1 学習素材集め
学習させたい画像を用意する。50枚くらい用意すると良い。

2 ラベル付け
Roboflowというサービスを使って、それぞれの写真のオブジェクトにラベル付けしていく
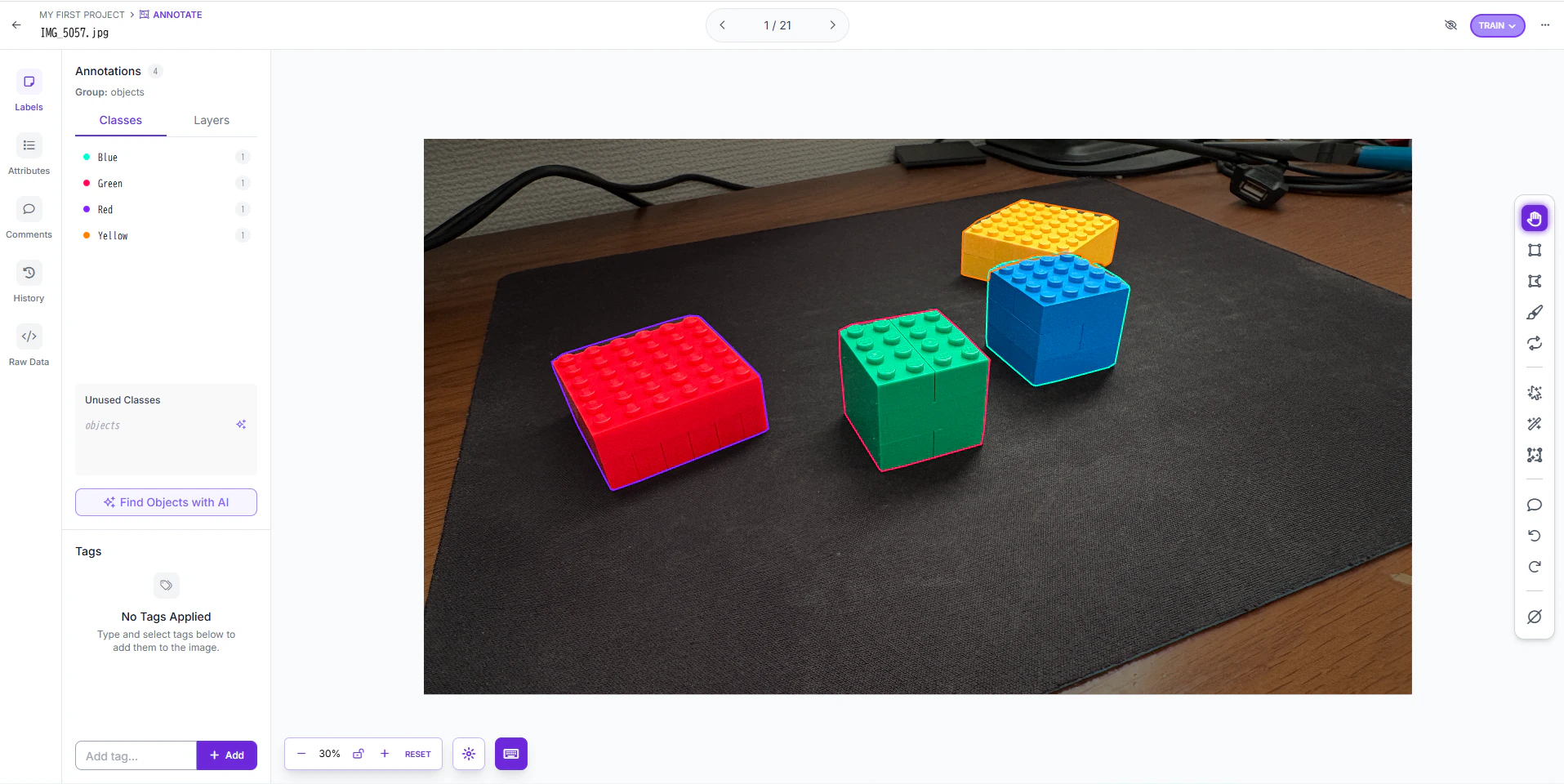
全ての写真に対して行う
3 画像の水増し
今ある画像の明るさやぼかし具合を変えて新たな画像として登録し、画像データを水増しする。
New Dataset Version →③PreprocessiogのResize 640×640 →④Augmentationのadd Augmentation StepからBrightnessとBlurをそれぞれかける→Generate
4 データのダウンロード
Versionsの画面でDownload
フォーマットをYOLOv8、Show download code
出てきたコードをコピー
5 学習
Google colabで行う
ランタイムのタイプをGPUに切り替える
初めに
!pip install ultralytics
次に先ほどコピーしたコードを走らす
from ultralytics import YOLO
# ラズパイZeroでも動く超軽量モデル「YOLOv8n (Nano)」を呼び出す
model = YOLO('yolov8n.pt')
# 学習の実行(epochs=50は「50回反復練習する」という意味です)
results = model.train(data=dataset.location + '/data.yaml', epochs=50, imgsz=640)
学習データが少ないとき(20個ほど)は、画像データがTrainではなく、Validになっている時がある。その場合は上のコードが走らない。その時には以下のコードを先に実行する。
import yaml
# データセットの設定ファイル (data.yaml) の場所
yaml_path = dataset.location + '/data.yaml'
# 設定ファイルを読み込む
with open(yaml_path, 'r') as f:
data = yaml.safe_load(f)
# Valid(テスト用)のパスを、Train(学習用)と全く同じ場所に書き換える
data['val'] = data['train']
# 上書き保存
with open(yaml_path, 'w') as f:
yaml.dump(data, f)
print("設定ファイルの修正が完了しました!もう一度学習セルを実行してください。")
6 学習データのダウンロード
フォルダの階層を以下の順番でクリックして開いていきます。
runs > detect > train > weights
その中に best.ptがあるのでそれをダウンロード
7 実行(PC)
一旦PC上で動かしてみる
PCのターミナルで以下のコードを実行する
pip install ultralytics opencv-python
1つのフォルダにbest.ptと以下のコードimage_test.pyとテスト用の画像を入れる
import cv2
from ultralytics import YOLO
# ==========================================
# 設定部分(ファイル名を自分の環境に合わせて変更してください)
MODEL_PATH = "best.pt" # ダウンロードしたAIモデル
INPUT_IMAGE = "test_photo.jpg" # 判定したい元の画像
OUTPUT_IMAGE = "result_photo.jpg" # 保存する結果の画像名
# ==========================================
print("AIモデルを読み込み中...")
model = YOLO(MODEL_PATH)
# 1. 画像を読み込む
print(f"画像 '{INPUT_IMAGE}' を読み込んでいます...")
img = cv2.imread(INPUT_IMAGE)
if img is None:
print("エラー: 画像が見つかりません。ファイル名と場所を確認してください。")
exit()
# 2. AIで推論(物体検出)を実行
# conf=0.5 は「自信度50%以上のものだけを採用する」という意味です
print("判定中...")
results = model(img, conf=0.5)
# 3. 検出結果の枠(バウンディングボックス)と名前を画像に描き込む
annotated_img = results[0].plot()
# 4. 結果を新しい画像ファイルとして保存(エクスポート)する
cv2.imwrite(OUTPUT_IMAGE, annotated_img)
print(f"大成功!結果を '{OUTPUT_IMAGE}' として保存しました。")
# 画面にも一応表示して確認する
cv2.imshow("Result", annotated_img)
cv2.waitKey(0) # 何かキーを押すとウィンドウが閉じます
cv2.destroyAllWindows()
ターミナルで以下のコードを実行
python image_test.py

8実行(Raspberry Pi zero 2 W)
下準備としてラズパイとPCのデータのやり取りを楽にするためにWinSCPを導入する。
ラズパイでは先ほどPCで走らせたのと同じ方式では走らない。
先ほどのGoogle Colabの画面で以下のコードを続きとして走らせる。
from ultralytics import YOLO
import os
# 学習結果のフォルダを探して、最新の best.pt を読み込む
# 通常は 'runs/detect/train/weights/best.pt' にあります
model_path = 'runs/detect/train/weights/best.pt'
if os.path.exists(model_path):
model = YOLO(model_path)
# 本物の学習データを含んだ状態で ONNX に変換
model.export(format='onnx')
print("✅ 変換成功!左のフォルダから best.onnx をダウンロードしてください")
else:
print("❌ エラー:学習済みの best.pt が見つかりません。学習(model.train)が完了しているか確認してください")
これで.onnxファイルができる。
ラズパイに1つフォルダを作り、以下のコードpi_ai_test.py、onnxファイル、テスト用の画像を入れる
import cv2
import numpy as np
# ==========================================
# 設定部分
MODEL_PATH = "best.onnx" # ⬅️ TFLiteではなくONNXを使います!
INPUT_IMAGE = "test_photo.jpg"
OUTPUT_IMAGE = "pi_result.jpg"
CONF_THRESH = 0.5
# ★重要★ Roboflowで設定したクラス名(色)の順番に合わせてください
# 例: ['Red', 'Blue', 'Green', 'Yellow']
CLASSES = ['Red', 'Blue', 'Green', 'Yellow']
# ==========================================
print("🚀 OpenCV内蔵のAIエンジンでモデルを起動中...")
# OpenCVの機能だけでONNXモデルを直接読み込む!
net = cv2.dnn.readNetFromONNX(MODEL_PATH)
# --- 1. 画像の読み込み ---
print(f"画像 '{INPUT_IMAGE}' を分析しています...")
img = cv2.imread(INPUT_IMAGE)
if img is None:
print("エラー: 画像が見つかりません。")
exit()
orig_h, orig_w = img.shape[:2]
# --- 2. AI向けの前処理と推論実行 ---
# 画像を640x640に変換し、AIが読めるデータ(blob)にする
blob = cv2.dnn.blobFromImage(img, 1/255.0, (640, 640), swapRB=True, crop=False)
net.setInput(blob)
print("AIが計算中...")
outputs = net.forward() # ここで推論!
# --- 3. 結果の解読 ---
predictions = np.squeeze(outputs).T
boxes = []
scores = []
class_ids = []
# 画像の縮尺を計算
x_factor = orig_w / 640.0
y_factor = orig_h / 640.0
for pred in predictions:
classes_scores = pred[4:]
class_id = np.argmax(classes_scores)
score = classes_scores[class_id]
if score > CONF_THRESH:
cx, cy, w, h = pred[0], pred[1], pred[2], pred[3]
# 枠の座標を元の画像サイズに引き伸ばす
x = int((cx - w / 2) * x_factor)
y = int((cy - h / 2) * y_factor)
width = int(w * x_factor)
height = int(h * y_factor)
boxes.append([x, y, width, height])
scores.append(float(score))
class_ids.append(class_id)
# 枠のダブりを消す(NMS処理)
indices = cv2.dnn.NMSBoxes(boxes, scores, CONF_THRESH, 0.4)
# --- 4. 結果の出力 ---
print("\n=== 🎯 判定結果 ===")
if len(indices) > 0:
for i in indices.flatten():
x, y, w, h = boxes[i]
class_id = class_ids[i]
score = scores[i]
class_name = CLASSES[class_id] if class_id < len(CLASSES) else f"Class{class_id}"
print(f"発見: {class_name} (自信度: {score*100:.1f}%) -> 座標 X:{int(x+w/2)}, Y:{int(y+h/2)}")
# 画像に枠を描画
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.putText(img, f"{class_name} {score:.2f}", (x, max(10, y - 10)), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2)
else:
print("ブロックは見つかりませんでした。")
cv2.imwrite(OUTPUT_IMAGE, img)
print("==================\n")
print(f"結果を '{OUTPUT_IMAGE}' として保存しました!")
ラズパイのターミナルで
python3 pi_ai_test.py
