環境
・ macOS Ventura 13.2
・ python 3.10.0
・ pandas 2.0.3
・ selenium 4.11.2
(なお、私はソースコードはiCloudに保存しています)
なぜ、作った?
毎月、大変な量の新刊が発売されるので、「自分の好みの作家」や「シリーズ物」の新刊の状況を確認できるようにしたいと思い作成しました。
■記述する内容は以下の通りです。
とても長いですが、コピペしてください。(まだ経験が浅いため、非効率な部分があると思いますが、ご容赦ください。)
■コピペが終わったら、あなた仕様にprogramのCodeを書き換えてください。
①モジュールのimport
インポートするモジュール群のコメントの頭に(*)がついているモジュールはpip等によりインストールが必要です。
②ダウンロードディレクトリは空の状態
*ダウンロードディレクトリは空の状態にしてください。
③検索する作者名ならびにシリーズ物のタイトルは、あなた仕様に変更してください。
検索する作者名ならびにシリーズ物のタイトルは、「auter」変数ならびに「title」変数を書き替えてください。
④「csvdata」ディレクトリと「book」ディレクトリを作成しておいてください
事前にこのprigramを保存するディレクトリに、「csvdata」ディレクトリを作成しておいてください(中身は空でOK)
事前に「書類」ディレクトリに 「book」ディレクトリ を作成しておいてください(中身は空でOK)
# 新刊情報収集Program
# ----------------------------------------------------------------
import pandas as pd
import os.path # ファイルやディレクトリが指定したパスに存在するかを確認したり、パスからファイル名や拡張子を取得したりなどを行う際に利用されるモジュール
import os # OSに依存しているさまざまな機能を利用するためのモジュール
import glob # 引数に指定されたパターンにマッチするファイルパス名を取得
from datetime import datetime # (*)日付や時間を扱うためのモジュール
import re # Python で正規表現を行うモジュール
from bs4 import BeautifulSoup # (*)複雑なHTMLの構造を解析し、必要な部分を取り出す
import requests # (*)HTTP接続するため
import shutil # フォルダのコピー(copy、copytree)や移動(move)、削除(rmtree)するためのモジュール
import subprocess as sb # Pythonからコマンドを実行するためのモジュール
import time
# ----------------------------------------------------------------
# seleniumオブジェクト(さまざまなブラウザを制御するためのクラスを提供
# 主にWebアプリケーションのテストやスクレイピングなどに使用するモジュール)
from selenium import webdriver
# find_element() メソッドを呼び出す際に要素を見つける方法を指定するために使用
from selenium.webdriver.common.by import By
# 要素が特定の条件を満たすまで待機するために使用
from selenium.webdriver.support.ui import WebDriverWait
# WebDriverWait と組み合わせて、要素が特定の条件を満たすまで待機するために使用
from selenium.webdriver.support import expected_conditions
# Serviceクラスは、ブラウザのドライバーを実行するためのサービスを管理するためのクラス
# 通常、直接使用することはありませんが、カスタム設定が必要な場合に便利
from selenium.webdriver.chrome.service import Service as ChromeService
# ----------------------------------------------------------------
# Selenium WebDriver用のドライバーを自動的にダウンロードして管理するためのツール(パッケージ)
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
# ----------------------------------------------------------------
# ヘッドレスモード設定
options = webdriver.ChromeOptions()
options.add_argument("--headless")
# ----------------------------------------------------------------
author = ['中山七里','柚月裕子','町田そのこ','今野敏','西尾維新','辻村深月','望月麻衣','青木祐子','米澤穂信','岡崎琢磨','恩田陸','三上延','住野よる','今村昌弘']
title = ['これは経費で落ちません','ビブリア古書堂','コンビニ兄弟','珈琲店タレーランの事件簿']
# ----------------------------------------------------------------
# ダウンロード先のフォルダの設定(※必ずフルパスとすること)
# 絶対パスからUserNameを取得
userpath = os.path.abspath(__file__)
userName = str(userpath.split('/')[2])
PATH = '/Users/'+userName+'/Downloads/'
PATH2 = '/Users/'+userName+'/Documents/book/'
# ================================================================
# TRC新刊図書オープンデータ(図書館流通センター)を加工
def opendeta():
# ファイル名の取得
path = PATH
# txtァイルのみ選別
import glob
fname = [os.path.basename(p) for p in glob.glob(path + "TRCO*.txt", recursive=True) if os.path.isfile(p)]
for i in range(len(fname)):
n = i
m = str(i)
# ----------------------------------------------------------------
df = pd.read_table(path + fname[n], skiprows=2,names=("ISBN","タイトル","サブタイトル","著者1","著者2","版表示","出版社","発売者","出版年月","ページ数等","大きさ","付属資料の種類と形態","シリーズ名・番号1","シリーズ名・番号2","シリーズ名・番号3","各巻のタイトル","本体価格","セット本体価格"))
# 特定の行・列に欠損値NaNがある列・行を削除: subset
df = df.dropna(subset=['ISBN'])
# ----------------------------------------------------------------
# 必要項目のみcsv保存
df.to_csv("csvdata/bookdata_"+ m +".csv",columns=("ISBN","タイトル","サブタイトル","著者1","出版社","出版年月"))
# ----------------------------------------------------------------
# csvからデータの読み込み
df = pd.read_table("csvdata/bookdata_"+ m +".csv")
# ファイルを削除
# txtファイルのみ選別
temp = [os.path.basename(p) for p in glob.glob(path + "TRCO*.txt", recursive=True) if os.path.isfile(p)]
for i in range(len(temp)):
delF = temp[i]
# txtファイルを削除
os.remove(path + delF)
# ================================================================
# csvdataディレクトリ内のファイルを一本化してcsvdataディレクトリ内にjoinData.csvを作成
def jon():
path = "csvdata"
files = os.listdir(path)
TRCO = glob.glob(os.path.join(path,"*.csv"))
# STEP6:csvファイルをDataFrameへ読み込み
df1 = pd.read_csv(TRCO[0])
df2 = pd.read_csv(TRCO[1])
df3 = pd.read_csv(TRCO[2])
df4 = pd.read_csv(TRCO[3])
'''2022/1/22にリリースされたpandas 1.4.0からappendメソッドが非推奨となったため
# STEP8:dataFrameの結合
# df1+df2
a1 = df1.append(df2, ignore_index=True)
# df3+df4
b1 = df3.append(df4, ignore_index=True)
df = a1.append(b1, ignore_index=True)
ln = len(df)
'''
# STEP8:dataFrameの結合
a1 = pd.concat([df1, df2], ignore_index=True)
# df3+df4
b1 = pd.concat([df3,df4], ignore_index=True)
df = pd.concat([a1,b1], ignore_index=True)
ln = len(df)
# STEP9:結合したDATAを保存
df.to_csv ('csvdata/joinData.csv')
print('-'*50)
# STEP10(joint):data重複の有無確認
df1 = df[df.duplicated()] # 重複した行を抽出:duplicated()
df2 = df1.empty
if df2 == True:
print('###data重複の有無:無し')
print('-'*50)
elif df2 == False:
print(f'重複の有無:有り = {df1}')
else:
print('')
# ================================================================
# /Documents/bookフォルダ内の古いファイルを削除する
def remv():
# フォルダ内のファイル一からファイルパスを取得してファイル名のみを取得してから、ファイルの作成日時(エポック秒)を取得
files = glob.glob(PATH2+ "*.csv")
temp2 = []
# ファイル名とエポック秒をセットにしてリストに変換し2次元リストを作成[['ファイル名', エポック秒],['ファイル名', エポック秒],...]
for file in files:
# ファイルパスからファイル名.拡張子を取得
file_name= os.path.basename(file)
# ファイルパスからファイル名のみを取得する場合は以下を続ける
# file_name = os.path.splitext(file_name)[0]
for i in range(1):
temp1 = []
# ファイル名をリストへ
temp1.append(file_name)
# ファイルのエポック秒を取得
getcTime = os.path.getctime(file)
# getcTimeをリストに代入
temp1.append(getcTime)
temp2.append(temp1)
# リストをソート
temp2.sort()
# temp2にあるファイルの個数を調べる
ln = len(temp2)
'''
# temp2リスト内の要素の表示(完成後コメントアウト)
for i in range(ln):
print(f'temp2[{i}][0]:{temp2[i][0]}')
print('-'*50)
print('')
'''
# リストに2ファイルを残して削除
# 削除する個数
lv = ln - 2
# 削除
for i in range(lv):
sr = temp2[i][0]
print(f'削除したファイル名:{sr}')
os.remove(PATH2 + sr)
if lv>2:
print('以上のファイルを/Documents/book/から削除完了しました。')
else:
print('/Documents/book/のファイル数は2個です。')
# ================================================================
# pandasで特定の文字列を含む行を抽出(完全一致、部分一致)
def searching():
'''2023-10-18 修正
# FutureWarning: 空のエントリを含む配列連結の動作は非推奨となったため不要
# 空のdataframeを作る(特定の作家の行を入れる箱)
cols = ['出版年月','タイトル','著者1','出版社','サブタイトル','ISBN']
athrDf = pd.DataFrame(index=[],columns=cols)
'''
# ----------------------------------------------------------------
# 'sasyugoCsv/joinData.csv'から必要な列を取得してdetaframeへ
cols = ['出版年月','タイトル','著者1','出版社','サブタイトル','ISBN']
df = pd.read_csv('csvdata/joinData.csv', usecols=[cols[0],cols[1],cols[2],cols[3],cols[4],cols[5]])
# ----------------------------------------------------------------
# 特定の作家の行を抽出
print('')
print('='*100)
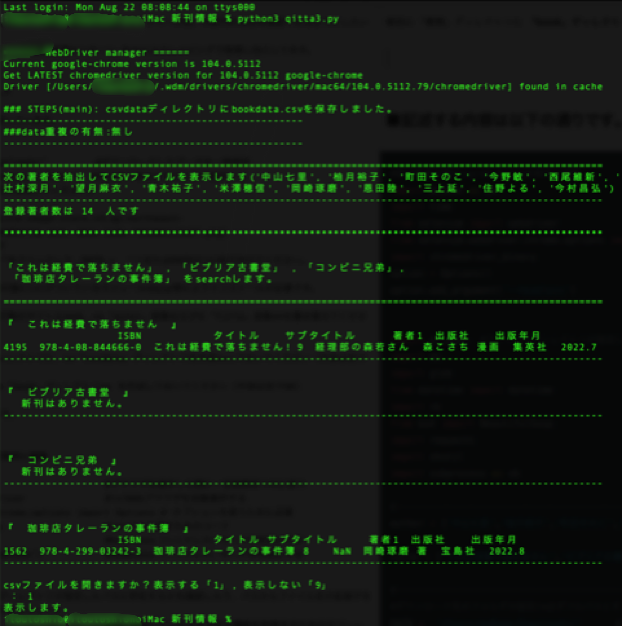
print(f"次の著者を抽出してCSVファイルを表示します{author}")
print('-'*100)
ln = len(author)
print(f'登録著者数は {len(author)} 人です')
'''2023-10-18 修正
# FutureWarning: 空のエントリを含む配列連結の動作は非推奨となったため不要
FutureWarning: 空のエントリを含む配列連結の動作は非推奨になります。 将来のバージョンでは、結果の dtype を決定するときに空の項目が除外されなくなります。 以前の動作を維持するには、concat 操作の前に空のエントリを除外します。
for n in range(ln):
#athrDf = pd.concat([athrDf ,df[df['著者1'].str.contains(author[n], na=False)]])
#csvに保存
athrDf.to_csv('csvdata/outhor.csv')
'''
# '著者1'列から著者名を正規表現で抽出
# isinstance(x, str)を使用して各要素が文字列であることを確認し、それ以外の場合は空の文字列に変換
# "import re" が必要
df['著者名'] = df['著者1'].apply(lambda x: re.sub(r' 著$', '', x) if isinstance(x, str) else '')
# 抽出した著者名でフィルタリング
# Pandasはベクトル化された演算をサポートしており、データフレーム全体に対して操作を実行
# isin関数を使用した方法は、効率的であり、forループを使うよりも簡潔で高速
athrDf = df[df['著者名'].isin(author)]
# 不要な著者名の列を削除
athrDf = athrDf.drop(columns=['著者名'])
# CSVに保存
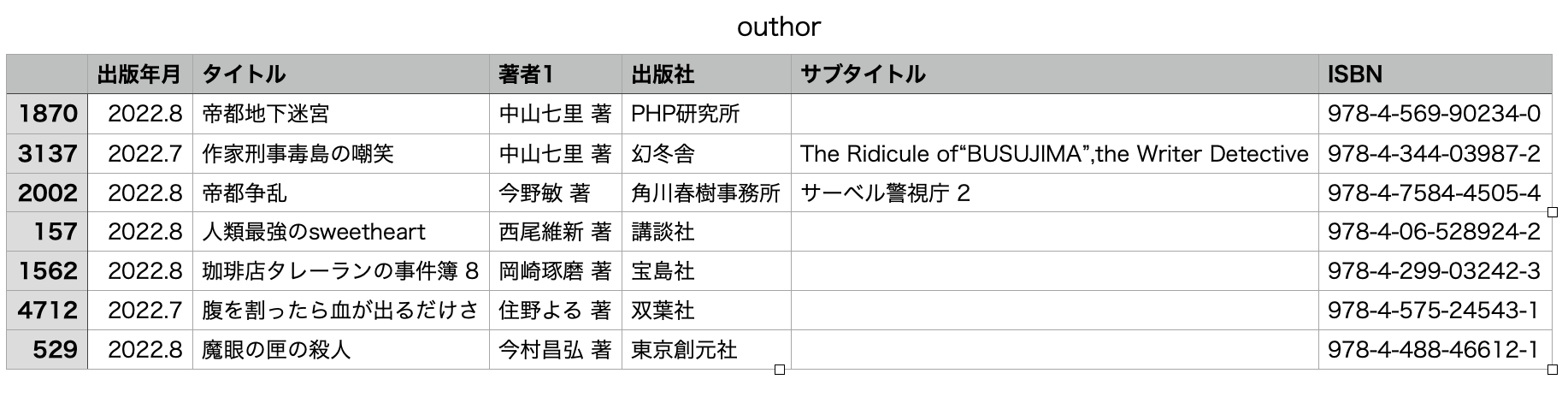
athrDf.to_csv('csvdata/outhor.csv', index=False)
#------------------------------------------
# 日付を取得
now = datetime.now()
str_now = now.strftime('%Y-%m-%d')
# ------------------------------------------
# 'Documentsに「book」ディレクトリを作成して保存(外出先でiPhonの「ファイル」から見るため)
athrDf.to_csv(PATH2+str_now+'新刊情報.csv')
# bookディレクトリに2ファイル残して古いファイルを削除
remv()
# ----------------------------------------------------------------
# 表示
print('')
print('*'*100)
print('')
print('')
print(f'「{title[0]}」 , 「{title[1]}」 , 「{title[2]}」,\n 「{title[3]}」 をsearchします。')
print('')
print('='*100)
n = 0
for i in range(len(title)):
print('')
print(f'『 {title[i]} 』')
df2 = df[df['タイトル'].str.contains(title[i],na=False)] # ※1
df2 = df2.empty # ※2
if df2 == False:
print(df[df['タイトル'].str.contains(title[i],na=False)])
print('-'*100)
elif df2 == True:
print(' 新刊はありません。')
print('-'*100)
print('')
print('')
# ================================================================
# ダウンロードディレクトリ
download_path = PATH
options.add_experimental_option("prefs", {"download.default_directory": download_path})
# Chromeを準備(options=optionでシークレットモード)
browser = webdriver.Chrome()
# ------------------------------------------
# STEP1:指定のURL(TRC新刊図書オープンデータ)にアクセス
url = "https://www.trc.co.jp/trc_opendata/"
browser.get(url)
time.sleep(1)
# ----------------------------------------------------------------
# BeautifulSoup: "a href"を取り出す
r = requests.get(url)# urlを取得
time.sleep(3) # 3秒待機
# aタグの個数を調べる
soup = BeautifulSoup(r.text, 'html.parser')
contents = soup.find(class_="typeA margB40")
get_a = contents.find_all("a")
# ----------------------------------------------------------------
# STEP2:リンクテキストでハイパーリンクを探し、ファイルのダウンロード
for i in range(len(get_a)):
n = str(i+1)
# ファイルのダウンロード
# file_link = browser.find_element_by_xpath('//*[@id="main"]/section/ul[2]/li['+n+']/a')# <-selenium3以前
file_link = browser.find_element(By.XPATH,'//*[@id="main"]/section/ul[2]/li['+n+']/a')# <-selenium3以降
file_link.click()
time.sleep(1)
# STEP3:ブラウザを閉じる
browser.quit()
# ----------------------------------------------------------------
# STEP4:ZIPファイルの解凍
# 使用後ファイルを削除するため、ダウンロードディレクトリのファイル名を取得(ファイル名にある日付があり変わるため)
dl_path = PATH
# ファイル名の取得
# zipファイルのみ選別してlist'delfile'へ代入
delfile = [os.path.basename(p) for p in glob.glob(dl_path + "TRCO*.zip", recursive=True) if os.path.isfile(p)]
# ---------------------
# Downloadsディレクトリ内のファイルの数を調べる
initial_count = 0
dir = PATH
for path in os.listdir(dir):
if os.path.isfile(os.path.join(dir, path)):
initial_count += 1
# ---------------------
# Downloadsディレクトリ内のファイルの数が4以上の場合IndexErrorとなるため。
ic = initial_count-2
if ic > 4:
print('*-'*50)
print('')
print(f'IndexError:Downloadsディレクトリ内のファイルの数が異常です。\n(ファイル数:{initial_count-2})')
print('Downloadsディレクトリを空にしてください。')
print('')
print('*-'*50)
exit()
else:
print('')
# ---------------------
# 繰り返し処理
for j in range(initial_count-2):
n = j
# Downloadsディレクトリ内のファイルを解凍して,Downloadsディレクトリ内に保存
shutil.unpack_archive(PATH + delfile[n], PATH)
# Downloadsディレクトリの.zipファイルを削除
os.remove(PATH + delfile[n])
# ----------------------------------------------------------------
# TRC新刊図書オープンデータ(図書館流通センター)を加工して、csvdataディレクトリにbookdata.csvで保存
opendeta() # self-made function
print('### STEP5(main): csvdataディレクトリにbookdata.csvを保存しました。')
# ----------------------------------------------------------------
# csvdataディレクトリ内のファイルを一本化してjoinData.csvを保存
jon() # self-made function
# ----------------------------------------------------------------
# pandasで特定の文字列を含む行を抽出(完全一致、部分一致)
searching() # self-made function
# ----------------------------------------------------------------
# csvdataディレクトリのjoinData.csvファイルを削除
os.remove('csvdata/joinData.csv')
# ----------------------------------------------------------------
# csvdataディレクトリの/bookdata_x.csvファイルを削除
# bookdata_*.csvファイルのみ選別してtempリストに代入
temp = [os.path.basename(p) for p in glob.glob("csvdata/bookdata_*.csv", recursive=True) if os.path.isfile(p)]
for i in range(len(temp)):
# csvファイルを削除
os.remove('csvdata/' + temp[i])
# ----------------------------------------------------------------
# csvファイルを開くかどうかの質問
ans = int(input('csvファイルを開きますか?表示する「1」, 表示しない「9」\n : '))
if ans == 1:
print('表示します。')
sb.run(['open','-n','csvdata/outhor.csv'])
elif ans == 9:
print('終了します。')
exit(1)
elif ans != 1 or ans != 9:
print('「1」または「9」以外の数字です。\n 終了します。')
exit(1)
<参考資料>
DATAは『TRC新刊図書オープンデータ(図書館流通センター)』をからスクレイピングで取得し加工してます。
Terminalの表示例
Numbersの表示例
--------------------------------------------
Pythonのrequest.getでSSLのエラーが出たときの解決方法
2024-03-18 TRC新刊図書オープンデータ(図書館流通センター)からスクレイピングの際発生したので、解決策を記載します。
--------------------------------------------
□Webdriver managerを使用していても、Google Chrome のバージョンをサポートしていないとメッセージが出た場合の対処方法
こんなこんなメッセージ
selenium.common.exceptions.SessionNotCreatedException: Message: session not created: This version of ChromeDriver only supports Chrome version 111
Current browser version is 113.0.5672.92 with binary path /Applications/Google Chrome.app/Contents/MacOS/Google Chrome
を参照にしました。
■ 2023-03-03修正記録
① selenium3以降の記述方法の修正
AttributeError: 'WebDriver' object has no attribute 'find_element_by_xpath'
の修正
# selenium3まで
webdriver.Chrome(ChromeDriverManager().install())
# selenium4以降
from selenium.webdriver.chrome.service import Service
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
② 2022/1/22にリリースされたpandas 1.4.0からappendメソッドが非推奨となったための修正
FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
(修正前)
# STEP8:dataFrameの結合
a1 = df1.append(df2, ignore_index=True)
b1 = df3.append(df4, ignore_index=True)
df = a1.append(b1, ignore_index=True)
(修正後)
a1 = pd.concat([df1, df2], ignore_index=True)
b1 = pd.concat([df3,df4], ignore_index=True)
df = pd.concat([a1,b1], ignore_index=True)
以上です
③ WebDriver の executable_path 使用に伴う非推奨機能に対する警告メッセージ(DeprecationWarning)回避の為の修正
# Serviceのインポート(selenium4での修正 )
以下のサイトを参考にさせて頂きました。
webdriverのselenium4での修正内容
selenium3以前
driver = webdriver.Chrome(ChromeDriverManager().install(), options=options)
selenium4以降
from selenium.webdriver.chrome.service import Service # executable_pathを指定
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=options)
以上