はじめに
kintone2アドベントカレンダー、8日目の記事です!
需要がありそうで事例が公開されてなかった「リレーショナルデータベース(RDB)→kintoneへのデータ移行」について、ガッツリと実験したのでノウハウ書いてみたいと思います。
対象読者は、RDB/SQLの基礎知識がある人です。
RDBに慣れてる人がkintoneに入門する場合も役に立つのではないかと思います。
検証はPostgreSQLで行いました。MySQL/Oracleなどでは挙動が違う可能性があるので、適宜読み替えてください。関数など多少違っても、「不可能」ってことはないと思います。
kintoneとRDBの比較
まず初めにkintoneとRDBを比較して、リレーションをkintone上でどう表現するのか整理しましょう。
アプリ vs テーブル vs サブテーブル
kintoneの基本単位は「アプリ」です。この言葉が意外と曲者で、kintoneアプリって、パソコンアプリ、スマホアプリ、一般的なWebアプリなどに比べると粒度が小さいですよね。小さなアプリを複数連携させてこそ、kintoneの真価を発揮できます。
僕は複数のアプリを1つのスペースにまとめて、スペース内のアプリ同士をルックアップで連携しながらシステムを作ることが多いです。その1スペースが、世間一般で「アプリ」と呼ばれるような粒度になるわけですね。
さて、そんな風にアプリ間の連携を考えながら設計するのは、RDBでのデータモデリングにとても近い感覚があります。
kintoneの「アプリ」は、RDBでの「テーブル」相当と考えると、DBに慣れてる人はしっくり来るんじゃないでしょうか。kintoneで「テーブル」といえば「サブテーブル」を指すのがややこしいですが、「サブ」というからには「メイン」が事実上あるわけで、「メインテーブル = アプリ」という解釈で良いのだと思います。1
てわけで、この記事では以下のように用語を使い分けます
- アプリ: kintoneアプリ
- サブテーブル: kintoneサブテーブル
- テーブル: RDBテーブル
「kintoneのテーブル」という言い方は紛らわしいので使わず、「サブテーブル」に統一します。
(もし書いちゃってたら指摘してね)
リレーションの表現方法
1:Nの結合
RDBでいう「1:Nのリレーション」をkintoneで表現する例として、以下のような「顧客」「売上」という2エンティティを考えてみましょう。顧客:売上 = 1:N です。

kintoneでは大きく3通りの選択肢が考えられます。
- 顧客アプリ、売上アプリをそれぞれ作成
- 売上から顧客をルックアップ
- 顧客アプリのみ作成
- サブテーブルに売上を登録
- 売上アプリのみ作成
- ドロップダウンフィールドの選択肢として顧客を登録
表で比較すると、こんな感じ。
| 2アプリ作成 | 顧客アプリのみ | 売上アプリのみ | |
|---|---|---|---|
| 顧客1件 | 1レコード | 1レコード | ドロップダウンフィールド |
| 売上1件 | 1レコード | サブテーブル1行 | 1レコード |
| リレーション | ルックアップ | 行追加 | ドロップダウン選択 |
| メリット | 顧客・売上どちらも多い場合の安定感 | 売上追加のUIが直感的 | 顧客名を変更したら全売上に自動反映 |
| デメリット | 顧客名を変更したら再ルックアップ必要 | CSVでの売上一括更新が不可 | 住所・TELなどを複数フィールドに分けられない |
RDB脳で設計するとつい1テーブル=1アプリで作っちゃいがちですが、ユースケースによっては「マスタアプリは作らずにドロップダウンで十分」みたいに、色々とkintoneならではの最適解を考える必要があります。
この辺が楽しくもあり、悩ましくもあるんですよねー。
(うんうん頷いてくれるのが目に浮かびますよ皆さん!)
N:Mの結合
「多対多」とも言いますね。
上記の1:Nを発展させて「商品」「顧客」「売上」の3エンティティで考えてみましょう。
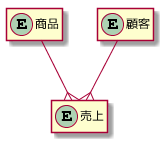
商品:売上 = 1:N であり、間接的に商品:顧客 = N:M となります。
これをkintone上で表現する場合、代表的な例はこんな3通りかな。
- 商品アプリ、顧客アプリ、売上アプリをそれぞれ作成
- 売上から商品・顧客をそれぞれルックアップ
- 商品アプリ、売上アプリの2つを作成
- 売上から商品をルックアップ
- 売上のドロップダウンフィールドで顧客を選択
- 商品アプリ、顧客アプリの2つを作成
- 顧客のサブテーブルに売上を登録
- 売上サブテーブル内で商品をルックアップ
本当はもっとバリエーション考えられますが省略。
特に最後の「サブテーブル&ルックアップを組み合わせると、2アプリで多対多が実現できる」
って方法がkintoneの面白いところですね。
データ移行 RDB→kintone
各種パターンが出揃ったところで、いよいよデータ移行を考えましょう。
RDBMSの機能でテーブル別にCSVをdumpすることも可能ですが、SQLでSELECT文を書いて、kintoneにそのまんまCSVインポートできる形で出力してあげるのがより良いと思います!
オンラインツール SQL Trainer
弊社SonicGardenの@mah_lab氏が開発した、オンラインでSELECT文を試せるツールがあります。このツールでそのまま流せるSQLを書いて、kintoneにインポートするところまでやってみたいと思います!
http://sql-study.mah-lab.com/
たくさんテーブルが用意されていますが、今回使うのは親1つに子2が並列してるこんな3テーブル2。ブログサービスのユーザー・記事・アクセス履歴と考えてください。
- service_users(ユーザ)
- entries(記事)
- access_histories(アクセス履歴)
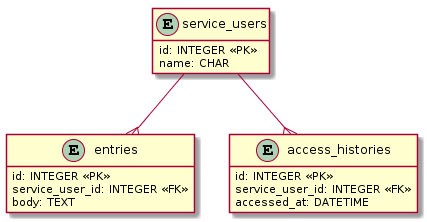
これはN:M結合ではなく、1:N結合が別々に2つある状態です。
1:Nのやり方を確実に押さえればN:Mはその応用でいけちゃうので、N:Mに特化した解説はしません。
試しに、普通にSQLを書いて実行してみましょう。これをツールにコピペして「Run」ボタンを押してください。
SELECT
u.name,
e.id as entry_id,
e.body as entry_body
FROM
service_users AS u
INNER JOIN
entries AS e ON
u.id = e.service_user_id
ORDER BY
e.id
LIMIT 3
ユーザ名とブログ記事が結合されて、こんな風に出力されればOK!
サンプルのSELECT文を即試せるWebツールがあるって最高ですねー ![]()
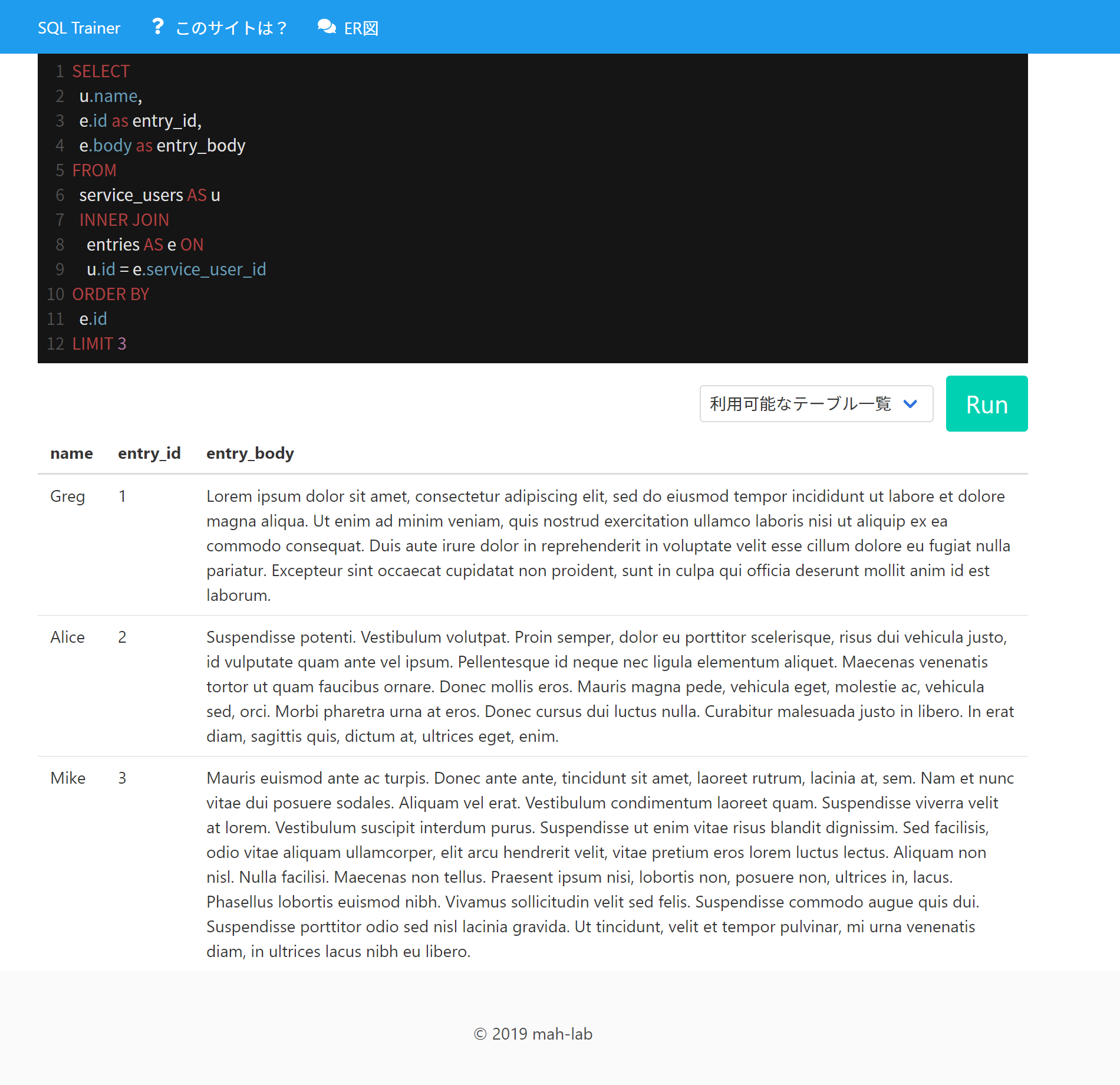
出力結果の表は、ブラウザ画面をドラッグ選択してExcelやGoogleスプレッドシートに奇麗にコピペできます。その先は普通にファイル保存してkintoneへインポート可能ですね。
ちなみにSQL文の整形にはこのオンラインツールが便利です。この記事のSQL整形にも使わせてもらいました。
SQLフォーマッターFor WEB
これで準備OK!ここからkintone向けの整形をやっていきます。
(やっと本題に入れるw)
各パターン別のSQL例
1テーブル → 1アプリ
まずは基本形。JOINはナシで、
service_usersテーブルだけkintoneに移行してみます。

SELECT
id AS "ユーザID",
name AS "ユーザ名"
FROM
service_users
ORDER BY
id ASC

AS でkintone側のフィールド名と一致させておくのがポイントです。そうすると、CSVインポート画面での紐づけが自動的にされますからね。
kintone側のフィールドコードは自由ですが、移行元DBのテーブル名.カラム名が連想できるような名前にしておくと、移行後にトラブったときの照らし合わせなどスムーズになると思います。

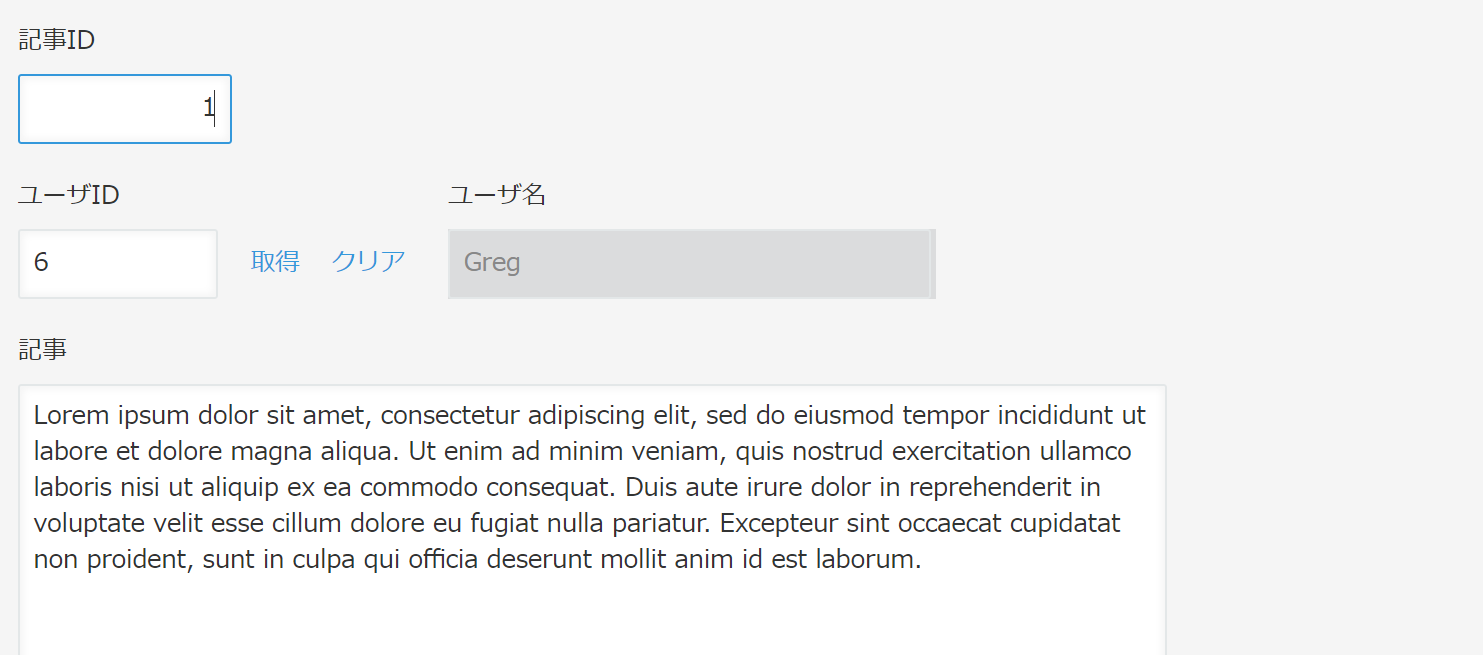
1親テーブル, 1子テーブル → 2アプリ
次は1つだけJOINする例ですが、kintone側を2アプリ構成(記事→ユーザをルックアップ)にすると、SQL的にはシンプルにすみます。アプリ2つ分のCSVを分けて作り、それぞれインポートする形ですね。
ユーザアプリ
記事アプリ
SELECT
id AS "ユーザID",
name AS "ユーザ名"
FROM
service_users
ORDER BY
id ASC
SELECT
e.id AS "記事ID",
u.id AS "ユーザID",
e.body AS "記事"
FROM
entries AS e
INNER JOIN
service_users AS u ON
u.id = e.service_user_id
ORDER BY
"記事ID" ASC
ルックアップに関する制約がポイントですね。
- ユーザのSQLは変わらないが、ユーザIDフィールドを重複禁止にしておく(ルックアップキーにするので)
- 記事のSQLに「ユーザ名」は不要(ルックアップコピーされるので)
- インポートは必ずユーザー→記事の順で行う
1親テーブル, 1子テーブル → 1アプリ, 1サブテーブル
さて、だんだん複雑になります。サブテーブルの登場。
ユーザアプリのサブテーブルに、ブログ記事を直接書いてしまいます。
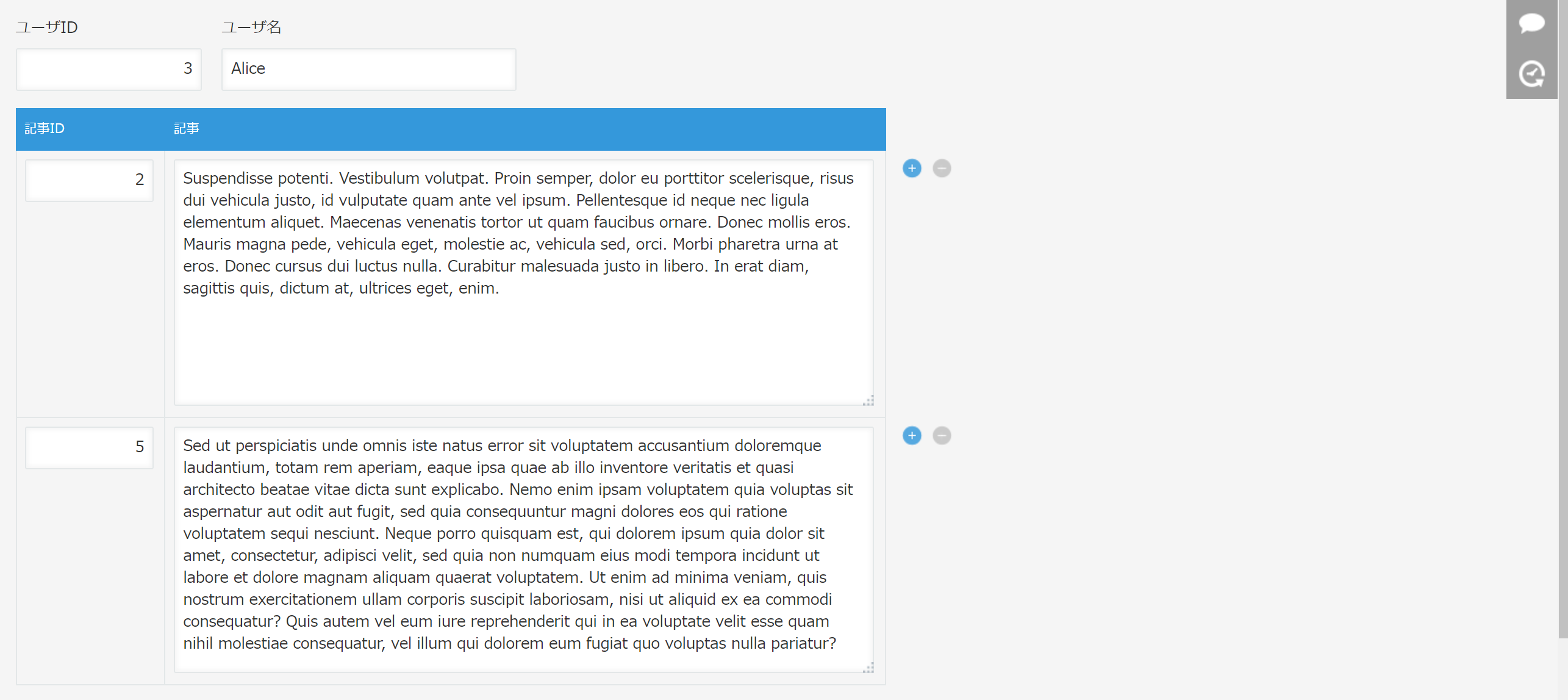
サブテーブルをCSVインポートするのって、列構成が面倒くさいんですよねー。僕がkintoneを使い始めた時はそもそもインポート不可能で、途中で機能追加されたけども使いにくいー!って思ったのを覚えています。
このジョイゾーさんの記事がとってもわかりやすいので必読!
【17年8月度版】テーブルデータのCSV読み込みが可能になりました
一番のポイントがレコードの開始行に*を入力するというルール。これをSQLで表現するのに一工夫いります。
まずはSQLと出力結果から見ましょう。
SELECT
CASE
WHEN u.id <> COALESCE(LAG(u.id) OVER(ORDER BY u.id), 0) THEN '*'
END AS "レコードの開始行",
u.id AS "ユーザID",
u.name AS "ユーザ名",
e.id AS "記事ID",
e.body AS "記事"
FROM
service_users AS u
LEFT JOIN
entries AS e ON
u.id = e.service_user_id
ORDER BY
"ユーザID" ASC,
"記事ID" ASC
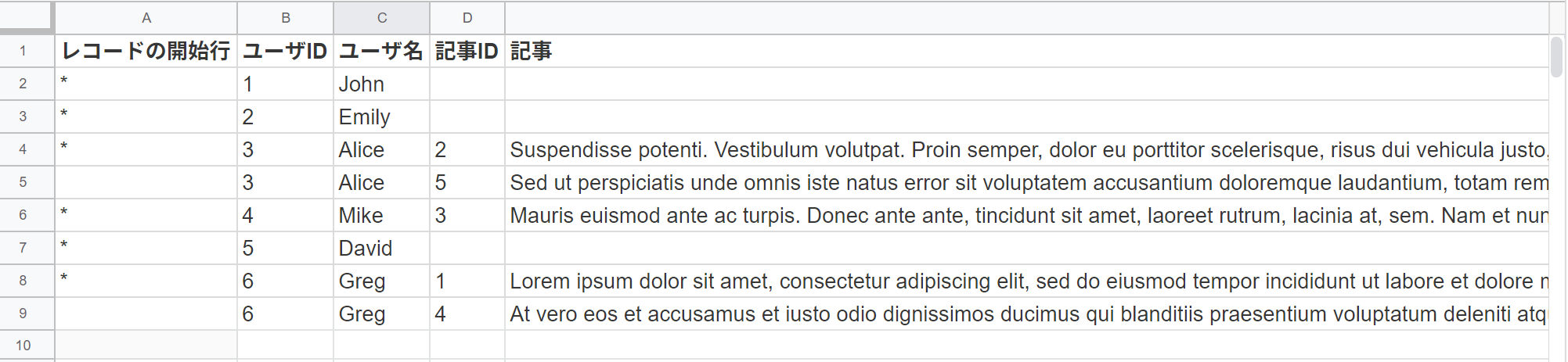
これで問題なくインポートできます!いい感じ。
さてSQLの難易度は一気に飛躍しましたが、今回のポイントはこのへん。
-
LEFT JOINでブログ記事が存在しないユーザも漏れなく取得 - レコードの開始行を示す
*を出力するには-
CASEによる条件分岐 - ウィンドウ関数
LAGで前の行と比較、ユーザIDの境目を判定 - 1行目の
LAGはNULLになるので、COALESCEを使ってNULLを0に置換する
-
ウィンドウ関数は最近この記事で知って、とっても便利だなーと思ったので早速LAG使ってみました。
そろそろSQLのウィンドウ関数を理解したい - 連載1/3話
LAG関数の解説はこの記事が丁寧でわかりやすい。
【BigQuery】LAG関数,LEAD関数の使い方
今回は「ユーザIDの境目がレコードの境目」なので、「前の行とユーザーIDが異なる場合は*」ってロジックです。スマートですね。
しかし、もしCOALESCE使わず単純にこう書いた場合、
CASE
WHEN u.id <> LAG(u.id) OVER(ORDER BY u.id) THEN '*'
END AS "レコードの開始行",
1行目だけ*は出ずに空欄になってしまうんです。なぜか?
先頭行のLAGの結果は、その前の行が存在しないのでNULLです。
普通のプログラミング言語だと、1 != nullはtrueになるじゃないですか。ところがSQLは独特で、1 <> NULLは「true falseどっちでもなく、unknownという第3の値」になっちまうんです!
3値論理とNULL (1/3):CodeZine(コードジン)
--以下の式は全部 unknown に評価される。 1 = NULL 2 > NULL 3 < NULL 4 <> NULL NULL = NULL
1 <> NULL → unknownとして評価されると、CASE文のTHENには行かないので、結果は*じゃなく空欄になってしまうんですね。
これがSQLの仕様ですが、そんな中でも、1行目にちゃんと*を出したい。
これを解決するにはいくつか方法があるけど、今回は「<>で比較する前にNULLを数値に置換しておく」ことにしました。そのために使うのがCOALESCE。
CASE
WHEN u.id <> COALESCE(LAG(u.id) OVER(ORDER BY u.id), 0) THEN '*'
END AS "レコードの開始行",
第二引数には0を入れました。「ユーザIDは必ず1以上」とデータから確認できているので、「0であれば、必ず<>での比較結果はtrue」ということです。
COALESCEについての解説は、この記事が分かりやすかった。
SQL関数coalesceの使い方と読み方
1親テーブル, 2子テーブル → 1アプリ, 2サブテーブル
さーいよいよ最後。1アプリ内に2つのサブテーブルが存在する場合です!
「アクセス日時」のkintoneフィールドは、「日時型」にしました。
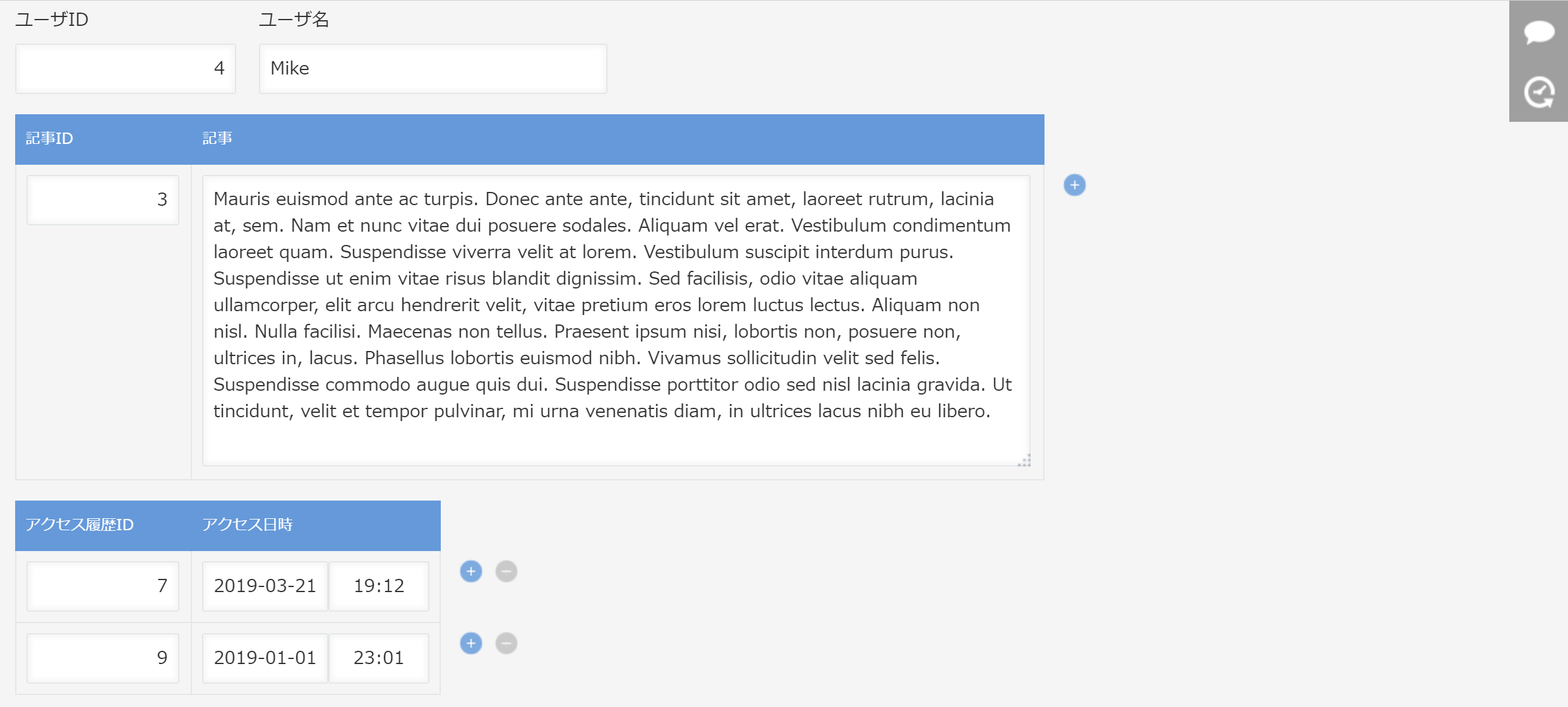
今回はまず、最終的に作りたい表から見てみましょう。
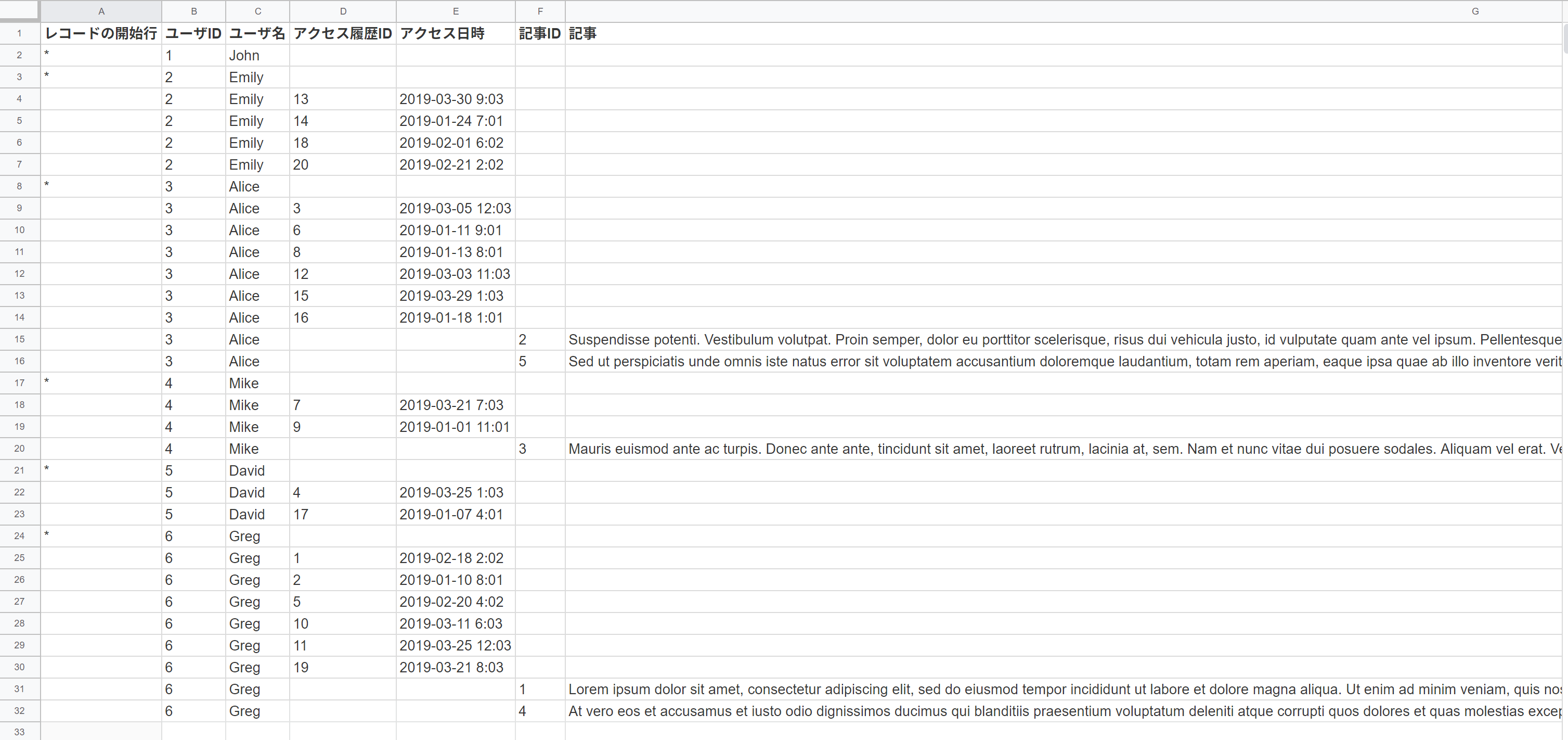
サブテーブル2つをインポートする場合に一番気を付けなければいけないのが、CSVの1行内に複数サブテーブルの値を載せてはいけないということです。
仮にサブテーブル行が1行ずつしかなくても、こんな表をインポートしようとすると叱られます。


以下の2パターンならどっちでもOK。(インポート結果も同じ)
前者のように親データとサブテーブルのデータは被って良いんだけど、全く被らない後者のスタイルの方が作りやすいので、後者の作り方を解説します。


サブテーブル1つバージョンとはガラッと変わり、こんなSQLにしてみました。
-- ユーザ x アクセス履歴の結合
SELECT
'' AS "レコードの開始行", -- UNION用の空列
u.id AS "ユーザID",
u.name AS "ユーザ名",
h.id AS "アクセス履歴ID",
to_char(h.accessed_at, 'YYYY-MM-DD hh:mm') AS "アクセス日時",
NULL AS "記事ID", -- UNION用の空列
NULL AS "記事" -- UNION用の空列
FROM
service_users AS u
INNER JOIN
access_histories AS h ON
u.id = h.service_user_id
UNION
-- ユーザ x 記事の結合
SELECT
'' AS "レコードの開始行", -- UNION用の空列
u.id AS "ユーザID",
u.name AS "ユーザ名",
NULL AS "アクセス履歴ID", -- UNION用の空列
NULL AS "アクセス日時", -- UNION用の空列
e.id AS "記事ID",
e.body AS "記事"
FROM
service_users AS u
INNER JOIN
entries AS e ON
u.id = e.service_user_id
UNION
-- ユーザ(結合なし)
SELECT
'*' AS "レコードの開始行",
u.id AS "ユーザID",
u.name AS "ユーザ名",
NULL AS "アクセス履歴ID", -- UNION用の空列
NULL AS "アクセス日時", -- UNION用の空列
NULL AS "記事ID", -- UNION用の空列
NULL AS "記事" -- UNION用の空列
FROM
service_users AS u
ORDER BY
"ユーザID" ASC,
"レコードの開始行" DESC,
"アクセス履歴ID" ASC,
"記事ID" ASC
今回のポイントはこのへん。行数は長いけど、難易度はさっきより低いかも。
-
SELECT文を複数書いて、UNIONで統合- それぞれのサブテーブルに存在しない列は
NULLを指定して何も出さない - せっかく
UNION使うので、レコードの開始行もLAGじゃなく単独SELECTでシンプルに
- それぞれのサブテーブルに存在しない列は
- 日時はそのまま出すと秒も付いてきてインポートができないので、
to_charでフォーマット
JOINの「結合」に対して、UNIONは「統合」と訳すようですね。同じ列構成の表を上下に並べるので、SELECT句での列指定をしっかりやっておく必要があります。
CASEを駆使すれば同様の結果は出せるかもしれないけど、UNIONの方がシンプルに書けて良いと思います。
詳しい解説はこちらを!
SELECT文を統合する「UNION」:SQL実践講座(9) - @IT
この方法はサブテーブル1つでも3つでも使えるので、「RDB→kintoneサブテーブルへの移行ならUNION」と覚えとくだけでも良さそうです!
後半はSQLそのものの勉強みたいになっちゃいましたが、RDBからkintoneへのデータ移行、この記事で紹介した4種類の方法を使い分ければ、必ずやスムーズにCSVが作れることでしょう!
おわりに
ここまで色々と書いといて言うのもなんですが、「本当にそのデータ移行、必要ですか?」というのは今一度問いたい。
RDBとkintoneは似ている部分もあるけど全然違います。なんだかんだでRDBの扱いやすさはエンジニアにとっては素晴らしく、深い部分まで行くとkintoneでは太刀打ちできません。RDB大好き人間のワタクシ、正直これまで、kintoneのDBとしての使いづらさにはかなり泣かされてきました。
RDBでガッツリ正規化されたデータベースを、本当にkintoneに移行するべきか?
移行するにしても、全データをkintone上で再現するのが最適なのか?クラウドRDBサービスを併用するのはどうか?
などなど、色々な選択肢があります。銀の弾丸はありませんが、ケースバイケースでしっかりと考えてアーキテクチャを検討しましょうね。