はじめに
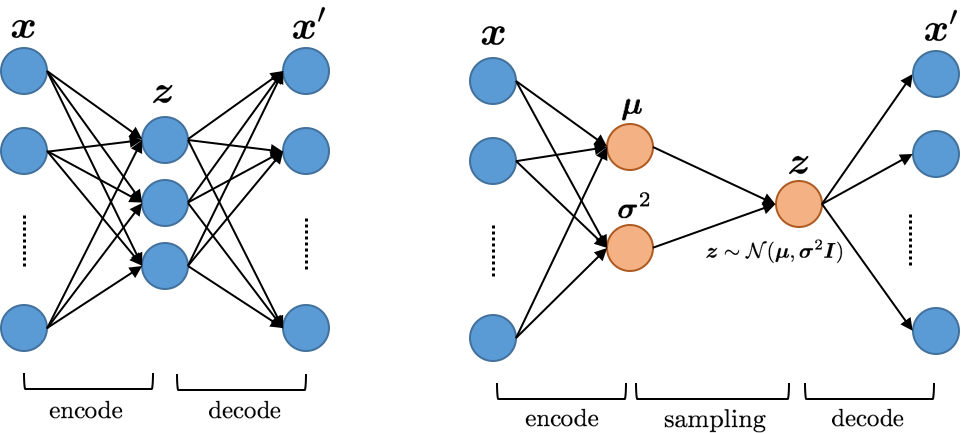
オートエンコーダ(AE)とは、左下の画像のように潜在変数 z にエンコードした後、もとの入力と一致するようにデコードするネットワークのことです。潜在変数 z は入力 x を圧縮したものだと考えることができます。一方で、z の存在する潜在空間がどのように使われているかは分からないため、適当な z をデコードしても意味のあるデータは生成されません。
変分オートエンコーダ(VAE)は、右下の画像のように、潜在変数 z がある確率分布に従うことを仮定しています。学習時には x' が元の x と一致するように、かつ z が仮定した分布に近づくようにKL損失を設定してパラメータを更新します。これによって、仮定した分布に従う z をデコードすると、学習したデータを生成することができます。学習時には posterior collapse と呼ばれる、KL損失を小さくしようとするあまりに仮定した分布と完全に一致してしまい、潜在変数 z を無視したデコードが行われてしまう現象が起こらないように気をつける必要があります。
なお、VAEについてはこちらのqiita記事が非常に詳しいです。
VAEによる文生成
[Bowman+, 2015]はVAEの枠組みを文生成に適用しようと試みた研究です。
VAEの学習モデルは以下となります。潜在変数 z はガウス分布に従うことを仮定しています。

ところで、ガウス分布に従う z1, z2 を 0 ~ 1 の t で内分するとそれもガウス分布に従います。
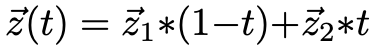
潜在空間を連続的に横断する複数の z から生成された文は次のようになります。

VAEの学習がうまくいったとすると、これらの文は学習データの特徴を捉えた何らかの文だということになります。似た単語を含む文は潜在空間で近くからデコードされているようですが、意味的に似ているとは限りません。(似た意味の文が潜在空間で近くにくるような学習方法をとっていないからです)
著者はテキストの学習にVAEを用いると、posterior collapse を起こしやすいと言っています。デコーダの入力に対してランダムな単語をUNKに変換することで軽減しているそうですが、そもそも学習時にデコーダにも文の情報を渡してしまうと潜在変数の情報を見なくなる posterior collapse が起こりやすくなるのは納得です。
おわりに
GANによる文生成もそうですが、離散的な単語列を学習する際にどうしてもデコーダ側で1単語ずつ生成しなければいけないことが本質的な問題だと感じました。CNNのdeconvolutionのように一発で単語列を生成できたら文生成も可能になりそうですが、そんなことしたら文法崩壊必至なので難しいです。ポジションエンベッドを応用してなんとかなりそうな気はしています。