Tensorflow をつかってデータを学習させていたのですが、結構高い確率で、うまく学習が進まない状況に陥ります。
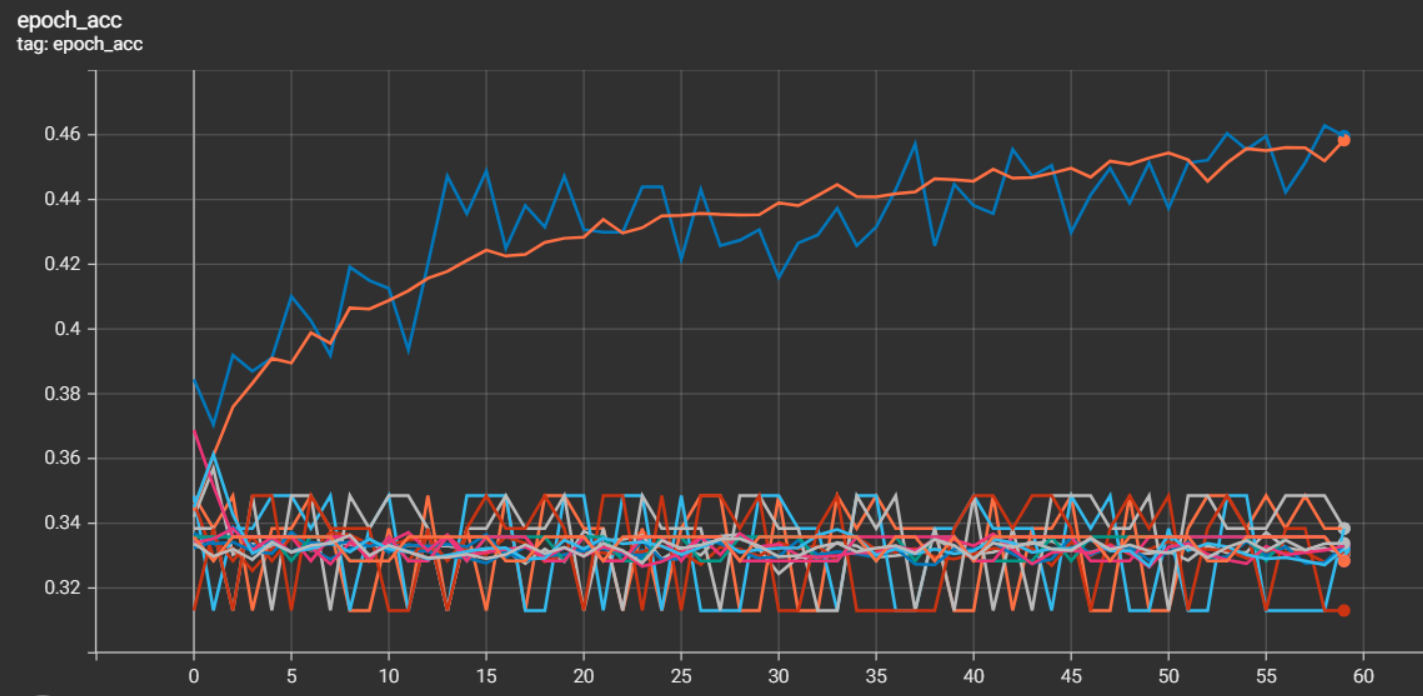
上図の0.31~0.35くらいで振れているのが、学習に失敗したパターン。
一応右肩上がりのオレンジ(Training)とブルー(Validatation)が上手くいったパターン。
予測難度の高いデータなので、そこは仕方ないのですが、1 回の学習(60 エポック)に 1 時間くらいかかっているので、せめて無駄な学習をエポックの途中で自動中断できないものかと模索していました。そこでkeras.callbacks.EarlyStoppingを使う手段にたどり着きます。
EarlyStopping (下記URLより引用)
tf.keras.callbacks.EarlyStopping( monitor='val_loss', min_delta=0, patience=0, verbose=0, mode='auto', baseline=None, restore_best_weights=False, start_from_epoch=0 )監視する値の変化が停止した時に訓練を終了します.
引数
- monitor: 監視する数量。デフォルトは "val_loss"
- min_delta: 改善とみなされる監視対象量の最小変化、つまり min_delta 未満の絶対変化は改善なしとしてカウントされます。デフォルトは 0
- patience: 改善が見られず、その後トレーニングが停止されるエポックの数。デフォルトは 0
- verbose: 詳細モード、0 または 1。モード 0 はサイレントで、モード 1 はコールバックがアクションを実行したときにメッセージを表示します。デフォルトは 0
- mode: {"auto", "min", "max"}の一つ。"min" モードでは、監視されている量が減少しなくなったときにトレーニングが停止します。"max" モードでは、監視される量の増加が停止すると停止します。"auto" モードでは 、監視される数量の名前から方向が自動的に推測されます。デフォルトは "auto"
- baseline: 監視対象の量のベースライン値。None でない場合、モデルがベースラインに対して改善を示さなければトレーニングは停止します。デフォルトは None
- restore_best_weights: 監視対象の数量の最良の値を持つエポックからモデルの重みを復元するかどうか。False の場合、トレーニングの最後のステップで取得されたモデルの重みが使用されます。baseline に対するパフォーマンスに関係なく、エポックが復元されます。 baselineを改善するエポックがない場合、トレーニングはエポックに対して実行されpatience、そのセット内の最良のエポックから重みが復元されます。デフォルトは False
- start_from_epoch: 改善の監視を開始する前に待機するエポック数。これにより、改善が期待できないウォームアップ期間が設けられるため、トレーニングが中止されることはありません。デフォルトは 0 ←注:Tensorflowのバージョンが古いと使えない模様
つまり、この EarlyStopping を使うと以下の状況で訓練を終了してくれます。
残念ながらどちらか片方でも 該当すると停止させられてしまいます。
でも、私が求めていたのはシンプルに
val_acc が 10 エポックの間に 0.355 を超えなかったら中断
というものでした。オリジナルの EarlyStoppingだと、min_deltaで引っかかってしまい、時間をかけて最高値を更新することがあるのケースでも中断されてしまい、このままでは使うことができませんでした。そこで ChatGPT 先生に聞いてみたところ、カスタムで作成できることを提案されます。
最初は想定と違うものが出てきましたが、ちょっと修正して理想通りのカスタム EarlyStoppingが出来上がりました。(下記)
from tensorflow.keras.callbacks import Callback
class CustomEarlyStopping(Callback):
def __init__(self, monitor='val_accuracy', baseline=0.36, patience=10, verbose=1):
super(CustomEarlyStopping, self).__init__()
self.monitor = monitor
self.baseline = baseline
self.patience = patience
self.verbose = verbose
self.wait = 0
def on_epoch_end(self, epoch, logs=None):
current = logs.get(self.monitor)
if current is None:
return
if current > self.baseline: # チェック値が指定より大きい(良い)
self.wait = 0
else: # チェック値が指定値より悪い状態
self.wait += 1
if self.wait >= self.patience:
if self.verbose:
print(f"\nEpoch {epoch + 1}: early stopping. Validation accuracy did not improve from baseline {self.baseline}.")
self.model.stop_training = True
実際に使うときは
early_stopping = CustomEarlyStopping(
monitor='val_acc', # val_accを監視
patience=10, # 10エポック連続で改善しなければ停止
verbose=1, # ログ出力
baseline=0.355, # ベースラインを設定
)
model.fit(x=X_train, y=y_train, validation_data=(X_eval, y_eval),
epochs=EPOCH, batch_size=BATCH,
callbacks=[tensorboard_callback, early_stopping],
verbose=VERBOSE)
これを組み込んで実行すると、"val_acc" の値が直近 10 エポックの間、ベースラインの値(0.355)を超えない場合は、学習を停止してくれるようになりました。
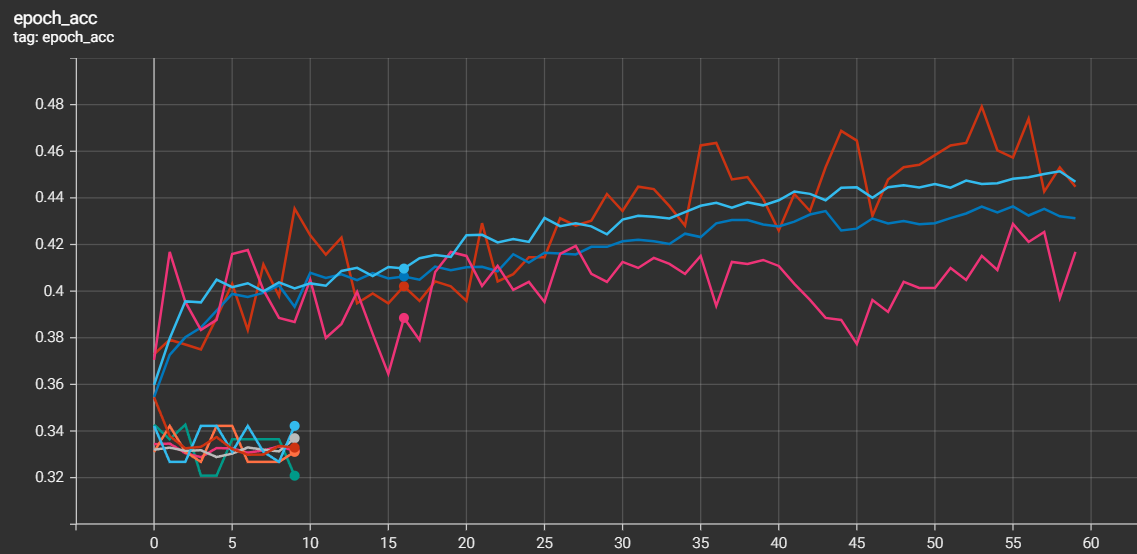
例えば 1 エポックが60秒かかるとすると、60 エポックで 60 分。学習に失敗して使えないモデルになるときに、1セッションあたりで、無駄にしていた50 分を節約できるという素晴らしい結果となりました 🎉
シンプルなコードなので、上記以外の条件での中断も簡単に記述できそうです。
よろしければご活用ください。
機械学習を始めて間もないのですが、いろいろ分からないことに遭遇します。でも、思うように意図した情報にたどり着けないこともあって、ChatGPTと共同作業で何とか乗り越えています:)
今回もその一例でした。
この学習が失敗するパターンは、3クラス分類をさせているのに予測で特定の1つのクラスにしか分類されていない状態なのですが、何か特定の表現あるのでしょうか?
画像認識では「モード崩壊」という表現があるようですが、同じ状況のようです。英語で「Class Collapse」という表現があるみたいで日本語にすると「クラス崩壊」。学級崩壊みたいな表現になって使いにくいですね…💦