概要
本論文では、NL文と(半)構造化テーブルの表現を合同で学習する事前学習済みLMであるTABERTを紹介する。TABERTは2600万個の表とその英語文脈からなる大規模なコーパスで学習される。実験では、TABERTを特徴表現層として用いたニューラル意味解析器が、弱教師あり意味解析ベンチマークであるWIKITABLEQUESTIONSで最良の結果を達成し、テキストtoSQLデータセットのSPIDERでも競争力のある性能を発揮することが分かった。
ACL 2020
第一著者:Pengcheng Yin
団体:Carnelgie Mellon University, Facebook AI Research
提案法

Content Snapshot
データベーステーブルは大きいので、すべてを使うにはTransformerには重い。そこで、セルの値から必要な行だけ抽出するようにする。手法としては、utterance (上の表の In which~) と表の各行の間でn-gramでの一致度を調べて一致度が高い順にK個の行を抽出する。この手法は複数行から情報を引っ張ってくるようなタスクにも有効となる。
Row Linearization
得られた行を一行ずつutteranceと結合していくことを考える。Figure 1の(B)にあるTransformerの入力部分のように、カラム名 | real or text | セルの値 を[SEP]で結合してTransformerに入力できるようにする。
Vertical Self-Attention Mechanism
Figure 1の(B)にあるCell-wise Poolingは カラム名 | type (real or text) | セルの値 を平均プーリングして一つのベクトルにしている。
Utterance and Colum Representations
(C)のvertical attentionは、(B)の操作を各行に対して行なったときの出力ベクトル列を垂直方向に平均している。こうして得られたベクトル列 $c_j$ は、後続のfinetuningタスクに用いる。
Training Data
テキストと構造化データ(表データ)を含む大規模なデータがなかったため、代わりに半構造化データを作成した。English WikipediaとCommonCrawlから収集した大規模テーブルデータであるWDC WebTable Corpusを用いた。
Pretrain
入力の一部にマスクをして出力されたベクトル列 $c_j$ からマスクの予測を行う。セルの値からマスクした列名とtypeを予測するタスクである Masked Column Prediction (MCP) と、コンテキストからマスクしたセルの値を予測するタスクである Cell Value Recovery (CVR) を行った。
Finetuning
以下のようなquestionとtableから表の答えを得るタスクであるWikitablequestionsを用いた。

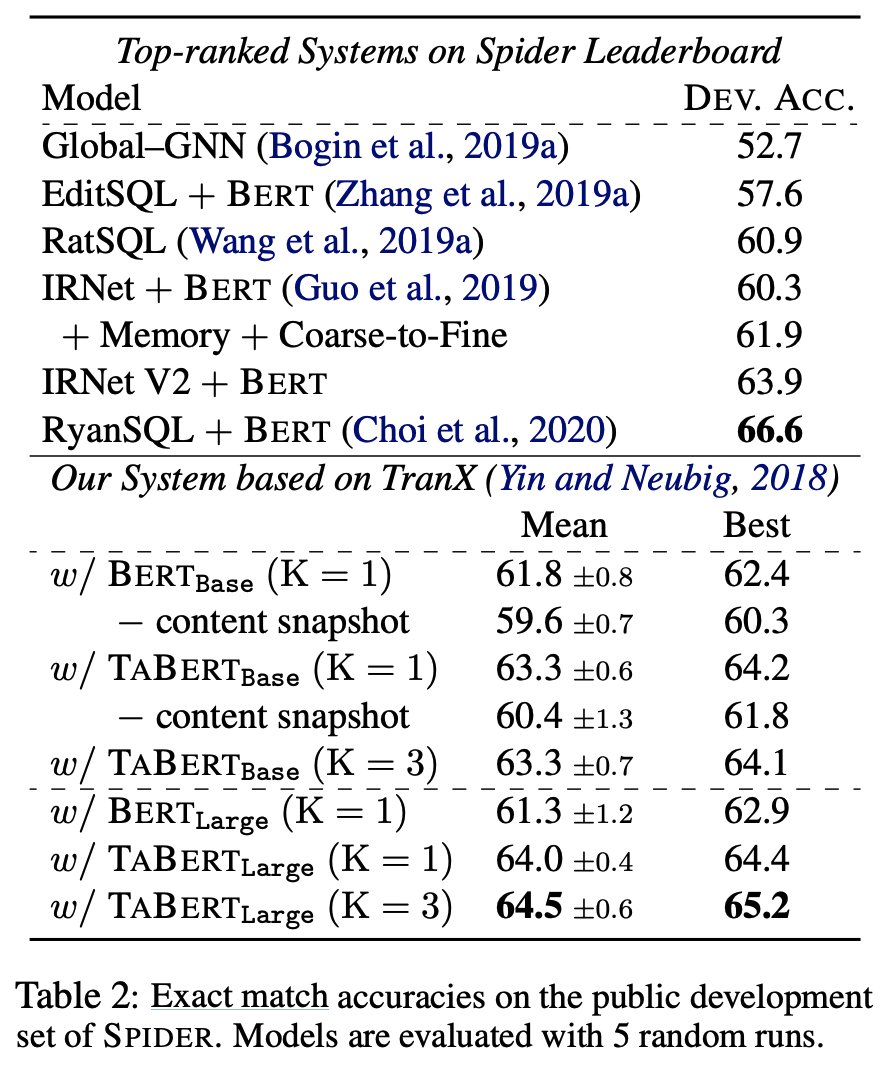
また、Spiderデータセットを用いてテキストからSQL文を予測するタスクを行った。評価はExact match accuracyで行った。

結果