1.はじめに
1.1.背景
現在のプロジェクトにて、LLMに対してのプロンプトを作成する機会が多くありました。
その際、出来る限り抽出精度を高めようと個人的に自然言語を気を付けようにも、いったい「どういった書き方がLLMにとって分かりやすいのか?」にとても悩みました。
そこでGoogle Cloudの提供するプロンプト最適化サービス『Vertex AI Prompt Optimizer API』を利用して、自身のプロンプトを改善するようにしました。
1.2.『Prompt Optimizer』とは?
- Google Cloud が提供するプロンプト最適化サービス
- AI分野のカンファレンスNeurIPS 2024での APO (Automatic Prompt Optimization) 論文をベースにした、プロンプトの最適化を提示。
- 論文の主張
- プロンプト最適化には「指示を改善する方法(IO)」と「例示を選ぶ方法(EO)」の2種類がある
- IOの研究比重が大きいけれど、EOのほうが効果が大きい場合もある
- そのためIOとEOを両方することで相乗効果により一番性能が引き出せる
- 論文の主張
1.2.1.2種類の機能モード
今回は手元に正解データセットがなくても、単一のプロンプトだけですぐに効果を検証できる『Zero-shot Optimizer』を利用し、プロンプト改善を実施していきます。
| No | モード名 | 機能概要 |
|---|---|---|
| 1 | Zero-shot Optimizer | 単一プロンプトで容易に実行可能 |
| 2 | Data-driven Optimizer | ラベル付きデータ(正解データ)を事前用意し詳細な最適化を実行 |
2.構築
構築したGithub:tetutetu214/google-optimizer
2.1.ディレクトリ構成
prompt-optimizer-tool/
├── .gitignore
├── README.md
├── requirements.txt
├── .env # 環境変数のサンプル
├── backend/
│ └── optimizer.py # PromptOptimizer クラス
└── frontend/
└── app.py # Streamlit UI
2.2.コード詳細
2.2.1.backend/optimizer.py
コードの詳細
"""
プロンプト最適化のバックエンドロジック
このモジュールはVertex AIのPrompt Optimizerを使用して、
ユーザーが入力したプロンプトを最適化する機能を提供する。
最適化結果はストリーミング形式で段階的に返される。
"""
import vertexai
from typing import Generator, Dict, Any
from google import genai
from google.genai import types
import os
class PromptOptimizer:
"""
Vertex AI Prompt Optimizerのラッパークラス
プロンプトの最適化をストリーミング形式で実行し、
元のプロンプト、最適化されたプロンプト、改善提案を
段階的に返す機能を提供する。
Attributes:
project_id (str): Google CloudのプロジェクトID
location (str): Vertex AIのリージョン
client (vertexai.Client): Vertex AIのクライアントインスタンス
"""
# PromptOptimizerの初期化
def __init__(self, project_id: str, location: str = "us-central1"):
# 共通
self.project_id = project_id
self.location = location
# Optimizer用 クライアント
self.client = vertexai.Client(project=project_id, location=location)
# 翻訳用
self.genai = genai.Client(
vertexai=True,
project=project_id,
location=location
)
# 英語テキストを日本語に翻訳する
def translate_to_japanese(self, text: str) -> str:
# Gemini APIを呼び出して翻訳実行
try:
response = self.genai.models.generate_content(
model="gemini-2.0-flash-001",
contents=f"以下の英語を自然な日本語に翻訳してください。翻訳結果のみを出力:\n\n{text}"
)
# strip()で前後の空白・改行を削除して整形
return response.text.strip()
# エラー時は元のテキストを返す
except Exception as e:
return text
# プロンプトを最適化し、結果をストリーミング形式で返す
def optimize_prompt_stream(self, prompt: str) -> Generator[Dict[str, Any], None, None]:
"""
プロンプトを最適化し、結果をストリーミング形式で返す
Args:
prompt: 最適化するプロンプト
Yields:
dict: ストリーミングデータ
"""
# 処理開始を通知
yield {
"type": "status",
"message": "プロンプト最適化を開始します..."
}
# プロンプトの分析と最適化を実行
try:
response = self.client.prompt_optimizer.optimize_prompt(prompt=prompt)
# parsed_responseには最適化結果が構造化されて格納
parsed = response.parsed_response
# 元のプロンプトを送信
yield {
"type": "original_prompt",
"content": parsed.original_prompt
}
# 最適化されたプロンプトをクライアントに返す
yield {
"type": "suggested_prompt",
"content": parsed.suggested_prompt
}
# 個別の改善提案を1つずつクライアントに返す
for i, guideline in enumerate(parsed.applicable_guidelines, 1):
# 英語の理由を日本語に翻訳
improvement_ja = self.translate_to_japanese(guideline.suggested_improvement)
# 改善提案を送信
yield {
"type": "guideline",
"index": i,
"name": guideline.applicable_guideline,
"improvement": improvement_ja,
"before": guideline.text_before_change,
"after": guideline.text_after_change
}
# 処理完了をクライアントに通知
yield {
"type": "status",
"message": "最適化が完了しました"
}
# エラー発生時はエラー情報をクライアントに返す
except Exception as e:
yield {
"type": "error",
"message": f"エラーが発生しました: {str(e)}"
}
2.2.2.frontend/app.py
コードの詳細
"""
Streamlitフロントエンド
Vertex AI Prompt Optimizerを使用したプロンプト最適化ツールのUI。
ユーザーはファイルアップロードまたは直接入力でプロンプトを入力し、
最適化結果をストリーミング形式でリアルタイムに確認できる。
"""
import streamlit as st
import sys
from pathlib import Path
import time
from dotenv import load_dotenv
import os
# .envファイルから環境変数を読み込み
load_dotenv()
# 親ディレクトリのbackendモジュールをインポートパスに追加
sys.path.append(str(Path(__file__).parent.parent))
from backend.optimizer import PromptOptimizer
# ページ設定
# Streamlitアプリケーションの基本設定を定義
st.set_page_config(
page_title="プロンプト最適化ツール",
layout="wide"
)
# 初期化
if 'is_optimizing' not in st.session_state:
st.session_state.is_optimizing = False
if 'optimization_result' not in st.session_state:
st.session_state.optimization_result = None
if 'guidelines_data' not in st.session_state:
st.session_state.guidelines_data = []
# タイトル
st.title("Prompt Optimizer API プロンプト最適化提案ツール")
st.markdown("---")
# サイドバー設定
with st.sidebar:
st.header("設定")
project_id = st.text_input(
"Google Cloud Project ID",
value=os.getenv("PROJECT_ID", ""),
help="Vertex AIを使用するプロジェクトID"
)
location = st.text_input(
"Location",
value=os.getenv("LOCATION", ""),
help="Vertex AIのリージョン"
)
# メインコンテンツ
# 画面を左右2カラムに分割(入力部と出力部)
col1, col2 = st.columns([1, 1])
with col1:
st.header("プロンプト入力")
# ファイルアップロード or テキスト入力
input_method = st.radio(
"入力方法",
["ファイルアップロード", "直接入力"],
horizontal=True
)
prompt_text = ""
if input_method == "ファイルアップロード":
uploaded_file = st.file_uploader(
"プロンプトファイルを選択",
type=["txt", "md"],
help="テキストファイルまたはMarkdownファイルをアップロード"
)
if uploaded_file:
prompt_text = uploaded_file.read().decode("utf-8")
st.text_area(
"ファイル内容",
value=prompt_text,
height=300,
disabled=True
)
else:
prompt_text = st.text_area(
"プロンプトを入力",
height=300,
placeholder="最適化したいプロンプトを入力してください..."
)
optimize_button = st.button(
"Prompt Optimizer API による最適化実行",
type="primary",
use_container_width=True,
disabled=not prompt_text or st.session_state.is_optimizing
)
with col2:
st.header("プロンプト出力")
# ストリーミング表示時にこれらのプレースホルダーに順次コンテンツを表示
status_placeholder = st.empty()
suggested_placeholder = st.empty()
guidelines_placeholder = st.empty()
# 最適化実行
if optimize_button and prompt_text:
try:
# 実行開始でボタンを無効化
st.session_state.is_optimizing = True
st.session_state.optimization_result = None
st.session_state.guidelines_data = []
# オプティマイザー初期化
optimizer = PromptOptimizer(project_id, location)
# ストリーミング表示
guidelines_data = []
suggested_prompt_content = None
# ストリーミング処理のメインループ
# optimize_prompt_streamから順次データを受け取り、リアルタイムで表示
for data in optimizer.optimize_prompt_stream(prompt_text):
# ステータスメッセージの表示
# 「最適化を開始します」「完了しました」などの進行状況を表示
if data["type"] == "status":
with status_placeholder:
st.info(data["message"])
time.sleep(0.5)
# 改善提案データの蓄積
elif data["type"] == "suggested_prompt":
st.session_state.optimization_result = data["content"]
elif data["type"] == "guideline":
st.session_state.guidelines_data.append(data)
# エラー発生時の表示
elif data["type"] == "error":
with status_placeholder:
st.error(data["message"])
# 完了後、ステータスをクリア
time.sleep(1)
status_placeholder.empty()
# 予期しないエラーが発生した場合
except Exception as e:
st.error(f"エラーが発生しました: {str(e)}")
finally:
# 実行終了: ボタンを再有効化
st.session_state.is_optimizing = False
# Vertex AIが生成した改善版プロンプトを表示
if st.session_state.optimization_result:
with suggested_placeholder.container():
st.subheader("最適化されたプロンプト")
st.code(st.session_state.optimization_result, language="text")
# ダウンロードボタン
st.download_button(
label="最適化プロンプトをダウンロード",
data=st.session_state.optimization_result,
file_name="optimized_prompt.txt",
mime="text/plain"
)
# 改善提案セクションを表示
if st.session_state.guidelines_data:
# 改善提案セクションを表示
with guidelines_placeholder.container():
st.subheader("改善提案")
# 蓄積された全ての改善提案を順次表示
# 新しい提案が来るたびに全体を再描画
for guideline in st.session_state.guidelines_data:
with st.expander(
f"改善点 {guideline['index']}: {guideline['name']}",
expanded=True
):
# 改善理由を表示
st.markdown(f"**理由:** {guideline['improvement']}")
# 変更前後を2カラムで並べて表示
col_before, col_after = st.columns(2)
with col_before:
st.markdown("**変更前:**")
st.code(guideline['before'], language="text")
with col_after:
st.markdown("**変更後:**")
st.code(guideline['after'], language="text")
3.画面構成
3.1.左ペインに「プロジェクトID」と「Location」を入力して「プロンプトファイルを選択」
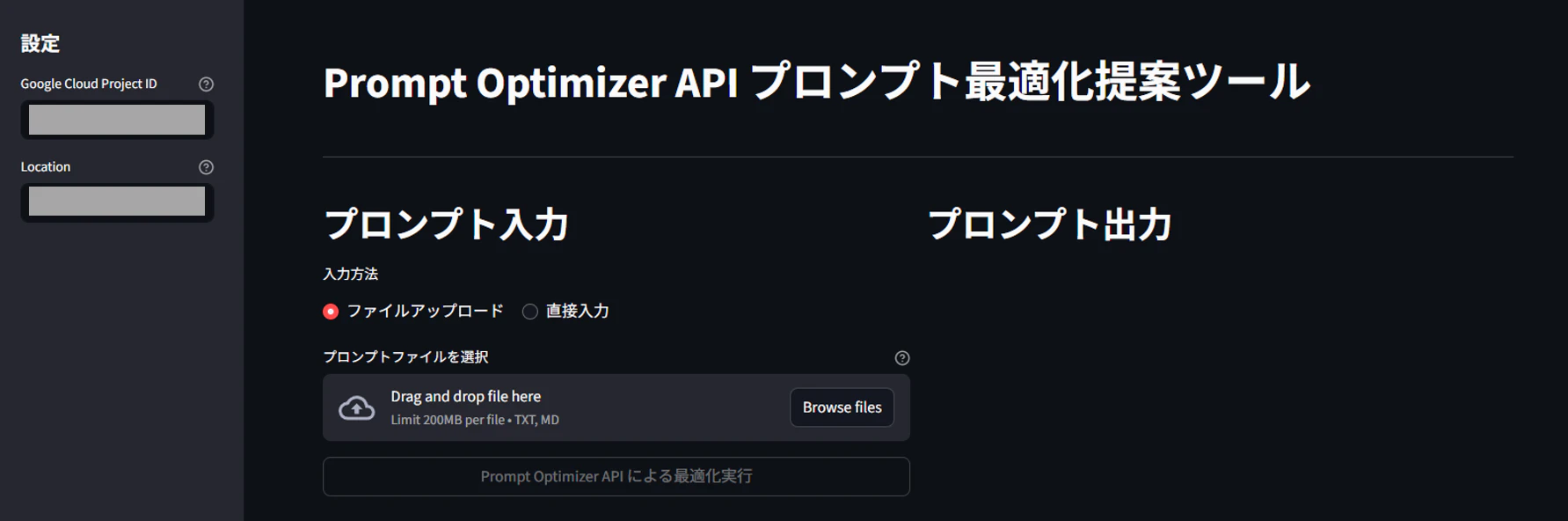
3.2.「Prompt Optimizer APIによる最適化実行」を押下
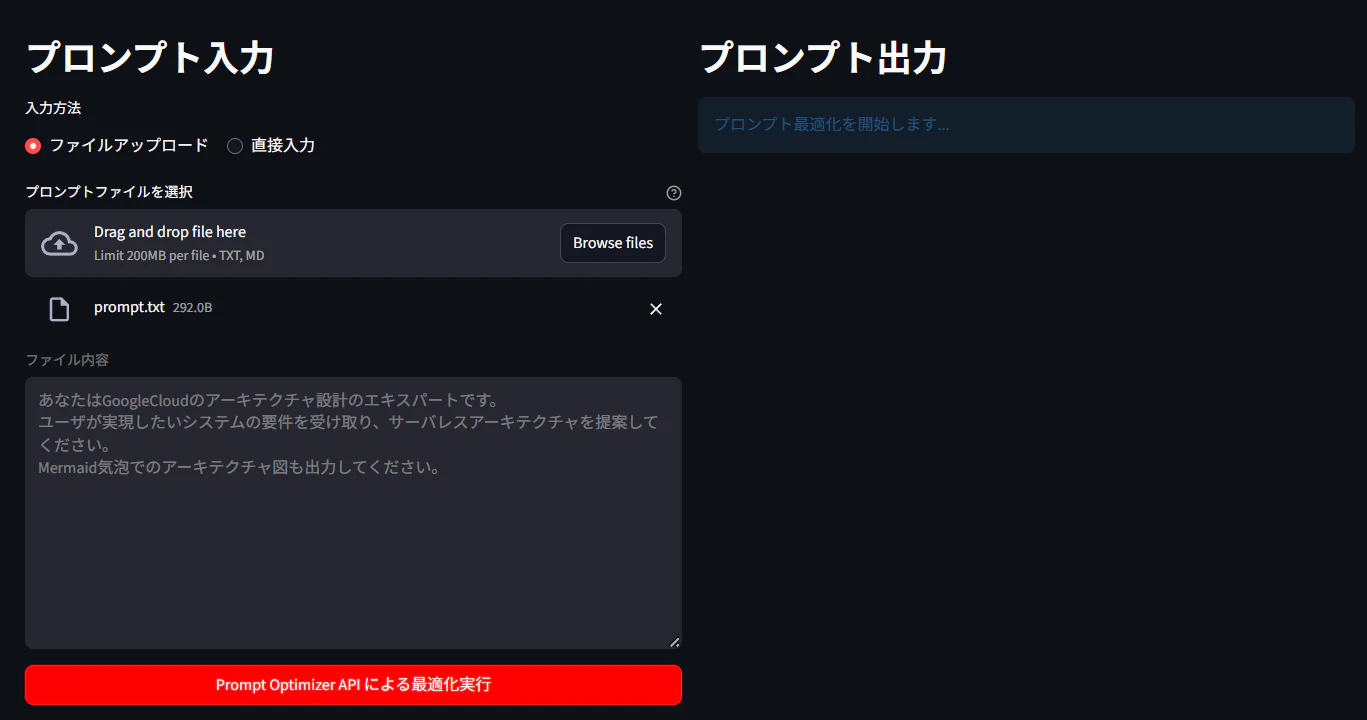
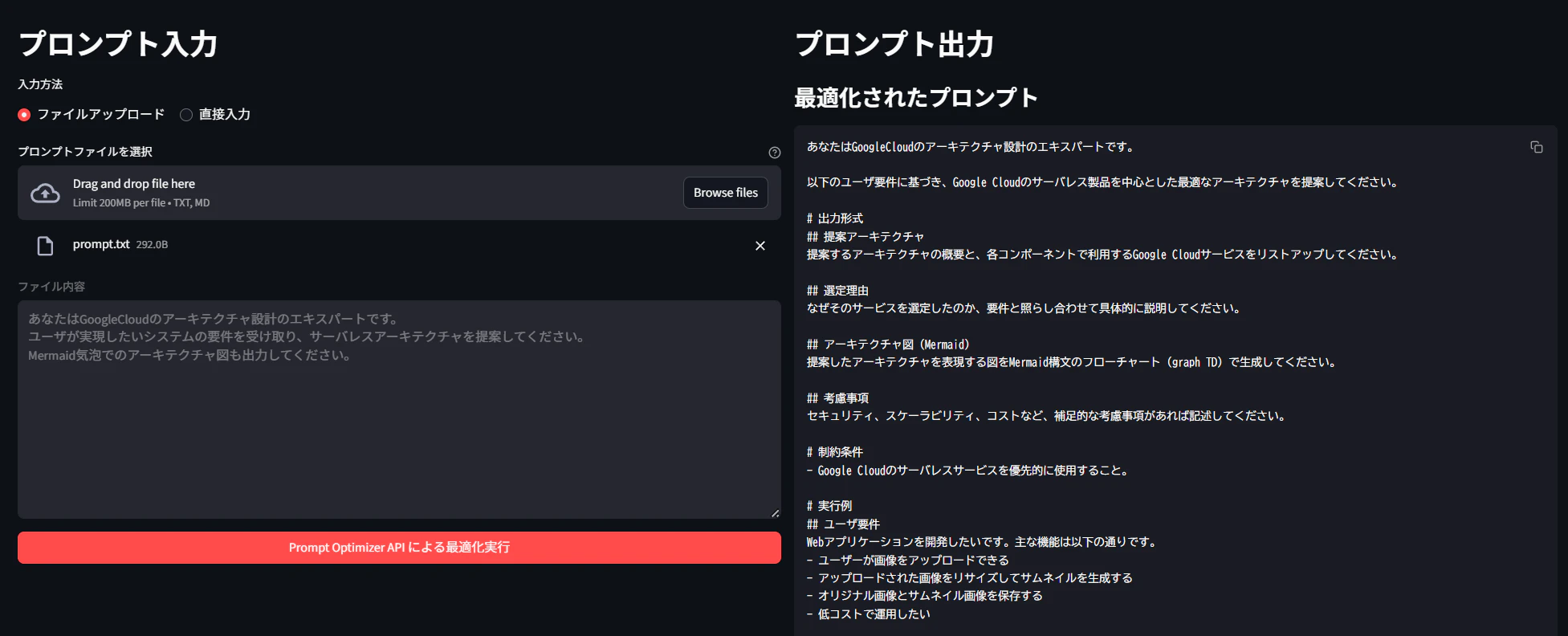
3.3.「プロンプト出力」に「最適化されたプロンプト」が表示される
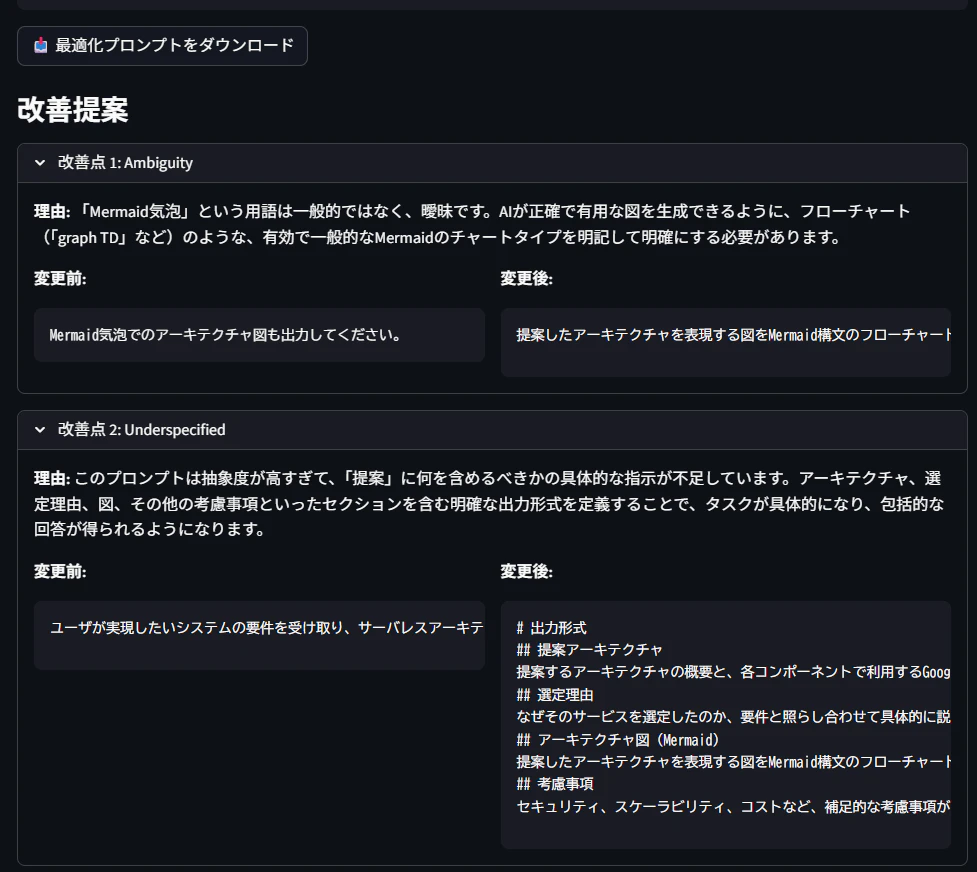
3.4.「最適化されたプロンプト」のダウンロード機能、「改善提案」が表示される
4.まとめ
4.1.感想
- 個人で「プロンプトのどこを調整したらいい?」と思うのであれば、導入検討してもよいと思いました
- プロンプト最適化に使用される内部モデルについては、公式ドキュメントに明記されてなさそう
4.2.得られた知見
- Zero-shot Optimizer による手軽なプロンプト最適化の方法
- 変更前後の比較など、どう改善すべきかを明示するようにできた
4.3.今後の課題
-
Data-driven Optimizerへの拡張- ラベル付きデータを用意して、モデル移行時のプロンプト最適化を実施
- 例: Gemini-2.5-Pro → Gemini-3-Pro への移行時のプロンプト調整
- ラベル付きデータを用意して、モデル移行時のプロンプト最適化を実施