去年の夏頃から株式会社LITALICOでエンジニアをやっています。@ti_aiutoです。
この記事は「LITALICO Engineers Advent Calendar 2019」の18日目の記事です。
LITALICO Engineers Advent Calendar 2019 - Qiita
https://qiita.com/advent-calendar/2019/litalico
はじめに
背景
先月から、最近リリースされたサービスのグロースに携わっています。これまでグロースハックというのにほとんど触れたことがなく、ひとまずここ数週間は、お勧めされた関連書籍を読み漁ったり、先輩方に色々聞いて回ったりしていました。
何をするにしても、まずはサービスの現状把握が必要ということで、手元にあるアクセスログを使って(SQLの練習も兼ねて)簡単なデータの分析基盤を作ってみることにしました。
ほしい結果が手に入ったところで、Qiitaの記事が意外となさそうだったので、記事を書くことにしました。
記事がないのはふつう直書きのSQLでそんなことしないからなのかもしれませんが、ちょっとしたエクササイズにはなると思います。興味のある方はお付き合いください。
やりたいこと
見てみるといいよと言われた指標、本に書いてあった指標、個人的に気になる指標を合わせて、次の数値を計算します。
- 直近のX日以内に連続で利用しているユーザ数(
FQX)、今回はFQ5を計算 - アクティブユーザ数(
DAU,WAU,MAU) - 再訪間隔(いい感じの頭字語がわからなかったので Days Between Repeat/Revisit/Return の略で
DBRにしておきます。通称あったらぜひご教示ください。) - セッションごとのページ訪問数の統計(平均値、標準偏差、中央値を計算します)
今回のチャレンジ?のポイントになるのが、これらの値を日次で取得したいという点です。
こういう結果を出力します。

分析関数について
今回のクエリを書くにあたって、分析関数が多いに役立ちました。ちゃんと調べて使ったのは初めてです。
標準 SQL での分析関数の概要 | BigQuery | Google Cloud
https://cloud.google.com/bigquery/docs/reference/standard-sql/analytic-function-concepts?hl=ja
データベースでは、分析関数は行のグループ全体に対して集計値を計算する関数です。行のグループに対して単一の集計値を返す集計関数とは異なり、分析関数は入力行のグループに対して分析関数を計算することで、行ごとに単一の値を返します。
上の説明を図にすると次のようになると思います。
集計関数の場合
ユーザ名ごとのグループを作り、できたグループごとに関数を適用して、グループごとに結果を返します。

分析関数の場合
各行について、その行のユーザ名と同じユーザ名のグループを作り、 できた各行のグループごとに関数を適用して、行ごとに結果を返します。

これの何が嬉しいのかという話ですが、行ごとにグループを作ることで、その行とそのグループの関係(値がグループ内でどんな立ち位置か)から、値を計算することができます。ふつうの集計関数がf(グループ)だとすると、f(グループ, 行)みたいな感じです。
例えば、そのグループ内で、その行の前の値をLAG関数、後の値を取得するLEAD関数や、その行がグループ内で何番目かを計算するRANK関数があります。「その行と2行前後の行の値の中で最大値を計算する」みたいな書き方もできます。
例えばLAG関数を使うと次のような動作になります。
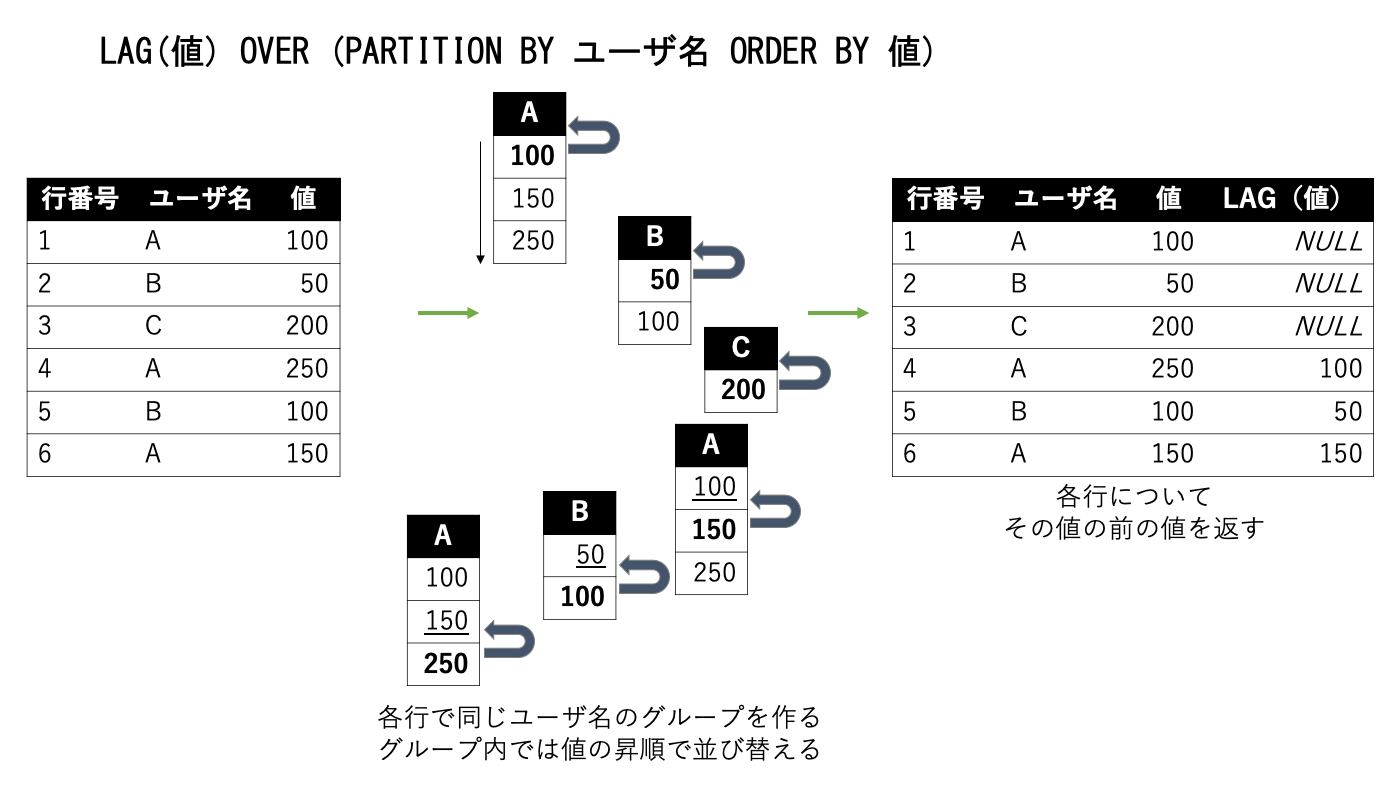
ちなみにこのLAG関数は一つ前の値を取得する関数ですが、LAG(値, n)のように指定すると、nつ前の値を取得することができます。該当がなければNULLとなります。
詳細な解説は↓の記事が読みやすかったので貼っておきます。連載の他の記事もよかったです。
連載:SQLのウィンドウ関数を利用した分析―セッションを利用したアクセスログの分析 | ブログ一覧 | DATUM STUDIO株式会社
https://datumstudio.jp/blog/%e3%82%bb%e3%83%83%e3%82%b7%e3%83%a7%e3%83%b3%e3%82%92%e5%88%a9%e7%94%a8%e3%81%97%e3%81%9f%e3%82%a2%e3%82%af%e3%82%bb%e3%82%b9%e3%83%ad%e3%82%b0%e3%81%ae%e5%88%86%e6%9e%90
下準備
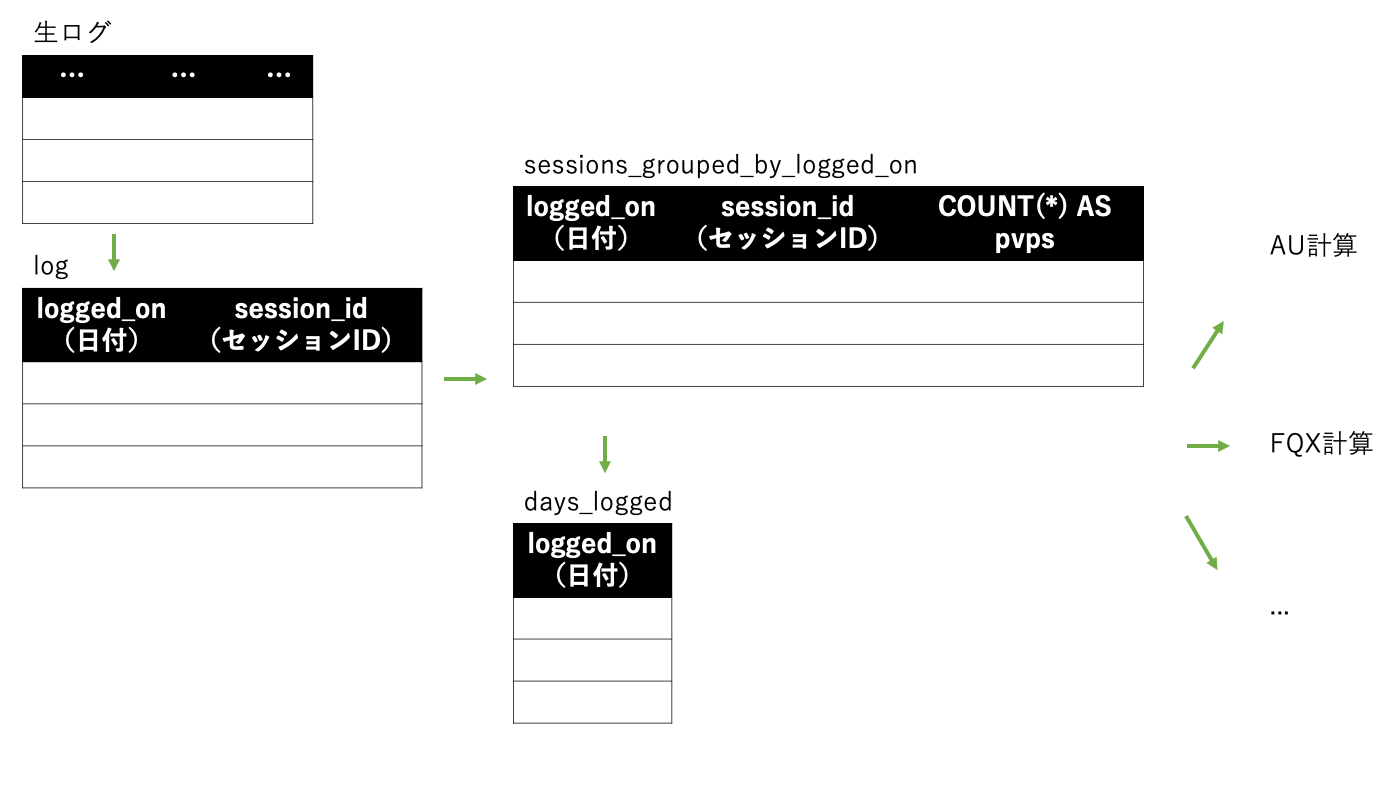
まず、生ログから離れてクエリを定義できるように、logというクエリを一枚間にはさみます。これは一回一回のアクセスを表します。
次に、日付とセッション(ユーザ)ごとのアクセス数を集計しておきます。この結果はsessions_grouped_by_logged_onという名前にします。pvpsはPage Views Per Sessionの略です。
また、ログに含まれる全ての日付を抽出した結果をdays_loggedという名前にしておきます。
これらの結果から、FQXやAUなどの各指標を計算していきます。
WITH
log AS ( -- 入力の定義とフォーマットの整形
SELECT
DATE(...) AS logged_on,
... AS session_id
FROM
...
),
sessions_grouped_by_logged_on AS ( -- まず日ごとに集計する
SELECT
logged_on,
COUNT(*) AS pvps,
session_id
FROM
log
GROUP BY
logged_on,
session_id ),
days_logged AS ( -- 集計対象の日付のリストを抽出しておく
SELECT
DISTINCT logged_on
FROM
sessions_grouped_by_logged_on ),
サブクエリのネストだらけになるのは嫌なので、WITH ... ASを活用していきます。
標準 SQL クエリ構文 | BigQuery | Google Cloud
https://cloud.google.com/bigquery/docs/reference/standard-sql/query-syntax?hl=ja#with-clause
FQXを計算する
まずはアクティブユーザなんじゃないかという話かもしれませんが、分析関数の話を忘れないうちにFQXを計算しようと思います。
FQXは「X日連続して利用していること」を表します。これを言い換えると、「日単位で考えたときに、あるセッションの利用の、その前の利用が前日であり、2つ前の利用が前々日であり、3つ前の利用が3日前であり、…(X-1)つ前の利用が(X-1)日前であること」と考えることができます。もし利用が途絶えていたら、1つ前の利用が2日前になっていたり3日前になったりして、行がずれる、すなわち遡った行数と日数の差が一致しなくなります。

関数に書き換えやすいように書くと、「ある行について、その行と同じセッションIDの全ての行から利用日を抽出したグループ(利用日順)を作って、その行の(X-1)つ前の利用日を取得して、日数の差を計算して、結果が(X-1)かどうか」を調べれば実現できます。
その行の値の(X-1)つ前の値はLAG(利用日, X-1)で、日数の差はDATE_DIFF(date1, date2, DAY)で求めることができます。なおDATE_DIFFは第一引数のほうが大きいと正の値になります。また引数にNULLが含まれていた場合はNULLが返ります。
ということで、DATE_DIFF(利用日, LAG(利用, 4) OVER (PARTITION BY セッションID ORDER BY 利用日), DAY) = 4がTRUEになる行が、連続で5日間利用している、つまりFQ5に該当するユーザです。
最後に、上の結果がTRUEになっている行数を日付ごとに集計します。
再訪間隔(日にち単位)を計算する
再訪間隔は、今回の利用と前回の利用の間が何日空いているかを計算すればいいので、FQXと同様の考え方で、「ある日のあるユーザの、その1つ前の利用日と、その日との日数の差」を計算すれば求まります。
関数に書き換えやすいように書くと、「ある行について、その行と同じセッションIDの全ての行から利用日を抽出したグループを作って、利用日順に並び替えて、その行の1つ前の利用日との日数の差を計算する」です。
ということで、DATE_DIFF(利用日, LAG(利用日) OVER (PARTITION BY セッションID ORDER BY 利用日), DAY)が再訪間隔(日数単位)になります。
FQXと再訪間隔は似たような処理なので、一つのクエリにまとめてしまうことにしました。
sessions_dbr_and_fq AS ( -- セッションごとの再訪間隔・連続再訪の判定
SELECT
*,
DATE_DIFF(logged_on, LAG(logged_on) OVER (PARTITION BY session_id ORDER BY logged_on), DAY) AS dbr,
DATE_DIFF(logged_on, LAG(logged_on, 4) OVER (PARTITION BY session_id ORDER BY logged_on), DAY) = 4 AS fq5
FROM
sessions_grouped_by_logged_on ),
fqx AS ( -- 連続再訪の集計結果
SELECT
logged_on,
COUNT(fq5 = TRUE
OR NULL) AS fq5_count
FROM
sessions_repeat_and_fq
GROUP BY
logged_on),
ここに行を追加していけば、FQ3やFQ7, FQ14などそれぞれ計算できます。
AU(WAU, MAU)を計算する
まずやってみる
AU(アクティブユーザ数)は、「一定期間内に一度でも利用があったユーザ数」として計算します。
計算の周期が決まっていれば、SELECT 日付を各周期の初日に切り落とした結果 AS day, COUNT(DISTINCT セッションID) GROUP BY dayのように計算することができます。(&通常はこれで充分かもしれません。)
しかし、今回はログの各日付を基準として日次でWAU, MAUを計算したいので、↑の方法は使えません。
まず思いついた方法が次のようなものです。
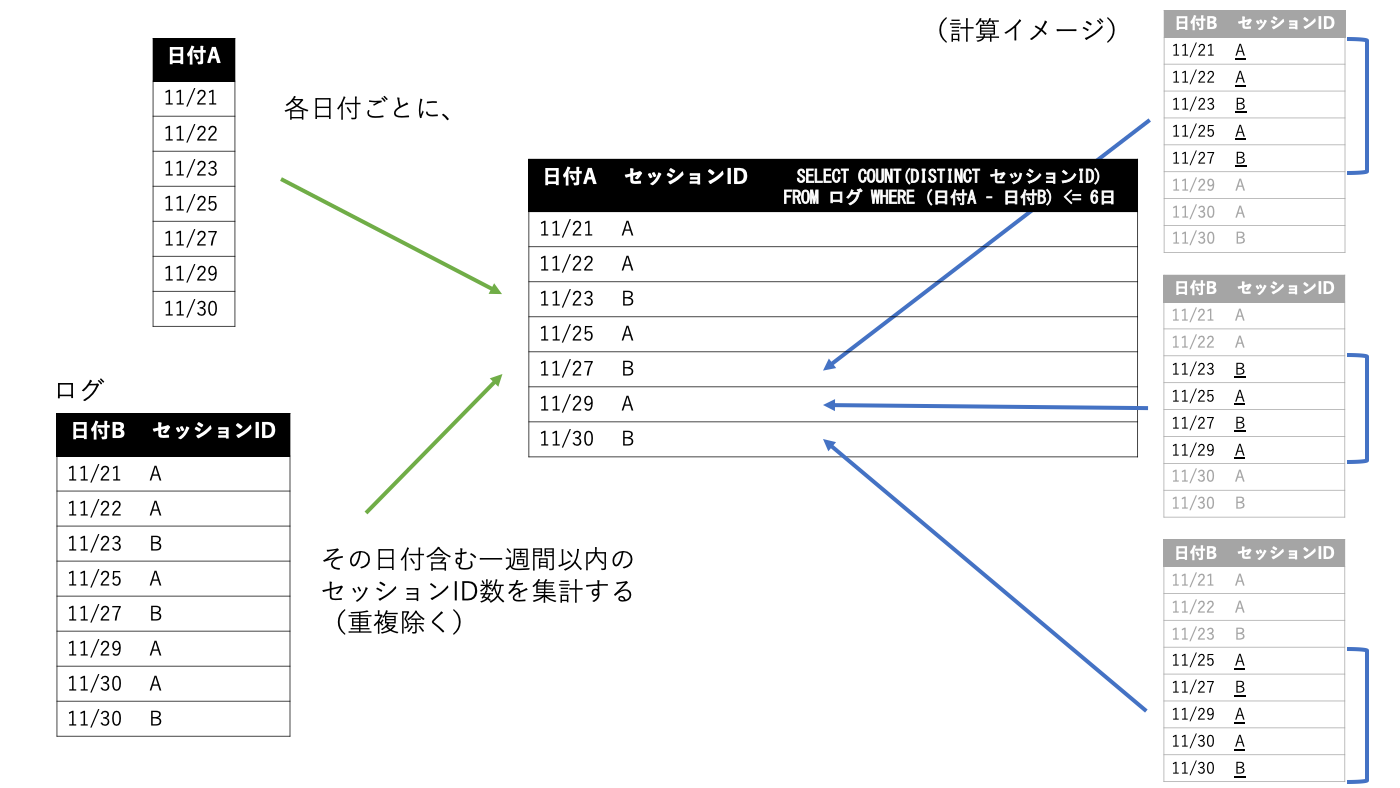
日付テーブルdays_loggedの各行について、サブクエリを使ってsessions_grouped_by_logged_onを参照して、その行の日付から一週間以内の行を探し出して、セッションID数を集計するというものです。
クエリにすると次のようになります。
-- これは動かない
SELECT
d.logged_on,
(
SELECT
COUNT(DISTINCT s.session_id)
FROM
sessions_grouped_by_logged_on s
WHERE
DATE_DIFF(d.logged_on, s.logged_on, DAY) <= 7)
FROM
days_logged d;
書いてはみたものの、これは次のようなエラーが出力されて動きませんでした。
LEFT OUTER JOIN cannot be used without a condition that is an equality of fields from both sides of the join.
どうやらサブクエリの中では>とか>=とかではなく、=の条件を使わないと動かないそうです。
また、分析関数を使ってその行を基準に過去一週間分を取得する方法が書けないかと考えましたが、6行前を取得することはできても、「一週間以内のセッションID全てから重複を除いて集計する」の部分が表現できず、うまくいきませんでした。
解決策
ここで行き詰まって色々と調べた結果、次のページにたどり着きました。まさにここでやりたいことです。
SQL - 日付毎にその日から一週間の間のアクティブユーザー数を集計したい|teratail
https://teratail.com/questions/159086
結合の条件で=が必要とはいうものの、INNER JOINではBETWEENが使えるようです。
これを使えば、テーブルAの各行に対して、テーブルBのカウント開始日<=テーブルAの基準列<=テーブルBのカウント終了日のような条件で、日付が特定の範囲に収まる行のみをテーブルBから抽出して、それらの中から特定の列を数える、ということができることになります。例えばINNER JOIN 利用履歴 B ON A.基準日付 BETWEEN B.カウント開始日AND B.カウント終了日のような感じです。
JOINでBETWEENが使われているところなんて見たこともなく、全く思いつかない発想でした。
アイデアは次の図のようになります。ログの各行について、①日付Bの6日後を計算しておき、②集計したい各日付Aの行ごとに、日付B<=日付A<=日付Bの6日後が成立する行を紐付けて、そこからセッションIDを取得して、③最後にそれを数える、という具合です。
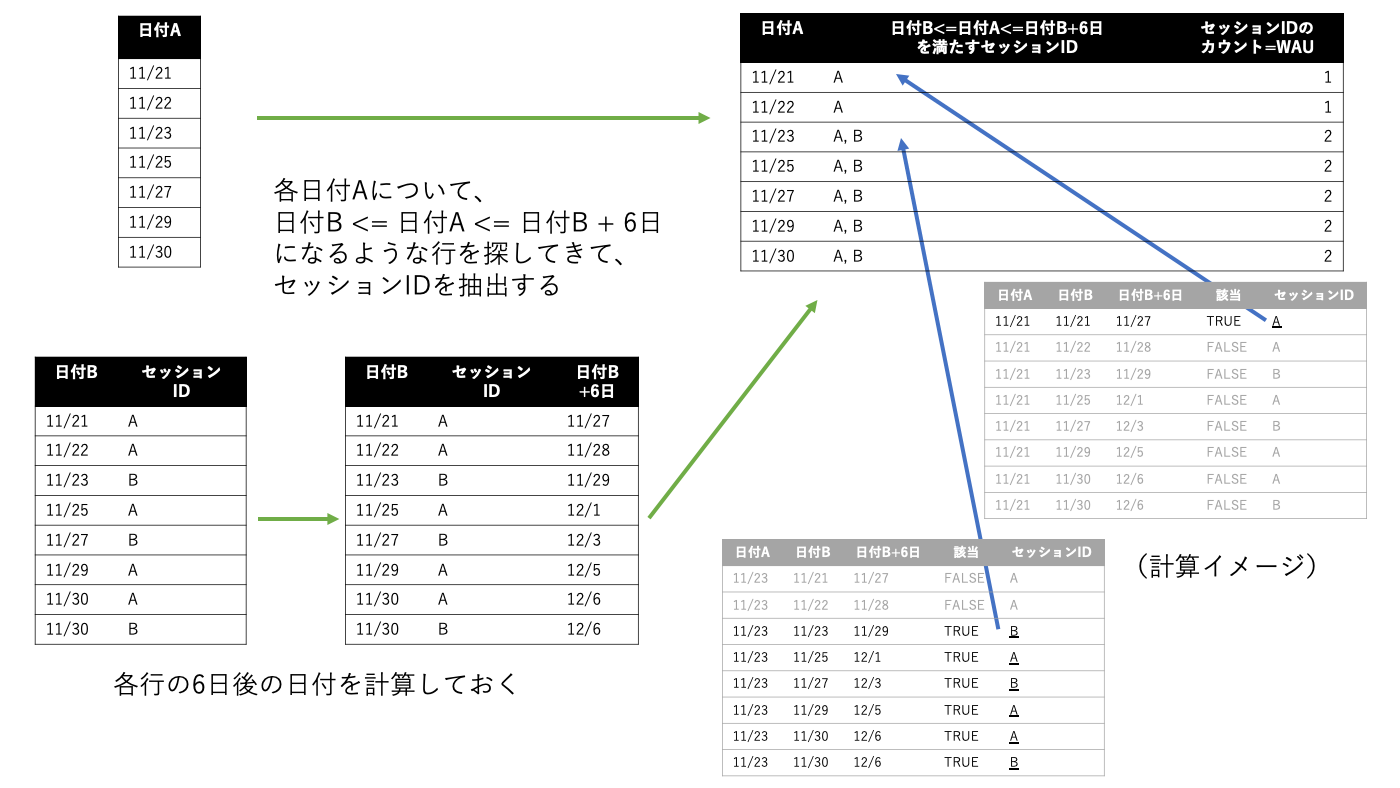
BETWEENの中に色々と式を書くのは見栄えが悪いので、カウント対象の期間を計算するだけのクエリau_tmpを書くことにしました。
WAU, MAUと呼んで良いのかわかりませんが、クエリ内ではau7, au28と記載しています。
au_tmp AS ( -- 一定期間内のアクティブユーザを計算するためにある日付が何日後までカウント対象になるか持っておく
SELECT
logged_on,
session_id,
DATE_ADD(logged_on, INTERVAL 6 DAY) AS max_day_au7,
DATE_ADD(logged_on, INTERVAL 27 DAY) AS max_day_au28
FROM
sessions_grouped_by_logged_on),
au7 AS ( -- 7日AU
SELECT
days_logged.logged_on,
COUNT(DISTINCT au7_tmp.session_id) AS au7
FROM
days_logged
INNER JOIN
au_tmp au7_tmp
ON
days_logged.logged_on BETWEEN au7_tmp.logged_on
AND au7_tmp.max_day_au7
GROUP BY
days_logged.logged_on),
au28 AS ( -- 28日AU
SELECT
days_logged.logged_on,
COUNT(DISTINCT au28_tmp.session_id) AS au28
FROM
days_logged
INNER JOIN
au_tmp au28_tmp
ON
days_logged.logged_on BETWEEN au28_tmp.logged_on
AND au28_tmp.max_day_au28
GROUP BY
days_logged.logged_on)
一つのテーブルで7日分と28日分を一気に結合すると、クエリがものすごく重くなったので((日数xユーザ数)^2になるのでそれはそうです)分けました。
DAUと基本統計量
DAUは日付ごとのユーザ数の集計で求まります。
基本統計量はも集計ですぐに求まりそうなものですが、中央値を求める専用の関数はないらしく、標本内での一を%単位で指定して値を取得するPERCENTILE_CONTを使わないといけなさそうです。PERCENTILE_CONT(v, 0.5) OVER(PARTITION BY k) のように使います。GROUP BY kでは動きません。
標準 SQL 関数と演算子 | BigQuery | Google Cloud
https://cloud.google.com/bigquery/docs/reference/standard-sql/functions-and-operators?hl=ja#percentile_cont
ということで、基本統計量のクエリは全て分析関数の形で書くことにしました。分析関数だと、集計関数と違って各行ごとに計算されてしまうので、DISTINCTをつけて余分な行を排除しました。ただ、無駄な計算をさせている気がするのが気になります。(これはいつかの宿題ということで…。ここも良い書き方あったらぜひご教示ください。)
集計部分をコピペしやすいように一度k, vというカラム名に変換してから計算しています。
descriptive_statistics AS ( -- ページ遷移の基本統計量
SELECT
DISTINCT k AS logged_on,
COUNT(1) OVER (PARTITION BY k) AS dau,
ROUND(AVG(v) OVER(PARTITION BY k), 3) AS average,
ROUND(PERCENTILE_CONT(v,
0.5) OVER(PARTITION BY k), 3) AS median,
ROUND(STDDEV_SAMP(v) OVER (PARTITION BY k), 3) AS stddev
FROM (
SELECT
logged_on AS k,
pvps AS v
FROM
sessions_grouped_by_logged_on ) ),
また、再訪間隔の平均値も計算しておきます。
ddr_descriptive_statistics AS ( -- 再訪間隔の基本統計量
SELECT
DISTINCT k AS logged_on,
ROUND(AVG(v) OVER(PARTITION BY k), 3) AS average
FROM (
SELECT
logged_on AS k,
dbr AS v
FROM
sessions_dbr_and_fq ) ),
出力
最後に、これまでのテーブルを全て結合します。
SELECT
pages_per_session_descriptive_statistics.logged_on,
pages_per_session_descriptive_statistics.dau,
pages_per_session_descriptive_statistics.average AS session_average,
pages_per_session_descriptive_statistics.median AS session_median,
pages_per_session_descriptive_statistics.stddev AS session_stddev,
ddr_descriptive_statistics.average AS ddr_average,
fqx.fq5_count,
au7.au7 AS au7_wau,
au28.au28 AS au28_mau
FROM
days_logged
INNER JOIN
pages_per_session_descriptive_statistics
ON
pages_per_session_descriptive_statistics.logged_on = days_logged.logged_on
INNER JOIN
ddr_descriptive_statistics
ON
ddr_descriptive_statistics.logged_on = days_logged.logged_on
INNER JOIN
fqx
ON
fqx.logged_on = days_logged.logged_on
INNER JOIN
au7
ON
au7.logged_on = days_logged.logged_on
INNER JOIN
au28
ON
au28.logged_on = days_logged.logged_on
ORDER BY
days_logged.logged_on DESC ;
これが、先ほどのスクリーンショットとして出力されます。
結論
以上で、欲しかった数値を全て入手することができました。あとはスプレッドシートなりRedashなりでグラフを作れば、傾向を直感的に把握しやすくなります。
今回の記事のクエリに行きつくまでに色々と試行錯誤をして、分析関数の表現力がよくわかりました。WITHももっと活用したほうがいいということがわかりました。
実業務でどこまで使えるかもわかりませんが、良い練習になったのと、案外使い所があるんじゃないかなと思ったりもしています。
明日のアドベントカレンダーは@YudaiTsukamotoさんが担当します。