はじめに
この記事はElixirアドベントカレンダー2025シリーズ2の6日目の記事です。
本記事ではElixir版のJupyterNotebookと言われているノートブック型のWeb実行環境であるLivebook上で
生成AIを実行します
その際にMLXのElixirバインディングであるEMLXを使用してGPUで高速化を試みた内容になります
実行環境
Livebookとは
Livebookのインストール
上記のWebページにアクセスして
Install livebookをクリック
Mac(Universal)をクリックしてインストールバイナリをダウンロードして、インストールをしてください
インストールが完了したらアプリアイコンをクリックするとローカルホストでサーバーが起動されてWebブラウザでそのページを開いてくれます
MLXとEMLX
MLX は、Appleの機械学習研究チームによって開発されたAppleシリコン向けの機械学習用配列フレームワークで、
GPU等を操作するMetalを活用した高速な推論を実現してくれます。
EMLXはそのMLXをElixirの行列ライブラリNxを演算のオフロード先にするNx Backendライブラリです
Livebookで生成!
では実際にやってみましょう
ライブラリのセットアップ
新しいnoteを作成して [+Smart]をクリックするといくつか使用可能なものが表示されるので[Neural Network task]をクリックします
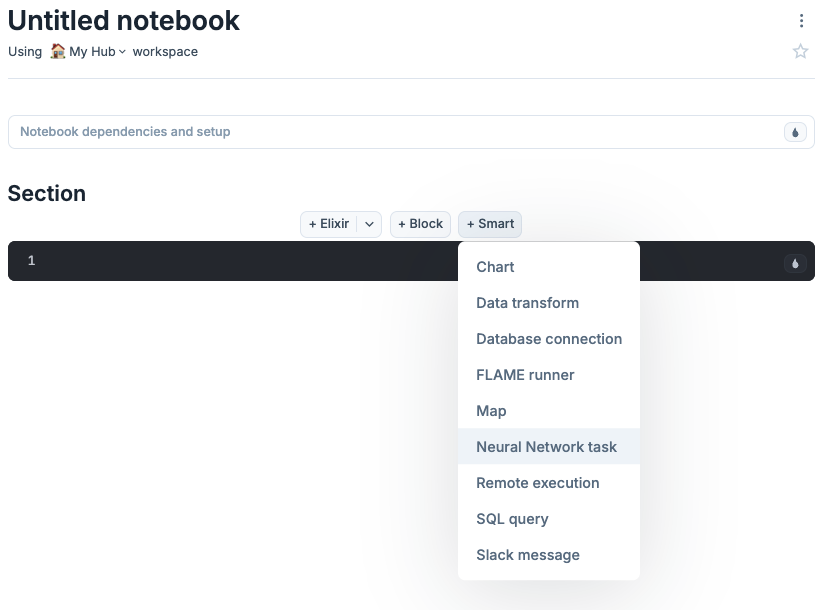
そうすると必要なライブラリの追加を促さられるので[+Add and restart]を押します
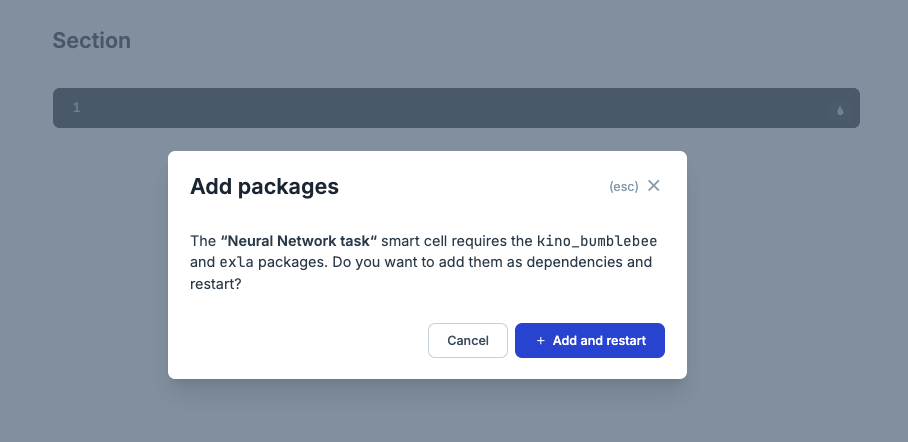
使用するライブラリが以下のように表示されます
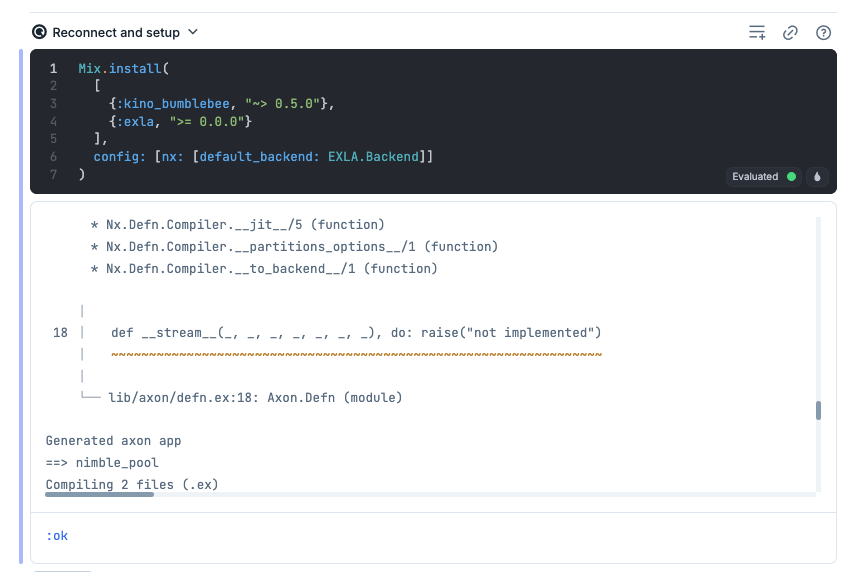
これを以下のように変更して[Reconnect and setup]をクリックするとライブラリのインストールが開始されます
Mix.install(
[
{:kino_bumblebee, "~> 0.5.0"},
{:emlx, github: "elixir-nx/emlx", branch: "main"}
], config: [nx: [default_backend: {EMLX.Backend, device: :gpu}]])
生成AI部分の作成
元々ノーコードで生成AI等を実行できるSmartCellという機能があるのでそちらに少し手を加えていきます
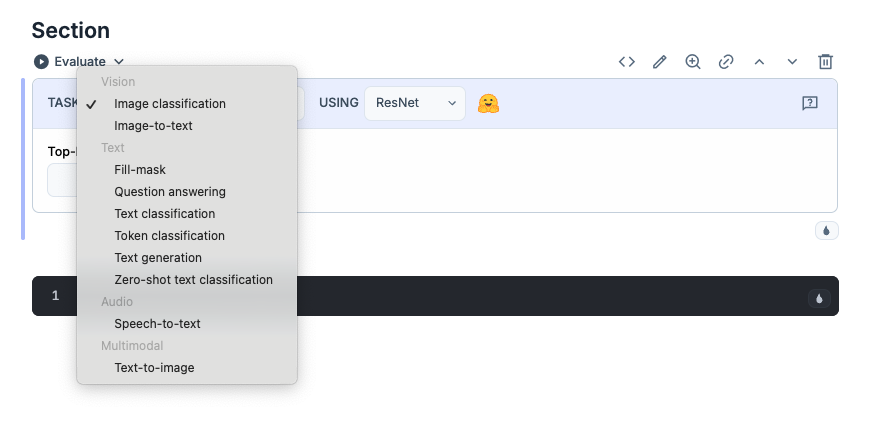
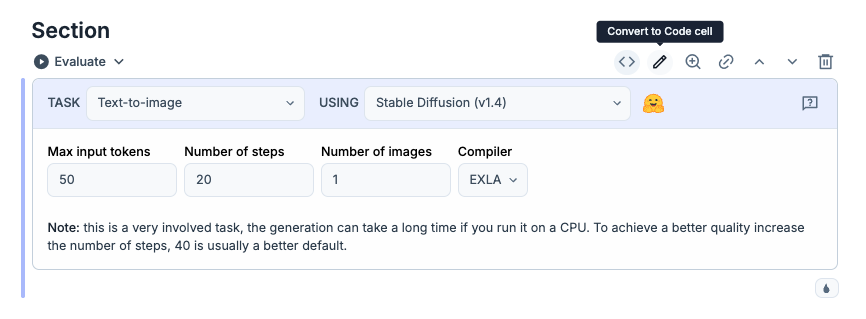
NeuralNetwork taskを選択すると以下のようなパーツがでるので、TASKを選択して Image classificationからText-to-imageに変更してください
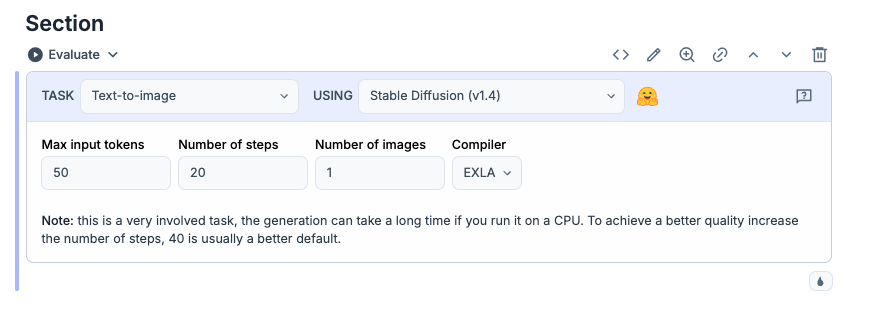
これで Evaluateを押すとモデルファイルのダウンロードが実行して以下の画面になるまでお待ち下さい
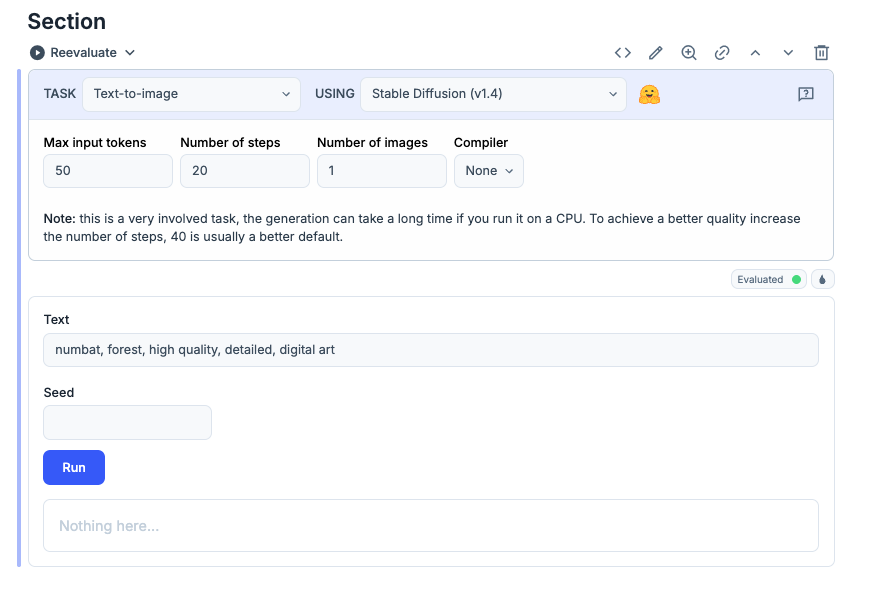
次は右上の鉛筆アイコンを押して、SmartCellを崩して編集可能なコードに変換します
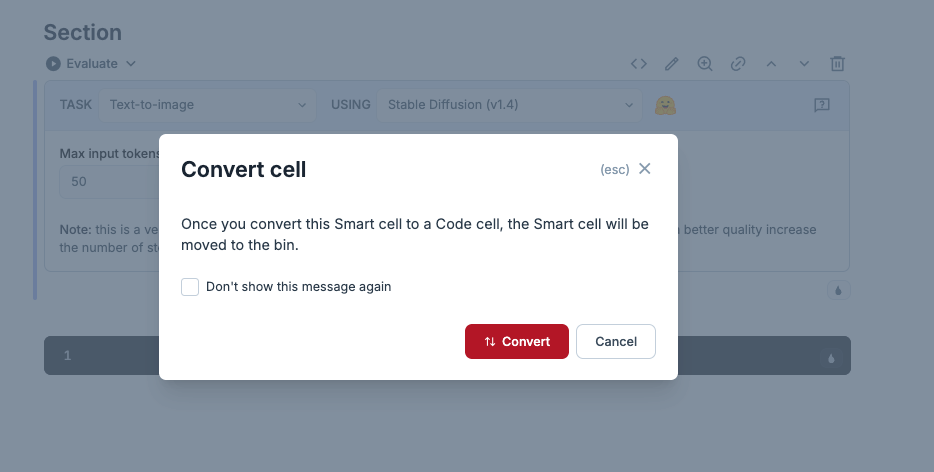
変換したら2つCodeCellができるので1つ目の以下のように書き換えます
Nx.global_default_backend({EMLX.Backend, device: :gpu})
repository_id = "CompVis/stable-diffusion-v1-4"
opts = [
params_variant: "fp16",
type: :bf16,
backend: {EMLX.Backend, device: :gpu}
]
{:ok, tokenizer} = Bumblebee.load_tokenizer({:hf, "openai/clip-vit-large-patch14"})
{:ok, clip} = Bumblebee.load_model({:hf, repository_id, subdir: "text_encoder"}, opts)
{:ok, unet} = Bumblebee.load_model({:hf, repository_id, subdir: "unet"}, opts)
{:ok, vae} = Bumblebee.load_model({:hf, repository_id, subdir: "vae"},
[architecture: :decoder] ++ opts)
{:ok, scheduler} = Bumblebee.load_scheduler({:hf, repository_id, subdir: "scheduler"})
{:ok, featurizer}= Bumblebee.load_featurizer({:hf, repository_id, subdir: "feature_extractor"})
{:ok, safety_checker} =
Bumblebee.load_model({:hf, repository_id, subdir: "safety_checker"}, opts)
serving =
Bumblebee.Diffusion.StableDiffusion.text_to_image(
clip, unet, vae, tokenizer, scheduler,
num_steps: 20,
num_images_per_prompt: 1,
safety_checker: safety_checker,
safety_checker_featurizer: featurizer,
compile: [batch_size: 1, sequence_length: 50]
)
1目ができたら2つ目のEvaluateを押すと先程のFormが表示されるので適当なプロンプトを入れて生成します
最後の方にGPUがガッツリ使用されたのがわかります
使用したモデル
CompVis/stable-diffusion-v1-4
MacだとEMLXとは別にEXLAというNx Backendライブラリがあり、そちらはMacではGPU使えないのでCPUのみで比較するとだいたい以下のような差になりました
EXLA CPU mode 60秒
EMLX GPU mode 10秒
最後に
バックエンド変えるだけでめんどくさい設定は一切しないでGPUで生成AIが使えるのはすごいなと思いました
CUDAをUbuntuで使えるようにするのはほんとに辛い・・・
そこまでの速度は出ないが軽く試してみたいのであればMacでEMLXが最適かなと思うので、ぜひ皆さんも試してみてください
本記事は以上になりますありがとうございました