こんにちは、現在GANを用いて画像生成を学んでいる者です。
統計や機械学習の知識も曖昧なまま不安ですが、ChatGPTやサイトを参考にMNISTデータセットから数字画像を生成するGANを実装してみたのでコードベースで解説しつつ、理解度を上げようと思います。ちなみにGANモデルの概要については触れません。GeneraticeAdversarialNets(敵対的生成ネットワーク)と検索すれば原論文が見つかりますし、多くのメディアで取り上げられているのであえて割愛します。
機械学習用フレームワークにはPytorchを使用しています。それでは早速行ってみましょう!
環境の準備(モジュール/ライブラリ/パラメータ)
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
#CPUかGPUどちらのデバイスで処理を行うかを決定する。GPUで処理をしたい場合はCUDA専用のPytorchをインストールする必要あり。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#事前に設定されるハイパーパラメーター
#ランダムノイズベクトルの次元数(大きいほど複雑な生成に対応)
latent_size = 64
#隠れ層のユニット数:入力層と出力層の間にある学習ユニットの数
hidden_size = 256
#画像のサイズ(今回は28×28のMnistを使用)
image_size = 784
#エポック数(num_epochs):訓練データを何回モデルに通すか
num_epochs = 100
#バッチサイズ:学習用データサンプルを一度にモデルに入力させる数
batch_size = 100
#学習率(LearningRate):勾配に対してどのぐらいの割合で更新を反映させるか
learning_rate = 0.0002
Pytorchをメインライブラリとして、様々なモジュールをインポートします。全ての機能を解説することは難しいので割愛しますがPytorchの代表的な機能2つを解説します。
テンソル操作
とてつもない量のデータ計算を行う機械学習ではテンソルという概念を用いて配列を表現し、それらを操作して効率的に訓練を行います。画像認識モデルなら高さ・幅・色の3次元のテンソルとして入力を受けますが、重みやバイアスなどの学習パラメータも扱います。
自動微分
また機械学習は、出力結果が入力した情報からどのように変化しているかを読み取り、より精度が高まるように更新していく作業です。この変わり具合を山の斜面に例えて「勾配」と呼ぶのですが、勾配を自動的に計算する機能もPytorchには備わっています。
これらが機械学習フレームワークの代表的な機能であり、モデルの構築には必要不可欠なのです。
データセットの準備
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])
])
mnist_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transform, download=True)
data_loader = DataLoader(dataset=mnist_dataset, batch_size=batch_size, shuffle=True)
まずtransformという変数にPytorchのパッケージtorchvisionから取り出してきた学習済みモデルを持たせます。torchvision.transforms(コード的にはtransforms)というのが画像変換・処理に特化したツールセットです。
この中に様々な学習済みモデルが入っており、今回はテンソル変換を行うToTensorと、データのピクセル数を0~1の範囲にスケール(正規化)するNormalizeを一連の処理として持たせています。
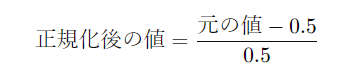
上記のような計算式でデータが平均0標準偏差1の範囲に収まるように調整し、一連の処理をデータダウンロード直後に画像に対して実行しています。
Generatorを定義
class Generator(nn.Module):#nn.Moduleを継承
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(latent_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, image_size),
nn.Tanh()
)
def forward(self, z):
return self.model(z)
Pytorchのnn.Moduleクラスを継承してGeneratorを定義しています。
initメソッド
super()を使って、親クラスの初期化メソッドを実行します。その後、nn.Sequentialを使用して複数の層を順に積み重ねようとしています。
各層の説明
nn.Linear():全結合層(線形層)と呼ばれ、入力されたデータ(潜在変数)に重みを掛け算し、バイアスを加えたあと次の層に出力します。
nn.ReLU():ReLUという活性化関数を適用します。非線形性を導入し、複雑なパターンにも対応できる表現力を獲得します。
nn.Tanh():ハイパボリックタンジェント関数といいなんだか難しそうな名前をしていますが仕組み自体はそれほど難しくありません。以下にTanh関数のグラフを表します。
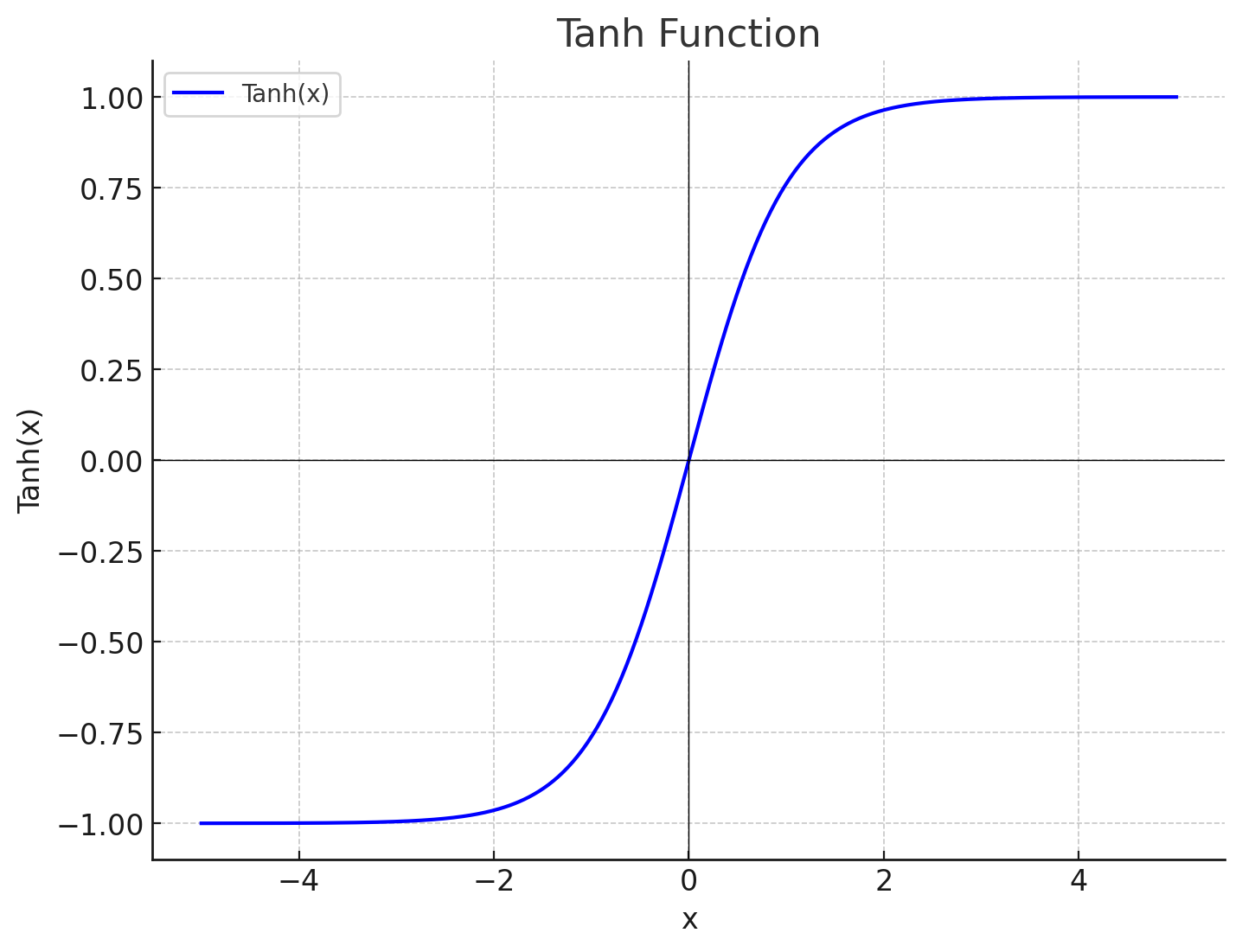
入力が0に近い時には出力も0に近づき、大きな正の値なら1、大きな負の値なら―1に近づくという特徴を持っています。データ前処理と同じ範囲になるように正規化を行い、安定した学習を行うため最後に実行しています。
Discriminatorを定義
# Discriminatorの定義
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(image_size, hidden_size),
nn.LeakyReLU(0.2),
nn.Linear(hidden_size, hidden_size),
nn.LeakyReLU(0.2),
nn.Linear(hidden_size, 1),
nn.Sigmoid()
)
def forward(self, x):
return self.model(x)
Pytorchのnn.Moduleクラスを継承してDiscriminatorを定義しています。所々Generatorと共通している部分はあるので、割愛して説明します。
LeakyReLU():Generatorで解説したReLUとは異なり入力が0以下の値でも小さな勾配(この場合は0.2)を持ちます。シンプルかつ高速なReLUではなくLeakyReLUを使う理由は、以下2つです。
①勾配消失問題の緩和
②死んだニューロン問題の防止
深いネットワークではReLUを使用すると勾配が消失して学習が進まなくなることがありますが、LeakyReLUは負の部分でも勾配を維持するため①が緩和できます。
また、ニューロンの出力が訓練中に一度0を出力すると更新されても0を吐き出し続ける場合があり、これも負の部分の勾配を持つことで完全に死ぬことはなくなります。
Sigmoid():シグモイド関数といい、入力値を0~1の範囲に変換する数学関数です。グラフにすると滑らかなS字型の曲線を描いているので全ての点で微分可能です。出力を確率として解釈できることがDiscriminatorにおいて使用される由縁です。
損失関数とオプティマイザの設定
# モデルとオプティマイザの初期化
G = Generator().to(device)
D = Discriminator().to(device)
criterion = nn.BCELoss()
g_optimizer = optim.Adam(G.parameters(), lr=learning_rate)
d_optimizer = optim.Adam(D.parameters(), lr=learning_rate)
# 損失とスコアを記録するリスト
d_losses, g_losses, real_scores, fake_scores = [], [], [], []
まずGeneratorとDiscriminatorのインスタンスを作成し、それぞれGとDという変数に格納しています。.to(device)とは序盤に指定した処理用デバイスの設定を表しています。
損失関数の設定
criterionという変数にバイナリ交差エントロピー損失関数(BCELoss)を代入しています。二項分類の問題で使用される損失関数で以下のように定義されます。
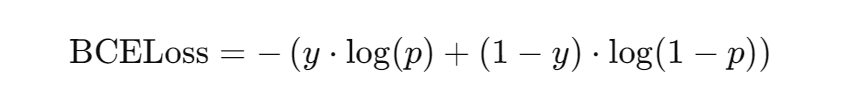
yは1か0の正解ラベルを指し、pは0~1の範囲でどちらのラベルに近いかの予測値です。予測値が正解に近ければ損失は小さくなります。GANのDiscriminatorは正に、Generatorの出力が本物か偽物かの判定を行いその精度を逆伝播させるため、この損失関数の設定が必要となります。
オプティマイザの設定
オプティマイザとはモデルのパラメータ(重み、バイアス)を更新するアルゴリズムです。ニューラルネットワークは正解データとの差が最小となるようなパラメータを見つけていく作業であるため、オプティマイザがなければ学習ができません。optim.AdamとあるようにAdamオプティマイザが使用されています。Adamに関する具体的な解説は他の記事を参照してください。学習が正確に収束するための画期的なアルゴリズムであることがわかるかと思います。
ここでは簡単に引数の内容を解説します。
g_optimizer = optim.Adam(G.parameters(), lr=learning_rate)
d_optimizer = optim.Adam(D.parameters(), lr=learning_rate)
G.parametersやD.parametersはPytorchのnn.Moduleクラスに組み込まれているメソッドで、そのモデルに含まれるすべてのパラメータ(nn.Lenearやnn.Conv2dのような層の重みとバイアス)を簡単に取得することができます。
またlearning_rateとは学習率のことで、パラメータをどれだけ更新するかを決めるハイパーパラメータというものです。先ほども説明しましたが、オプティマイザはパラメータの更新アルゴリズムであるため、パラメータを一度にすべて引き渡す簡易的メソッドが組み込まれているのです。
モデルの訓練ループ
訓練ループは、モデルがデータから学習するために繰り返されるプロセスです。GeneratorはDiscriminatorを騙すように学習し、Discriminatorは本物と偽物を正しく区別するように学習します。
for epoch in range(num_epochs):
for i, (images, _) in enumerate(data_loader):
batch_size = images.size(0)
real_labels = torch.ones(batch_size, 1).to(device)
fake_labels = torch.zeros(batch_size, 1).to(device)
# 本物の画像を訓練
images = images.reshape(batch_size, -1).to(device)
outputs = D(images)
d_loss_real = criterion(outputs, real_labels)
real_score = outputs
# 偽の画像を生成して訓練
z = torch.randn(batch_size, latent_size).to(device)
fake_images = G(z)
outputs = D(fake_images)
d_loss_fake = criterion(outputs, fake_labels)
fake_score = outputs
# Discriminatorの更新
d_loss = d_loss_real + d_loss_fake
d_optimizer.zero_grad()
d_loss.backward()
d_optimizer.step()
# Generatorの訓練
z = torch.randn(batch_size, latent_size).to(device)
fake_images = G(z)
outputs = D(fake_images)
g_loss = criterion(outputs, real_labels)
# Generatorの更新
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
# 損失とスコアを保存
d_losses.append(d_loss.item())
g_losses.append(g_loss.item())
real_scores.append(real_score.mean().item())
fake_scores.append(fake_score.mean().item())
print(f"Epoch [{epoch+1}/{num_epochs}], d_loss: {d_loss.item():.4f}, g_loss: {g_loss.item():.4f}, D(x): {real_score.mean().item():.2f}, D(G(z)): {fake_score.mean().item():.2f}")
# 生成された画像の表示
if (epoch + 1) % 10 == 0:
with torch.no_grad():
fake_images = G(torch.randn(16, latent_size).to(device)).reshape(-1, 28, 28)
fake_images = fake_images.cpu().numpy()
fig, axes = plt.subplots(4, 4, figsize=(10, 10))
for i, ax in enumerate(axes.flat):
ax.imshow(fake_images[i], cmap='gray')
ax.axis('off')
plt.savefig(f'generated_images_epoch_{epoch+1}.png')
plt.close()
print("訓練完了")
エポックとバッチの設定
for epoch in range(num_epochs):
for i, (images, _) in enumerate(data_loader):
batch_size = images.size(0)
1ループすることをepochと呼び、序盤に指定したnum_epochsの値分ループしていることがわかると思います。
Pytorchのsizeメソッドでテンソルの各次元のサイズを返し、batch_sizeに代入しています。batch_sizeとは一度に入力する画像データの個数でしたが、画像テンソルの0番目にバッチサイズが入力されているので問題ありません。
例えばimagesテンソルがバッチサイズ100の28×28ピクセルの画像データを含んでいる場合、imagesテンソルは[100, 28, 28]となります。
ラベルの設定
real_labels = torch.ones(batch_size, 1).to(device)
fake_labels = torch.zeros(batch_size, 1).to(device)
Pytorchのonesメソッドとzerosメソッドを使い、正解ラベルと偽物ラベルを定義していきます。第一引数にバッチサイズ、第二引数にテンソルの各次元のサイズを指定します。全ての要素に1または0のラベルを埋め尽くしたいだけなので単なる配列となり、1次元でいいことが分かります。
Discriminatorの訓練
images = images.reshape(batch_size, -1).to(device)
outputs = D(images)
d_loss_real = criterion(outputs, real_labels)
real_score = outputs
本物の画像をDiscriminatorに渡し、出力outputsを得ます
imagesはバッチサイズ、チャンネル数、画像の高さ、幅の次元を持つ4次元テンソルな訳ですが、入力前にreshape(batch_size,-1)とすることで1次元テンソル(28×28ピクセルなら784個の要素を持つ1次元ベクトル)に変換されます。
これがDiscriminatorに入力され、画像が本物である確率を出力、損失関数にて損失値を記録し、最後に学習の進行を評価するための指標として出力値も記録しています。
z = torch.randn(batch_size, latent_size).to(device)
fake_images = G(z)
outputs = D(fake_images)
d_loss_fake = criterion(outputs, fake_labels)
fake_score = outputs
次は偽画像を用いて識別器を訓練します。サンプル数と次元数を指定したランダムノイズをGeneratorに通すことで生成が始まり、あとは本物画像の訓練と同様です。次元数が高ければ高いほど多様性が生まれるものの計算量が多くなり、低いほど十分な表現力を持てないという欠点があります。
d_loss = d_loss_real + d_loss_fake
d_optimizer.zero_grad()
d_loss.backward()\^[]+ b
d_optimizer.step()
本物と偽物に対する損失を合計し、その損失を最小化するようにDiscriminatorのパラメータを更新します。その後zero_gradを実行することで前回の勾配をリセットしています。なぜなら、モデルの各パラメータに対して計算された勾配はデフォルトで累積される仕様になっているからです。
1行目で計算した損失の合計からbackward()メソッドを使って各パラメータに対する勾配を計算します。この操作はバックプロパゲーションと呼ばれ、各パラメータが損失を最小化する方向にどの程度変更されるべきかが計算されます。
計算された勾配は、その後stepメソッドによってオプティマイザに通され、パラメータの更新が行われます。
Generatorの訓練
z = torch.randn(batch_size, latent_size).to(device)
fake_images = G(z)
outputs = D(fake_images)
g_loss = criterion(outputs, real_labels)
ランダムノイズから画像を生成し、Discriminatorに本物と誤認させるよう訓練します。real_labelsとDiscriminatorの出力の損失を算出することで、どれぐらい騙せているかが分かります。
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
g_lossが最小化するようにパラメータを更新していきます。
損失とスコアの保存
# 損失とスコアを保存
d_losses.append(d_loss.item())
g_losses.append(g_loss.item())
real_scores.append(real_score.mean().item())
fake_scores.append(fake_score.mean().item())
print(f"Epoch [{epoch+1}/{num_epochs}], d_loss: {d_loss.item():.4f}, g_loss: {g_loss.item():.4f}, D(x): {real_score.mean().item():.2f}, D(G(z)): {fake_score.mean().item():.2f}")
進行状況と生成画像の表示・保存
# 損失とスコアを保存
if (epoch + 1) % 10 == 0:
with torch.no_grad():
fake_images = G(torch.randn(16, latent_size).to(device)).reshape(-1, 28, 28)
fake_images = fake_images.cpu().numpy()
fig, axes = plt.subplots(4, 4, figsize=(10, 10))
for i, ax in enumerate(axes.flat):
ax.imshow(fake_images[i], cmap='gray')
ax.axis('off')
plt.savefig(f'generated_images_epoch_{epoch+1}.png')
plt.close()
10エポックごとに生成された画像を表示・保存します。
結果の可視化と分析
plt.figure(figsize=(10, 5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(g_losses, label="G")
plt.plot(d_losses, label="D")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.savefig("training_loss.png")
plt.show()
plt.figure(figsize=(10, 5))
plt.title("Discriminator Scores During Training")
plt.plot(real_scores, label="D(x)")
plt.plot(fake_scores, label="D(G(z))")
plt.xlabel("Epochs")
plt.ylabel("Score")
plt.legend()
plt.savefig("discriminator_scores.png")
plt.show()
まとめ
いかがでしたでしょうか。私はこれを機に初めてPytorchを勉強したのですが、便利な関数が沢山組み込まれていてモデルに合わせて組み替えるだけでいいように感じ、凄く機械学習が手軽なものに感じました。解説の中で日本語が不十分なところや間違っている点がいくつもあるかと思いますが、ご容赦ください。少しでも誰かの役に立てれば幸いです。