動機
GraphQLを勉強しているとき、
- GraphQLが"グラフ"を扱っているのはわかるけどそれによってどんないいことがあるんだろう?
- バックエンドにGraphQLを選択した際、ビジネスロジックはどこに表現されるべきなんだろう?
という私の疑問にサクッと答えてくれる日本語の文献が少なくともネット上には見つからなかったので、書いてみることにしました。
作るもの
いわゆる"TODOリスト"を作ります。TodoistやRememberTheMiik的なあれですね。
いきなり余談ではありますが、何か新しい言語やフレームワーク、DBなどをサクッと試したいときに作るものの題材として、"TODOリスト"は個人的に以下の観点からオススメです。
- 仕様がイメージしやすい
- 大抵の方は何らかのTODOリストを使ったことありますよね?
- どんなアーキテクチャでも大抵1日以内に完成する
- 慣れないアーキテクチャであまり壮大なアプリケーションに挑戦すると挫折しがちなので。。。
- データのCRUDが一通り抑えられる
- 今回の例では便宜上R(読み取り)しか扱わないですが、CRUDを全部抑えられるような仕様をイチから考えるのは結構大変だったりします。
ということで、「○○(言語でもDBでも何でも)を勉強したいんだけど、何作ろうかなぁ。。。」と迷って始められないくらいであれば、"TODOリスト"をデフォルトの選択肢するのはいかがでしょうか?
環境準備
今回は、Apollo Serverを使用します。まあ、2020年1月時点でデファクトスダンダードといっても差し支えないですかね。尚、今回はGraphQLに焦点を絞りたいので、UIは作りません。また、DBについても特に使用せず、Apollo ServerのGet Startedのようにデータは内部メモリの上の配列に持つことにします。
ということで、Get Startedを参考に環境準備しましょう。前提として、Node.jsとnpmはよしなに最新Stableでも入れておいてください。
$ mkdir graphql-practice-todos
$ cd graphql-practice-todos
$ npm init --yes
$ npm instlal --save apollo-server graphql
$ touch index.js
まずはシンプルに作ってみる
ビジネスロジックのことは一度置いておいて、まずはシンプルにTODOリストのタスクをQueryを通じて参照できるGraphQL Serverを作ってみましょう。Get Startedを見ながら真似れば何となくできると思います。
実装
const {ApolloServer, gql } = require('apollo-server');
/**
* GraphQLのSchema
*/
const typeDefs = gql`
"タスク"
type Task{
"タスクのID"
id: ID!
"タスク名"
name: String!
"期限(YYYY-MM-DD hh:mm:ss)"
expiresAt: String!
"完了フラグ(完了していればtrue)"
done: Boolean!
}
"クエリ"
type Query{
"すべてのタスク"
allTasks: [Task!]!
"完了済タスク"
finishedTasks: [Task!]!
"未完了タスク"
unfinishedTasks: [Task!]!
"IDからタスクを取得"
taskByID(
"取得したいタスクのID"
id: ID!
): Task
}
`;
/**
* タスクを管理する内部配列
*/
const tasks = [
{
id: 'd1947409-95b4-4a46-8e83-cc60b94d3dd4',
name: '牛乳を買う',
expiresAt: '2020-01-23 20:00:00',
done: true
},
{
id:'97dcafa7-53d3-47b0-b25f-8457577749c8',
name: 'Qiitaに投稿する',
expiresAt: '2020-01-25 22:00:00',
done: false
}
];
/**
* GraphQLのResolver
*/
const resolvers = {
/**
* "Query"ノードについてのResolver
*/
Query: {
/**
* すべてのタスク
*/
allTasks: () => tasks,
/**
* 完了済タスク
*/
finishedTasks: ()=> tasks.filter(task => task.done),
/**
* 未完了タスク
*/
unfinishedTasks: ()=> tasks.filter(task => !task.done),
/**
* IDからタスクを取得する
* Schemaで定義したパラメータは第2引数のargsオブジェクトの中に格納される点に注意
*/
taskByID: (_, args) => tasks.find(task => task.id === args.id)
}
};
//定義したSchema(typeDefs)とRosolversを使用してApolloServerを作成
const server = new ApolloServer({typeDefs, resolvers});
//作成したApolloServerの起動(デフォルトポートは4000)
server.listen().then(({url}) => console.log(`Server ready at ${url}`));
動作確認
$ node index.js
Server ready at http://localhost:4000/
ブラウザでlocalhost:4000にアクセスすると、動作確認用のUIが表示されるはずです。
例えば以下のようなクエリを左側に入力してください。
すべてのタスクを取得
クエリ
query{
allTasks{
id
name
expiresAt
done
}
}
結果
{
"data": {
"allTasks": [
{
"id": "d1947409-95b4-4a46-8e83-cc60b94d3dd4",
"name": "牛乳を買う",
"expiresAt": "2020-01-23 20:00:00",
"done": true
},
{
"id": "97dcafa7-53d3-47b0-b25f-8457577749c8",
"name": "Qiitaに投稿する",
"expiresAt": "2020-01-25 22:00:00",
"done": false
}
]
}
}
IDからタスクを取得
クエリ
query{
taskByID(
id:"d1947409-95b4-4a46-8e83-cc60b94d3dd4"
){
id
name
expiresAt
done
}
}
結果
{
"data": {
"taskByID": {
"id": "d1947409-95b4-4a46-8e83-cc60b94d3dd4",
"name": "牛乳を買う",
"expiresAt": "2020-01-23 20:00:00",
"done": true
}
}
}
完了済リストと未完了リストを同時に取得する
クエリ
query{
# 完了済リスト
# 完了しているので有効期限は不要なので要求しない
finishedTasks{
id
name
}
# 未完了リスト
unfinishedTasks{
id
name
expiresAt
}
}
結果
{
"data": {
"finishedTasks": [
{
"id": "d1947409-95b4-4a46-8e83-cc60b94d3dd4",
"name": "牛乳を買う"
}
],
"unfinishedTasks": [
{
"id": "97dcafa7-53d3-47b0-b25f-8457577749c8",
"name": "Qiitaに投稿する",
"expiresAt": "2020-01-25 22:00:00"
}
]
}
}
スキーマを"グラフ"として理解する
さて、ここからが本題です。
GraphQLはその名の通りGraph(グラフ)を扱う問い合わせ言語(Query Language)です。
グラフ理論についての詳細な解説はこちらの素晴らしい記事にお任せするとして、ここでは単純に、
グラフ = 頂点(Node)と辺(Edge)でモデル化したもの
と捉えてください。
例えば、今回定義したスキーマはこのような有向グラフ(辺に方向があるグラフ)として表すことができます。
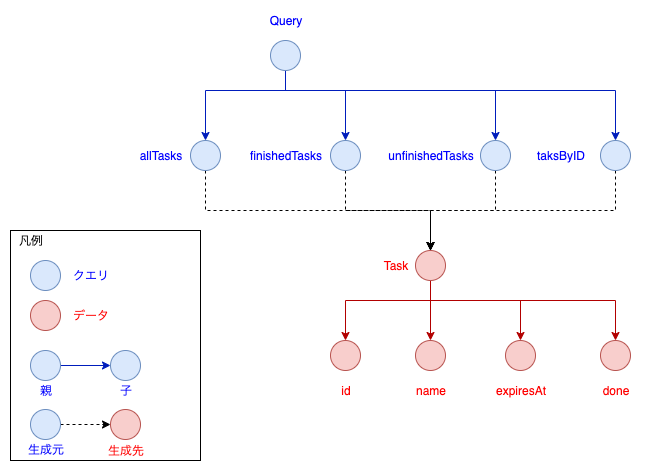
つまり、
- Queryの子ノードとしてallTasks,finishedTasks,unfinisehdTasks,taskByIDの4ノードがある
- 上記の4ノードはTaskノードを生成する
- Taskの子ノードとしてid,name,expiresAt,doneの4ノードがある
というモデルであると捉えることができます。
リゾルバはノードに割り当てられる
さて、スキーマをグラフとして整理できると、今度はリゾルバとの関係も整理できるはずです。
/**
* GraphQLのResolver
*/
const resolvers = {
/**
* "Query"ノードについてのResolver
*/
Query: {
/**
* すべてのタスク
*/
allTasks: () => tasks,
/**
* 完了済タスク
*/
finishedTasks: ()=> tasks.filter(task => task.done),
/**
* 未完了タスク
*/
unfinishedTasks: ()=> tasks.filter(task => !task.done),
/**
* IDからタスクを取得する
* Schemaで定義したパラメータは第2引数のargsオブジェクトの中に格納される点に注意
*/
taskByID: (_, args) => tasks.find(task => task.id === args.id)
}
};
形を見ればわかる通り、このコードで定義したリゾルバはQueryノードの子ノードであるallTasks,finsihedTasks,unfinishedTasks,taskByIDに割り当てられています。ここではまず、
リゾルバ(Resolver)はスキーマ(Schema)のノード(Node)に割り当てられる
ということだけ理解してください。
スキーマとリゾルバとクエリの関係
さて、スキーマとリゾルバの関係が整理できたところで、先ほど動作確認したようなクエリが投げられたとき、それらがどういう作用をするか考えていきましょう。先ほどのグラフ(図)を見ながら、下記のクエリと動作と結果の関係を追ってみてください。
すべてのタスクを取得する
query{
allTasks{
id
name
expiresAt
done
}
}
- Queryノードの子ノードであるallTasksノードが要求される
- allTasksノードのリゾルバが呼ばれ、(0..n個の)Taskノードを生成する
- 生成されたTaskノードの子要素のうちクエリで指定されたid,name,expiresAt,doneが要求される
- それぞれのノードの値がクエリの結果として返却される
{
"data": {
"allTasks": [
{
"id": "d1947409-95b4-4a46-8e83-cc60b94d3dd4",
"name": "牛乳を買う",
"expiresAt": "2020-01-23 20:00:00",
"done": true
},
{
"id": "97dcafa7-53d3-47b0-b25f-8457577749c8",
"name": "Qiitaに投稿する",
"expiresAt": "2020-01-25 22:00:00",
"done": false
}
]
}
}
完了済リストと未完了リストを同時に取得する
query{
# 完了済リスト
# 完了しているので有効期限は不要なので要求しない
finishedTasks{
id
name
}
# 未完了リスト
unfinishedTasks{
id
name
expiresAt
}
}
- Queryの子ノードであるfinishedTaskとunfinishedTaskが要求される
- finishedTaskのリゾルバが呼ばれ0..n個のTaskが生成される
- 生成されたTaskノードの子要素のうちクエリで指定されたid,nameが要求される
- unfinishedTaskのリゾルバが呼ばれ0..n個のTaskが生成される
- 生成されたTaskノードの子要素のうちクエリで指定されたid,name,expiredAtが要求される
- finishedTaskのリゾルバが呼ばれ0..n個のTaskが生成される
- それぞれのノードの値がクエリの結果として返却される
{
"data": {
"finishedTasks": [
{
"id": "d1947409-95b4-4a46-8e83-cc60b94d3dd4",
"name": "牛乳を買う"
}
],
"unfinishedTasks": [
{
"id": "97dcafa7-53d3-47b0-b25f-8457577749c8",
"name": "Qiitaに投稿する",
"expiresAt": "2020-01-25 22:00:00"
}
]
}
}
ここまでのまとめ(スキーマとリゾルバとクエリの関係)
- スキーマはグラフである
- リゾルバはスキーマの各ノード(頂点)に設定される
- クエリが発行されると、その内容に応じてエッジ(辺)の方向にノードを参照していき、リゾルバがあればそれが実行される
では、ビジネスロジックを入れてみよう
それでは、GraphQLと"グラフ"の関係が整理できたところで、表題の目的に立ち返って簡単なビジネスロジックを入れてみましょう。
ビジネスロジック:urgent(緊急)タスク
以下のようなビジネスロジックを考えることにします。
- 「未完了」かつ「期限が現在時刻から8時間以内」のタスクをurgent(緊急)タスクとする
- 各TaskはurgentというBoolean型のプロパティを持ち、上記に定義されたurgentタスクであればtrueを返す
ということで、まずはスキーマにurgentプロパティを追加しましょう。
/**
* GraphQLのSchema
*/
const typeDefs = gql`
"タスク"
type Task{
"タスクのID"
id: ID!
"タスク名"
name: String!
"期限(YYYY-MM-DD hh:mm:ss)"
expiresAt: String!
"完了フラグ(完了していればtrue)"
done: Boolean!
"緊急タスクかどうか"
urgent: Boolean!
}
"クエリ"
type Query{
"すべてのタスク"
allTasks: [Task!]!
"完了済タスク"
finishedTasks: [Task!]!
"未完了タスク"
unfinishedTasks: [Task!]!
"IDからタスクを取得"
taskByID(
"取得したいタスクのID"
id: ID!
): Task
}
`;
スキーマを更新したので、グラフも更新しましょう。Taskの子ノードとしてurgentを追加します。
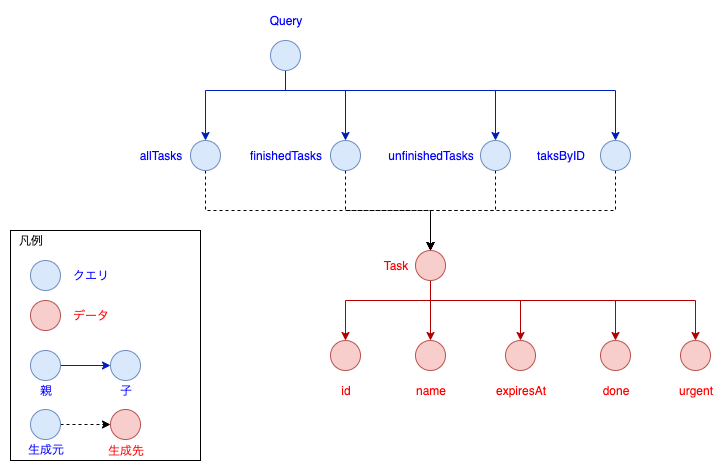
ついでに、今回のビジネスロジックは時間を扱う(現在時刻から8時間)ので、利便性を考えてmomentを入れておきましょう。
$ npm install --save moment
GraphQLらしくない解決策
では、仮にGraphQLの特性を全く無視してこのビジネスロジックを実現しようとしたらどうなるでしょうか。少しJavaScriptに慣れた人であれば、このような解決策がパッと思いつくかも知れません。
const moment = require('moment');
/**
* taskがurgent(緊急)かどうか
* @param {Object} task タスク
* @return {Boolean} taskがurgentであればtrue
*/
const isUrgent = (task) => !task.done && moment().add(8,"hours").isAfter(task.expiresAt);
/**
* リスト内のtaskにurgentプロパティを追加する
* @param {Array} tasks タスクのリスト
* @return {Array} urgentプロパティが追加されたtaskのリスト
*/
const addUrgent = (tasks) => tasks.map(task => Object.assign({},task, {urgent: isUrgent(task)}));
/**
* GraphQLのResolver
*/
const resolvers = {
/**
* "Query"ノードについてのResolver
*/
Query: {
/**
* すべてのタスク
*/
allTasks: () => addUrgent(tasks),
/**
* 完了済タスク
*/
finishedTasks: ()=> addUrgent(tasks).filter(task => task.done),
/**
* 未完了タスク
*/
unfinishedTasks: ()=> addUrgent(tasks).filter(task => !task.done),
/**
* IDからタスクを取得する
* Schemaで定義したパラメータは第2引数のargsオブジェクトの中に格納される点に注意
*/
taskByID: (_, args) => addUrgent(tasks).find(task => task.id === args.id)
}
};
なるほど、確かにjavascript的には全く問題なさそうですし、動作確認すればちゃんと動きます。
query{
allTasks{
id
name
expiresAt
done
urgent
}
}
{
"data": {
"allTasks": [
{
"id": "d1947409-95b4-4a46-8e83-cc60b94d3dd4",
"name": "牛乳を買う",
"expiresAt": "2020-01-23 20:00:00",
"done": true,
"urgent": false
},
{
"id": "97dcafa7-53d3-47b0-b25f-8457577749c8",
"name": "Qiitaに投稿する",
"expiresAt": "2020-01-25 22:00:00",
"done": false,
"urgent": true
}
]
}
}
ですが、この実装は以下の2点において不満です。
DRY(Don't Repeat Yourself)になっていない
この実装はすべてのリゾルバにおいて、tasksを参照する際に必ずaddUrgent(tasks)というようにaddUrgent関数の呼び出しを強要するものです。このルールは今後新たなQueryを定義する時にもMutation(本記事では扱っていませんが、データを作成・更新・削除する命令)を定義する時にも適用されます。
忘れない自信はありますか?1つくらいなら大丈夫かも知れません。では、Taskに関するビジネスルールが追加された場合は?
この実装は明らかにDRY原則に反していますね。このまま拡張を続けていけばすぐに保守性の問題にブチ当たりそうです。
クエリによっては実行コストが無駄になる
GraphQLの大きな特徴の1つに、「データは要求された分しか返さない」というものがあります。つまり、
すべてのクエリがurgentプロパティを要求するとは限らない
のです。
query{
allTasks{
name
}
}
先ほどの実装では、たとえクエリが上記のようなものであっても「そのTaskがurgentかどうか」を判定する演算(つまりisUrgent関数やaddUrgent関数の実行)をしてしまいます。
もちろん、この程度の演算で大したリソースは消費しません。仮にタスクが10,000件あっても大して問題にならないでしょう。
しかし、もしビジネスロジックがI/Oを伴うものであったら?バックエンドのDBに追加のクエリを発行する必要があるものであったら?ただタスクの名前の一覧が欲しいだけのクライアントに大して何秒待たせることになるのでしょう?
このような不必要な(不必要になるかも知れない)演算をしてしまう実装は、あまりGraphQLの特長を生かしているとは言えないのです。
いつからリゾルバはQueryノードにしか割り当てられないと勘違いしていた?
ということで、もう少しGraphQLらしい解決策を考えて見ましょう。
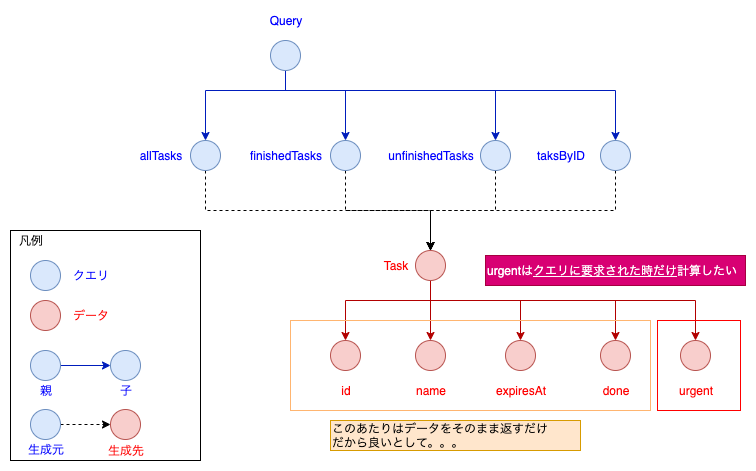
このようにTaskの子ノードを整理してみると、id,name,expiredAt,doneとurgentは性質が異なることが分かると思います。
urgentは"クエリに要求されたときだけ"計算したい
あれ?"クエリに要求された時"に動く処理って何かありませんでしたっけ?
そう、リゾルバですね。
リゾルバは"ノードに割り当てること"ができるのです。誰も"Queryノードに"と限定していませんよ?
urgentノードにリゾルバを割り当てる
ということで、urgentにリゾルバを割り当ててみましょう。
const moment = require('moment');
/**
* GraphQLのResolver
*/
const resolvers = {
/**
* "Query"ノードについてのResolver
*/
Query: {
/**
* すべてのタスク
*/
allTasks: () => tasks,
/**
* 完了済タスク
*/
finishedTasks: ()=> tasks.filter(task => task.done),
/**
* 未完了タスク
*/
unfinishedTasks: ()=> tasks.filter(task => !task.done),
/**
* IDからタスクを取得する
* Schemaで定義したパラメータは第2引数のargsオブジェクトの中に格納される点に注意
*/
taskByID: (_, args) => tasks.find(task => task.id === args.id)
},
/**
* "Task"ノードについてのResolver
*/
Task:{
/**
* taskがurgent(緊急)かどうか
* urgentノードに割り当てられたResolver
* @param {Object} task タスク(Resolverの第1引数には"親ノード"が渡される)
* @return {Boolean} taskがurgentであればtrue
*/
urgent: (task) => !task.done && moment().add(8,"hours").isAfter(task.expiresAt)
}
};
先ほどのisUrgentやaddUrgentは削除してあります。
その代わりに、Taskノードの子ノードであるurgentノードに対するリゾルバを定義し、そこでurgentかどうかの演算をやっています。
動作確認
同じく、先ほどのグラフを見ながら処理の流れを追ってみてください。
query{
allTasks{
id
name
expiresAt
done
urgent
}
}
- Queryノードの子ノードであるallTasksノードが要求される
- allTasksノードのリゾルバが呼ばれ、(0..n個の)Taskノードを生成する
- 生成されたTaskノードの子要素のうちクエリで指定されたid,name,expiresAt,done,urgentが要求される
- id,name,expiresAt,doneについてはリゾルバが無いのでallTasksが返した値が割り当てられる
- urgentノードについてはリゾルバが呼ばれ、urgentかどうかの演算の結果が割り当てられる
- それぞれのノードの値がクエリの結果として返却される
{
"data": {
"allTasks": [
{
"id": "d1947409-95b4-4a46-8e83-cc60b94d3dd4",
"name": "牛乳を買う",
"expiresAt": "2020-01-23 20:00:00",
"done": true,
"urgent": false
},
{
"id": "97dcafa7-53d3-47b0-b25f-8457577749c8",
"name": "Qiitaに投稿する",
"expiresAt": "2020-01-25 22:00:00",
"done": false,
"urgent": true
}
]
}
}
上記は一例としてallTasksを呼んだ場合を例にしましたが、他のQueryやMutationを呼んだ場合でも3.以下は同じ挙動になります。
また逆に、クエリ内にurgentプロパティが指定されていない場合は、urgentのリゾルバは実行されません。
まとめ
いかがでしたでしょうか。
ここまでをまとめると、
- GraphQLのスキーマは有向グラフである
- リゾルバはグラフの頂点(ノード)に割り当てることができる
- QueryやMutaion(今回取り扱ってないですが)だけでなく他のノードにも
- クエリはスキーマで適宜された有向グラフの方向に沿って解決される
- リゾルバが定義されているノードにたどり着いた時にリゾルバが実行される
- 上記の性質を利用してビジネスロジックを表現することができる
ということになります。
今回の例はスキーマもビジネスロジックもごく単純なのであまりGraphQLの恩恵を実感しにくいかも知れませんが、GraphQLが本領を発揮するのは、
- 複数のデータソース(RDBMS,NoSQL,ファイル,etc...)を統合して単一のAPIを提供する
- さらに複数のAPI(REST,gRPC,他のGraphQL,etc...)を統合してBFF(Backend For FrontEnd)を提供する
といった局面かと思います。
こういった設計をする際に、今回紹介したようなGraphQLの性質が頭に入れておくと、パフォーマンス面やAPIの品質(分かりやすさなど)面でGraphQLの恩恵が受けやすいのでは無いかと思います。
補足
apolloの公式ドキュメントによると、リゾルバに与えられる引数は(parent, args, context, info)です。
つまり、QueryやMutationに対するリゾルバだけではなく、他のノードのリゾルバにおいても引数が取れます。たとえば今回のTaskノードで言えば
"タスク"
type Task{
"タスクのID"
id: ID!
"タスク名"
name: String!
"期限(YYYY-MM-DD hh:mm:ss)"
expiresAt: String!
"完了フラグ(完了していればtrue)"
done: Boolean!
"緊急タスクかどうか"
urgent: Boolean!
"引数に与えられた時間に緊急かどうか"
isUrgentAt(
"調べたい時間(YYYY-MM-DD hh:mm:ss)"
datetime:Strng!
):Boolean
}
上記のisUrgentAt(datetime)のような引数をもつメソッドのようなものを定義することも可能です。
最後にフルソースを貼っておきますので、もしよろしければ思い思いに拡張して頂いて理解を深めてみてください。
フルソース
const {ApolloServer, gql } = require('apollo-server');
/**
* GraphQLのSchema
*/
const typeDefs = gql`
"タスク"
type Task{
"タスクのID"
id: ID!
"タスク名"
name: String!
"期限(YYYY-MM-DD hh:mm:ss)"
expiresAt: String!
"完了フラグ(完了していればtrue)"
done: Boolean!
"緊急タスクかどうか"
urgent: Boolean!
}
"クエリ"
type Query{
"すべてのタスク"
allTasks: [Task!]!
"完了済タスク"
finishedTasks: [Task!]!
"未完了タスク"
unfinishedTasks: [Task!]!
"IDからタスクを取得"
taskByID(
"取得したいタスクのID"
id: ID!
): Task
}
`;
/**
* タスクを管理する内部配列
*/
const tasks = [
{
id: 'd1947409-95b4-4a46-8e83-cc60b94d3dd4',
name: '牛乳を買う',
expiresAt: '2020-01-23 20:00:00',
done: true
},
{
id:'97dcafa7-53d3-47b0-b25f-8457577749c8',
name: 'Qiitaに投稿する',
expiresAt: '2020-01-25 22:00:00',
done: false
}
];
const moment = require('moment');
/**
* GraphQLのResolver
*/
const resolvers = {
/**
* "Query"ノードについてのResolver
*/
Query: {
/**
* すべてのタスク
*/
allTasks: () => tasks,
/**
* 完了済タスク
*/
finishedTasks: ()=> tasks.filter(task => task.done),
/**
* 未完了タスク
*/
unfinishedTasks: ()=> tasks.filter(task => !task.done),
/**
* IDからタスクを取得する
* Schemaで定義したパラメータは第2引数のargsオブジェクトの中に格納される点に注意
*/
taskByID: (_, args) => tasks.find(task => task.id === args.id)
},
/**
* "Task"ノードについてのResolver
*/
Task:{
/**
* taskがurgent(緊急)かどうか
* urgentノードに割り当てられたResolver
* @param {Object} task タスク(Resolverの第1引数には"親ノード"が渡される)
* @return {Boolean} taskがurgentであればtrue
*/
urgent: (task) => !task.done && moment().add(8,"hours").isAfter(task.expiresAt)
}
};
//定義したSchema(typeDefs)とRosolversを使用してApolloServerを作成
const server = new ApolloServer({typeDefs, resolvers});
//作成したApolloServerの起動(デフォルトポートは4000)
server.listen().then(({url}) => console.log(`Server ready at ${url}`));