手っ取り早く、やられたシーンを抽出したい人向け
OBSと連携するWebアプリを作成しました
詳細はこちらの記事をご参照ください。
スプラトゥーン3で、やられたシーンをOBSのリプレイバッファで自動保存する
以前のWebアプリ
スプラトゥーン2 やられたシーン自動頭出しツール「iKut」
Dockerイメージ
こちらでDockerイメージを配布しています。
はじめに
スプラトゥーン2を発売日からやりこんで3年になります。2年かけて全ルールがウデマエXに到達しましたが、そこからXパワーが上がらずウデマエX最底辺で停滞しています。最近は自分のプレイ動画を見て対策を立てるのですが、すべての動画を見るのは大変です。そこで敵にやられたシーンは特に修正すべき自分の弱点があると考え、そこだけを自動で抽出するシステムを作ってみました。

↑このシーンを切り出します。
画像の引用
この記事では任天堂株式会社のゲーム、スプラトゥーン2のスクリーンショットを引用しています。
使用技術
他のスプラトゥーン関連の画像処理を行っている例では、テンプレートマッチングを使用しているものが多いですが、この記事では工数削減と他のシーン検出への発展性を考慮してディープラーニングで処理しています。さらにそのモデルもGoogle AutoML Visionで自分では調整などを全くせずに作っています。学習データはすべての画像を目視して人力で分類して作っていますが、Google Cloud Vision APIのテキスト検出を使い、仮である程度分類したあとに目視で間違いを修正する形で省力化しています。
システムの概要
分類モデル
プレイ動画中のやられたシーンの画像とそれ以外のシーンの画像を分類するモデルを作ります。やられたシーンには「○○でやられた!」といった表示が中央上あたりに表示されます。
| やられたシーン | それ以外のシーン |
|---|---|
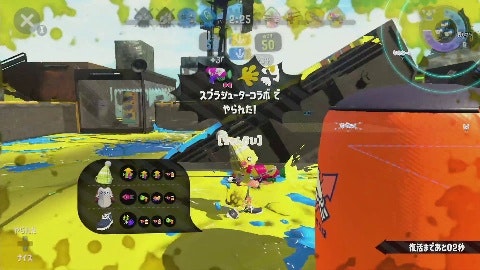 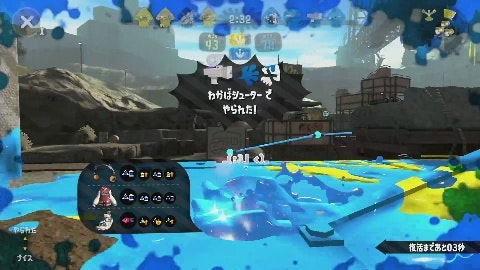
|
 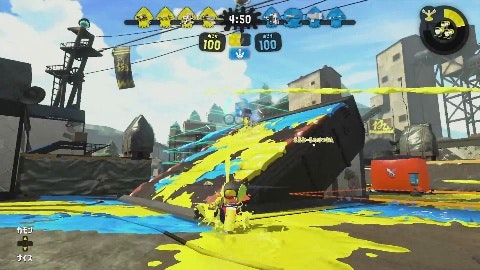
|
動画の切り出し
動画から0.5秒に1回フレームを抽出して前述のモデルで分類します。やられたシーンと分類された場合は、その数秒前から動画を切り出します。
前準備
Python
Pythonをインストールします。
OpenCV Python、TensorFlow、tqdmをインストールします。
この記事では学習をGoogle AutoML Visionで行うのでNVIDIAのGPUが無いPCでも良いです。
pip install opencv-python
pip install tensorflow
pip install tqdm
ffmpeg
ffmpegをインストールします。
Macの場合はHomebrewでインストール出来ます。
brew install ffmpeg
学習元動画を準備
まず試合の録画をmp4形式で10時間分用意して、 src_movie ディレクトリに格納しました。
合計録画時間の確認
OpenCVには動画から合計フレーム数と1秒あたりフレーム数を取る機能があります。それを使って合計録画時間を確認しました。
import os
import cv2
# 合計録画秒数
total_seconds = 0
# 元動画格納ディレクトリ
dirname = 'src_movie'
# 動画ファイル一覧
for name in os.listdir(dirname):
if name.endswith('.mp4'):
path = os.path.join(dirname, name)
# 動画を読み込む
cap = cv2.VideoCapture(path)
# フレーム数を取得
frame_count = cap.get(cv2.CAP_PROP_FRAME_COUNT)
# 1秒あたりフレーム数を取得
fps = cap.get(cv2.CAP_PROP_FPS)
# 秒数を取得
seconds = frame_count / fps
# ファイル名と秒数を出力
print("%s %d min" % (path, seconds / 60))
# 合計する
total_seconds += seconds
# 合計を出力する
print(total_seconds/3600)
3秒ごとにフレーム画像を切り出す
出力先として src_image ディレクトリを作ります。
OpenCVには動画からフレーム画像を抽出する機能があります。それを使って3秒ごとにフレーム画像を切り出しました。
import os
import numpy as np
import cv2
# 元動画格納ディレクトリ
src_dir = 'src_movie'
# フレーム画像格納ディレクトリ
dst_dir = 'src_image'
# 保存インデックス
save_index = 0
# 動画ファイル一覧
for name in os.listdir(src_dir):
if name.endswith('.mp4'):
path = os.path.join(src_dir, name)
# 動画を読み込む
cap = cv2.VideoCapture(path)
# 1秒あたりフレーム数を取得
fps = cap.get(cv2.CAP_PROP_FPS)
# 3秒に1回フレーム画像を取得する
skip = fps * 3
# フレームインデックス
i = 0
while True:
ret, img = cap.read()
if ret:
if i % skip == 0:
# フレームを縮小して保存する
shrink = cv2.resize(
img, (480, 270), interpolation=cv2.INTER_CUBIC)
out_path = os.path.join(
dst_dir, "frame%05d.jpg" % save_index)
cv2.imwrite(out_path, shrink)
print(out_path)
save_index += 1
i += 1
else:
break
12,227枚の画像が出来ました。
やられたシーンとそれ以外のシーンに半自動で分ける
12,227枚の画像を1枚1枚目視して、やられたシーンを拾おうと思いましたが、
実際やってみると大変だったので、Google Cloud Vision APIのドキュメントテキスト検出を使いました。やられたシーンには「○○でやられた!」という表示があるので、テキスト検出して「で」と「やられた」を含む画像をやられたシーンとして分類します。
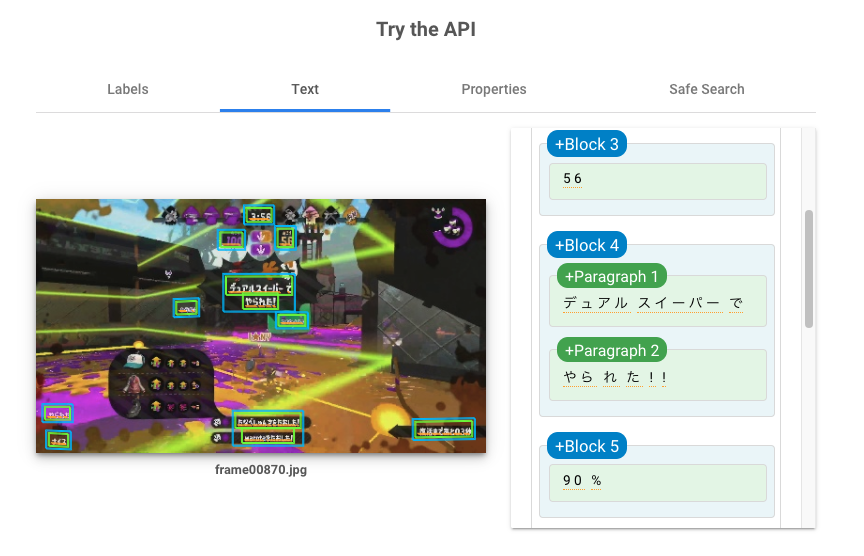
「で」をつけた理由はこのように味方から「やられた」シグナルを頂いたシーンを含まないようにするためです。

料金
Google Cloud Vision APIの呼び出しには無視できない金額がかかります。12,227枚の画像からテキスト検出するためには、約2,000円ほどかかります。
テキスト検出による分類を実行する
いったん全ての画像のテキスト検出結果をファイルに保存してから、検出されたテキストを処理して画像分類しています。画像分類は手直しの可能性が高く、Google Cloud Vision API呼び出しにはお金と時間がかかるためです。
すべての画像をテキスト検出結果をファイルに保存する
まず保存先ディレクトリとしてtextを作ります。
こちらのPythonスクリプトでAPIのレスポンスをすべて保存します。
認証周りについてはこちらの公式解説を参考にしてください。
import os
import subprocess
import pathlib
import base64
import requests
# フレーム画像格納ディレクトリ
src_dir = 'src_image'
# テキスト検出結果格納ディレクトリ
dst_dir = 'text'
# アクセストークンの取得
access_token = subprocess.check_output(
'gcloud auth application-default print-access-token', shell=True)
access_token = access_token.decode('utf-8').rstrip()
# フレーム画像一覧
names = []
for name in os.listdir(src_dir):
if name.endswith('.jpg'):
names.append(name)
names.sort()
for name in names:
print(name)
# テキスト検出元画像パス
path = os.path.join(src_dir, name)
with open(path, 'rb') as f:
data = f.read()
# 画像データをBase64に変換
b64data = base64.b64encode(data).decode('utf-8')
# リクエスト本文の作成
request_body = {
'requests': [
{
'image': {
'content': b64data
},
'features': [
{
'type': 'DOCUMENT_TEXT_DETECTION'
}
]
}
]
}
# Cloud Vision API呼び出し
r = requests.post('https://vision.googleapis.com/v1/images:annotate',
headers={'Authorization': "Bearer %s" % access_token},
json=request_body)
# レスポンスを保存する
if r.ok:
# 出力ファイル名
out_name = pathlib.PurePath(name).stem + '.json'
out_path = os.path.join(dst_dir, out_name)
with open(out_path, 'w') as f:
f.write(r.text)
else:
raise Exception('Vision API Error: %d' % r.status_code)
検出されたテキストを処理して画像分類する
やられたシーン格納ディレクトリとして train_1、それ以外のシーン格納ディレクトリとして train_0 を作ります。text ディレクトリにあるjsonファイルを読んで、src_image ディレクトリにある画像を train_0 train_1 に分類します。
import os
import pathlib
import json
import shutil
# フレーム画像格納ディレクトリ
image_dir = 'src_image'
# テキスト検出結果格納ディレクトリ
text_dir = 'text'
# フレーム画像一覧
names = []
for name in os.listdir(image_dir):
if name.endswith('.jpg'):
names.append(name)
names.sort()
for name in names:
print(name)
# フレーム画像パス
image_path = os.path.join(image_dir, name)
# テキスト検出結果を取得する
json_name = pathlib.PurePath(name).stem + '.json'
json_path = os.path.join(text_dir, json_name)
with open(json_path) as f:
responses = json.loads(f.read())
try:
description = responses['responses'][0]['fullTextAnnotation']['text']
except KeyError:
description = ""
# テキストを見て分類する
if 'で' in description and 'やられた' in description:
# 「で」「やられた」が含まれていていれば、train_1にコピー
train_path = os.path.join('train_1', name)
else:
# そうでなければ、train_0にコピー
train_path = os.path.join('train_0', name)
shutil.copy(image_path, train_path)
12,227枚中、596枚がやられたシーン、11,631枚がそれ以外のシーンに分類されました。
手動で手直しする
Finderで流すようにすべての画像を見て、誤った分類があれば手動で正しいディレクトリに置きます。
このように、やられたあとマップを見ているシーンもやられたシーン判定になっています。左下の上キーで「やられた」シグナルを出す案内と「復活まであと02秒」に「で」が含まれるためです。このケースは通常のマップを開いたシーンと大きな違いが無いため、それ以外のシーンに分類しました。テキストの位置を見るようにスクリプトを変更しても良かったのですが、手動で分類を直した方が早いと思いました。

「○○でやられた」テキストがあっても検出されなかった画像もありました。
その結果87枚をやられたシーンからそれ以外のシーンに移動して、20枚をそれ以外のシーンからやられたシーンに移動しました。2時間ぐらいかかりました。
Google AutoML Visionで分類モデルを作成する
Google Cloud Storageに画像とCSVをアップロードする
まずは分類済みの画像ディレクトリ train_0 と train_1 をGoogle Cloud Storageにアップロードします。
次に各画像のGoogle Cloud StorageのURLと分類ラベルを行にしたCSVファイルを生成します。2列目がdeathだとやられたシーンの画像、otherだとそれ以外のシーンの画像になります。
gs://tfandkusu_spla_cut/death/train_1/frame00029.jpg,death
gs://tfandkusu_spla_cut/death/train_1/frame00044.jpg,death
gs://tfandkusu_spla_cut/death/train_1/frame00048.jpg,death
略
gs://tfandkusu_spla_cut/death/train_0/frame00000.jpg,other
gs://tfandkusu_spla_cut/death/train_0/frame00001.jpg,other
gs://tfandkusu_spla_cut/death/train_0/frame00002.jpg,other
略
そしてCSVファイルもGoogle Cloud Storageにアップロードします。
最終的にはこのようになりました。
CSV作成スクリプト
CSVを作成するスクリプトはこちらです。
import os
train_1 = 'train_1'
train_0 = 'train_0'
train_1_images = []
train_0_images = []
for name in os.listdir(train_1):
if name.endswith('.jpg'):
train_1_images.append(name)
for name in os.listdir(train_0):
if name.endswith('.jpg'):
train_0_images.append(name)
train_1_images.sort()
train_0_images.sort()
for name in train_1_images:
print("gs://tfandkusu_spla_cut/death/train_1/%s,death" % name)
for name in train_0_images:
print("gs://tfandkusu_spla_cut/death/train_0/%s,other" % name)
このように実行します。
python train_csv.py > death.csv
Google AutoML Visionにインポートする
分類済みの画像を学習して、やられたシーンの画像とそれ以外のシーンの画像を分類するモデルをGoogle AutoML Visionを使って作成します。
Google Cloud Platformの左側のメニューからVision → ダッシュボードを選びます。
AUTOML APIを有効にします。
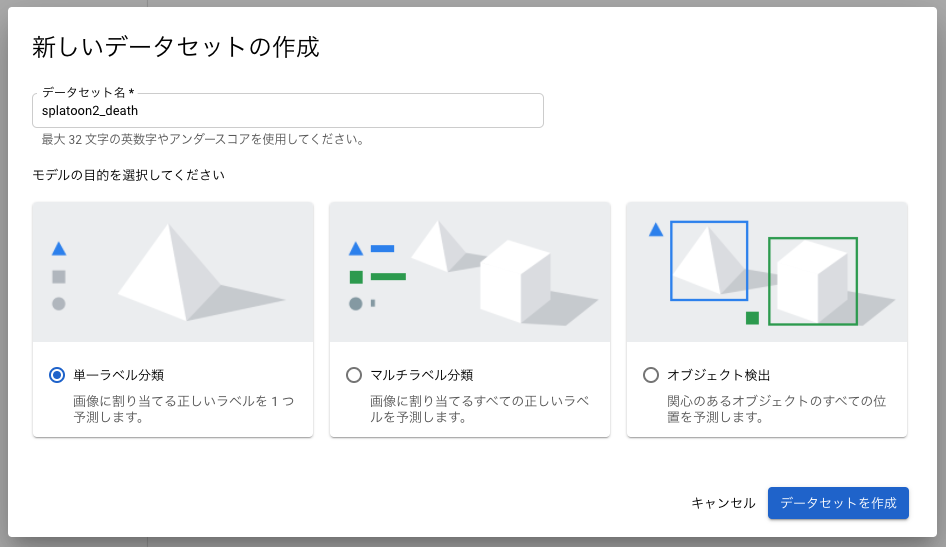
単一ラベル分類として新しいデータセットを作成します。
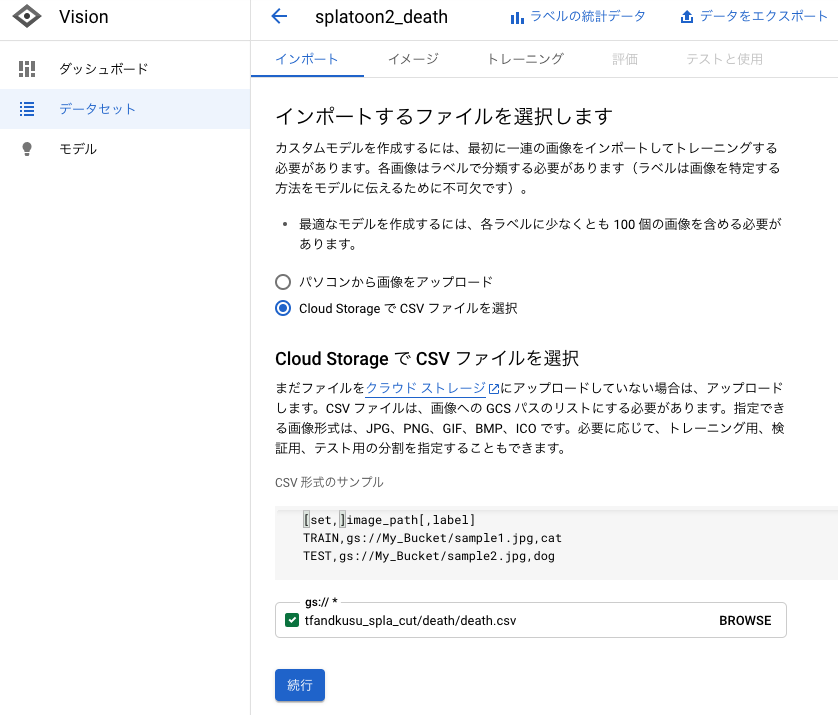
作成したCSVファイルのGoogle Cloud StorageのURLを指定することでインポートします。
インポートには時間がかかるのでしばらく待ちます。
インポートが完了しました。
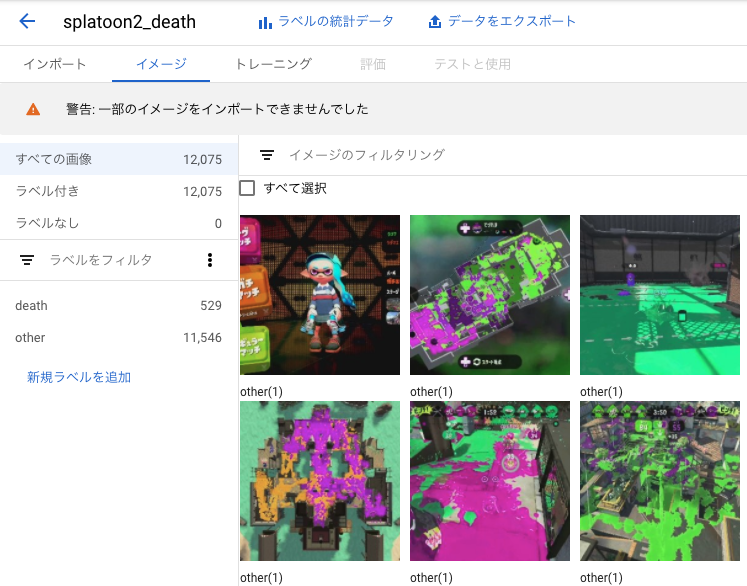
一部の画像はエラーが発生してしまいインポート出来ませんでした。原因はよく分からないですが、98.7%の画像はインポートに成功したのでそのまま進みます。
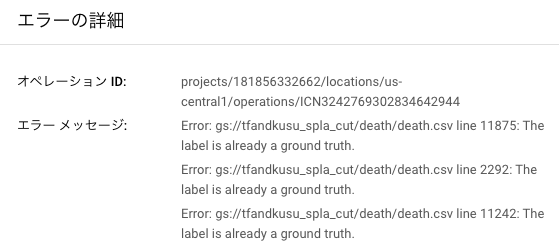
学習を行う
トレーニング タブを開くと、自動で画像がトレーニング用、テスト用、検証用に分けられていることが分かります。その3種類の違いはこちらで解説されていました。 トレーニングを開始 ボタンを押します。
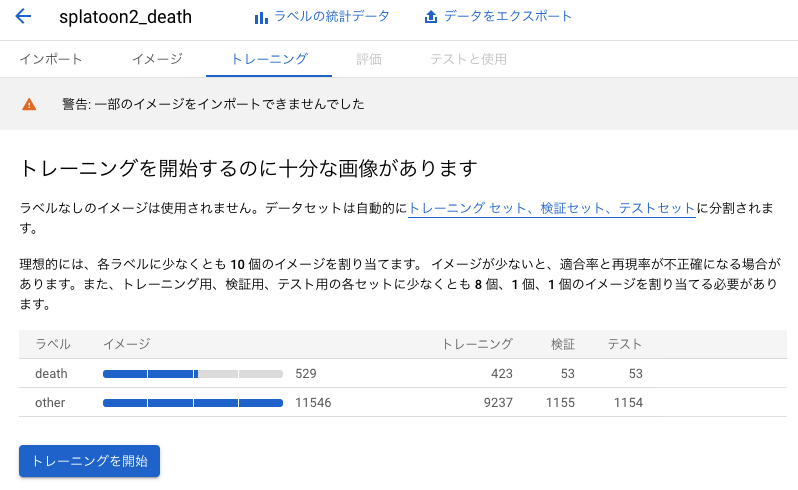
クラウドかエッジかを聞かれます。今回はあまりお金をかけないように手元のPCで分類したいのでエッジにします。
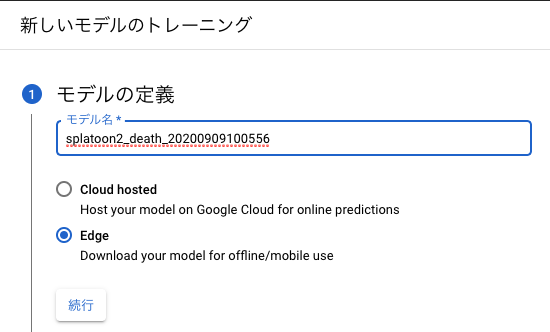
処理時間を優先するか精度を優先するか聞かれますが、モバイル端末で分類する予定はないので精度重視で行きます。

ノード時間予算もおすすめの10 node hoursにします。
料金はこちらです。
トレーニングを開始 ボタンでトレーニングが開始されます。
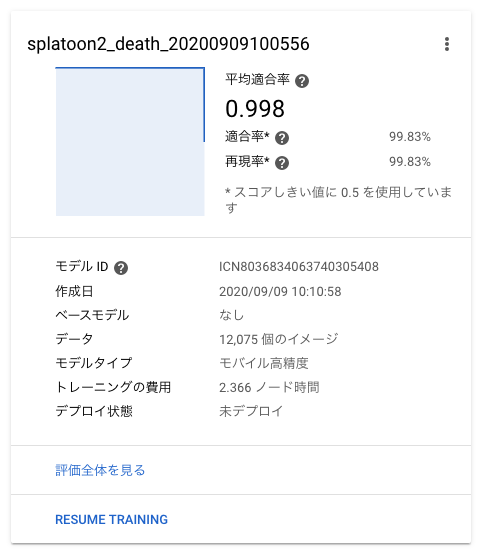
3時間ほどで学習モデルができて評価も出ました。
実際かかったノード時間は2.366でした。40までの無料枠があるようなので、その請求は来ませんでした。
評価を確認する
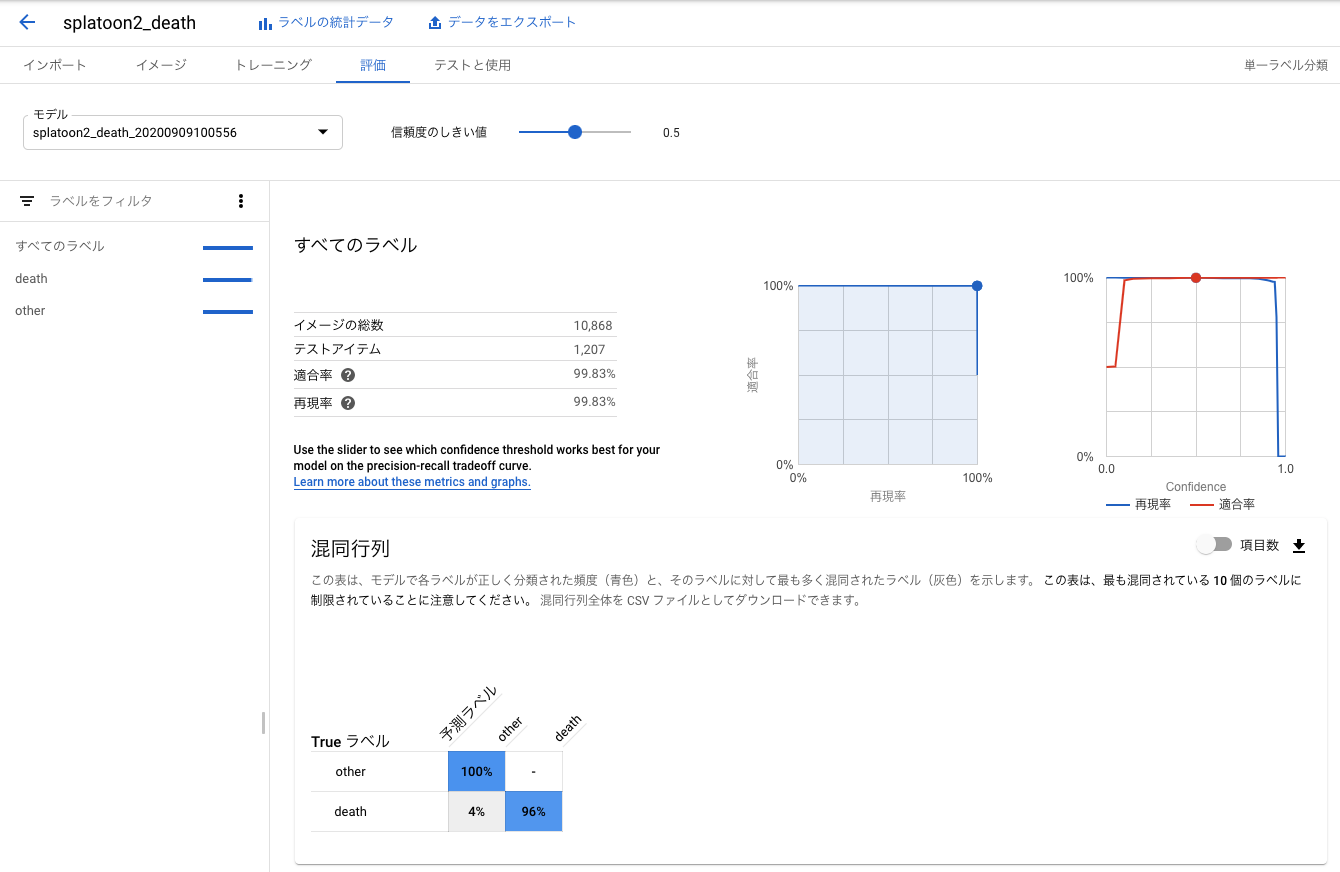
混同行列を見ると、やられたシーンは4%の確率でそれ以外のシーンと誤分類されますが、それ以外のシーンがやられたシーンに誤分類されることはないようです。使用目的であるやられたシーンの数秒前からの動画の切り出しに適用すると、25回やられたら24回はやられたシーンの動画を切り出せるので、実用的な精度だと思います。
学習モデルをダウンロードする
テストと使用 タブからTF Liteを選びます。
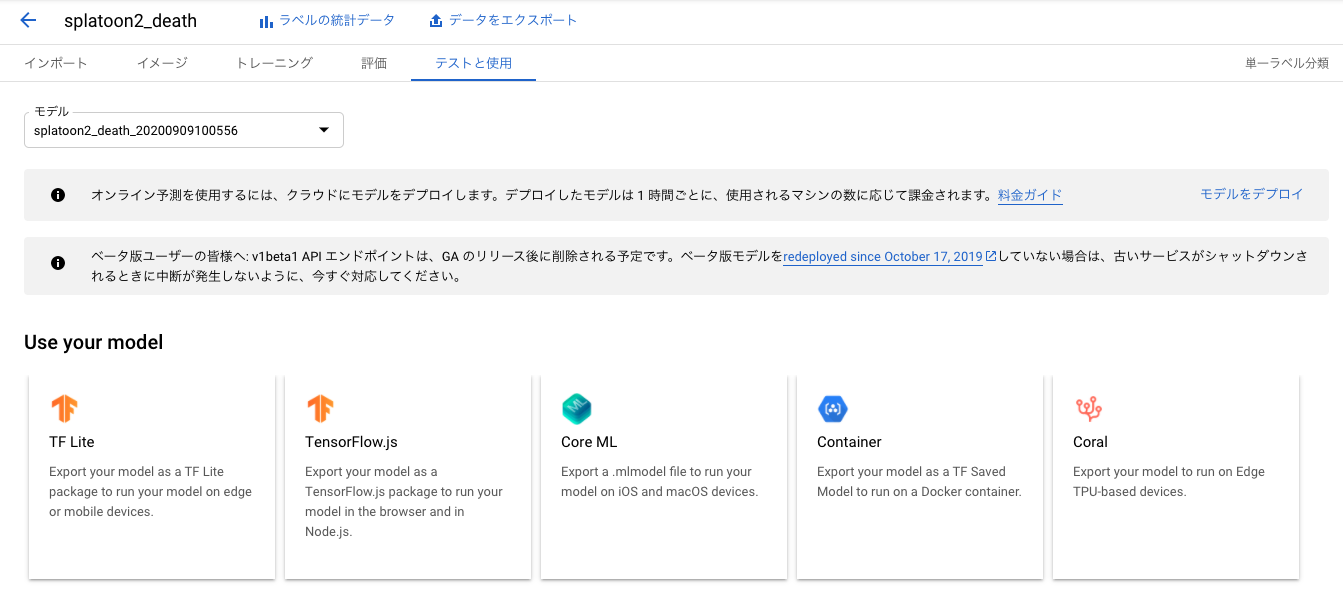
出力先Google Cloud StorageのURLを指定します。
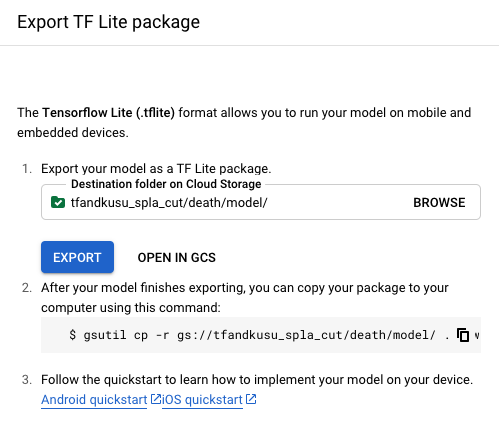
出力先の深めの階層に学習モデルのファイルがあるので、dict.txtとmodel.tfliteをダウンロードして、modelディレクトリに格納しました。
TensorFlow Liteを使って、やられたシーンを切り出す
入力層、出力層の形を確認する
まずはAutoML Visionによって作られたモデルの入力層、出力層の形を確認します。
TensorFlow Liteの使い方はこちらの記事が参考になりました。
初心者に優しくないTensorflow Lite の公式サンプル
まずはモデルを読み込みます。
import tensorflow as tf
interpreter = tf.lite.Interpreter(model_path='model/model.tflite')
入力層の形を確認します。(ここからJupyter Labを使いました。)
interpreter.get_input_details()
[{'name': 'image',
'index': 0,
'shape': array([ 1, 224, 224, 3], dtype=int32),
'shape_signature': array([ 1, 224, 224, 3], dtype=int32),
'dtype': numpy.uint8,
'quantization': (0.007874015718698502, 128),
'quantization_parameters': {'scales': array([0.00787402], dtype=float32),
'zero_points': array([128], dtype=int32),
'quantized_dimension': 0},
'sparsity_parameters': {}}]
(1, 224, 224, 3)の4次元配列を入力することが分かりました。学習画像はフルHDの4/1 - 480×270の大きさに縮小しましたが、さらに縮小する必要があるそうです。
出力層の形を確認します。
interpreter.get_output_details()
[{'name': 'scores',
'index': 172,
'shape': array([1, 2], dtype=int32),
'shape_signature': array([1, 2], dtype=int32),
'dtype': numpy.uint8,
'quantization': (0.00390625, 0),
'quantization_parameters': {'scales': array([0.00390625], dtype=float32),
'zero_points': array([0], dtype=int32),
'quantized_dimension': 0},
'sparsity_parameters': {}}]
(1, 2)の2次元配列を出力することが分かりました。2種類に分類するモデルなので要素数が2になります。
次に dict.txt ファイルを見て、やられたシーンとそれ以外のシーンのインデックスを確認します。
cat model/dict.txt
other
death
このモデルの出力は
[[243, 13]]
のように0番目の方が大きいと、それ以外のシーン、
[[ 16, 240]]
ように1番目の方が大きいと、やられたシーンになることが分かりました。
やられたシーンを切り出す。
0.5秒に1フレーム推論して、やられたフレームを見つけたら、その8秒前からやられたフレームまで動画を切り出します。切り出し後は8秒間推論をスキップします。動画の切り出しにはffmpegコマンドを使用しました。
ライブラリをインポートします。tqdmはプログレス表示用のライブラリです。
import subprocess
import csv
import numpy as np
import cv2
import tensorflow as tf
from tqdm import tqdm
動画切り出し設定です。
# 切り出し元動画パス
src_movie = 'test.mp4'
# 切り出し秒数
cut_duration = 8
# 切り出し終了時間からこの秒数は切り出し開始しない
death_duration = 8
TensorFlow Liteの初期化を行います。
interpreter = tf.lite.Interpreter(model_path='model/model.tflite')
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
切り出し開始秒数をCSVファイルに書き出します。
# 書き出しCSVファイル
with open('cut_time.csv', 'w') as f:
writer = csv.writer(f)
# 動画を読み込む
cap = cv2.VideoCapture(src_movie)
# フレーム数を取得
frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
# 1秒あたりフレーム数を取得
fps = cap.get(cv2.CAP_PROP_FPS)
# 0.5秒に1回予測する
skip = fps / 2
# フレーム
i = 0
# 切り出し開始しないカウントダウン
no_start = 0
for i in tqdm(range(frame_count)):
ret, img = cap.read()
if ret:
if i % skip == 0 and no_start == 0:
# フレームを予測する大きさに縮小
shrink = cv2.resize(
img, (224, 224), interpolation=cv2.INTER_CUBIC)
# 4次元に変換する
input_tensor = shrink.reshape(1, 224, 224, 3)
# それをTensorFlow liteに指定する
interpreter.set_tensor(input_details[0]['index'], input_tensor)
# 推論実行
interpreter.invoke()
# 出力層を確認
output_tensor = interpreter.get_tensor(output_details[0]['index'])
# やられたシーン判定
scene = np.argmax(output_tensor)
if scene == 1:
# やられたシーンの時は
# 切り出し開始秒数を出力
ss = i - cut_duration * fps
if ss < 0:
ss = 0
writer.writerow(["%d.%02d" % (ss/fps, 100 * (ss % fps)/fps)])
# シーン判定をしばらく止める
no_start = fps * death_duration
if no_start >= 1:
no_start -= 1
else:
break
このようなCSVファイルができあがります。
cut_time.csv
511.00
544.50
561.00
// 略
CSVファイルを読み込んで切り出し開始時刻配列を作ります。
sss = []
with open('cut_time.csv') as f:
reader = csv.reader(f)
for row in reader:
sss.append(row[0])
subprocesモジュールでffmpegコマンドを呼び出して、切り出します。
for i in tqdm(range(len(sss))):
ss = sss[i]
command = "ffmpeg -y -ss %s -i %s -t %d -c copy extract/scene%03d.mp4" % (ss, src_movie, cut_duration, i)
subprocess.run(command, shell=True)
実用性のある精度か確認する
ガチマッチに2時間潜り録画しました。私は癖としてやられるとすぐにマップを開いてしまうのですが、そうすると「○○でやられた」表示が出なくなります。そこは注意しました。
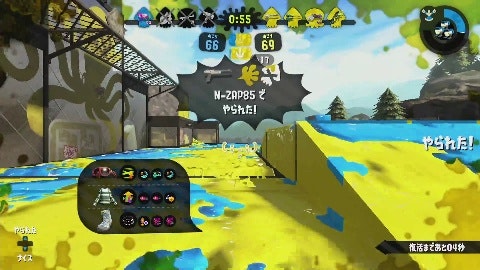
↑やられたら、この表示を必ず出す。
ikaWidget2で各試合のデス数を確認して合計してみたところ132回デスしていましたが、このシステムはその132回をすべて正しく切り出していました。十分に実用的な精度です。
学習済みモデルと動画切り出しのJupyter Notebook
学習済みモデルとそれを使って動画を切り出すスクリプトはJupyter Notebook形式でGithubに置きました。
https://github.com/tfandkusu/splatoon2_movie_death
補足
ローラーでひかれたケース
ローラーの転がしに巻き込まれてやられたときは「ローラーでひかれた!」という表示になるというご指摘がありました。そのパターンはめったに無いため学習データやテストデータには含まれていませんでした。
「やられた」で検出してるけど「ローラーにひかれた」とかもなかったっけ。 https://t.co/LSWUnuq7zF
— もおあき (@moooaki) September 12, 2020
そこでYouTubeから、ななとさんのコロコロ縛りプラベ動画をお借りして検証してみました。
https://youtu.be/FIMpiH9SkBo
0.5秒に1回のフレーム画像の予測結果をすべて目視で確認してみたところ、混同行列はこのようになりました。
| やられたシーンに予測された | それ以外のシーンに予測された | |
|---|---|---|
| 正解はやられたシーン | 49 | 1 |
| 正解はそれ以外のシーン | 0 | 2,071 |
ローラーによくひかれる人にとっても、実用的な精度であることが確認できました。