サイト
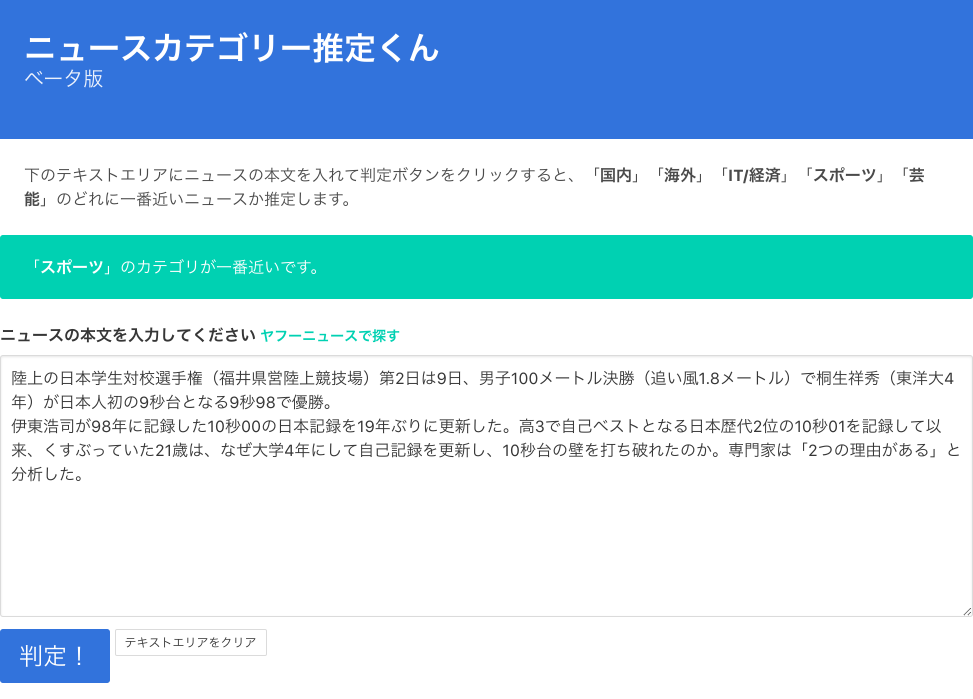
テキストエリアにニュースの本文を入れて判定ボタンをクリックすると、「国内」「海外」「IT/経済」「スポーツ」「芸能」のうち、一番近いカテゴリを出力するサイトを作りました。
50000件のニュース記事を学習させて、テストを回したときは93.2%の正答率だったので、そこそこ精度はあるはず。
実装
Facebookが無料で公開している自然言語の機械学習ツールことFasttextを使いました。
facebookresearch/fastText: Library for fast text representation and classification.
これはpythonのツールではなくバイナリのコマンドなので、前処理さえしてしまえばPythonのコードを一切書かずに文章のカテゴリ推定ができます。
大まかな手順は以下
- 某ニュースサイトから記事をせっせとスクレイピング
- 文章をMecabで名詞だけ抽出し、分かち書きをしてfasttextが読める形に加工
- 記事50000件のうち、1カテゴリにつき9000件を学習用、1000件をテスト用に
- fasttextで学習
- 出来上がったモデルでテスト
学習自体は速く、10分程度で終わります。(もちろんスペックにもよりますが)
fasttextについて
インストールはcloneしてmakeするだけ
$ git clone https://github.com/facebookresearch/fastText.git
$ cd fastText
$ make
fasttext自体には色々機能があるのですが、ここでは文章分類に絞って述べます
まずfasttextが読み込める形に文章を加工します。形式は以下の通り
__label__ラベル名 , 単語をスペース区切りにした本文
ここでは学習用のテキストをnews_train.txt,テスト用をnews_test.txtとします。例えばnews_train.txtはこんな感じです。
news_train.txt
__label__sports , 陸上 日本 学生 対校 選手権 福井 県営 陸上 競技 場 日...
__label__dom , 国会 首相 ....
これをfasttextに読みませて学習します。
./fasttext supervised -input news_train.txt -output news -dim 100 -lr 0.1 -wordNgrams 2 -minCount 1 -bucket 10000000 -epoch 300 -thread 4
細かいパラメータは公式ドキュメントが一番詳しいので割愛(
学習が完了すると同一ディレクトリにnews.binとnews.vecができているはずです。
今度はそれを使って精度を検証します。
./fasttext test news.bin news_test.txt
機械学習の細かい実装をしなくてもサクッと文章分類できるので、fasttextもっと広まってもいんじゃないかと思いました。(こなみ)