本当にただタイトル通りにやりたいだけですが、これが意外と面倒。
まず CSV のエクスポートですが、AWS マネジメントコンソールにログイン後、GUI で実行できる機能があるにはあります。
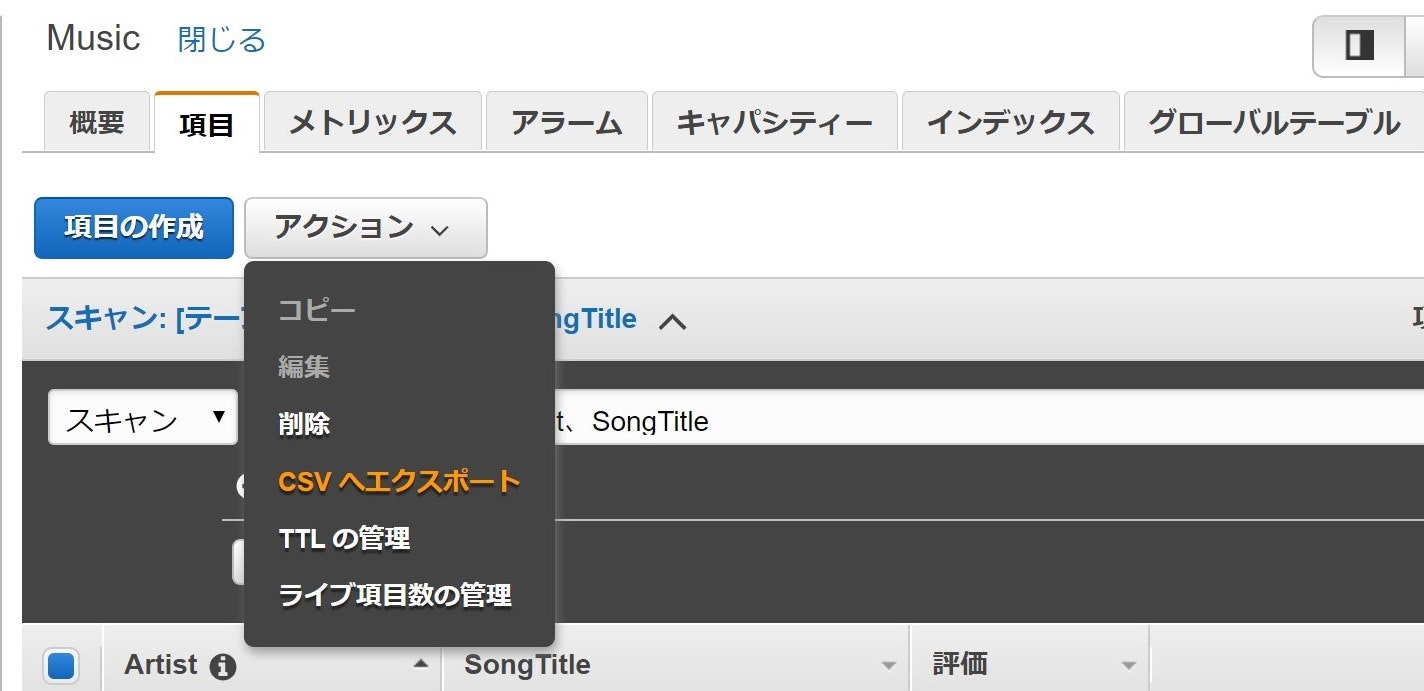
が、こちらの機能、画面上に一度に表示できる数(最大100?)が限界のようで、大量データを全量となるとぽちぽちページ送りをして何回も CSV をダウンロードする羽目になりそうです。めんどくさいですね。
また、インポートに関してはそもそもそういった機能はなさそう。どうしましょ。。
調べてみると、大きく2通りの解決方法がありそうです。
- AWS Data Pipeline を使う
- ツール(有償)を使う
Data Pileline は入出力先として s3 が必要なうえ、JSON ⇔ CSV の変換はやってあげないといけないみたいですね。
ツールのほうは良さそうなのがありますが、このためだけにお金をかけるのはちょっと・・・。
と、前置きが長くなりましたが、それならば実装しちゃいましょう!
前提
以下の環境で実装していきます。
- Google Colaboratory
- DynamoDBの読み書き権限のあるユーザーのアクセスキーとシークレットキーがある
- DynamoDB のチュートリアル「NoSQL テーブルを作成してクエリを実行する」のステップ2の状態のテーブルがある(↓こんな感じ)
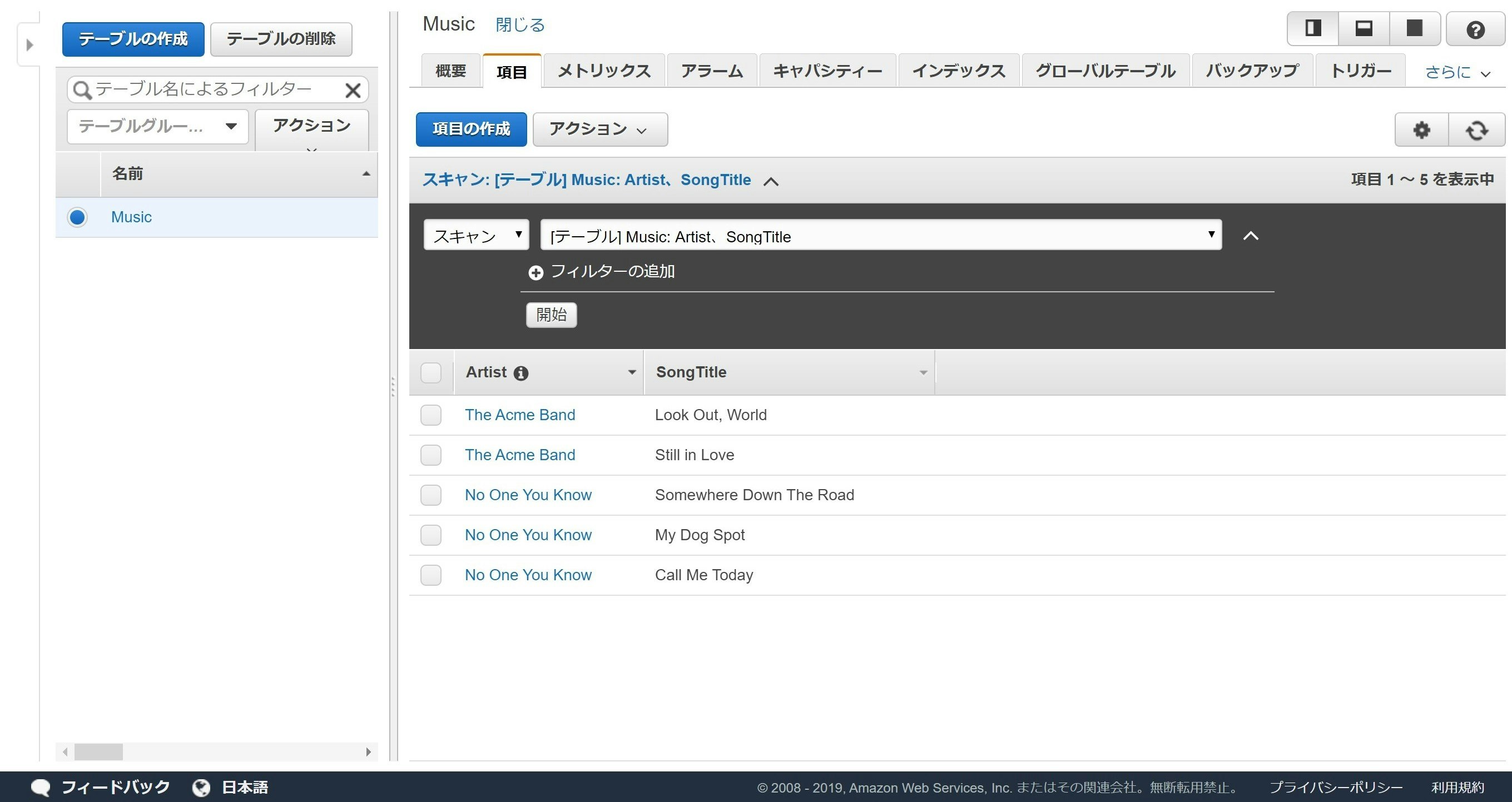
このテーブルのデータを CSV でローカルに保存すること、およびローカルにある CSV 形式のデータをこのテーブルに追加することを目指します。
データの確認
まずは今あるデータを colaboratory で確認してみます。
認証情報をセットしておきましょう。
リージョンは東京だと ap-northeast-1 となります。
# 認証情報
aws_access_key_id='XXXXXXXXXXXXXXXXXXX'
aws_secret_access_key='XXXXXXXXXXXXXXXXXXX'
# テーブル名
table_name = 'Music'
# リージョン
region_name = 'XXXXXXXXXXXXXXXXXXX'
AWS に接続するので、以下のインポートが必要ですね。
# インポート
from boto3.session import Session
以下を実行して colaboratory に出力してみます。
# テーブルを取得する関数
def get_dynamo_table(key_id, access_key, table_name, region_name):
session = Session(
aws_access_key_id=key_id,
aws_secret_access_key=access_key,
region_name=region_name
)
dynamodb = session.resource('dynamodb')
dynamo_table = dynamodb.Table(table_name)
return dynamo_table
# データ確認
dynamo_table = get_dynamo_table(aws_access_key_id, aws_secret_access_key, table_name, region_name)
dynamo_table.scan()
以下のような結果になればOKです!
{'Count': 5,
'Items': [{'Artist': 'No One You Know', 'SongTitle': 'Call Me Today'},
{'Artist': 'No One You Know', 'SongTitle': 'My Dog Spot'},
{'Artist': 'No One You Know', 'SongTitle': 'Somewhere Down The Road'},
{'Artist': 'The Acme Band', 'SongTitle': 'Look Out, World'},
{'Artist': 'The Acme Band', 'SongTitle': 'Still in Love'}],
'ResponseMetadata': {'HTTPHeaders': {'connection': 'keep-alive',
'content-length': '389',
'content-type': 'application/x-amz-json-1.0',
'date': 'Sat, 12 Oct 2019 04:23:31 GMT',
'server': 'Server',
'x-amz-crc32': '272980438',
'x-amzn-requestid': 'ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890'},
'HTTPStatusCode': 200,
'RequestId': 'ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890',
'RetryAttempts': 0},
'ScannedCount': 5}
CSV をインポート
先ほどのテーブルに以下のデータを追加してみましょう。
| Artist | SongTitle | 評価 |
|---|---|---|
| Blue Day | Majority | 4 |
| Quuun | We Will Knock You | |
| BAAB | Dancing King | 3 |
| Balloon5 | Read Only Memories | 4 |
| Hotplay | Fax You | |
| スパッツ | 海も泳げるはず | 5 |
| クイーンアンドプリンセス | シンデレラボーイ | 4 |
| 大阪事件 | 黄色日和 | |
| 米酢玄人 | カボス | 3 |
| いろは坂44 | こないでリンス | |
| こんな感じの表をエクセルで作って CSV として保存したファイルを使います。 | ||
| また、先ほど確認したデータにはない「評価」というフィールドが入っていますね。このように元のテーブルにないフィールドが来ても対応できるような実装をしていきます。 |
データを確認したものとは別のノートブック(ipynb)に実装していくので、まずは先ほどと同様の認証情報をセットし、以下をインポートしておきます。
# インポート
from boto3.session import Session
from google.colab import files
import pandas as pd
import csv
続いて以下を実行してファイルをアップロードしましょう。
# ファイルアップロード
uploaded_file = files.upload()
中身を pandas の read_csv で確認してみます。
# データ確認(pandas)
key = [x for x in uploaded_file.keys()]
data = pd.read_csv(key[0])
data
以下のような結果になります。
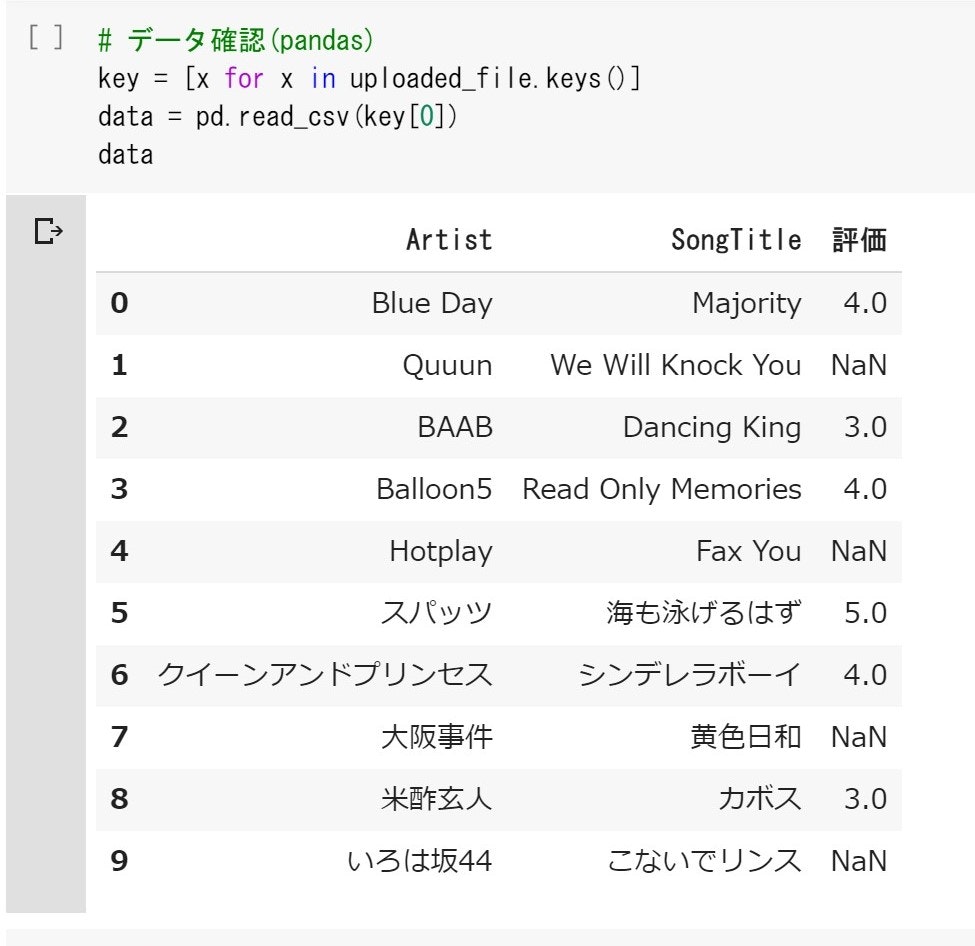
「評価」の列がいくつかNaNになっていることが分かりますね!
今度は cvs モジュールの DictReader で読み込んでみましょう。
ちなみに encoding が utf-8-sig なのは、CSV ファイルに BOM がついているからです。
# データ確認(csv)
with open(key[0], 'r', encoding = 'utf-8-sig') as f:
for line in csv.DictReader(f):
print(line)
結果↓
OrderedDict([('Artist', 'Blue Day'), ('SongTitle', 'Majority'), ('評価', '4')])
OrderedDict([('Artist', 'Quuun'), ('SongTitle', 'We Will Knock You'), ('評価', '')])
OrderedDict([('Artist', 'BAAB'), ('SongTitle', 'Dancing King'), ('評価', '3')])
OrderedDict([('Artist', 'Balloon5'), ('SongTitle', 'Read Only Memories'), ('評価', '4')])
OrderedDict([('Artist', 'Hotplay'), ('SongTitle', 'Fax You'), ('評価', '')])
OrderedDict([('Artist', 'スパッツ'), ('SongTitle', '海も泳げるはず'), ('評価', '5')])
OrderedDict([('Artist', 'クイーンアンドプリンセス'), ('SongTitle', 'シンデレラボーイ'), ('評価', '4')])
OrderedDict([('Artist', '大阪事件'), ('SongTitle', '黄色日和'), ('評価', '')])
OrderedDict([('Artist', '米酢玄人'), ('SongTitle', 'カボス'), ('評価', '3')])
OrderedDict([('Artist', 'いろは坂44'), ('SongTitle', 'こないでリンス'), ('評価', '')])
1行1行を OrderedDict の形式で読み込むことができます。
値が空の部分でもキーはちゃんと入るんですね~
これなら boto3 の table.batch_writer() で行けそうな気がします!
というわけで早速以下を試してみると・・・
# テーブル取得
def get_dynamo_table(key_id, access_key, table_name, region_name):
session = Session(
aws_access_key_id=key_id,
aws_secret_access_key=access_key,
region_name=region_name
)
dynamodb = session.resource('dynamodb')
dynamo_table = dynamodb.Table(table_name)
return dynamo_table
dynamo_table = get_dynamo_table(aws_access_key_id, aws_secret_access_key, table_name, region_name)
# データ登録
with open(key[0], 'r', encoding = 'utf-8-sig') as f:
with dynamo_table.batch_writer() as batch:
for line in csv.DictReader(f):
for d in [x for x in line.keys() if line[x]=='']:
del line[d]
batch.put_item(line)
print(line)
結果(一部)↓
/usr/local/lib/python3.6/dist-packages/botocore/client.py in _make_api_call(self, operation_name, api_params)
659 error_code = parsed_response.get("Error", {}).get("Code")
660 error_class = self.exceptions.from_code(error_code)
--> 661 raise error_class(parsed_response, operation_name)
662 else:
663 return parsed_response
ClientError: An error occurred (ValidationException) when calling the BatchWriteItem operation: One or more parameter values were invalid: An AttributeValue may not contain an empty string
エラーになってしまいました。。。
どうやら value が空で key だけっていうのはダメみたいですね。
しかたないので value が空の要素を削除します!
# 辞書から空の要素を削除
with open(key[0], 'r', encoding = 'utf-8-sig') as f:
for line in csv.DictReader(f):
for d in [x for x in line.keys() if line[x]=='']:
del line[d]
print(line)
結果↓
OrderedDict([('Artist', 'Blue Day'), ('SongTitle', 'Majority'), ('評価', '4')])
OrderedDict([('Artist', 'Quuun'), ('SongTitle', 'We Will Knock You')])
OrderedDict([('Artist', 'BAAB'), ('SongTitle', 'Dancing King'), ('評価', '3')])
OrderedDict([('Artist', 'Balloon5'), ('SongTitle', 'Read Only Memories'), ('評価', '4')])
OrderedDict([('Artist', 'Hotplay'), ('SongTitle', 'Fax You')])
OrderedDict([('Artist', 'スパッツ'), ('SongTitle', '海も泳げるはず'), ('評価', '5')])
OrderedDict([('Artist', 'クイーンアンドプリンセス'), ('SongTitle', 'シンデレラボーイ'), ('評価', '4')])
OrderedDict([('Artist', '大阪事件'), ('SongTitle', '黄色日和')])
OrderedDict([('Artist', '米酢玄人'), ('SongTitle', 'カボス'), ('評価', '3')])
OrderedDict([('Artist', 'いろは坂44'), ('SongTitle', 'こないでリンス')])
これで行けるはず!!
以下を実行してみます。
# テーブル取得
def get_dynamo_table(key_id, access_key, table_name, region_name):
session = Session(
aws_access_key_id=key_id,
aws_secret_access_key=access_key,
region_name=region_name
)
dynamodb = session.resource('dynamodb')
dynamo_table = dynamodb.Table(table_name)
return dynamo_table
dynamo_table = get_dynamo_table(aws_access_key_id, aws_secret_access_key, table_name, region_name)
# データ登録
with open(key[0], 'r', encoding = 'utf-8-sig') as f:
with dynamo_table.batch_writer() as batch:
for line in csv.DictReader(f):
for d in [x for x in line.keys() if line[x]=='']:
del line[d]
batch.put_item(line)
print(line)
エラーっぽいのが出てなければOKですね~
テーブルを確認してみましょう。
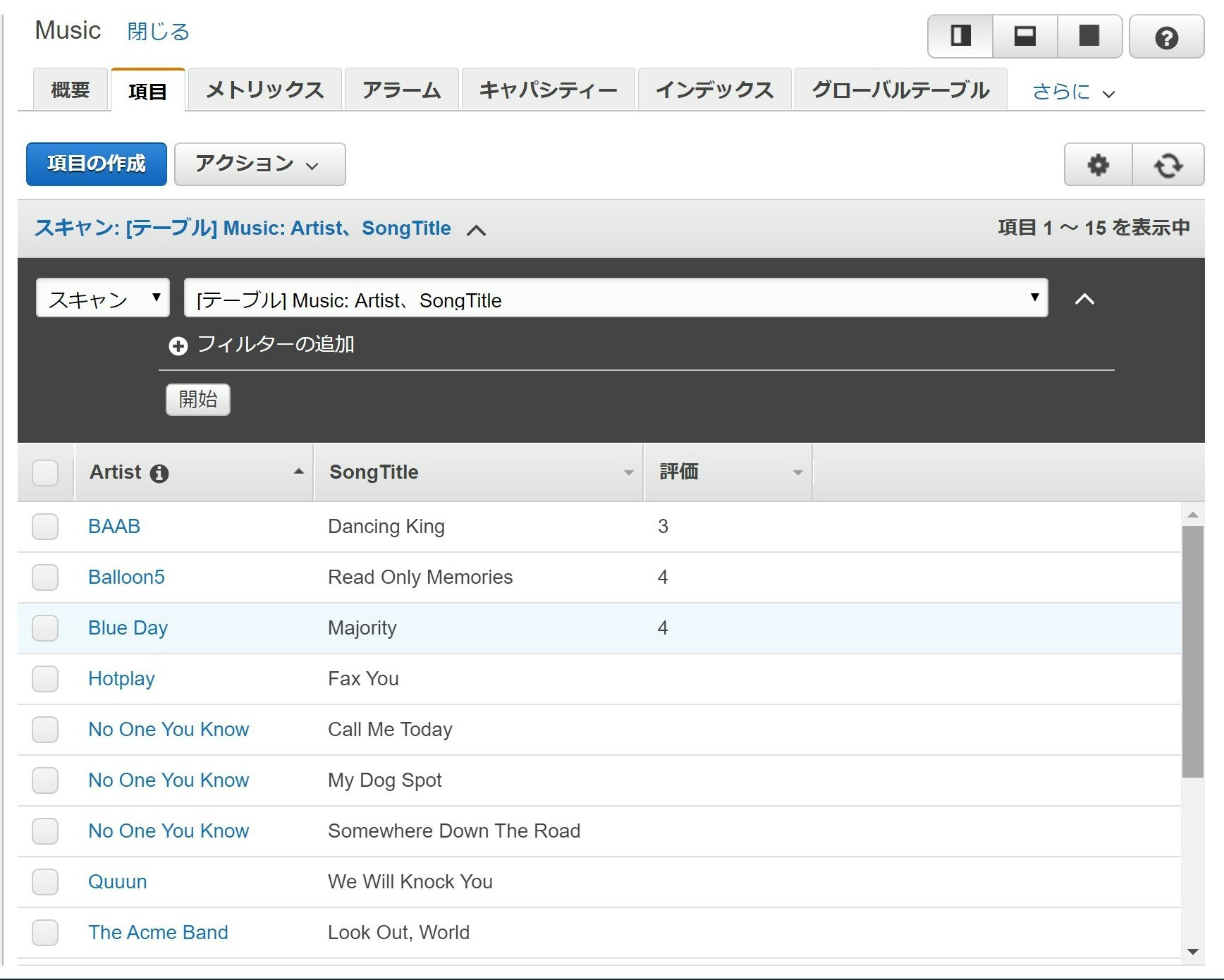
「評価」フィールドも含め、無事にインポートできたようです!
CSV にエクスポート
また別のノートブックでやっていきますので、認証情報のセットと以下のインポートを実行しておきます。
# インポート
from boto3.session import Session
from google.colab import files
import pandas as pd
先ほど DynamoDB の画面でテーブルは確認していますが、あらためて colaboratory でも以下を実行して確認しておきます。
# データ確認
def get_dynamo_table(key_id, access_key, table_name, region_name):
session = Session(
aws_access_key_id=key_id,
aws_secret_access_key=access_key,
region_name=region_name
)
dynamodb = session.resource('dynamodb')
dynamo_table = dynamodb.Table(table_name)
return dynamo_table
dynamo_table = get_dynamo_table(aws_access_key_id, aws_secret_access_key, table_name, region_name)
dynamo_table.scan()
結果↓
{'Count': 15,
'Items': [{'Artist': '大阪事件', 'SongTitle': '黄色日和'},
{'Artist': 'Blue Day', 'SongTitle': 'Majority', '評価': '4'},
{'Artist': 'Balloon5', 'SongTitle': 'Read Only Memories', '評価': '4'},
{'Artist': 'No One You Know', 'SongTitle': 'Call Me Today'},
{'Artist': 'No One You Know', 'SongTitle': 'My Dog Spot'},
{'Artist': 'No One You Know', 'SongTitle': 'Somewhere Down The Road'},
{'Artist': 'クイーンアンドプリンセス', 'SongTitle': 'シンデレラボーイ', '評価': '4'},
{'Artist': 'BAAB', 'SongTitle': 'Dancing King', '評価': '3'},
{'Artist': 'Hotplay', 'SongTitle': 'Fax You'},
{'Artist': 'The Acme Band', 'SongTitle': 'Look Out, World'},
{'Artist': 'The Acme Band', 'SongTitle': 'Still in Love'},
{'Artist': '米酢玄人', 'SongTitle': 'カボス', '評価': '3'},
{'Artist': 'いろは坂44', 'SongTitle': 'こないでリンス'},
{'Artist': 'Quuun', 'SongTitle': 'We Will Knock You'},
{'Artist': 'スパッツ', 'SongTitle': '海も泳げるはず', '評価': '5'}],
'ResponseMetadata': {'HTTPHeaders': {'connection': 'keep-alive',
'content-length': '1182',
'content-type': 'application/x-amz-json-1.0',
'date': 'Sat, 12 Oct 2019 06:31:58 GMT',
'server': 'Server',
'x-amz-crc32': '4044681601',
'x-amzn-requestid': 'ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890'},
'HTTPStatusCode': 200,
'RequestId': 'ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890',
'RetryAttempts': 0},
'ScannedCount': 15}
これらを pandas のデータフレームにして、最後は CSV にしていきます!
まずデータフレームのカラムを取得していきます。「Artist」などのキーがカラムになる部分ですね!
以下を実行して、重複がないようにリストを作ります。ついでにソートもしておきます。
# fields取得
data_to_dump = dynamo_table.scan()
fields_list = []
for record in data_to_dump['Items']:
for key in record.keys():
if key not in fields_list:
fields_list.append(key)
fields_list.sort()
fields_list
結果↓
['Artist', 'SongTitle', '評価']
これをカラムとして、空のデータフレームを作っておきましょう。
# 空のデータフレーム作成
export_df = pd.DataFrame(columns=fields_list)
作ったデータフレームにデータを入れていきましょう。
# export用データフレーム作成
export_df = pd.DataFrame(columns=fields_list)
for d in data_to_dump['Items']:
export_df = export_df.append(pd.Series([d[x] if x in d else "" for x in fields_list], index=export_df.columns), ignore_index=True)
export_df
結果↓
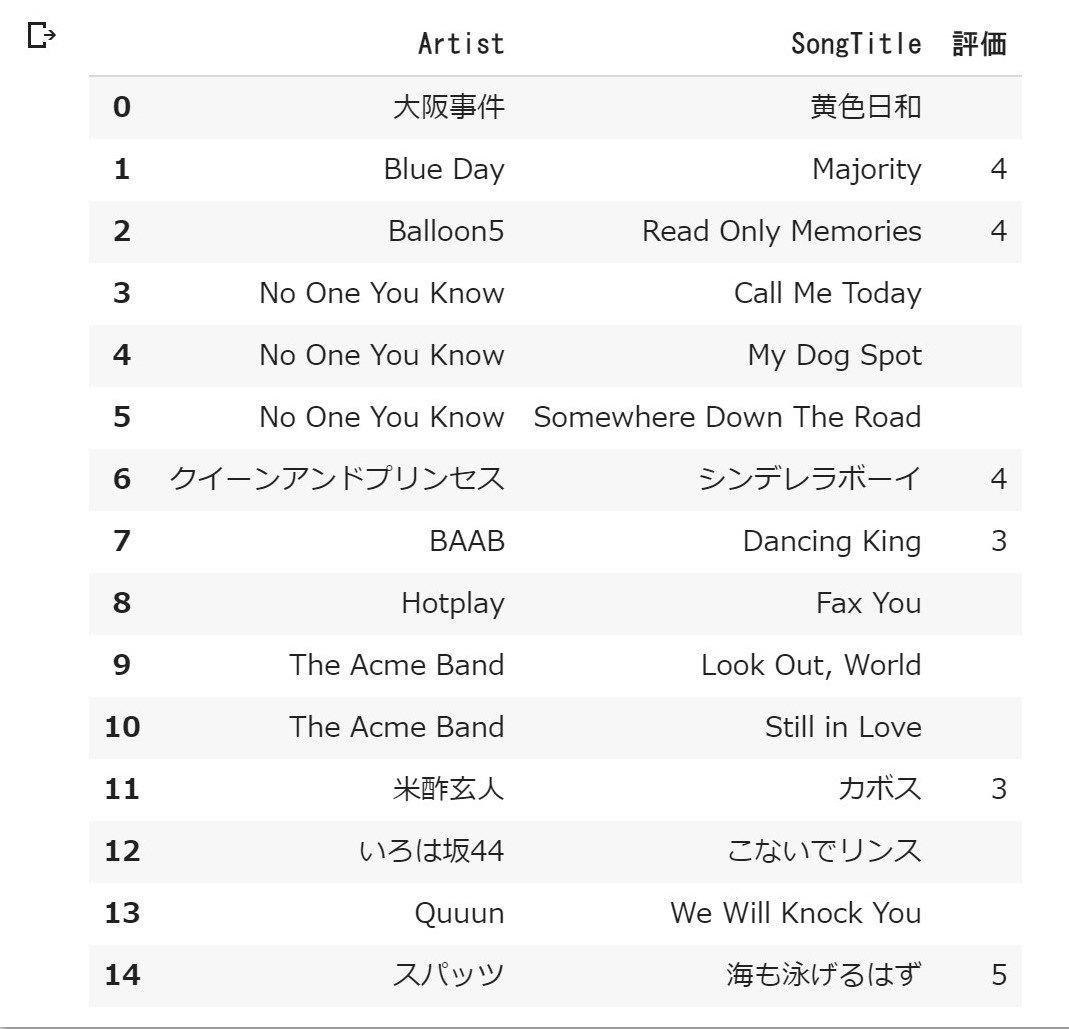
無事にできました!
あとは以下を実行してローカルにダウンロードしましょう!
# csv作成
export_df.to_csv('export.csv', index=False)
# ローカルに保存
files.download('export.csv')