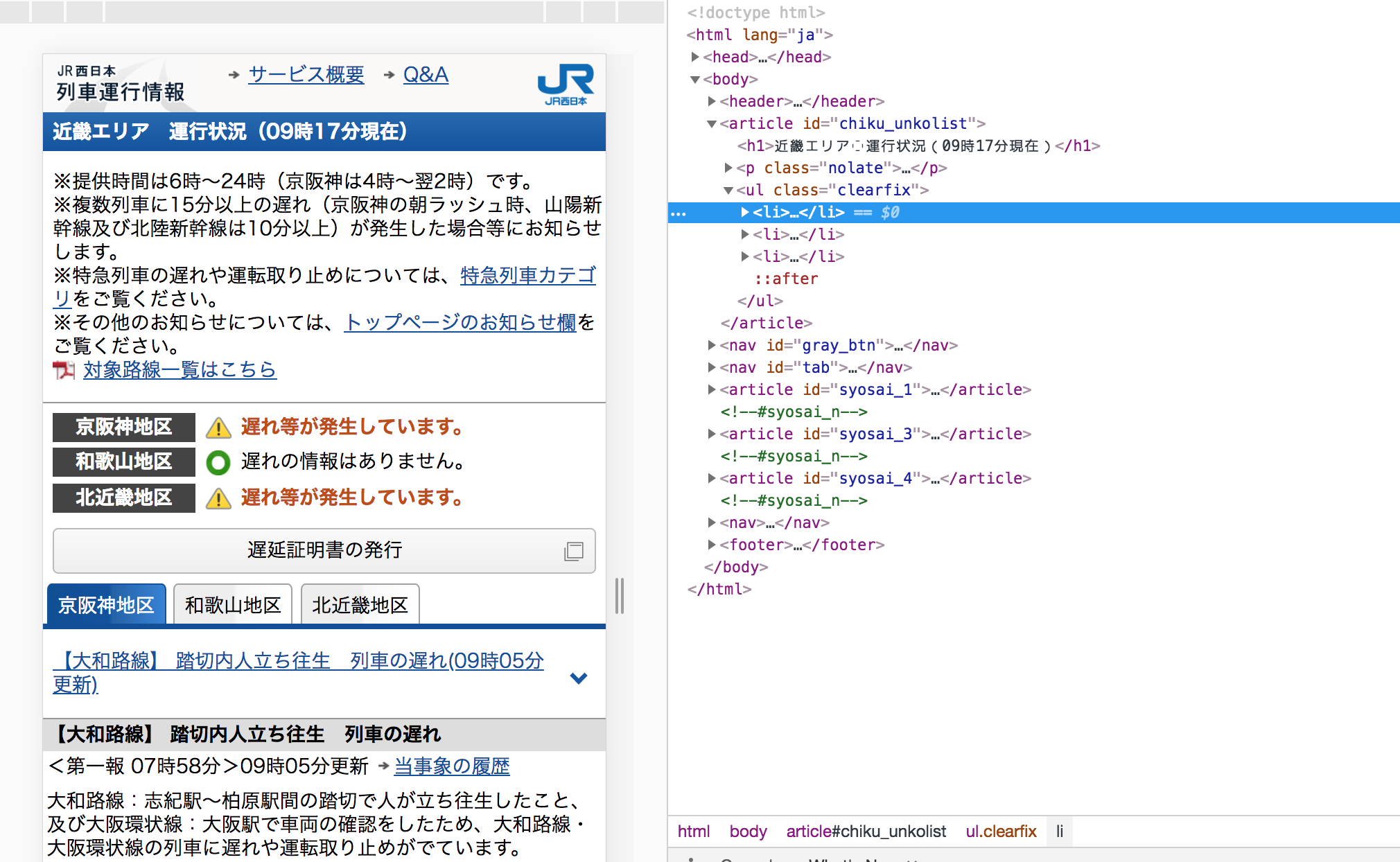
こんな感じ。京阪神地区で遅れてますね😭
ここのメッセージが取得できれば遅延してるかどうか判断できそう!
こういうの見てるとちょっと楽しいですね。げへ。
特定のタグからエレメントをとってみましょうか。
取得方法は soup.find('<tag>') です。
container = soup.find('article', {'id' : 'chiku_unkolist'})
# find は最初に見つかった要素を返す
# リストで欲しい時は select
info_element = container.find('ul', {'class' : 'clearfix'}).find("li")
information = info_element.find('span', {'class':'unko_status'}
if information != "遅れの情報はありません。":
print(information)
お、たのしい。無事メッセージが取得できました。
後はこのメッセージと URL を Slack に通知してみることにします。
Slack への通知方法は Webhook slack とかで検索したらでてきますね。
今回はこちらの記事を参考にさせていただきました。感謝です。
最終的なソースコードはこうなりました。
#!/usr/bin/env python3
import requests
from bs4 import BeautifulSoup
import sys
import slackweb
TARGET_URL_JR = "https://trafficinfo.westjr.co.jp/sp/kinki.html"
SLACK_WEB_URL = "<Webhook URL>"
MESSAGE_DELAY_JUDGE = "遅れの情報はありません。"
def scraiping_jr():
res = requests.get(TARGET_URL_JR)
soup = BeautifulSoup(res.text, 'lxml')
container = soup.find('article', {'id' : 'chiku_unkolist'})
info_element = container.find('ul', {'class' : 'clearfix'}).find("li")
information = info_element.find('span', {'class':'unko_status'}).find(text=True, recursive=False)
if information != MESSAGE_DELAY_JUDGE:
time = parent.find('h1').find(text=True, recursive=False)
# 送信メッセージに時間とURLを含める
l = [time, information, TARGET_URL_JR]
message = "\n".join(l)
slack = slackweb.Slack(SLACK_WEB_URL)
slack.notify(text=message, unfurl_links='true')
if __name__ == '__main__':
scraiping_jr()
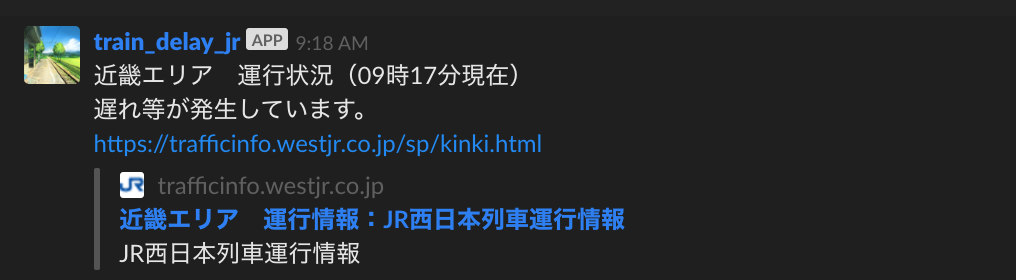
これで遅れてるかどうかがわかりましたね!
これを定期実行して朝の時間に勝手にメッセージ送られてくるようにすれば毎日優雅に朝コーヒーが飲めるんじゃ...!
やってみよう
せっかくなので AWS の EC2 をたてて実行してみます。
EC2 に Python3 の環境を整えます。
pipenv 勢なんですが、正しい Python 環境の整え方教えてください。。。
#!/bin/bash
yes_or_no() {
while true ; do
read -p "$1 [Y/n]?" answer
case $answer in
"" | [yY] | [yY]es | YES )
return 0;;
[nN] | [nN]o | NO )
return 1;;
* ) echo "Please answer yes or no.";;
esac
done
}
# pyenv を github からクローン
sudo yum install git -y
git clone https://github.com/yyuu/pyenv.git ~/.pyenv
echo 'export PATH="$HOME/.pyenv/bin:$PATH"' >> ~/.bash_profile
echo 'eval "$(pyenv init -)"' >> ~/.bash_profile
source ~/.bash_profile
# 依存関係のインストール
sudo yum install gcc gcc-c++ zlib-devel bzip2 bzip2-devel readline readline-devel sqlite sqlite-devel openssl openssl-devel libffi-devel zlib -y
# python をインストール
read -p "install python: " version
pyenv install ${version}
pyenv global ${version}
pyenv rehash
# 正しいバージョンが反映されてたら pipenv の環境も整える
echo ""
python --version
yes_or_no "Is correct this version?"
if [ $? -eq 1 ]; then
exit
fi
pip install pipenv
pipenv --version
あとは cron で定期実行してやれば毎朝遅延してるかどうかがわかりますね!
30 7 * * * python scraiping_train.py
...まてよ、これ EC2 じゃなくて Lambda でできんの?
やってる人がいました。
AWS でやるならこっちの方がやすいですよね。。。
環境構築しなくていいし、無料期間終わったらお金かかるし。
AWS Batch って使ったことないから調べなきゃ。
まとめ
Python の書き方とか問題ないですかね。。。大丈夫。。。?
オレのスクレイピング、こうした方がええのんちゃう?、すてきやん。。。メッセージ、ぜひよろしくお願い致します。
単発1回だけだから通知後に遅延した時とか
遅延が解消された時とか通知しようと思うとどうしたらいいのかな。
これでどんな情報でも抜き出せる!と、思いきや、
サイトによってはスクレイピング禁止となっているものもあります。
サーバに負荷がかかりますからね。株価のサイトとか禁止されてたりします。
用法容量を守ってただしくしこしこしましょう。
Enjoy Lifehack !!
参考
【Python】スクレイピングで電車の運行情報を取得してみた - もなかアイスの試食品
Python3でslackに投稿する - Qiita
python3でwebスクレイピング(Beautiful Soup) - Qiita