[AI51] Custom Vision で出来ること & 出来ないからって諦めてませんか? / 2019年5月30日
TL;DR(要約)
- Custom Visionで構築したモデルをエクスポートし、ローカルで使用することができる。
- Custom Visionで精度を上げるには、前処理が一番大事(ノイズ取り、不用箇所除去、データの水増し)である。
- 実装方式早見表にしたがって、環境、推定方法を考えるとよい。
リソース
Micfrosoft Custom Vision Serviceを利用して、画像を分類する
感想
Custom Visionで推論したモデルをローカルで使用できるので、推論することが目的にならないように、簡単に業務化したい場合に、コストパフォーマンスがよく、使いやすいと感じた。
とりあえずは、ハンズオンを利用して学習してみよう思います。
講師
Custom Visionの効果的な使い方を知りたい
実際に使ったことがある。
来場者の事例
- PoCで、飲食店のポップやメニューの料理の色味のデザインとしてどのようなものが良いのか
- イメージをつかみたいという場合に、Custom Visionを使うのがわかりやすく示すことができて、社内説明と顧客説明を効果的にすることができた。
- プロトタイプで商品の写真からJANコードを抜き出す際に使った
- 100%でなくてもビジネスになるという事例
Custom Visionのコンテナ
最近はコンテナでやることができるので、推論はローカルですることができる。
Custom Visionのコンテナは、今はお金がかからない。他のコンテナは、Azureと通信するのでお金がかかる
https://docs.microsoft.com/ja-jp/azure/cognitive-services/computer-vision/computer-vision-how-to-install-containers
https://qiita.com/annie/items/21bb726e9bbc8db56e54
Custom Visionの概要


そもそもComputer Visionで何がしたい?
現愛よく使われているのは、製造業で多い

よく使われている検知のシナリオ。
証拠の動画や、立ち入り禁止の場所。不正アクセス。安全性チェックに使用する。
【事例】ビジネス的な話として工場の計器類を判定できないか?
- 今のメーターを読めないか?ちゃんとしたところに言うと、3パターンぐらいならできる。定点カメラのほうが向いている。カメラの向きがずれると違うものになるので、そこは別(運用の問題)
- 今ある機器を変更するのはお金がかかるし安定稼働の分に問題、1秒おきに送ってみていくという話もあるかもしれない。
Custom Visionで精度上げる方法
-
データ以外で精度を上げる方法があるのか
- 前処理
- ノイズをとること(OpenCV)
- とりすぎるとよくない
- カラーの写真を白黒にする
- モノクロにすることで余計な情報をなくす
- ビジネスの場合に、白黒化することで精度が高くなる。下手にアルファチャンネル(透明)が問題になってくることが多い
- モノクロにすることで余計な情報をなくす
- 不要な部分を切断する
- ノイズをとること(OpenCV)
- データの水増し(Data Argumentation)をすることが大事になってくる。
- 前処理
-
定点カメラ
- ビジネスの場面では、定点カメラを使うことが多い
小技
- トレーニングを2種類の方法でできるようになっている
Advanced Option
- 学習の時間を何時間までやっていいという指定が出てくる
- 色々よしなにやってくれる
- 時間を延ばすことでもうちょっと学習制度を上げてくれる。(細かいところは触れないが、色々な学習をしてくれる)
- 終わってからメール
- ふつう何十秒だけなら長すぎ
- 時間を延ばすことでもうちょっと学習制度を上げてくれる。(細かいところは触れないが、色々な学習をしてくれる)
- 色々よしなにやってくれる
モデルをエクスポートするために
モデルをコンパクトにする
- モデルをコンパクトとした場合にだけ、Exportすることができる(ローカルで再利用できる)
ドメイン(どのようなものを判定するか)を絞り込む
- ドメインとして、どういう写真を学習するかということを選ぶが、すごく大事。何向けが強いか、ということはドキュメントに書いている。何も考えなくてもGeneralにすると、コンパクトにできなくなって、エクスポートできなくなる
Computer Vision と Custom Visionについて
- Custom Vision APIはカスタムできる。Computer Visionはあらかじめ決まっている。リトレーニングできない。無理。もしやりたければ自分でネットワークを書く
Custom Visionでできないこと
大きい写真
- 大きい写真はダメだが、あまりそういうことはないだろう
セグメンテーション
- セグメンテーションは、2017年。結構最近にできたものであり、ムズカシイ。実装されていない。
大量な枚数と回線
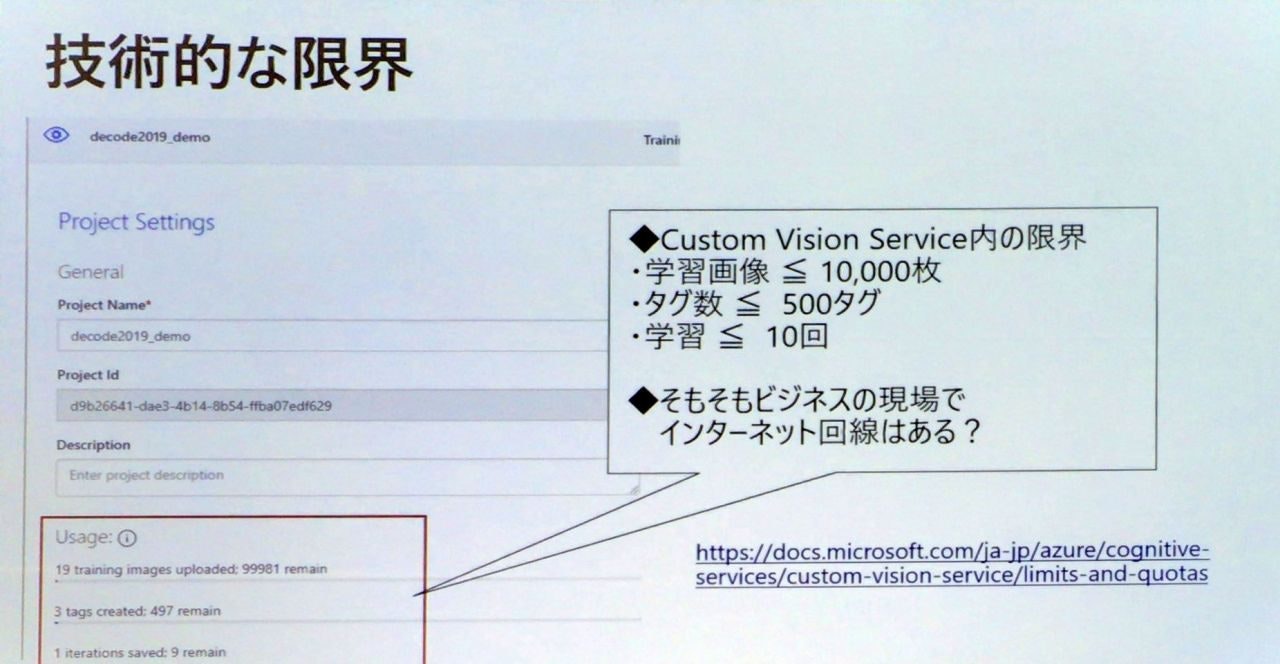
- Custom Vision Service内での限界
- 限界は100,000枚(画像が間違い)
- ちょっとしたPoCに使えるものである、と考えると良いのかもしれない
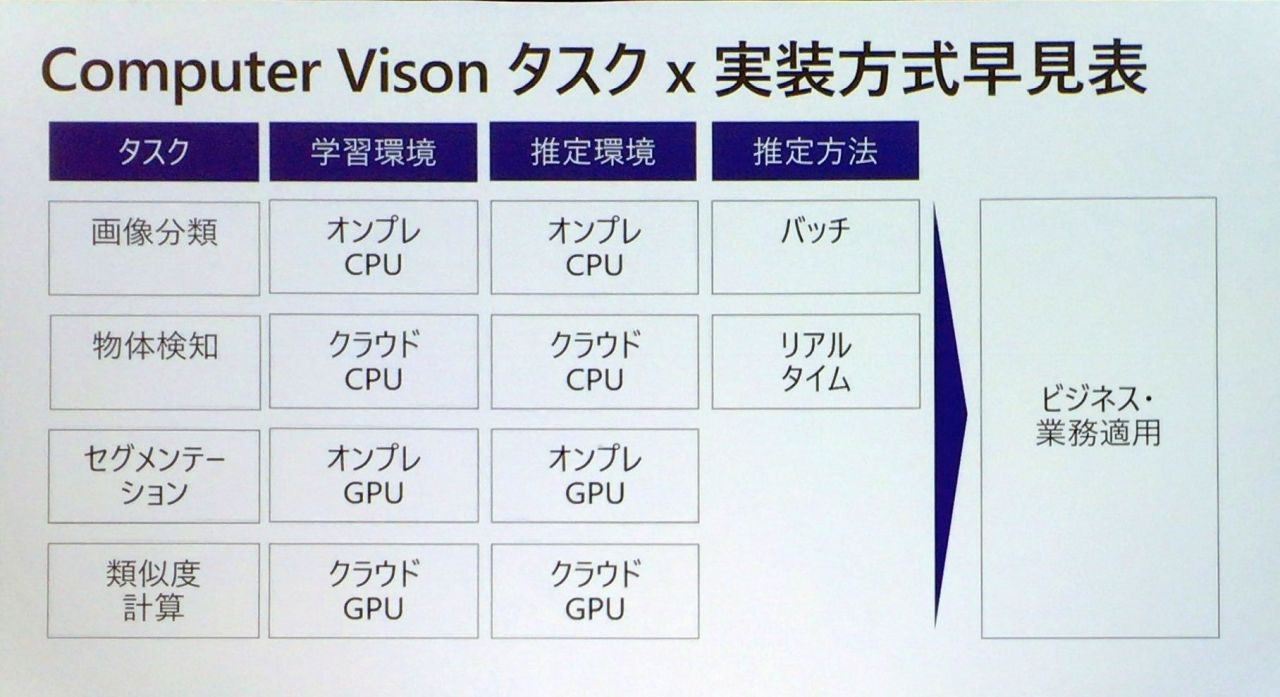
実装方式早見表
Edgeでの推定をどのように考えるのか?
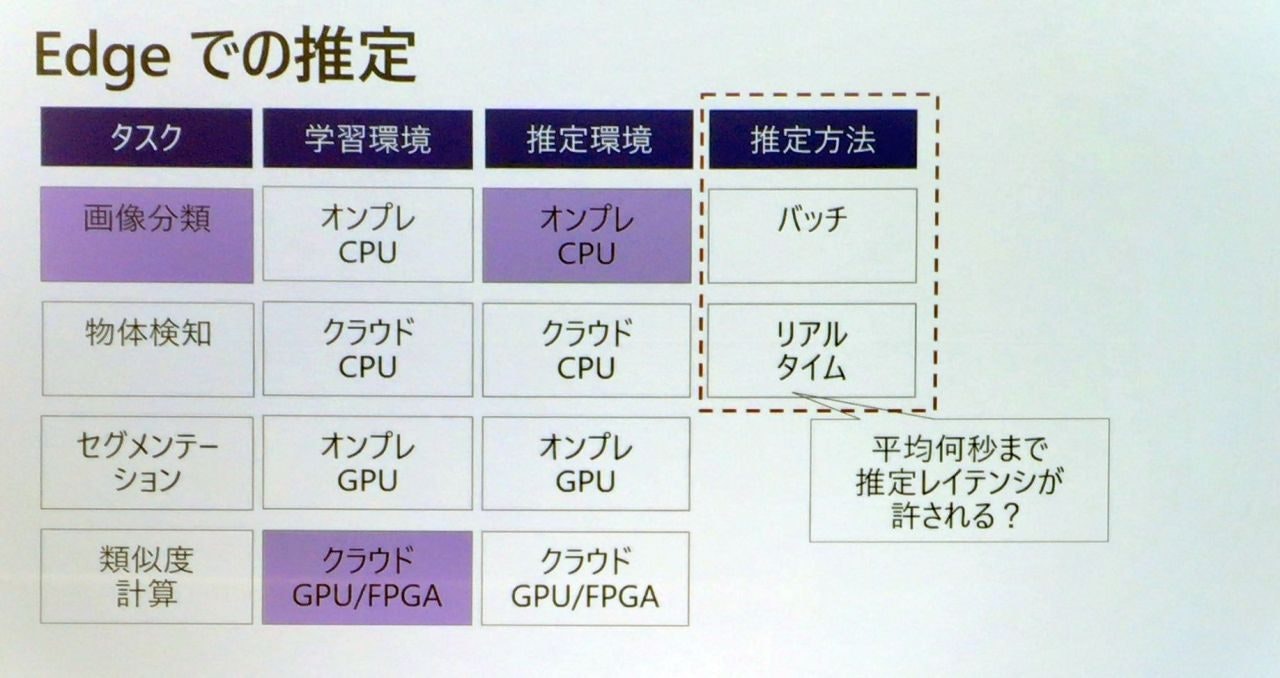
業務で必要なレイテンシ次第で推定方法をどのようにするかは考える。mmsecが必要だ、と言われたときにも、その業務で本当に必要かどうかがで考える
例えば、手術で必要な判断であれば、0.5sでは足りない
ちなみに、この図でのオンプレというと、tensorflowを指している
エクスポートについて
エクスポートは、ONNX(オニキス)というフォーマットでエクスポートする。
Windows MLというAPIで直接読みだしてロードする、tensorflowも不要。.NET Coreでオニキス対応しているので、tensorflowはいらない。
機械学習したら、ONNXでエクスポートしておけば、tensorflowでもML.NETでも読みだせる。
参考資料
https://qiita.com/ymym3412/items/05a7cecf81309a3f131e
https://docs.microsoft.com/ja-jp/azure/cognitive-services/custom-vision-service/custom-vision-onnx-windows-ml
コンパイラ
チップセットについてコンパイラが用意されているのでさらに早くなる
Micfrosoft Learnを使って、学習してみよう

Micfrosoft Custom Vision Serviceを利用して、画像を分類する
https://docs.microsoft.com/ja-jp/learn/modules/classify-images-with-custom-vision-service/
ハンズオン、ワークショップで使えるようなものが記載されているので、一通りやってみるとよい。