「ゲームで学ぶ探索アルゴリズム実践入門」のサンプルコードでAtCoderの問題を解いてみた
はじめに
どうもこんにちは、thunderです。
私事ではありますが、2023/2/18に「ゲームで学ぶ探索アルゴリズム実践入門~木探索とメタヒューリスティクス」という技術書を出版しました!
本書の魅力はspeakerdeckにアップロードしたスライドにまとめているので、御覧いただけると幸いです。
さて、本書のサンプルコードはサポートページからダウンロードできるのですが、学んだ内容を活かして何かプログラムを書きたい!という方もいらっしゃるのではないかと思います。
本記事では、このサンプルコードを用いて実際にAtCoder上の問題を解く過程を説明していきます。
本記事を通して、「ゲームで学ぶ探索アルゴリズム実践入門~木探索とメタヒューリスティクス」で学んだ内容を「実際に使える技術」に落とし込んでいただくことを目指します。
対象読者
「ゲームで学ぶ探索アルゴリズム実践入門~木探索とメタヒューリスティクス」を読了した方。(最低でも3章は読み終わっているとよいです)
問題設定
本記事では、第2回 RCO日本橋ハーフマラソン 予選A問題「ゲーム実況者Xの挑戦」を扱います。
少し古いと感じるかもしれませんが、探索アルゴリズムを適用するにあたっては今でも色褪せない、入門にぴったりの問題です。
https://atcoder.jp/contests/rco-contest-2018-qual/tasks/rco_contest_2018_qual_a
細かい入力やルールは公式ページを読んでいただきたいですが、ざっくりとルールを説明します。
まず最初にN個のマップが入力されます。(本来はN=100ですが、説明のためにN=4で図をつくりました。)
マップはコイン(o)、壁(#)、罠(x)、キャラクター(@)で構成されます。

その中で、プレイヤーは好きなマップをK個選択します。(本来はK=8ですが、説明のためにK=2で図をつくりました。)
たとえば、マップ1とマップ2を選択したとします。

その後、キャラクター(@)を最大T回動かします。(本来はT=2500です。移動方向は上、下、左、右の四方向から自由に選択できます。)
選択した移動は全てのマップに同時反映されます。
上の図から「上移動」を選択した場合、以下の図のような状態になります。
マップ1では、コインのある場所にキャラクターが移動しました。この場合、マップからコインを排除し、ゲームスコアを1加算します。
マップ2では、移動先に壁(#)があります。この場合、キャラクターは移動しません。

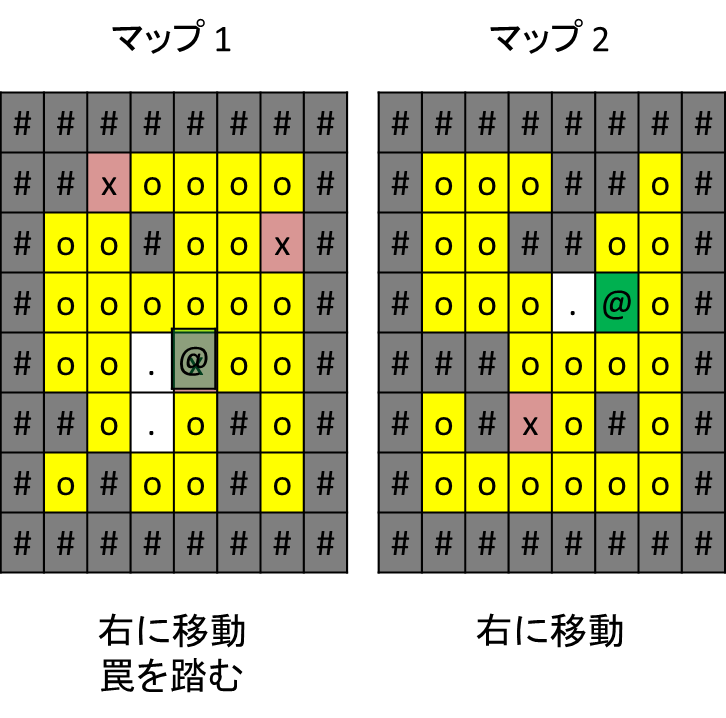
同様に、「右移動」を選択したとします。
マップ1、マップ2、共に移動先に壁がないため、右移動をします。
マップ1ではキャラクターが罠を踏みました。罠を踏んだマップではそれ以降移動ができなくなります。
マップ2ではコインを獲得しました。ゲームスコアが既に1だったので、この時点でゲームスコアは2になります。
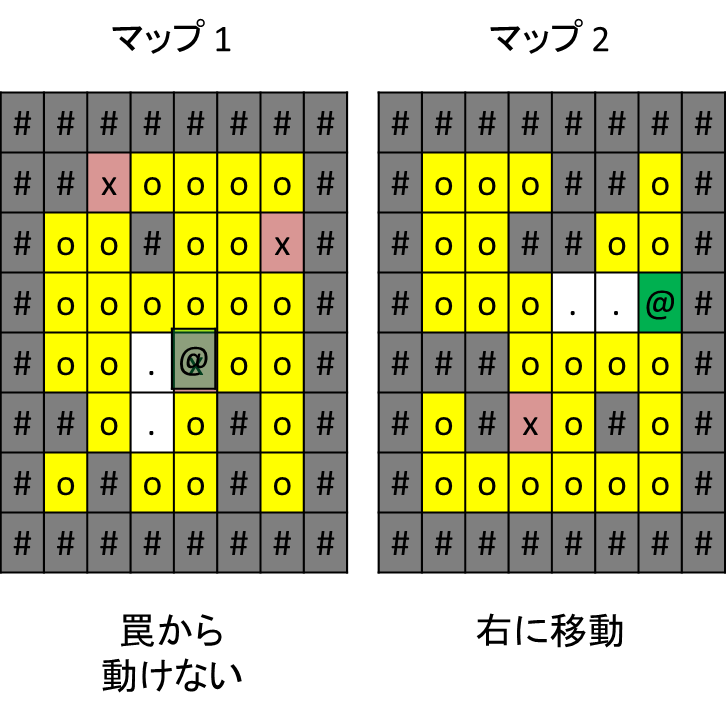
さらにもう一度、「右移動」を選択したとします。
マップ1では、先ほど罠を踏んでいるため、移動できません。
マップ2では、右に移動してコインを獲得しました。ゲームスコアが既に2だったので、この時点でゲームスコアは3になります。
このような手順で、最大T回の移動を終えた後のゲームスコアを最大化することがこのゲームの目的です。
「K個のマップを選択する」、「T回の移動方向を選択する」といったシンプルなルールなゲーム性の中で、探索アルゴリズムがどのように活用できるのか見ていきましょう。
サンプルコードを適用する
準備
まずは「ゲームで学ぶ探索アルゴリズム実践入門~木探索とメタヒューリスティクス」のサポートページからサンプルコードをダウンロードします。
https://gihyo.jp/book/2023/978-4-297-13360-3/support
sample_code.zipを解凍すると、以下のようなフォルダ構成になっています。
今回のように、書籍で扱った以外のゲームに探索アルゴリズムを適用する際は、Appendixフォルダ内のコードを利用します。
sample_code
├── 03_OnePlayerGame
├── 04_HeuristicGame
├── 05_AlternateGame
├── 06_SimultaneousGame
├── 07_Advanced
├── 08_Actual
└── Appendix ←書籍に記載のゲーム以外に適用できる汎用サンプルコード
さて、「ゲームで学ぶ探索アルゴリズム実践入門」を読了した皆さんならば、今回の問題にどのアルゴリズムが適しているかわかるのではないでしょうか。
今回の問題では、「マップを8つ選択する」、「2500回分のコマンドを選択する」の2フェーズに分けることができます。
なんらかの方法で「マップを8つ選択する」を終えた後は、マス目状のキャラクターを動かすターン制のゲームということで、「ゲームで学ぶ探索アルゴリズム実践入門」の「数字集め迷路」にかなり近いルールになることがわかります。
対戦相手がいるわけではなく、自分自身の行動だけでゲームの状況が時系列的に確定することから、「文脈のある一人ゲーム」として扱えそうです。
これは3章の範囲なので、今回はAppendixの中の03_BeamSearchWithTime.cppか03_ChokudaiSearchWithTime.cppが有効そうです。
sample_code
└── Appendix ←書籍に記載のゲーム以外に適用できる汎用サンプルコード
├── 03_BeamSearchWithTime.cpp
└── 03_ChokudaiSearchWithTime.cpp
ビームサーチとChokudaiサーチ、どちらを使用してもよいですが、今回はビームサーチで説明することにします。
ということで、03_BeamSearchWithTime.cppを元に「ゲーム実況者Xの挑戦」を解くプログラムを実装する手順を説明していきます。
入出力形式に合わせた修正
03_BeamSearchWithTime.cppでは、未完成のStateクラスを用意しています。
このStateクラスを問題にあわせて実装して完成させ、main関数から適切にbeamSearchActionWithTimeThresholdを呼び出すことで、問題を解くことができます。
と、言いたいところですが、実は実際に問題を解く際に注意すべきことがあります。
というのも、AtCoderの場合、大きく分けて2種類の入出力方式があります。
- 入力と出力を交互に繰り返す形式(インタラクティブ形式 )
- 入力を1度受け取った後、出力を1度して終了する形式(バッチ形式 )
ここで、03_BeamSearchWithTime.cppのStateを見てみましょう。
class State
{
int first_action_ = -1; // 探索木のルートノードで最初に選択した行動
};
Stateクラスは、探索した後に残す行動を1手分しか保持しないつくりになっています。
これは、上記の「1.インタラクティブ型」の問題を解く際に1手ずつ出力するのに有効です。
今回の問題は最大2500手分の行動を1回で出力するので、「2. バッチ形式」に該当します。
「2. バッチ形式」の場合、サンプルコードを以下のように修正することで、探索した行動履歴を全て保持し続けることができます。(行動履歴を保持する方法には工夫の余地がありますが、本記事では最も簡単な方法で説明します。)
class State
{
- int first_action_ = -1; // 探索木のルートノードで最初に選択した行動
+ std::vector<int> actions_{}; // 現在のノードまでの全行動履歴
};
// ビーム幅と制限時間(ms)を指定してビームサーチで行動を決定する
- int beamSearchActionWithTimeThreshold(
+ std::vector<int> beamSearchActionWithTimeThreshold(
const State &state,
const int beam_width,
const int64_t time_threshold)
{
//~略
if (time_keeper.isTimeOver())
{
- return best_state.first_action_;
+ return best_state.actions_;
}
//~略
- if (t == 0)
- next_state.first_action_ = action;
+ next_state.actions_.emplace_back(action);
//~略
- return best_state.first_action_;
+ return best_state.actions_;
}
全体像
細かい修正の前に、プログラムの全体像をイメージします。
以下に完成系のコードを示しますが、実際に実装するのは各クラスや関数を実装してからでよいです。
- 入力を読み取る
バッチ形式の問題の場合、最初に入力を読み取ります。 - マップをK個選択して出力する
今回はキャラクターの移動部分のみを考えたいため、最も簡単な実装をします。 - ビームサーチで探索する
メインの探索部です。ビーム幅や探索時間には工夫の余地を残しています。 - 探索結果の行動を出力する
出力まで終えた段階で得点を得られるプログラムになります。
Board all_boards[N]{}; // 100個のマップ情報を全て保持する
int main()
{
/********************************************************************/
// 1. 入力を読み取る
read(); // 読み取った情報は、グローバル領域のall_boardsに100個のマップ情報として格納される
/********************************************************************/
// 2. マップをK個選択して出力する
// 今回は簡単のため、入力から読み取った順にK個を選択することにする
State state{};
for (int i = 0; i < K; i++)
{
state.boards_[i] = all_boards[i];
std::cout << i << " ";
}
std::cout << std::endl;
/********************************************************************/
// 3.幅64のビームサーチで3秒探索する
auto actions =
beamSearchActionWithTimeThreshold(state, 64, 3000);
/********************************************************************/
// 4.探索結果の行動を出力する
for (auto &action : actions)
{
std::cout << DC[action];
}
std::cout << std::endl;
return 0;
}
各クラス、構造体が保持する情報の整理
まず、探索の要となるStateクラスについて考えます。
Stateクラスは各ターンにおけるゲームの状態を保持する必要があります。
今回のゲームの場合、8個のマップと、全体で共通する情報全てをStateクラスに保持すればとりあえず探索に必要な情報がそろいます。
// マップ8個分の情報をあるターンのゲーム状態として保持する
class State
{
ScoreType evaluated_score_ = 0; // 探索上で評価したスコア
std::vector<int> actions_{}; // 現在のノードまでの全行動履歴
+ Board boards_[K]{}; // 8個のマップ情報を全て保持する
+ int turn_ = 0; // 現在のターン
+ int coin_ = 0; // 取得したコインの数(8マップ合計)
};
Stateクラスでマップ情報8個を保持することにしたので、
マップ情報1個分の情報を構造体として定義します。
これは好みにもよりますが、筆者の場合はstd::mapと混同しないようにMapのような名前は避けています。
// マップ1つあたりの情報を保持する
struct Board
{
int id_ = 0; // マップid
char cell_[H][W]{}; // 座標(y,x)の情報{`o`:コイン, `x`:罠, `#`:壁, '.': コインのない床
Coord character_{}; // キャラクター位置
};
書籍の本文中にも何度も登場していますが、座標を保持する構造体Coordを用意してキャラクター位置を表現します。
// 座標を保持する
struct Coord
{
int y_;
int x_;
Coord(const int y = 0, const int x = 0) : y_(y), x_(x) {}
};
入力の読み取り
各データ構造の持つ情報を決めたので、入力を読み取る部分を実装します。
入力の1行目N K H W Tは固定値のため、読み飛ばしてよいです。
その後は100個のマップ情報を順番に読み取るだけなので複雑なことはありませんが、キャラクターの位置(@)はマップとしては何もない場所(.)として格納する点に注意します。
Board all_boards[N]{}; // 100個のマップ情報を全て保持する
// 入力を読み取る
void read()
{
std::string buffer; // 1行ずつ読み込むバッファ
std::getline(std::cin, buffer); // Nなどの定数は不要なので無視
for (int i = 0; i < N; i++)
{
auto &board = all_boards[i];
for (int y = 0; y < H; y++)
{
std::cin >> buffer;
for (int x = 0; x < W; x++)
{
char c = buffer[x];
if (c == '@')
{
board.character_.y_ = y;
board.character_.x_ = x;
c = '.'; // 盤面としてはなにもない状態として持つ
}
board.cell_[y][x] = c;
}
}
}
}
つくりかけのStateを完成させる
ここまで実装できれば、後はサンプルのStateの未実装部分を埋めるだけです。
ゲームの終了判定は「数字集め迷路」と同様で、経過ターン数を見るだけでよいです。
// ゲームの終了判定
bool isDone() const
{
+ return this->turn_ == T;
}
今回はコイン数をそのまま盤面評価とします。
// 探索用の盤面評価をする
void evaluateScore()
{
+ this->evaluated_score_ = coin_;
}
合法手を取得する関数を実装します。
今回のゲームにおいては4方向の移動全てが常に実行可能ですが、1マップでも罠を踏んでしまうとかなりスコアが落ちてしまうため、探索中は罠を踏まないことにします。
constexpr const int DY[4] = {0, 0, 1, -1}; // 右、左、下、上への移動方向のy成分
constexpr const int DX[4] = {1, -1, 0, 0}; // 右、左、下、上への移動方向のx成分
// 現在の状況でプレイヤーが可能な行動を全て取得する
std::vector<int> legalActions() const
{
+ std::vector<int> actions{};
+ for (int action = 0; action < 4; action++)
+ {
+ bool can_action = true;
+ for (const auto &board : this->boards_)
+ {
+ const Coord &character = board.character_;
+ int ty = character.y_ + DY[action];
+ int tx = character.x_ + DX[action];
+ // ルール上は罠を踏むことは可能だが、
+ // 今回は罠を踏まない前提で進める
+ if (board.cell_[ty][tx] == 'x')
+ {
+ can_action = false;
+ break;
+ }
+ }
+ if (can_action)
+ {
+ actions.emplace_back(action);
+ }
+ }
+
return actions;
}
指定したactionでゲームを1ターン進める関数を実装します。
legalActionsで罠を踏むことを禁止したため、こちらでは罠についてルール通りに実装する必要はありません。
また、移動予定の場所に壁があった場合はキャラクター位置を更新しない点に注意しましょう。
// 指定したactionでゲームを1ターン進める
void advance(const int action)
{
+ for (auto &board : this->boards_)
+ {
+ Coord &character = board.character_;
+ int ty = character.y_ + DY[action];
+ int tx = character.x_ + DX[action];
+ char &cell = board.cell_[ty][tx];
+
+ if (cell == '#')
+ {
+ continue;
+ }
+ else
+ {
+ if (cell == 'o')
+ {
+ ++this->coin_;
+ cell = '.';
+ }
+ character.y_ = ty;
+ character.x_ = tx;
+ }
+ }
+ ++this->turn_;
+ }
提出
ここまで実装できればあとは提出するだけです。
上記を実装したコードをAtCoderのジャッジに提出したところ、
結果は160392点でした。
コンテスト本番でのA問題1位のスコアは292021なので、約半分程度のスコアです。本番はわずか4時間で2問解く形式なので、コンテスト参加者はかなり急いでこの問題を解いています。そのため、初心者の皆さんでも、時間をかけて本記事のコードを改良すれば、コンテスト本番相当のスコアを達成するのも夢ではないでしょう。
今回は8個の地図をちゃんと選んでいないですし、探索効率をよくする仕組みを導入していません。
ぜひご自身の力で、さらなる高みを目指して見ましょう。
おまけ
人に見せるように清書していないため、あまりきれいではありませんが、筆者の提出を2つ紹介します。
- 7章に記載の応用テクニックなどを活用し、上記をさらに改良した筆者のコード(スコア: 314361)
https://atcoder.jp/contests/rco-contest-2018-qual/submissions/38464755 - 問題特性にあわせて探索部を大幅に変更した、より高速な筆者のコード(スコア: 315838)
https://atcoder.jp/contests/rco-contest-2018-qual/submissions/38718152