はじめに
機械学習でよく扱われるタスク用の実装をまとめました。Pandasデータフレームの扱い方・データの可視化・前処理・モデル学習などにおいて、汎用的な部分が多いので、他のタスクにも転用可能だと思います。
花の品種分類
Iris(アヤメ)には以下の4つの測定値が含まれており、これらの情報から品種を予測するタスクを解いていきます。
1 Sepal Length(cm) がく片の長さ
2 Sepal Width がく片の幅
3 Petal length 花びらの長さ
4 petal Width 花びらの幅
※Petal(花びら)
※Sepal(がくの長さ)
正解値(ラベル: 品種の名称)は、こちらです。
0: Setosa
1: Versicolor
2: Versinica
この3値分類タスクを行う上でまず、標準化とOneHotEncode、データの分割を行います。
標準化とは、身長・体重のようなスケール(データ値の範囲)の異なる複数の変数について、平均が0・分散が1になるような変換処理です。これを行うことで、機械学習モデルが計算しやすくなるメリットがあります。以下のサイトに詳しく書かれています。
OneHotEncodeはデータ整数型のデータをバイナリ型のデータに変換する処理です。モデルが予測を出力する場合、整数ではなく[0, 0, 1]のように正解ラベルのみ1となるため、この処理が必要になります。以下のサイトに詳しく書かれています。
import pandas as pd
import seaborn as sns
import numpy as np
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.model_selection import train_test_split
iris = sns.load_dataset('iris')
# 二重括弧にするとDataFrame型を維持できる
y = iris[['species']]
X = iris.iloc[:, :-1]
# One hot encoding
enc = OneHotEncoder(sparse=False)
y = enc.fit_transform(y)
# 分割
X_train, X_test, y_train, y_test = train_test_split(X, y)
# スケーリング(学習データのみの平均・分散を保持する)
# https://stackoverflow.com/questions/63037248/is-it-correct-to-use-a-single-standardscaler-before-splitting-data
scaler = StandardScaler().fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
# 学習データの平均・分散を取り出す
mean = scaler.mean_
std = np.sqrt(scaler.var_)
# display(X)
# 2つの変数を組み合わせた図
# sns.pairplot(iris, hue="species")
# データの分布
# X.plot.kde()
標準化前のデータセットの中身 display(X) はこんな感じです。
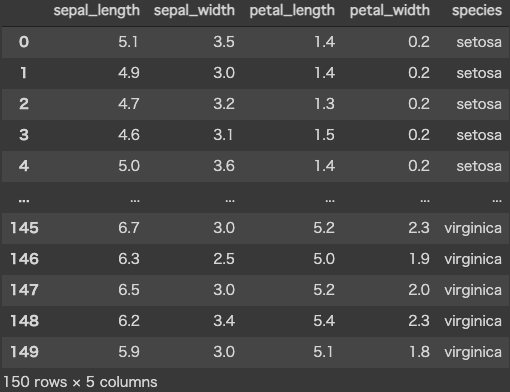
2変数を組み合わせた図 sns.pairplot() を用いると次のような図が描けます。左上から右下にかけて対角線上にあるグラフは各カテゴリに関する変数のヒストグラム(頻度)を表しています。その他は2変数を組み合わせた散布図であり、その全てのパターンを一覧表示できます。
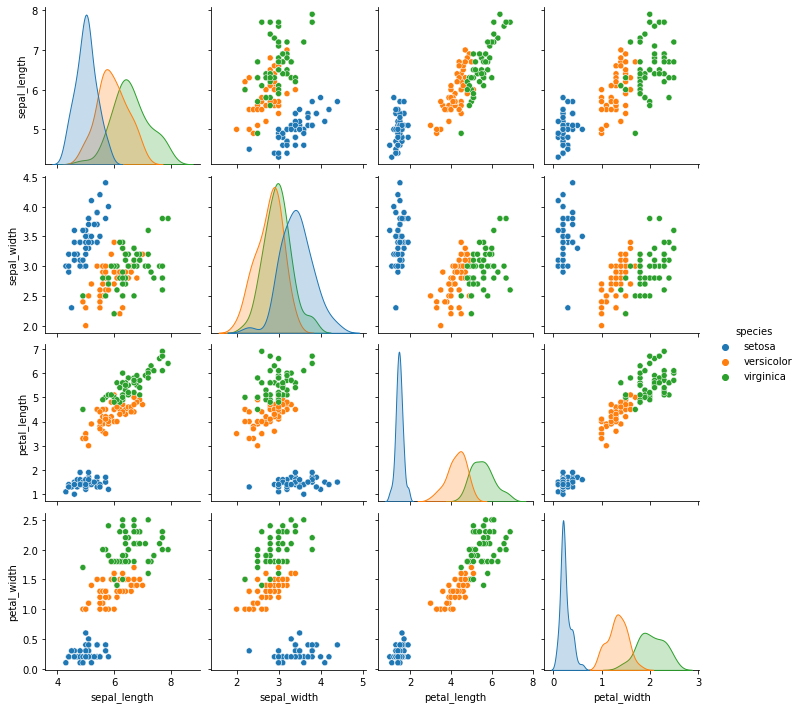
標準化して X.plot.kde() で表示した分布はこのようになります。
加工したデータセットの学習を行います。
from keras.layers import Input, Dense
from keras.models import Model
inputs = Input(shape=X_train.shape[1:])
x = Dense(32, activation='relu')(inputs)
x = Dense(8, activation='relu')(x)
x = Dense(3, activation='softmax')(x)
model = Model(inputs, x)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics='accuracy')
model.fit(X_train, y_train, batch_size=16, epochs=20, validation_split=0.1)
学習したモデルを元にテストデータの評価を行います。
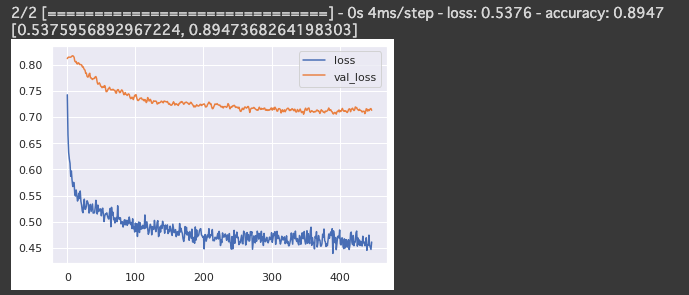
pd.DataFrame(history.history).plot()
# 評価
model.evaluate(X_test, y_test)
accuracyは 89.47% でした。
タイタニック生存者予測
以下のデータ(5行を抜き出し列を折り返して表示)から数値データだけを取り出し、生存者予測(2クラス分類) を行います。
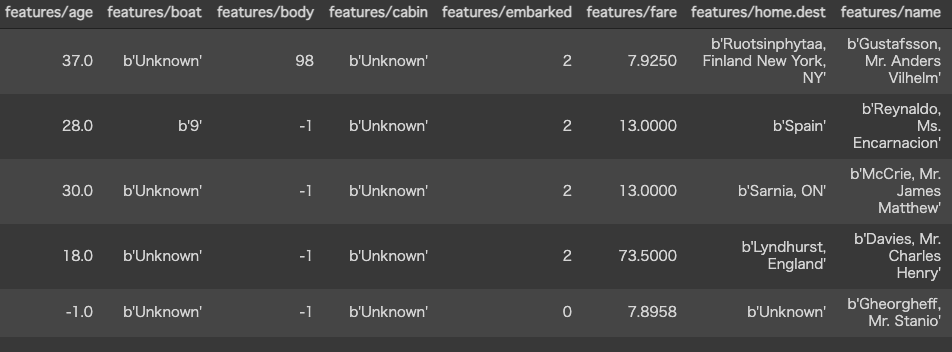
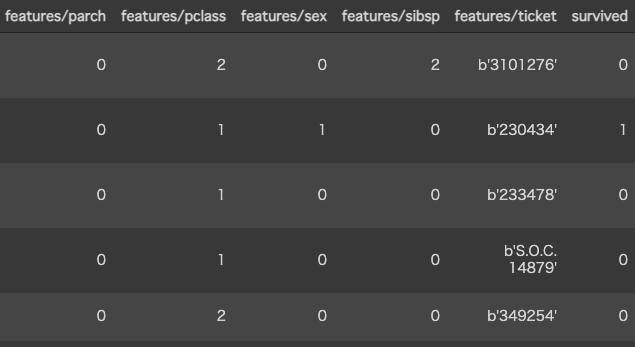
import tensorflow.compat.v2 as tf
import tensorflow_datasets as tfds
from sklearn.preprocessing import StandardScaler
from keras.layers import Input, Dense
from keras.models import Model
# Construct a tf.data.Dataset
ds = tfds.load('titanic', split='train', shuffle_files=True)
df = tfds.as_dataframe(ds)
# 詳細を確認したい場合
# display(df.head())
# display(df.describe())
# df.isnull().sum()
# print(len(df))
# 列の要素をカウントする
# item_counts = df["features/parch"].value_counts(normalize=False)
# print(item_counts)
# 数値データだけ取り出す
X = df.loc[:, ['features/age', 'features/body', 'features/embarked', 'features/fare', 'features/parch', 'features/pclass', 'features/sex', 'features/sibsp']].to_numpy()
y = df.loc[:, ['survived']].to_numpy()
# 分割
X_train, X_test, y_train, y_test = train_test_split(X, y)
# スケーリング(学習データのみの平均・分散を保持する)
# https://stackoverflow.com/questions/63037248/is-it-correct-to-use-a-single-standardscaler-before-splitting-data
scaler = StandardScaler().fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
# 学習データの平均・分散を取り出す
mean = scaler.mean_
std = np.sqrt(scaler.var_)
# モデルの学習
inputs = Input(shape=X_train.shape[1:])
x = Dense(32, activation='relu')(inputs)
x = Dense(8, activation='relu')(x)
x = Dense(1, activation='sigmoid')(x)
model = Model(inputs, x)
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])
history = model.fit(X_train, y_train, batch_size=32, epochs=20, validation_split=0.1)
# 精度のプロット
pd.DataFrame(history.history).loc[:, ['loss', 'val_loss']].plot()
pd.DataFrame(history.history).loc[:, ['acc', 'val_acc']].plot()
# テストデータの精度
model.evaluate(X_test, y_test) # 80.18%
訓練データと検証データの正解率推移
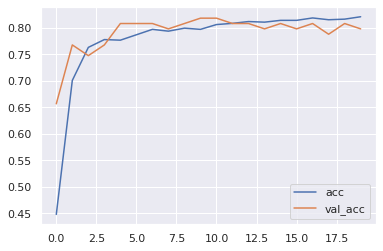
カリフォルニア住宅価格予測
こちらのタスクは、カリフォルニアの住宅価格を、以下のデータをもとに予測するものです。
(MedInc)median income in block-収入の中央値
(HouseAge)median house age in block-ブロック内の家の中央年齢
(AveRooms)average number of rooms-平均部屋数
(AveBedrms)average number of bedrooms-ベッドルームの平均数
(Population)block population-ブロック人口
(AveOccup)average house occupancy-平均住宅占有率
(Latitude)house block latitude-家屋の緯度
(Longitude)house block longitude-ハウスブロックの経度
早速、データセットの事前加工を行います。
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 標準化すると、直接価格を予測するよりも精度・学習速度ともに有利
# 簡単のため訓練データとテストデータを混ぜてmean, varを求める
def scale_data(df):
scaler = StandardScaler()
df.iloc[:, :] = scaler.fit_transform(df) # 全カラムを標準化
df.plot.kde(xlim=(-3, 3))
mean = scaler.mean_[-1]
std = np.sqrt(scaler.var_)[-1]
X = df.iloc[:, :-1].to_numpy()
y = df["median_house_value"].to_numpy()
X_train, X_test, y_train, y_test = train_test_split(X, y)
return X_train, X_test, y_train, y_test, mean, std
df = pd.read_csv('sample_data/california_housing_train.csv')
X_train, X_test, y_train, y_test, mean, std = scale_data(df)
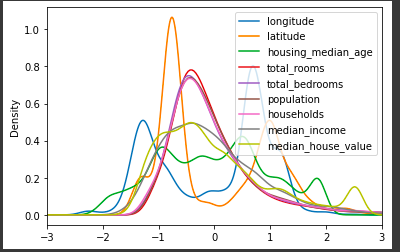
次に、モデルを用意して学習させます。
from keras.layers import Input, Dense, Dropout
from keras.models import Model
# from tensorflow.keras.callbacks import EarlyStopping
inputs = Input(shape=X_train.shape[1:])
x = Dense(8, activation='relu')(inputs)
x = Dense(4, activation='relu')(x)
x = Dropout(0.5)(x)
x = Dense(1)(x)
model = Model(inputs, x)
model.summary()
model.compile(loss="mae", optimizer="adam")
# early_stop = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=10)
history = model.fit(X_train, y_train, batch_size=128, epochs=30, verbose=1, validation_split=0.2)
事前に求めたmean, stdをもとに、住宅価格を予測します。
from sklearn.metrics import mean_absolute_error
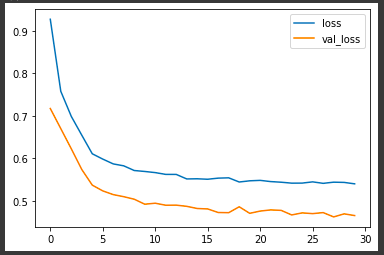
pd.DataFrame(history.history).plot()
predictions = model.predict(X_test)
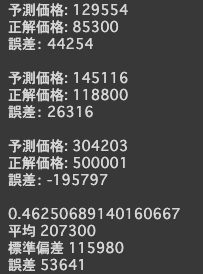
for i in range(3):
print("予測価格:", int(predictions[i][0] * std + mean))
print("正解価格:", int(y_test[i] * std + mean))
print("誤差:", int((predictions[i][0] - y_test[i]) * std))
print('')
mae_loss = mean_absolute_error(y_test, predictions)
print(mae_loss)
print("平均", int(mean))
print("標準偏差", int(std))
print("誤差", int(mae_loss * std))
おわりに
機械学習でよく扱われるタスク用の実装をまとめました。今回タイタニックのタスクでは捨てられるデータもあったため、今後は表データと共に自然言語を扱うタスクに注力していきたいです。