記事の全体像
この記事は2部構成になっています。
・第一部:EDA・前処理 ← いまここ
・第二部:ベクトル化・モデル作成編(LSTM、BERT) (工事中、Coming Soon!)
第二部では第一部で前処理を行ったデータを用いる為、
記事の最下部に前処理を一括で実行できるコードを記載しているので、
第一部をスキップされたい方はそちらを実行して第二部に進んでください。
(※データはこの記事を参照して入手してください!)
コンペティションの概要
Kaggle : Real or Not? NLP with Disaster Tweets
自然言語処理の入門コンペです。
タスクは、ツイートを「災害ツイート」or「災害以外のツイート」の2つに分類することです。
最近では、災害時の救助要請などにツイッターが使われており、災害救援団体や通信社などで災害発生時のツイート自動監視の関心が高まっています。
しかし、ツイートが実際に災害を表しているかどうかを機械的に判断することは難しいです。
それは、例えば災害を明示的に表す「燃えている」という表現も、比喩表現として「空が燃えている」のように使われることがあるからです。
このコンペでは、10,000のツイートのデータセットを使用して、「災害ツイート」or「災害以外のツイート」を予測する機械学習モデルを構築します。
いざハンズオン!
Jupyter Notebookを使用してハンズオンを進めていきます。
0. データの入手
Kaggle : Real or Not? NLP with Disaster Tweets - Data
上述のページのから
・test.csv
・train.csv
の2つをダウンロードします。
以後は、分析を行うノートブックと同じ階層にこのcsvファイルを置いてください。
csvファイルの各カラムの内容は以下の通り。
| ファイル名 | 説明 |
|---|---|
| id | 各ツイートの一意の識別子 |
| text | ツイートのテキスト本文 |
| location | ツイートが送信された場所(空欄有り) |
| keyword | ツイート内の特定のキーワード(空欄有り) |
| target | ツイートのラベル(災害ツイート=1、災害以外のツイート=0) |
| 具体的な内容や欠損値の情報は次項で説明します。 | |
| コンペでは、test.csvのtargetカラムを予測します。 |
1.ライブラリの読み込み
今回のハンズオンで使用するライブラリを事前に定義します。
# データ分析
import pandas as pd
import numpy as np
# 可視化
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
# 自然言語処理
import string # 記号(punctuation)の一覧を取得
import re
import contractions # 文書の短縮形を
from wordcloud import STOPWORDS # ストップワードのリストを取得する
from collections import defaultdict # n-gram作成時に利用
2.データの内容確認
早速データの内容を確認してみたいと思います。
まずは、データをデータフレームとして読み込みます。
データフレームの行数・列数を表示して、行をランダムで10個抽出してみます。
# 訓練データとテストデータの読み込み
df_train = pd.read_csv('train.csv', dtype={'id': np.int16, 'target': np.int8})
df_test = pd.read_csv('test.csv', dtype={'id': np.int16})
# 訓練データとテストデータの行数・列数を表示する
print('Training Set Shape = {}'.format(df_train.shape))
print('Test Set Shape = {}'.format(df_test.shape))
# 訓練データの中から10行をランダムで抽出
df_train.sample(n=10, random_state=28)
Training Set Shape = (7613, 5)
Test Set Shape = (3263, 4)
以下、実行結果の続き(ランダムで抽出された行の内容)
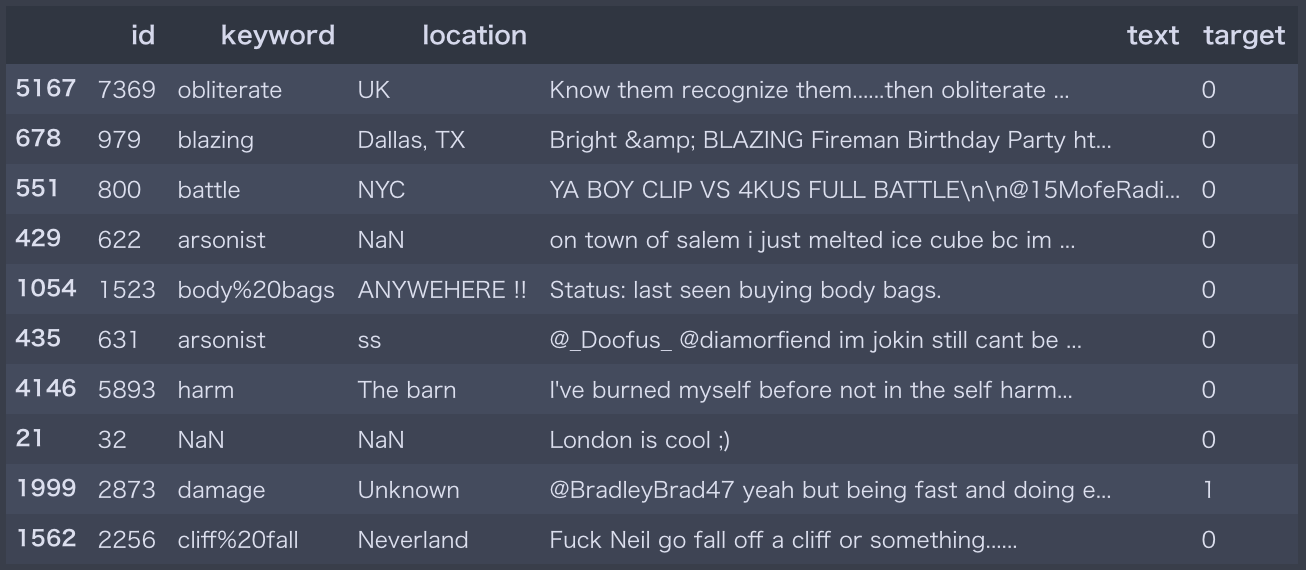
keywordとlocationのカラムの中には欠損値NaN がある場合もありますね。
欠損値について詳細に調べてみたいと思います。
# 訓練データ、テストデータの各カラムの欠損値率を算出
print("missing-value ratio of training data(%)")
print(df_train.isnull().sum()/df_train.shape[0]*100)
print("\nmissing-value ratio of test data(%)")
print(df_test.isnull().sum()/df_test.shape[0]*100)
missing-value ratio of training data(%)
id 0.000000
keyword 0.801261
location 33.272035
text 0.000000
target 0.000000
dtype: float64
missing-value ratio of test data(%)
id 0.000000
keyword 0.796813
location 33.864542
text 0.000000
dtype: float64
欠損値は、訓練データとテストデータいずれにおいても keyword で0.8%、location で33~34%あることが分かります。
次に、訓練データのtargetの分布を見てみましょう。
# ターゲットの要素とその個数をプロット
target_vals = df_train.target.value_counts()
sns.barplot(target_vals.index, target_vals)
plt.gca().set_ylabel('samples')
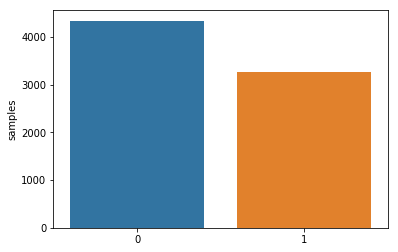
データセット中には災害ツイート=1よりも災害以外のツイート=0の方が多いことが分かります。
次に、text、keyword、locationそれぞれのカラムのユニークな要素の個数を調べてみたいと思います。
# text、keyword、locationのユニークな要素の個数を表示
print(f'Number of unique values in text = {df_train["text"].nunique()} (Training) - {df_test["text"].nunique()} (Test)')
print(f'Number of unique values in keyword = {df_train["keyword"].nunique()} (Training) - {df_test["keyword"].nunique()} (Test)')
print(f'Number of unique values in location = {df_train["location"].nunique()} (Training) - {df_test["location"].nunique()} (Test)')
Number of unique values in text = 7503 (Training) - 3243 (Test)
Number of unique values in keyword = 221 (Training) - 221 (Test)
Number of unique values in location = 3342 (Training) - 1603 (Test)
textとlocationは自由入力であることが分かります。
一方でkeywordはtextの中から事前に定義された221のキーワードを自動抽出していることが分かります。
3.探索的データ分析(Explanatory Data Analysis:EDA)
データの特徴を理解するための処理をいくつか行っていきたいと思います。
まずはtext内の特徴を大雑把に把握・比較したいと思います。
特徴は、単語数、ユニークな単語数、ストップワードの数、URLの数、単語文字数の平均、文字数、punctuation(※)の数、ハッシュタグ数、メンション数の9個を調べてみます。
1点補足をしておくと、ここでいうpunctuation(※)とは句読点の意味ではなく、英数字以外のアスキー文字のことを指します。
ざっくりと、string.punctuationで定義される「記号」のようなイメージを持ってもらえれば大丈夫です。
また、これらの特徴はメタ特徴量として、データフレームに結合していきます。
更に、訓練データ内で災害ツイート=1⇄災害以外のツイート=0、訓練データ⇄テストデータ
について9個の特徴の分布を比較します。
災害に関連するツイート、そうでいないツイート、訓練データ、テストデータはそれぞれデータ点数が異なるため、
分布の可視化を行う際には、カーネル密度推定を行うことによってスケールが揃えられて直感的に分布を比較することができます。
可視化のライブラリであるseabornのdistplotのデフォルト引数でkde=Trueとなっていますが、今回は明示的にkde=Trueを記載します。
# 単語数
df_train['word_count'] = df_train['text'].apply(lambda x: len(str(x).split()))
df_test['word_count'] = df_test['text'].apply(lambda x: len(str(x).split()))
# ユニークな単語数
df_train['unique_word_count'] = df_train['text'].apply(lambda x: len(set(str(x).split())))
df_test['unique_word_count'] = df_test['text'].apply(lambda x: len(set(str(x).split())))
# ストップワードの数
df_train['stop_word_count'] = df_train['text'].apply(lambda x: len([w for w in str(x).lower().split() if w in STOPWORDS]))
df_test['stop_word_count'] = df_test['text'].apply(lambda x: len([w for w in str(x).lower().split() if w in STOPWORDS]))
# URLの数
df_train['url_count'] = df_train['text'].apply(lambda x: len([w for w in str(x).lower().split() if 'http' in w or 'https' in w]))
df_test['url_count'] = df_test['text'].apply(lambda x: len([w for w in str(x).lower().split() if 'http' in w or 'https' in w]))
# 単語文字数の平均
df_train['mean_word_length'] = df_train['text'].apply(lambda x: np.mean([len(w) for w in str(x).split()]))
df_test['mean_word_length'] = df_test['text'].apply(lambda x: np.mean([len(w) for w in str(x).split()]))
# 文字数
df_train['char_count'] = df_train['text'].apply(lambda x: len(str(x)))
df_test['char_count'] = df_test['text'].apply(lambda x: len(str(x)))
# 句読点の個数
df_train['punctuation_count'] = df_train['text'].apply(lambda x: len([c for c in str(x) if c in string.punctuation]))
df_test['punctuation_count'] = df_test['text'].apply(lambda x: len([c for c in str(x) if c in string.punctuation]))
# ハッシュタグの個数
df_train['hashtag_count'] = df_train['text'].apply(lambda x: len([c for c in str(x) if c == '#']))
df_test['hashtag_count'] = df_test['text'].apply(lambda x: len([c for c in str(x) if c == '#']))
# メンションの個数
df_train['mention_count'] = df_train['text'].apply(lambda x: len([c for c in str(x) if c == '@']))
df_test['mention_count'] = df_test['text'].apply(lambda x: len([c for c in str(x) if c == '@']))
# 9つの特徴の分布を、災害ツイート=1 ⇄ 災害以外のツイート=0、訓練データ ⇄ テストデータで比較する
METAFEATURES = ['word_count', 'unique_word_count', 'stop_word_count', 'url_count', 'mean_word_length',
'char_count', 'punctuation_count', 'hashtag_count', 'mention_count']
DISASTER_TWEETS = df_train['target'] == 1
fig, axes = plt.subplots(ncols=2, nrows=len(METAFEATURES), figsize=(20, 50), dpi=100)
for i, feature in enumerate(METAFEATURES):
# 災害ツイート=1 ⇄ 災害以外のツイート=0の分布を比較する(カーネル密度推定を行う)
sns.distplot(df_train.loc[~DISASTER_TWEETS][feature], label='Not Disaster', ax=axes[i][0], color='green', kde=True)
sns.distplot(df_train.loc[DISASTER_TWEETS][feature], label='Disaster', ax=axes[i][0], color='red', kde=True)
# 訓練データ ⇄ テストデータの分布を比較する(カーネル密度推定を行う)
sns.distplot(df_train[feature], label='Training', ax=axes[i][1], kde=True)
sns.distplot(df_test[feature], label='Test', ax=axes[i][1], kde=True)
for j in range(2):
axes[i][j].set_xlabel('')
axes[i][j].tick_params(axis='x', labelsize=12)
axes[i][j].tick_params(axis='y', labelsize=12)
axes[i][j].legend()
axes[i][0].set_title(f'{feature} Target Distribution in Training Set', fontsize=13)
axes[i][1].set_title(f'{feature} Training & Test Set Distribution', fontsize=13)
plt.show()
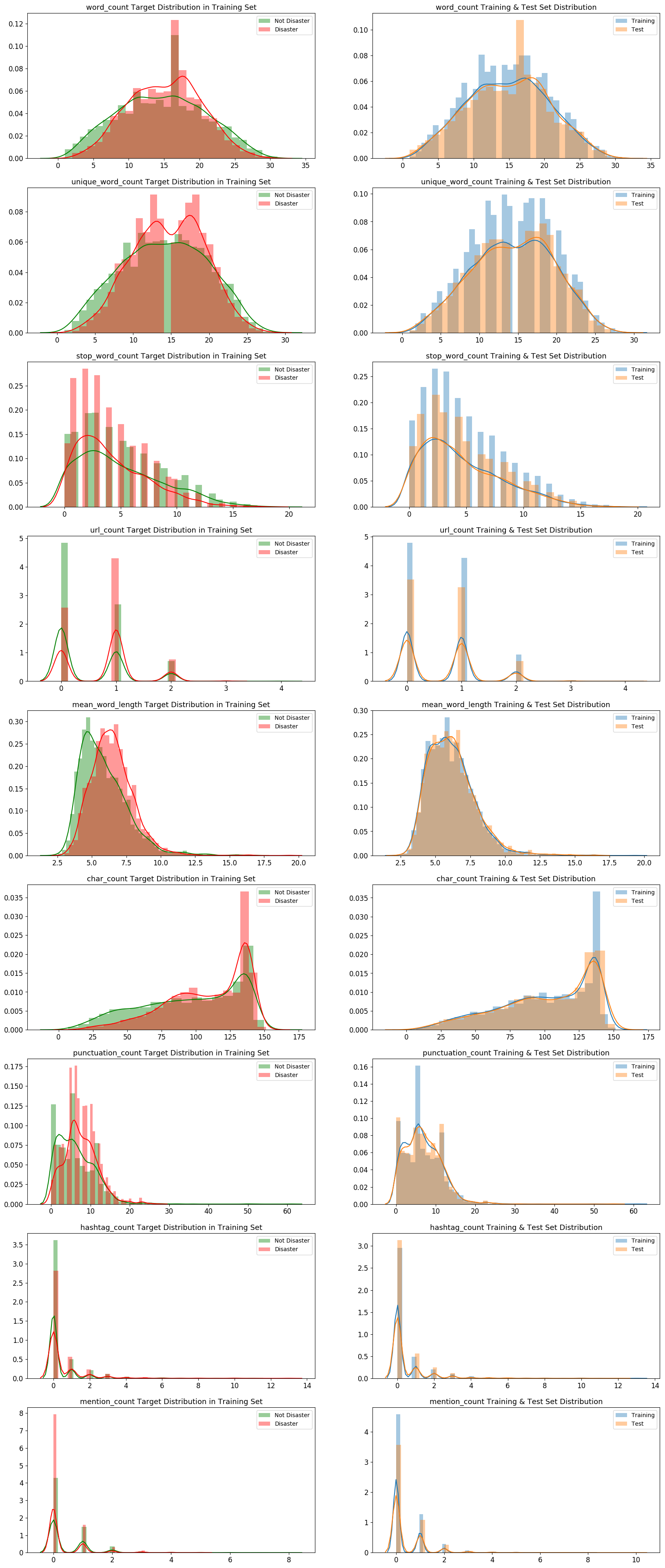
災害ツイートと災害以外のツイート、訓練データとテストデータで分布に大きな違いが無いことがわかります。
URL、ハッシュタグ、メンションが含まれるツイートも、それらを含まないツイートと同程度かそれ以上あることが分かります。
URL、ハッシュタグ、メンション等の表記は災害ツイート、災害以外のツイートの判断に必要な情報でない可能性が高いので、前処理でクレンジングすると良いかもしれません。
次に、keywordの単語のうち、どれが災害ツイートで多く登場し、どれが災害以外ツイートで多く登場するかを調べます。
災害ツイートのtargetは整数で1、災害以外のツイートは整数で0のため、
keywordの単語毎のtargetの平均値を取り、1に近ければ災害ツイートに登場する傾向がある単語、
0に近ければ災害以外のツイートに登場する傾向がある単語であることが分かります。
pandasのgroupbyメソッドを使用して、keywordの単語毎にtargetの平均値を求めて、その値を訓練データ全体に付加します。
その後、災害ツイートで登場する単語から順に登場回数をプロットします。
# keywordの単語毎に、targetの平均値を求めて、その値を訓練データ全体に付加する
df_train['target_mean'] = df_train.groupby('keyword')['target'].transform('mean')
fig = plt.figure(figsize=(8, 72), dpi=100)
# keyword に含まれるラベル分布を確認
sns.countplot(y=df_train.sort_values(by='target_mean', ascending=False)['keyword'],
hue=df_train.sort_values(by='target_mean', ascending=False)['target'])
plt.tick_params(axis='x', labelsize=15)
plt.tick_params(axis='y', labelsize=12)
plt.legend(loc=1)
plt.title('Target Distribution in Keywords')
plt.show()
# targetの値の平均値のカラムは以降使用しないので削除する
df_train.drop(columns=['target_mean'], inplace=True)
出力結果は以下のようになります。
221個の単語のラベル分布全てを、本記事に表示すると縦に長くなってしまうので、
災害ツイートに登場する傾向がある単語と、災害以外のツイートに登場する傾向がある単語、
それぞれ上位のみを表示します(実際は縦長のラベル分布の図が得られます)。
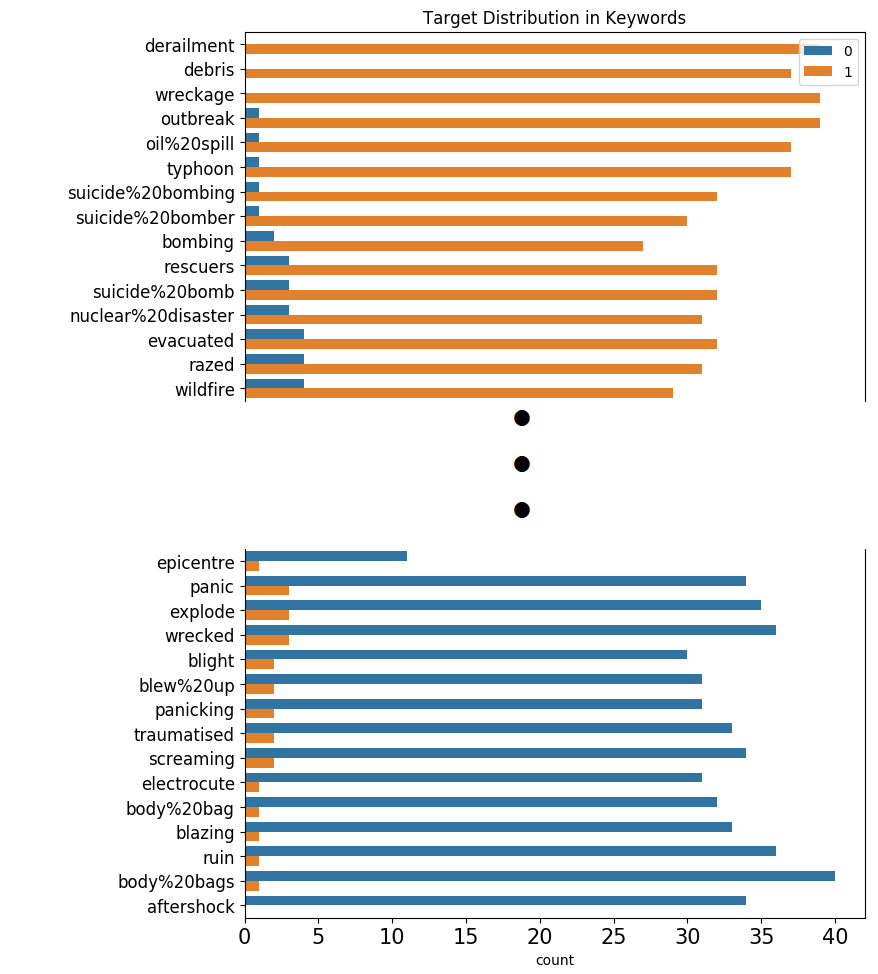
derailment(=脱線)、debris(=残骸)、wreckage(=残骸)といった災害に関連する具体的な状態を表す名詞は、災害ツイートで登場する傾向があります。
一方で、aftershock(=余震、余波)、body bags(=遺体袋)、ruin(=破滅(名詞)、台無しにする(動詞))などは一見災害に関連する単語ですが、
災害ツイートでは登場しない傾向があります。
これは、比喩表現としても使われる単語であるためだと考えられます。
次に、n-gramによる頻出単語の確認を行います。
今回は、ユニグラム(n=1)、バイグラム(n=2)、トライグラム(n=3)で頻出単語を、災害ツイート=1⇄災害以外のツイート=0でそれぞれ確認します。
まずは、n-gramのリストを生成する関数を定義します。
n-gramのリストを生成する関数の詳しい解説記事も良かったらご覧ください。
def generate_ngrams(text, n_gram=1):
# ストップワードのリストにない単語のみをトークナイズ
token = [token for token in text.lower().split(' ') if token != '' if token not in STOPWORDS]
# n_gramのタプルの作成、zip(*)によってリストの先頭から同じインデックスの要素を取り出す。
ngrams = zip(*[token[i:] for i in range(n_gram)])
return [' '.join(ngram) for ngram in ngrams]
次に、関数を用いてユニグラム(n=1)、バイグラム(n=2)、トライグラム(n=3)とその頻度を計算します。
# ユニグラム
disaster_unigrams = defaultdict(int)
nondisaster_unigrams = defaultdict(int)
# df_trainの中の災害ツイートのユニグラムを作成する
for tweet in df_train[DISASTER_TWEETS]['text']:
for word in generate_ngrams(tweet):
disaster_unigrams[word] += 1
# df_trainの中の災害以外のツイートのユニグラムを作成する。
for tweet in df_train[~DISASTER_TWEETS]['text']:
for word in generate_ngrams(tweet):
nondisaster_unigrams[word] += 1
# 出現頻度でソートする
df_disaster_unigrams = pd.DataFrame(sorted(disaster_unigrams.items(), key=lambda x: x[1])[::-1])
df_nondisaster_unigrams = pd.DataFrame(sorted(nondisaster_unigrams.items(), key=lambda x: x[1])[::-1])
# バイグラム
disaster_bigrams = defaultdict(int)
nondisaster_bigrams = defaultdict(int)
for tweet in df_train[DISASTER_TWEETS]['text']:
for word in generate_ngrams(tweet, n_gram=2):
disaster_bigrams[word] += 1
for tweet in df_train[~DISASTER_TWEETS]['text']:
for word in generate_ngrams(tweet, n_gram=2):
nondisaster_bigrams[word] += 1
df_disaster_bigrams = pd.DataFrame(sorted(disaster_bigrams.items(), key=lambda x: x[1])[::-1])
df_nondisaster_bigrams = pd.DataFrame(sorted(nondisaster_bigrams.items(), key=lambda x: x[1])[::-1])
# トライグラム
disaster_trigrams = defaultdict(int)
nondisaster_trigrams = defaultdict(int)
for tweet in df_train[DISASTER_TWEETS]['text']:
for word in generate_ngrams(tweet, n_gram=3):
disaster_trigrams[word] += 1
for tweet in df_train[~DISASTER_TWEETS]['text']:
for word in generate_ngrams(tweet, n_gram=3):
nondisaster_trigrams[word] += 1
df_disaster_trigrams = pd.DataFrame(sorted(disaster_trigrams.items(), key=lambda x: x[1])[::-1])
df_nondisaster_trigrams = pd.DataFrame(sorted(nondisaster_trigrams.items(), key=lambda x: x[1])[::-1])
まずは、出現頻度の高い30のユニグラムを見てみましょう。
N = 30 # 上位30のユニグラムだけ表示する
fig, axes = plt.subplots(ncols=2, figsize=(15, 15), dpi=100)
plt.tight_layout()
sns.barplot(y=df_disaster_unigrams[0].values[:N], x=df_disaster_unigrams[1].values[:N], ax=axes[0], color='red')
sns.barplot(y=df_nondisaster_unigrams[0].values[:N], x=df_nondisaster_unigrams[1].values[:N], ax=axes[1], color='green')
for i in range(2):
axes[i].spines['right'].set_visible(False)
axes[i].set_xlabel('')
axes[i].set_ylabel('')
axes[i].tick_params(axis='x', labelsize=13)
axes[i].tick_params(axis='y', labelsize=13)
axes[0].set_title(f'Top {N} most common unigrams in Disaster Tweets', fontsize=15)
axes[1].set_title(f'Top {N} most common unigrams in Non-disaster Tweets', fontsize=15)
plt.show()
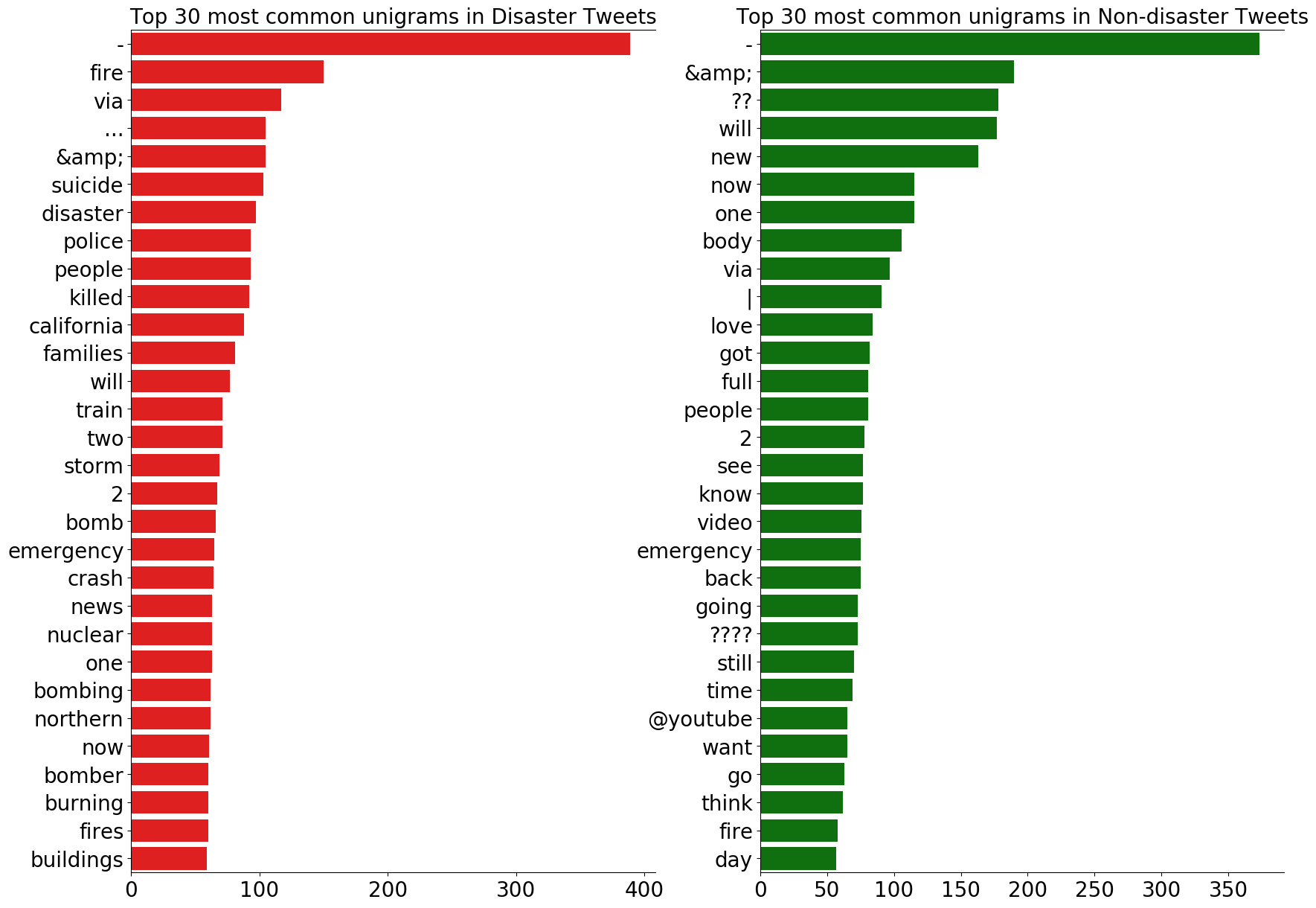
災害ツイート、災害以外のツイートであっても、最頻出のユニグラムの多くが記号、取り除ききれなかったストップワード、数字であることが分かります。
これらのユニグラムはtargetの判断基準にならないので、モデリングの前に削除した方がよいでしょう。
また、災害ツイートで頻出のユニグラムは、災害に関する具体的な情報を提供していることが分かります。
一方、災害以外のツイートで頻出のユニグラムの中に、動詞が多いことが分かります。
これは、災害以外のツイートでは、ユーザーが自身もしくは何かの動作についてツイートする傾向があるからだと考えられます。
バイグラムとトライグラムについても見てみましょう。
# バイグラム
fig, axes = plt.subplots(ncols=2, figsize=(20, 15), dpi=100)
plt.subplots_adjust(wspace=0.4, hspace=0.6)
sns.barplot(y=df_disaster_bigrams[0].values[:N], x=df_disaster_bigrams[1].values[:N], ax=axes[0], color='red')
sns.barplot(y=df_nondisaster_bigrams[0].values[:N], x=df_nondisaster_bigrams[1].values[:N], ax=axes[1], color='green')
for i in range(2):
axes[i].spines['right'].set_visible(False)
axes[i].set_xlabel('')
axes[i].set_ylabel('')
axes[i].tick_params(axis='x', labelsize=20)
axes[i].tick_params(axis='y', labelsize=20)
axes[0].set_title(f'Top {N} most common bigrams in Disaster Tweets', fontsize=20)
axes[1].set_title(f'Top {N} most common bigrams in Non-disaster Tweets', fontsize=20)
plt.show()
# トライグラム
fig, axes = plt.subplots(ncols=2, figsize=(20, 15), dpi=100)
plt.subplots_adjust(wspace=0.7, hspace=0.6)
sns.barplot(y=df_disaster_trigrams[0].values[:N], x=df_disaster_trigrams[1].values[:N], ax=axes[0], color='red')
sns.barplot(y=df_nondisaster_trigrams[0].values[:N], x=df_nondisaster_trigrams[1].values[:N], ax=axes[1], color='green')
for i in range(2):
axes[i].spines['right'].set_visible(False)
axes[i].set_xlabel('')
axes[i].set_ylabel('')
axes[i].tick_params(axis='x', labelsize=20)
axes[i].tick_params(axis='y', labelsize=20)
axes[0].set_title(f'Top {N} most common trigrams in Disaster Tweets', fontsize=20)
axes[1].set_title(f'Top {N} most common trigrams in Non-disaster Tweets', fontsize=20)
plt.show()
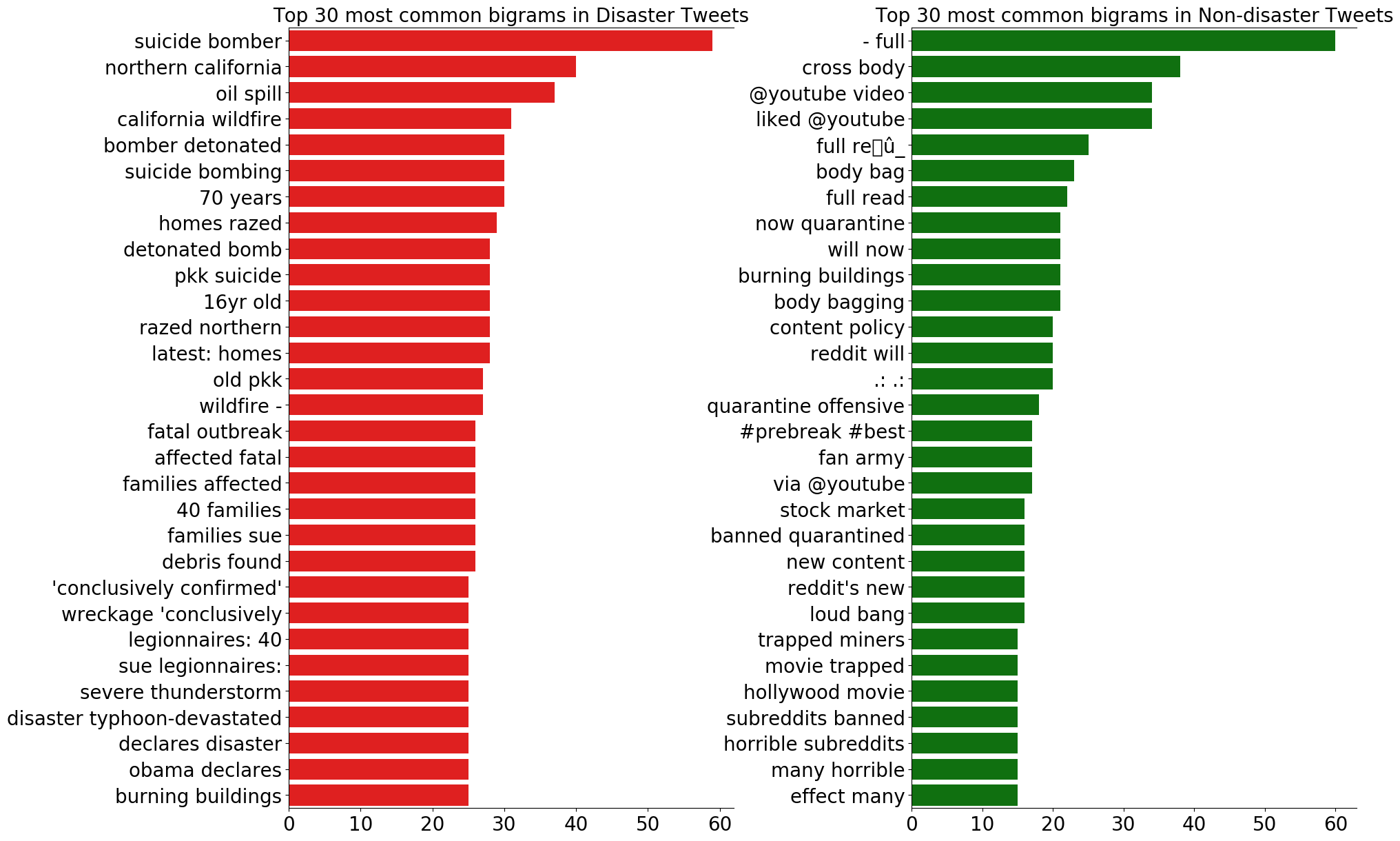
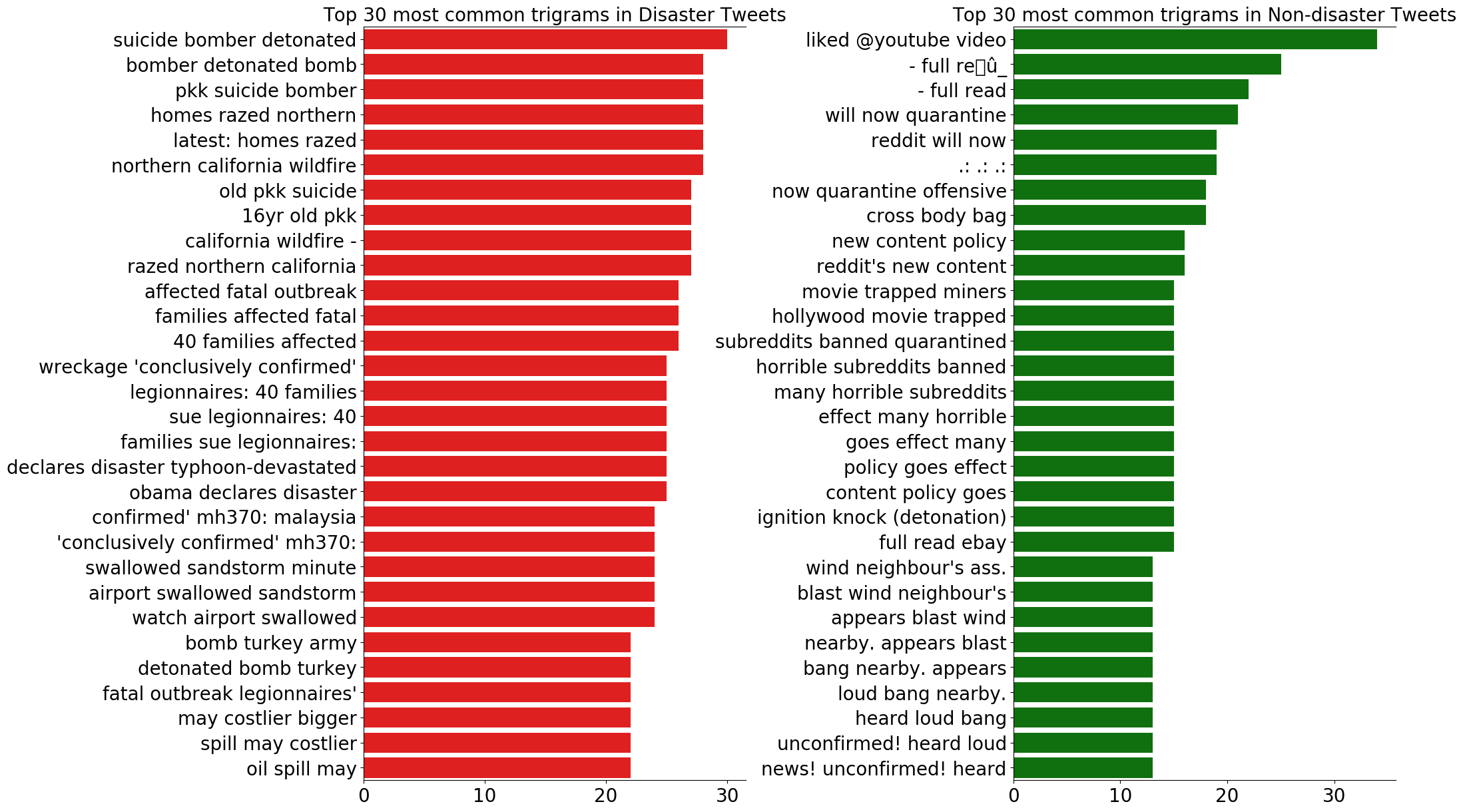
災害ツイートは、バイグラムもトライグラムも共通して具体的な災害の内容を多く含んでいることが分かります。
また、災害ツイートではユニグラムにあったような記号やストップワード、数字があまり登場しないことも分かります。
一方、災害以外のツイートは、区切り文字やストップワードが登場し、redditやyoutubeといった単語も多く登場します。
4.データの前処理
探索的データ分析によって、ツイートからモデル構築に不要な情報を取り除く必要があることが分かりました。
モデル構築の前にいくつかの前処理を訓練データ、テストデータに行います。
まず、I'mや、we'veといった短縮形の単語をI amやwe haveといった形に戻します。
pythonではcontractionsというモジュールが提供されており、contractions.fix(text)で、
短縮形を元の形に戻すことができます。
def fix_contractions(text):
return contractions.fix(text)
# 関数適応前のツイート例
print("tweet before contractions fix : ", df_train.iloc[1055]["text"])
# 関数の適用
df_train['text']=df_train['text'].apply(lambda x : fix_contractions(x))
df_test['text']=df_test['text'].apply(lambda x : fix_contractions(x))
# 関数適用後のツイート例
print("tweet after contractions fix : ", df_train.iloc[1055]["text"])
tweet before contractions fix : @asymbina @tithenai I'm hampered by only liking cross-body bags. I really like Ella Vickers bags: machine washable. http://t.co/YsFYEahpVg
tweet after contractions fix : @asymbina @tithenai I am hampered by only liking cross-body bags. I really like Ella Vickers bags: machine washable. http://t.co/YsFYEahpVg
次に、URLを含むツイートから、正規表現を用いてURLのみ削除します。
def remove_URL(text):
url = re.compile(r'https?://\S+|www\.\S+')
return url.sub(r'',text)
# 関数適応前のツイート例
print("tweet before URL removal : ", df_train.iloc[1055]["text"])
# 関数の適用
df_train['text']=df_train['text'].apply(lambda x : remove_URL(x))
df_test['text']=df_test['text'].apply(lambda x : remove_URL(x))
# 関数適用後のツイート例
print("tweet after URL removal : ", df_train.iloc[1055]["text"])
tweet before URL removal : @asymbina @tithenai I am hampered by only liking cross-body bags. I really like Ella Vickers bags: machine washable. http://t.co/YsFYEahpVg
tweet after URL removal : @asymbina @tithenai I am hampered by only liking cross-body bags. I really like Ella Vickers bags: machine washable.
次に、記号を削除したいと思います。
これによって、ハッシュタグやメンションを表す記号を含む#@!"$%&\'()*+,-./:;<=>?[\\]^_`{|}~の記号が削除されます。
削除する記号の一覧はstring.punctuationで取得可能です。
def remove_punct(text):
table=str.maketrans('','',string.punctuation)
return text.translate(table)
# 関数適応前のツイート例
print("tweet before punctuation removal : ", df_train.iloc[1055]["text"])
# 関数の適用
df_train['text']=df_train['text'].apply(lambda x : remove_punct(x))
df_test['text']=df_test['text'].apply(lambda x : remove_punct(x))
# 関数適用後のツイート例
print("tweet after punctuation removal : ", df_train.iloc[1055]["text"])
tweet before punctuation removal : @asymbina @tithenai I am hampered by only liking cross-body bags. I really like Ella Vickers bags: machine washable.
tweet after punctuation removal : asymbina tithenai I am hampered by only liking crossbody bags I really like Ella Vickers bags machine washable
上述の3つの処理によってツイート本文が綺麗になりました。
今後は、綺麗になったテキストを用いてベクトル化、モデル化を行っていきたいと思います!
ベクトル化、モデル化の記事は現在執筆中です!お待ちください!
参考にしたノートブック
本記事で参考に(or 使用)したコンペのノートブック
・https://www.kaggle.com/gunesevitan/nlp-with-disaster-tweets-eda-cleaning-and-bert
(EDA、データ前処理、ベクトル化、BERT)
・https://www.kaggle.com/shahules/basic-eda-cleaning-and-glove
(EDA、データ前処理、GloVe)
次章を進める前に行う前処理
以下のコードを実行した状態で次章に進んでください
# データ分析
import pandas as pd
import numpy as np
# 可視化
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
# 自然言語処理
import string # 記号(punctuation)の一覧を取得
import re
import contractions # 文書の短縮形を
from wordcloud import STOPWORDS # ストップワードのリストを取得する
from collections import defaultdict # n-gram作成時に利用
# 短縮形の復元
def fix_contractions(text):
return contractions.fix(text)
# URLの削除
def remove_URL(text):
url = re.compile(r'https?://\S+|www\.\S+')
return url.sub(r'',text)
# 記号の削除
def remove_punct(text):
table=str.maketrans('','',string.punctuation)
return text.translate(table)
# 関数の適用
df_train['text']=df_train['text'].apply(lambda x : fix_contractions(x))
df_test['text']=df_test['text'].apply(lambda x : fix_contractions(x))
df_train['text']=df_train['text'].apply(lambda x : remove_URL(x))
df_test['text']=df_test['text'].apply(lambda x : remove_URL(x))
df_train['text']=df_train['text'].apply(lambda x : remove_punct(x))
df_test['text']=df_test['text'].apply(lambda x : remove_punct(x))