この記事はLITALICO Advent Calendar 2024のカレンダー1の21日目の記事です
https://qiita.com/advent-calendar/2024/litalico
株式会社LITALICOでWEBエンジニアをやっている @ti_aiuto です。
普段は主に個人向けのWEBサービスの開発のサポートを担当していて、特にモノリスなアプリケーションを持続可能な形に保つことや、データモデリング・データ分析に関わる諸々の整備に関心があります。
はじめに
自分が所属している基盤グループという組織は、サービスの中長期に渡る安定稼働をミッションとしています。具体的な業務としては、ライブラリやミドルウェアのアップデート、セキュリティやパフォーマンスに関する改善、技術的に難易度の高い施策のリファクタリングや設計開発のサポートといった内容が多いです。
この基盤グループも発足から1年半が経ちそうした課題への対処もある程度目処が立ってきたところで、新たに技術主導での(手段からのアプローチで)プロダクト改善の手立ての提案もしていくことになりました。
そこで、これまで機能としては存在しているがあまりPDCAを回せていなかった、かつ技術的に取れる選択肢が増えてきているということで、レコメンデーションの改善に着手することにしました。
前置き
「レコメンデーション」というとなんだか難しいことをやっていそうなイメージがありますが、この記事では技術的にすごくチャレンジングなことをしているわけではありません。
むしろ「必ずしも技術的に難しいことをしなくても改善の余地がある」「こんな伸びしろがある」という点について紹介していければと思います。
この記事の狙い
次の3点について触れていきます。
- レコメンデーションに関する論点を観点に整理する
- ここ最近で使えるようになった便利な技術(サービス)を紹介する
- 実際に行った施策の一部について概要を紹介する
この記事のゴール
この記事を読むことで次の2つの文の意味が分かるようになるといいなと思って書きました。
- 「よく一緒に読まれるコラム」は、AmazonPersonalizeの活用によりコールドスタート問題が軽減されたことでパフォーマンス向上。さらにEmbeddingのベクトル検索で内容の近い記事も推薦できるように。
- 「あなたにおすすめのコラム」は、内容ベースフィルタリングから簡易的な協調フィルタリングへの切り替えにより大幅改善。
プロダクトの紹介
今回の事例はLITALICO発達ナビという「発達が気になるお子さまの保護者や支援者の方に向けたポータルサイト」での事例です。
「コラム」
会員登録をすると、5000弱の記事を無料で読むことができます。ユーザのアンケート結果を読んでみると、子育ての参考や各種制度に関してなど情報収集のために使うユーザも多いようです。
新規記事の公開は1-3件/日ほどで、ニュースサイトのようなメディアと比較すると少ないほうだと思います。一方で、ガイドラインの改定などのタイミングで必要に応じて過去記事のリライトを行うことで、正確な情報を発信するようにしています。
「知りたい情報」
サイト内ではコラム以外にも様々な機能が実装されていますが、そうした各機能で各ユーザにとって最適な情報を届けるために、地域・立場・年齢・障害といった情報を登録することができます。
技術解説
レコメンデーションについて
レコメンデーションとは
まず、色々なところで引用されている『推薦システム実践入門』という本から次の定義を拝借したいと思います。
推薦システム:複数の候補から価値のあるものを選び出し、意思決定を支援するシステム 1
この「推薦システム(Recommender System)」が提示してくれる内容のことをここでは「レコメンデーション」と呼びます。
現代ではあらゆるサービスのあらゆる場面でレコメンデーションを目にすることが増えていると思います。例えばEC・SNS・音楽や動画のストリーミング・漫画やオーディオブックのサブスク、などなど様々なサービスの利用場面を思い浮かべると、レコメンデーションを提示された経験が思い当たるのではないでしょうか。
今回の施策に関して読んだ別の本では、次のような説明がされていました。
あらゆるものに対してレコメンデーションが算出される時代において、レコメンデーションはユーザ体験のすべてであるといえます。レコメンデーション・エクスペリエンス(RX)は、どのように見え、どのように感じられるべきなのでしょうか。2
「ユーザにとって価値のあるものを見つけ出すシステム」という点では「検索」もかなり近いところがありますが、ここでその違いについても簡単に触れておきたいと思います。
- 検索
- ユーザがシステムに「こういうのがほしい」と能動的に依頼して情報を引き出す
- レコメンデーション
- ユーザがシステムから「こういうのどうよ」と受動的に情報を受取る
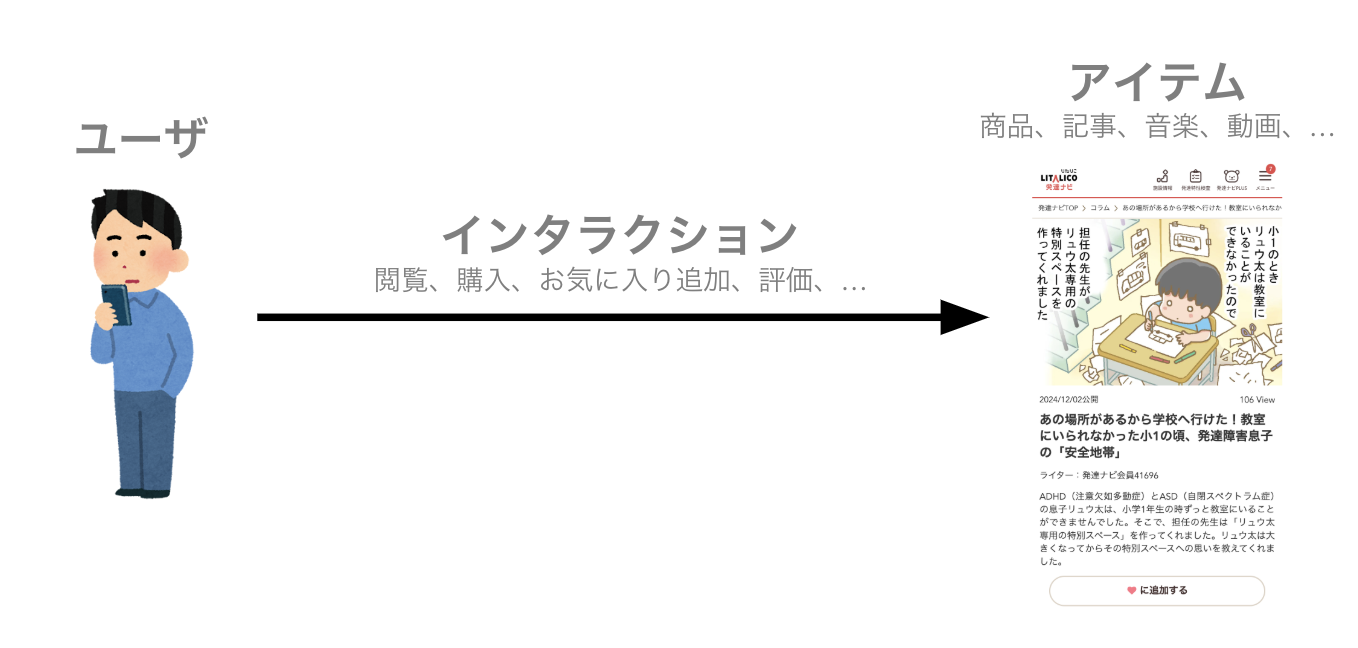
ユーザ・アイテム・インタラクション
今回の記事の中では、
- システムを使う人を「ユーザ」
- ユーザが探して求めているモノを「アイテム」
- 例:商品、記事、音楽、動画
- 「ユーザ」の「アイテム」に対する作用を「インタラクション」
- 例:閲覧、購入、お気に入り追加、評価
として話を進めていきます。
この記事で扱うレコメンデーション
レコメンデーションにも様々な種類がありますが、今回は「アイテム→アイテム」「ユーザ→アイテム」を中心に触れていきます。
- アイテム→アイテム
- あるアイテム1つに対して、関連する他のアイテムをレコメンドします
- 例:「関連アイテム」「この商品を買った人はこんな商品も〜」「あわせて読みたいコラム」
- ユーザ→アイテム
- あるユーザ1人に対して、そのユーザにとっておすすめのアイテムをレコメンドします
- 例:「◯◯さんにおすすめのコラム」
- ※ここでは扱わないけどよくあるやつ
- 概要推薦:「売れ筋ランキング」「運営チームからのおすすめ」のように全ユーザに同じ内容を表示する
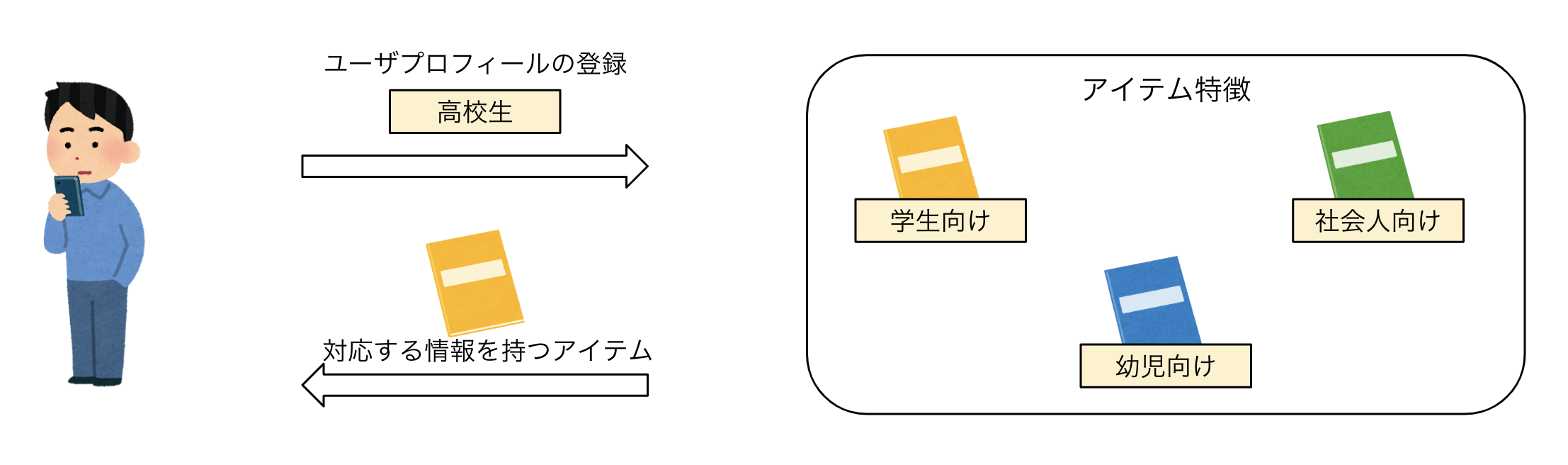
代表的な2つのアプローチ①:内容ベースフィルタリング
プロフィールで「高校生」を選ぶと「学生向け」タグのついたアイテムをレコメンド のように、ユーザやアイテムに紐づくプロフィールや属性情報を照らし合わせてレコメンドします。
本のタイトルや作者、ジャンルなどのようなアイテムの内容を表す情報を利用します。ユーザーがどのようなアイテムを好むかという情報をもとに、内容が似ているアイテムを計算することで推薦を行うアルゴリズムです。 3
代表的な2つのアプローチ②:協調フィルタリング
そのユーザと好みが近いユーザが好んでいるものをレコメンド のように、過去の他のインタラクションの傾向を参考にレコメンドします。
サービス内の他のユーザーの過去の行動などにより得られる好みの傾向を利用することで推薦を行うアルゴリズムです。4

2つの方式の比較と「ハイブリッド法」
先ほどの2つの方式のメリット・デメリットは裏返しの関係にあり、整理すると次のようになります。
| 内容ベースフィルタリング | 協調フィルタリング | |
|---|---|---|
| ドメイン知識が必要 | YES タグやカテゴリなどの属性情報を正しく設定するには、その分野について知識がないといけない |
NO |
| ログが貯まるのを待つ必要 | NO | YES 他のユーザの過去のインタラクションのログを参考にするため、ログがないと何もできない |
ということで、2つの手法を組み合わせた「ハイブリッド法」もあります。
今回ご紹介するAmazon Personalizeのアイテム→アイテムのレコメンドもハイブリッド方式です。
よくある問題
コールドスタート問題
データを使ってレコメンドする以上は、データがないと動きません。先ほどの「協調フィルタリングはログがないと何もできない」もこれに該当します。
サービス内でのユーザやアイテムに関する情報が少ないケース、特に新規ユーザーや新規アイテムについて適切に推薦を行うことが難しいという問題のことです5
ハリー・ポッター問題
「この商品を買った人はこれも買っている」というレコメンドを行うときに、文脈に関係なく特定の人気商品がいたるところで推薦されてしまう問題を「ハリー・ポッター問題」といいます。
とある時期に多くの人がハリーポッターの書籍を他のアイテムと一緒に購入していたので、関連アイテム推薦でどのアイテムに対してもハリーポッターが似たアイテムとして常に推薦されてしまいました6
ドメインやビジネスロジックにもよる
人気か類似か?
人気のアイテムにアクセスが集中しても問題ないのか、人気アイテムそのもののレコメンド表示せずにそれに類似したアイテムを表示するのか、という問題です。
例えばコラム記事や動画であれば(いくらアクセスが集中しても減るわけではないので)人気アイテムに表示が偏っても問題ないですが、飲食店であれば予約枠には限りがあるので、単に人気アイテムを表示するだけでは予約が埋まった後に適切なレコメンドを行うことができなくなってしまいます。
人気か過去の同一アイテムか?
ユーザが過去に利用したアイテムを優先するか、過去の利用状況に関係なく人気アイテムを優先するかという問題です。
例えば旅館宿泊サイトの一休では、「ヘビーユーザーは使い慣れた旅館を好むことが多いため過去に利用したのと同じ旅館をレコメンドしてほしいが、新規ユーザはいろいろな旅館を使ってみたいと考えるため人気の旅館を多めにレコメンドしてほしいことがある」のような例が紹介されていました。本文中ではその傾向もその時々で変化していくとうことも書かれていました。
何をもって「良い」レコメンデーションと考えるか
- 正確さ
- 適合率(表示したうちどれだけ正解か)、再現率(正解のうちどれだけ表示できたか)などがあります
- レコメンデーションのリストの全体でユーザが得られる利得の合計を数値化する方法も色々あるそうです
- カタログカバレッジ
- 「レコメンドできるアイテム全体のうち、どれだけのアイテムをレコメンドできるか」という問題です
- 例えば「人気アイテムTOP 10」のようなアルゴリズムでは、レコメンドできるアイテムが何万点あろうとも、そのうちの10件しかレコメンドできません
- 新規性・多様性・セレンディピティ
- 「ユーザがまだ知らない・これまで利用していたものとちょっと違うけど、好きになるであろうもの」をレコメンドできたほうがいいよね、という話です
- ビジネス上の指標
- ビジネスとして上がってくれないと困る数字を見ます
- 例:会員登録や購入のコンバージョン数や、広告枠のクリック数
- プロダクト観点での指標
- ユーザがそのサービスを便利に使っていたら上がるであろう指標を見ます
- 例:直帰率、滞在時間、スクロール、いいね!への追加、2ページ目以降の閲覧
ここでは扱わないけど重要な話題
- 明示的なフィードバックか暗黙的なフィードバックか
- 明示的:「いいね」やレビューなどのユーザが意図的に評価として入力したデータ
- 暗黙的:PVやクリックなど評価の意図はなく単にサービス利用の中で記録されたデータ
- プライバシー・公平性
- 「そのデータってそんなふうに使っていいの?ユーザの許可は得たの?」という問題です
- 今回の記事ではユーザが明示的に「知りたい情報」として入力したデータを中心に活用することでこの問題を軽減しています
他社の参考事例
今回の話題と特に関係が深い他社事例をご紹介します。
- NewsPicks
- 協調フィルタリングを内容ベースフィルタリングに変更して改善したそうです
- 検証の精度や体制についても課題があったそうです
- 一休
- 先ほどの「人気か過去の同一アイテムか」の点については、最近の傾向ではヘビーユーザも含め自分好みの宿ばかりではなく、「most popularを多く織り混ぜるほうが好まれている」そうです 7
- メルカリ
- 協調フィルタリングとベクトル検索(後述)によりレコメンド枠のタップ率が改善したそうです
またAWSが用意している次の資料も大変参考になりました。他社事例・施策実施における重要な考え方(「打率を上げる」よりも「打席を増やす」)・社内の説得の仕方など様々な観点から整理されています。
AmazonPersonalizeについて
何ができるのか?
一言でいうと、「いい感じのレコメンデーションを生成してくれるフルマネージドサービス」と言って良いと思います。
機械学習を活用するときは通常だと各種コンピューティングリソースの管理であったり各種ソフトウェア・ライブラリの実行環境の管理であったりが必要になってきますが、「フルマネージドサービス」なので、そういった管理は一切不要で、ただAPIを叩いて「ユーザ」「アイテム」「インタラクション」のデータを投入するだけでレコメンデーションを生成してくれます。APIはバッチ処理とリアルタイムの二種類を選べます。
生成するレコメンデーションの種類とアルゴリズムは「レシピ」という選択肢を変えることで切り替えられます。
今回活用した「レシピ」
今回の記事では Similar-Items というレシピを活用した施策をご紹介します。特徴は次のとおりです。
- インタラクションとアイテムの2種類のデータからアイテム→アイテムのレコメンデーションを生成
- 協調フィルタリングと内容ベースフィルタリングのハイブリッド方式
- 人気アイテムと類似アイテムのどちらに寄せるかを選択可能
- インタラクションが無いアイテムでもレコメンデーションを取得できる(コールドスタート問題を回避可能)
ちなみに今回の記事では詳しくは触れませんが、別の施策でUser-Personalization-v2というレシピにより個別のユーザごとに完全にパーソナライズしたユーザ→アイテムのレコメンデーションも行っています。詳細は検証中ですが、こちらも質の高いレコメンデーションができていそうな感触があります。
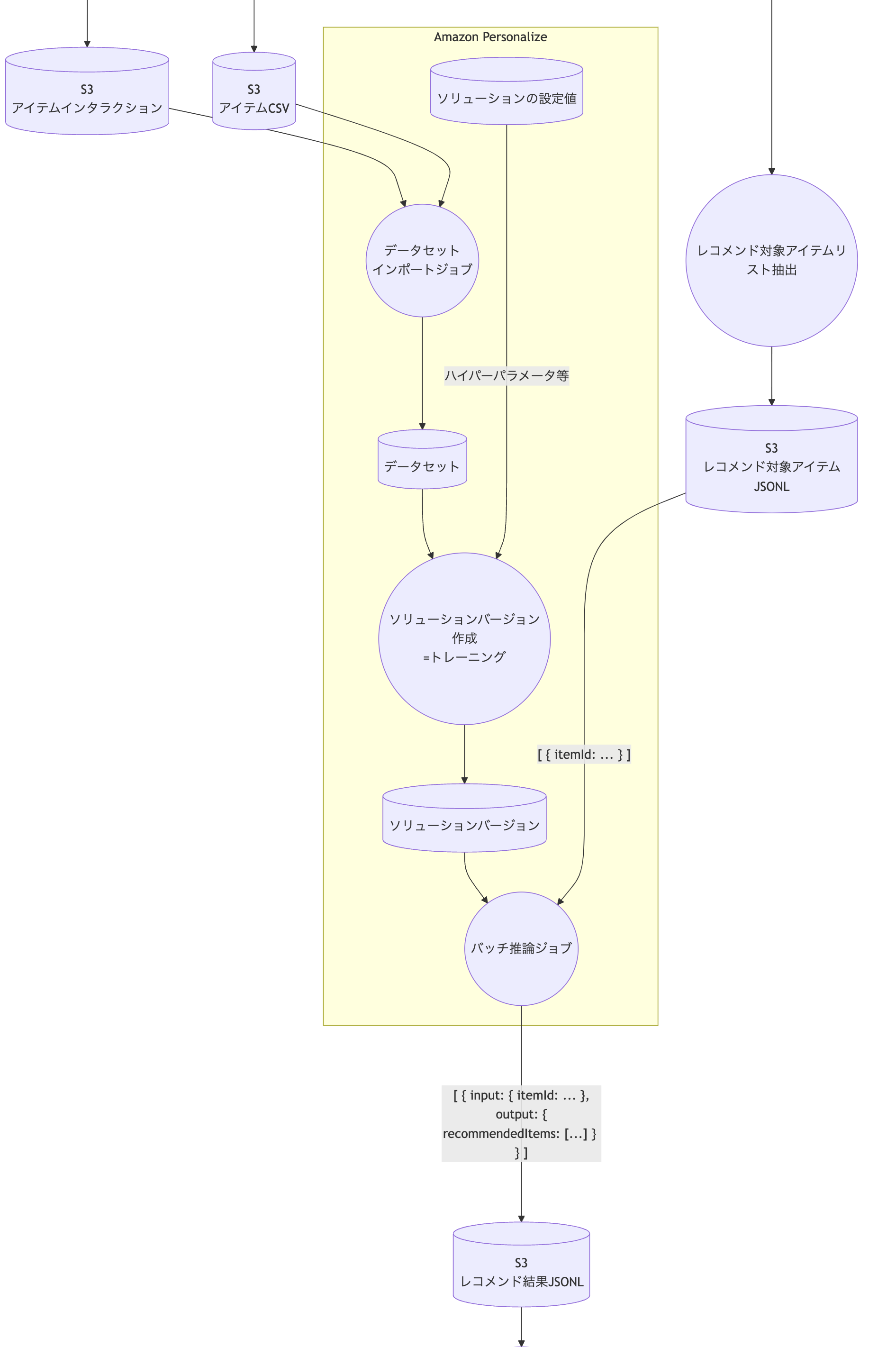
使い方
先ほど「APIを叩くだけで使える」と書きましたが、具体的には主に次の3種類のAPIを使います。
- 「データセット」を作成しておく
- RDBの「テーブル」のような概念です
- 「データセット」にアイテムやインタラクションのデータをインポートする(
create_dataset_import_job)- インポートするデータはS3に配置しておきます
- 「ソリューション」「ソリューションバージョン」を作成する (
create_solution_version)- 使うレシピやハイパーパラメータ(機械学習の設定)を一式の設定が「ソリューション」です
- 特定時点のデータセットの内容を使って学習した一回分のモデルの学習結果が「ソリューションバージョン」です
- レコメンデーションを生成したい対象のアイテムのリストと使いたい「ソリューションバージョン」を選択して「バッチ推論」を実行する(
create_batch_inference_job)- 結果はS3に出力されます
DFDにするとこんな感じです。
Embeddingとベクトル検索について
なぜこの話か?
レコメンデーションの改善の文脈で色々とリサーチをしているうちに、「Embedding(埋め込み表現)を使ったセマンティック検索」というのがElasticsearchやOpenSearchの活用法の中で話題になっていることがわかりました。
セマンティック検索とは語句の意味を解釈する検索エンジン技術のことです。セマンティック検索の結果は、クエリの単語に文字通り一致する内容ではなく、クエリの意味に一致する内容を返します。
文の意味や文脈を考慮して文章を検索する技術というのは、コラム記事やUGCコンテンツのレコメンデーションでも活用できると思ったため、この方向性でも使える手段を検討していくことにしました。
Embedding(埋め込み表現)とは
すごく雑に言うと「文章の意味・文脈の近さが距離の大小として現れるとても便利な性質を持ったベクトル」ということになると思います。
主に単語や文章(テキスト)、画像、音声などの複雑なデータを、AI/機械学習/言語モデルが処理しやすい数値ベクトル表現に変換する技術である
... 単語の使用文脈や周囲の単語との関係を考慮してベクトルを生成します。これにより、同一単語でも文脈に応じて異なるベクトルを持つことができます。
意味的に類似した単語や文はベクトル空間内で互いに近い位置にマッピングされ、テキストの深い意味的な分析を可能にします。
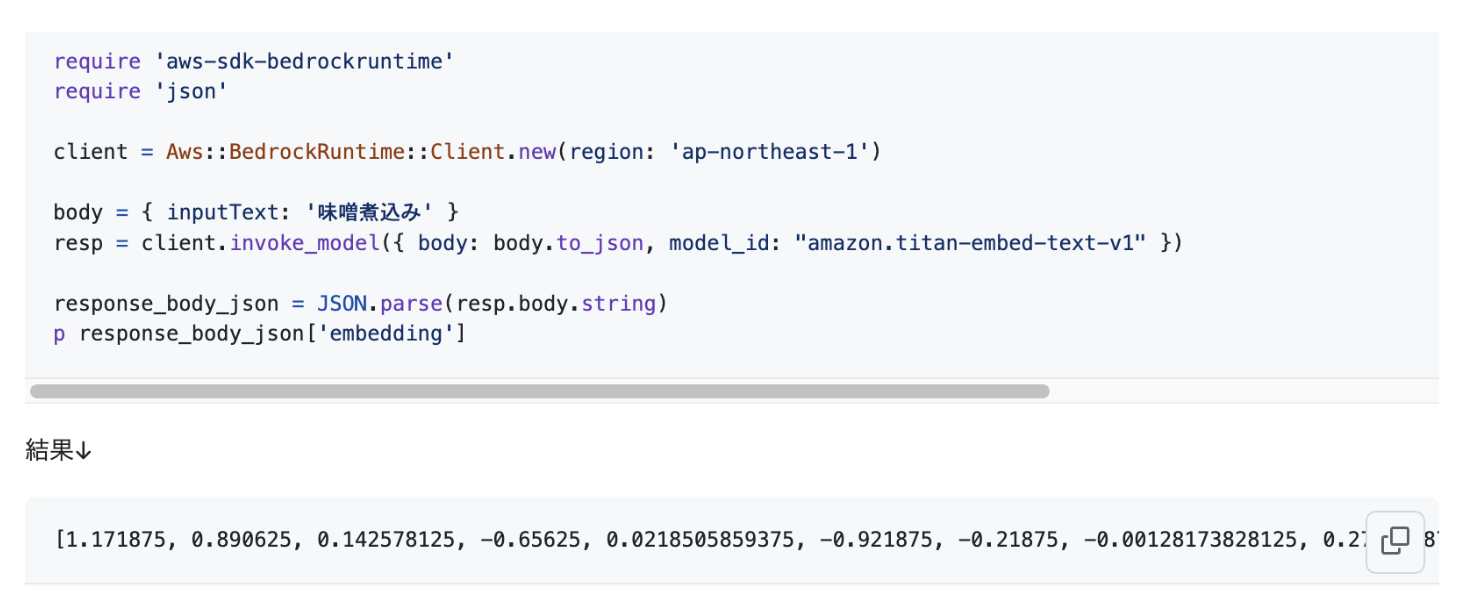
例えばあるコラム記事のコンテンツからEmbeddingを生成すると次のようなベクトル(ここでは配列)になります。
Embeddingはどうしたら手に入る?
一言でいうと「何かしらの言語モデルを準備して、そこに文章を入力して生成する」ことで手に入ります。同じ言語モデルを使って生成したEmbedding同士は比較可能です。ベクトルの次元数も使う言語モデルによって変わります。
今回はAmazon BedrockのAmazon Titan Text Embeddingというモデルを活用しました。AWSのSDKを活用することで次のような数行のコードで取得できます。
BigQueryのベクトル検索サポートがpre-GAに!
先ほどEmbeddingは「内容が近い文章は距離が近いという便利な性質を持ったベクトル」というような説明をした通り、ベクトル同士の類似度を計算することで文章の近さを測ることができます。
普段からデータ分析にはBigQueryを活用しているのですが、なんと今年の2月からBigQueryでベクトル検索の機能がpre-GAとなりました。これにより、BigQueryにベクトルのデータを投入しておけば、あとは普段通りにクエリを書くだけで簡単にベクトル同士の類似度を計算することができます。
ドキュメント内のコード例にもありますが、①ベクトルの取得方法、②距離の比較方法(コサイン類似度・ユークリッド距離・内積)を指定するだけで簡単に使えます。

ベクトル検索による類似文書検索の例
以下が実際にEmbeddingとベクトル検索により類似文書を検索した例です。一番上の記事の記事に対して、距離の近い順にソートすることで、似たような内容の記事が取得できていることがわかります。(これがタグ付けや複雑な自然言語処理を一切せずに実現できるというのですから驚きです)

施策概要
全体の流れ
- 企画
- どの機能について、どんな方法で、何を目指して改善するのか?を決めます
- 今回は「よく一緒に読まれるコラム」「あなたにおすすめのコラム」をはじめとしたいくつかの機能を対象にしました
- PdMとの相談
- 事業影響などの懸念事項の確認や、他の施策とのダブりやコンフリクト防止のためPdMとすり合わせをしました
- 今回は事前告知さえすれば適宜本番環境でのABテスト等の反映をしても良いことになりました(裁量をもって進めさせていただけたのは大感謝です)
- ABテストの体制の整備
- 既存のアルゴリズムと比較して何がどれだけ上がった・下がったを計測できる体制を準備しました
- 施策の効果検証に必要なABテストの仕組み・ログ基盤・データ分析基盤はもともと整備してあったので大掛かりなことはしていません
- 特に「どのアルゴリズムで」「リストの何番目が」を記録するなど、レコメンデーション改善の文脈で必要なデータを記録したり、モニタリングに必要なダッシュボードの準備を行ったりしました
- 各パターンの検証
- 学習データ・学習時のパラメータ・学習結果の活用方法などを変えて様々な条件でABテストを実施していきます
- 振り返り
- 改善した箇所について「なぜ改善したのか?」「再現性を持って他の機能に展開するにはどうしたらいいか?」を考察します
- 横展開・自動化などなど
- うまくいった施策は他の機能にも同様に展開(これを「横展開」と読んでいます)します
- 手作業でデータ投入を行っていた箇所については自動でレコメンデーションを取得できる仕組みを作ります
そもそもレコメンドの内容って大事なの?
この記事は「レコメンデーションのアルゴリズムを改善しよう」という話なのですが、場合によってはそんなに凝ったアルゴリズムを頑張って実装しなくても、人気ランキングなどのシンプルな手法でユーザにとって十分便利な内容が提示できるという可能性もあります。
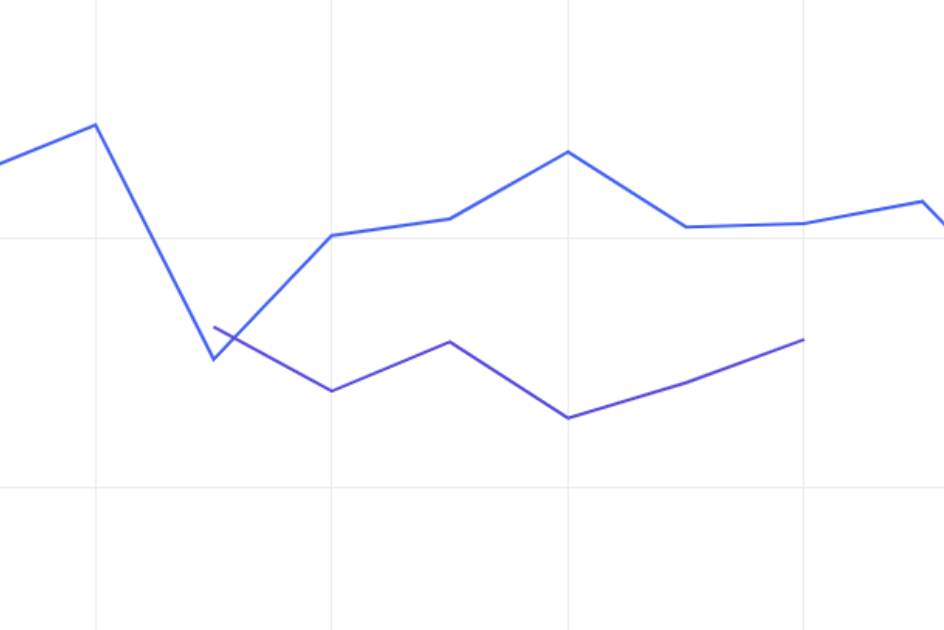
ということで、まず「よく一緒に読まれているコラム」の領域について、 旧アルゴリズム (青線) vs. 人気ランキング (紫線) で検証してみました。
見ての通り、紫線が青線を下回っています。(統計的検定でも有意に悪化していました。)
最初にこの検証を行ったことで、「ユーザはちゃんとレコメンド枠の表示内容を見ている」「レコメンデーションの精度を高めればそれがちゃんとユーザに届く」という自信を持って後の検証を進められました。
「よく一緒に読まれているコラム」の施策の概要

変更前
BigQuery上で共起UUを使った簡易的な協調フィルタリングを実装していました。詳細は割愛しますが、絞り込み条件が厳しく設定されていたため、ログが揃っている一部の記事でしかレコメンデーションが生成できない問題(コールドスタート問題)が発生していました。
変更後
AmazonPersonalizeのSimilar-Itemsレシピを異なるデータで学習した2パターンと、Embeddingによる類似記事検索の計3パターンを組み合わせたアルゴリズムに変更しました。
この判断の意図としては、
- 今回対象としているサービスの使われ方として、調べ物・情報収集に使うことも多いことを考えると、「同じような話題の記事をいくつか読み比べてみる」場面での使いやすさも重要なはず
- 「他のユーザから評価が高い内容のレコメンド」に関しても、複数の文脈におけるログを組み合わせることで、できるだけ多面的なレコメンデーションが提示できるようにしたい
ということがあります。
効果
試行錯誤の末に、次のような結果にたどり着くことができました。
- レコメンデーションの提示回数の劇的改善
- 「変更前」で説明したコールドスタート問題が解消されたことにより、「そもそもレコメンデーションが提示できない」ケースを激減させることができました
- クリック率の改善
- 3パターンのいずれにおいても、クリック率は変更前よりも有意に増加しました
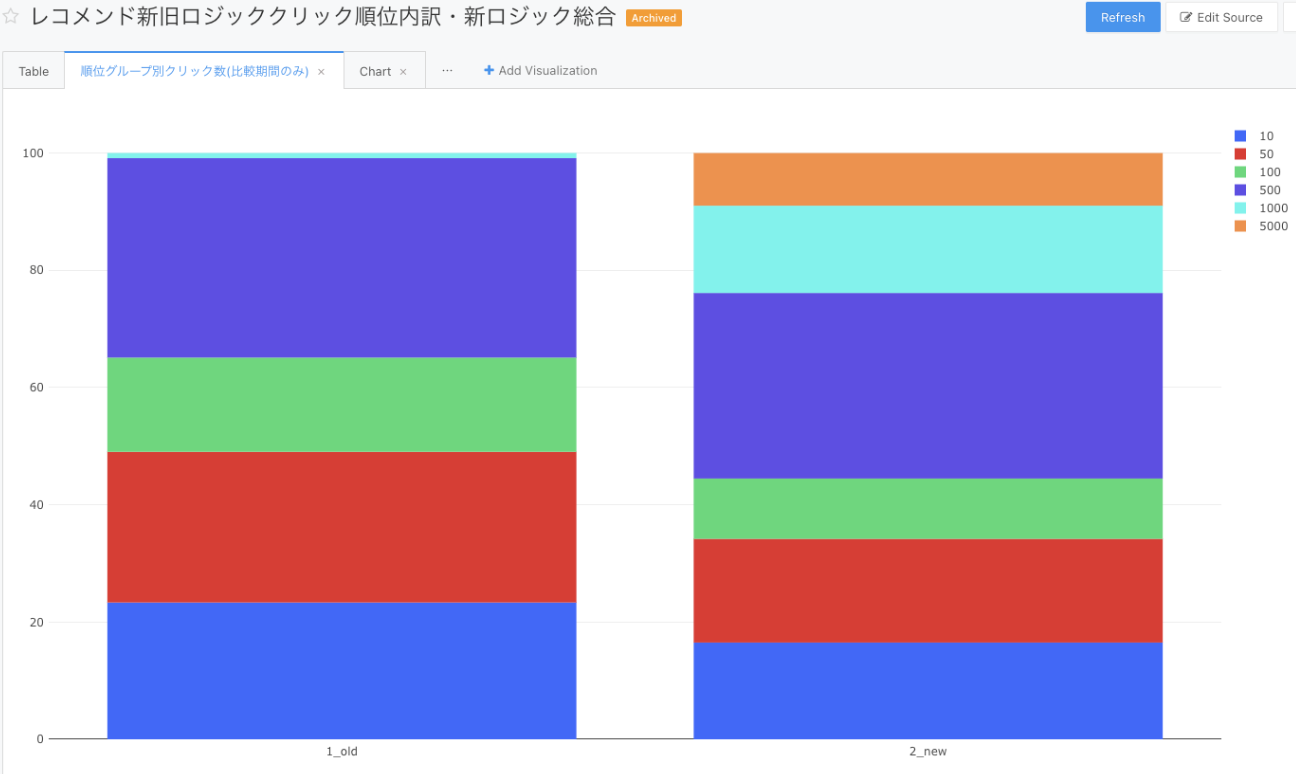
- 遷移先記事のバリエーションの改善
- レコメンド枠からユーザが実際に遷移した記事の特徴を調べると、比較期間において、変更前では490記事しかクリックされていなかったのが、変更後は1719記事がクリックされるようになりました
- 単に「多面的なレコメンデーション」ではなく、「多面的かつ実際にユーザが必要としているレコメンデーション」ができるようになったと捉えて良いと思います
変更後(右側)において、水色(500-1000位)・オレンジ色(1000-5000位)の領域が大きく増えていることが分かります。
「あなたにおすすめのコラム」の施策の概要

変更前
ユーザが「知りたい情報」で選択した内容をもとに、対応するタグが付いている記事を検索して表示するという典型的な内容ベースフィルタリングで実装していました。
変更後
「ユーザが知りたい情報で設定したプロフィールを参考にユーザをグループ化して、近いグループの評価を参考にレコメンデーションを提示する」という簡易的な協調フィルタリングの手法に変更しました。
「類似のユーザを見つける」の点については、機械学習によるクラスタリングのような手法を使うこともできますが、今回対象としているサービスは「知りたい情報」の選択内容によって必要としている情報が大きく異なると推測されたことと、実際にログを分析した結果もその通りの傾向となっていたため、ドメイン知識を活用したグループ化が適切だと考えました。
効果
- ログイン・未ログインのいずれの場合においても、クリック率が大幅に向上しました
(大幅向上のイメージ)
他の観点での効果検証(何が改善していれば「改善」なのか?)
もちろんクリックさえ増えれば何でも良いわけではなく、当然その結果としてユーザにとっても事業にとってもプロダクトが良い方向に進化していることが重要です。
プロダクト観点
ユーザにとって必要な情報を届けていくという点で、次のような点でも効果検証を行いました。
- 遷移後のスクロール率
- 記事の下のほうまでスクロールした割合は有意に増加しました
- 2ページ以上ある記事の2ページ目以降の閲覧
- 2ページ目以降を開いたユーザの割合は有意に増加しました(つまり1ページ目だけ読んで離脱してしまうケースが減少しました)
よって、「クリックしたけど実は読みたい記事じゃなかった」というケースが減少していることが分かりました。クリック数が増えた分ある程度の悪化も想定していましたが、逆に改善していたのでこれは嬉しい結果でした。
事業観点
レコメンド枠のクリック後の会員登録率は低下しませんでした。つまり今回の施策により、クリック率が上がった分、レコメンド枠経由の会員登録数が増加しました。
Amazon PersonalizeのSimilar-Itemsの使いどころ
今回初めてAmazon PersonalizeのSimilar-Itemsレシピを活用してみてわかったことをご紹介します。
- 簡単な手順でレコメンデーションを生成できるのは何と言っても便利
- レコメンデーションが何も提示できないケースの対策を考慮しなくていいのも含めて楽
- 「人気」←→「類似」のどちらに寄せるかを選べるとはいっても、いずれにしても「人気」アイテムが結構な割合で入ってくる
- BigQueryで人気アイテムを優先したアルゴリズムを再現してみると、「人気」に寄せた場合は約6割が、「類似」に寄せた場合は約4割が一致しました
- 体感だと、「人気が大半・類似が多少・残りは誤差」のような結果が返っているように思います
- 利用料金がかっちり決まらないのはちょっと扱いづらい
- 学習にかかった時間で課金されるのですが、「このデータ量だとこれくらいの時間がかかる傾向だな」のような概算でしかコストがわからないのは不便といえば不便です
- どんなときに使うべきか?
- 「人気」に寄せたい・かつコールドスタート問題が起きにくい場合は、必ずしも使わなくても同じようなパフォーマンスが出せるかもしれません
- BigQueryで共起UUを使ってアイテムごとに人気アイテムを算出するなど
- とはいえものすごくデータ量が多いとかでなければ利用料金もそんなにかからないですし、使い方もシンプルなのでとりあえず検討してみるのも良いかもしれません
- 「人気」に寄せたい・かつコールドスタート問題が起きにくい場合は、必ずしも使わなくても同じようなパフォーマンスが出せるかもしれません
全体を通した振り返り
今回のいくつかの施策を通して得られた学びをご紹介します。
- 人気なものは人気である
- 身も蓋もないですが、多くのユーザがアクセスしている記事は、ただそれだけの理由でレコメンドする意味があるのだなと改めて分かりました
- ドメイン知識は使えるに越したことはない
- これも言うまでもないといえばそれはそうなのですが、どうしたらユーザにとって必要なものを提示できるか?の仮説を立てていく上で、ユーザがどのような理由や背景で・どんなときに・どのようにプロダクトを使うのか?の知識は極めて重要です
- プロダクトにとって何が重要か?の視点は欠かせない
- 先ほどの「何をもって改善と考えるか」の話とつながりますが、どんな数値が上がればユーザにとって・事業にとって改善だと言えるのか?も考えておく必要があります
- もっともこれはレコメンデーションに限らず普段から適切なモニタリング指標を考えておくべきことでもあります
- 複雑なことをしないと改善できないわけじゃない
- 今回はAmazon Personalize, BigQueryでのSQL、BigQueryでのベクトル検索という技術的にはフルマネージドサービスだけを使ったシンプルな方法ではありますが、それだけでも様々な手を打つことができると分かりました。
最後に
ゴールを改めて
次の2つの文の意味が分かるようになったでしょうか。
- 「よく一緒に読まれるコラム」は、AmazonPersonalizeの活用によりコールドスタート問題が軽減されたことでパフォーマンス向上。さらにEmbeddingのベクトル検索で内容の近い記事も推薦できるように。
- 「あなたにおすすめのコラム」は、内容ベースフィルタリングから簡易的な協調フィルタリングへの切り替えにより大幅改善。
今後に向けて
今回の「第一歩」を通して最も実感したのは、「複雑なことをしなくても改善できる余地はたくさんある」ということです。
特に、
- 新規記事の増加ペースが緩やか
- 過去記事のアクセスが多く過去記事もアップデートされている
- ログがたくさんある
- どの機能もテキストベースのコンテンツが多く類似コンテンツの検索が容易
といった点も踏まえると、個別のユーザに向けたパーソナライズも含め、色々と工夫できる点がありそうです。
また、既存の機能横断の検索機能や機能横断の動線のあるべき姿も含めて、各機能がどのように連携すればユーザがサービス全体を最大限有効活用できるか?という広い視点での設計も、より深く考えていく必要があると思いました。
参考文献
次回予告
次回は @harukanoda さんが担当します。お楽しみに!
この記事の他に2つ記事を書いています。よかったらご覧ください!