本記事は、NTTコミュニケーションズ Advent Calendar 2019 の9日目の記事です。
昨日は、 @mtskhs さんの スポーツ解説アプリ SpoLive における分析基盤の構築 でした。
この記事の概要
最近、GCPのCloud Runが正式リリースになったのでなんか作ってみたいなぁと思い、雑にSlackBotを作ってみました。
その作ったSlackBotの紹介をしようと思います。
作ったもの
その名もhaiku-manです。
何が出来るかと言うと
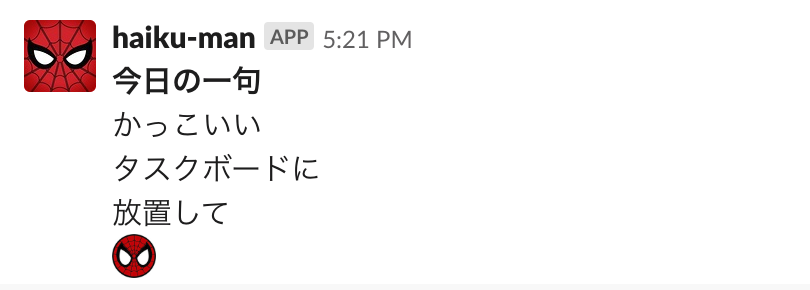
こんな感じで1日1回俳句を読んでくれます。
この俳句の文章は全て自分の分報チャンネルから取ってきています。
分報とは?
僕の所属するチームでは分報を取り入れていて、自分用のpublic channelに仕事の話とかコンビニで買ったお菓子の話とかを毎日色々書いています。
分報がどんな感じで役に立ってるかは以下の記事を読んでいただくとわかりやすいと思います。
https://developer.ntt.com/ja/blog/d55e2be0-255d-4321-9d45-8608ce9d9726
システム構成図
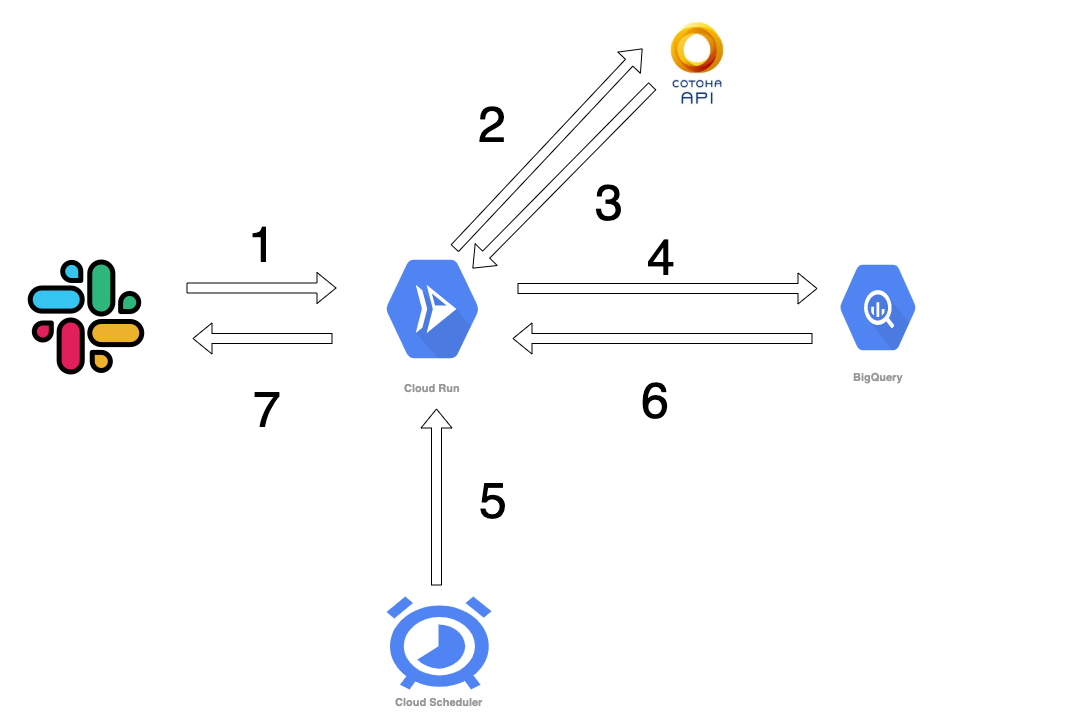
処理の流れは以下の通りです
1.自分の分報チャンネルでの呟きをSlack Event APIを使って取得、サーバー(CloudRunで実装)に送信。
2.呟きをCOTOHA APIで形態素解析にかける
3.COTOHAAPIの結果を受け取って、5音と7音とそれ以外に分ける
4.5音と7音の言葉はBigQueryに挿入してデータを貯める。
5.決まった時間にCloud Schedulerを使ってCloudRunのエンドポイントを叩く
6.その日に溜まった5音と7音の言葉をランダムにBigQueryから取得
7Incomingwebhookを経由してSlackに投稿する
と言う感じです
ここから先は構築時のtips的なことを書いていきます
Cloud RunでのSlackBotの構築方法
Dockerfileの用意
公式ドキュメント
https://cloud.google.com/run/docs/quickstarts/build-and-deploy
Cloud RunはCloud Functionsとは違ってコンテナ上で動作します。
なので、Dockerfileを書く必要があります。
今回のhaiku-manのDockerfileはこんな感じです。
# Use the official Python image.
# https://hub.docker.com/_/python
FROM python:3.7
# Copy local code to the container image.
ENV APP_HOME /app
WORKDIR $APP_HOME
COPY . .
# Install Packages
RUN pip install -r requirements.txt
# Run the web service on container startup. Here we use the gunicorn
# webserver, with one worker process and 8 threads.
# For environments with multiple CPU cores, increase the number of workers
# to be equal to the cores available.
CMD exec gunicorn --bind :$PORT --workers 1 --threads 8 app:app
requirements.txtの中に必要なパッケージを書いてます。
`requirements.txt`の中身はこんな感じです
cachetools==3.1.1
certifi==2019.11.28
chardet==3.0.4
Click==7.0
Flask==1.1.1
google-api-core==1.14.3
google-auth==1.7.2
google-auth-oauthlib==0.4.1
google-cloud-bigquery==1.22.0
google-cloud-core==1.1.0
google-resumable-media==0.5.0
googleapis-common-protos==1.6.0
gunicorn==20.0.4
idna==2.8
itsdangerous==1.1.0
Jinja2==2.10.3
MarkupSafe==1.1.1
numpy==1.17.4
oauthlib==3.1.0
pandas==0.25.3
pandas-gbq==0.12.0
protobuf==3.11.1
pyasn1==0.4.8
pyasn1-modules==0.2.7
pydata-google-auth==0.1.3
pyee==6.0.0
python-dateutil==2.8.1
python-dotenv==0.10.3
pytz==2019.3
requests==2.22.0
requests-oauthlib==1.3.0
rsa==4.0
six==1.13.0
urllib3==1.25.7
Werkzeug==0.16.0
今回は結構いろいろ入れてますが、最低限SlackのEventAPIが使えたらいいとかであれば
RUN pip install Flask gunicorn
として、Flaskとgunicornだけ入れるとか特定のパッケージだけ入れることもできます。
コードを書く
slack event apiの処理はこんな感じです(一部抜粋)
app = Flask(__name__)
@app.route('/slack/events', methods=['POST'])
def slack_event():
if request.headers['Content-Type'] != 'application/json':
app.logger.debug(request.headers['Content-Type'])
return jsonify(res='error'), 400
# event apiの認証部分
if request.json['type'] == 'url_verification':
return jsonify({
'status': 'OK',
'data': request.json['challenge']
}), 200
if request.json['event']['type'] == 'message':
# 受け取ったtextをcotohaapiに投げる
cotoha(request.json['event']['text'])
return jsonify(res='ok'), 200
event apiの認証については、SlackのダッシュボードでRequest URLを指定する際にurl_verificationというtypeのイベントがくるので、そのイベントを受け取ったら、requestのchallengeの値を返してあげるということをやっています。
イメージをGCRへアップロードする
app.pyとかでとりあえず、アプリケーションを書いたら、コンテナイメージをGCR(Google Container Registry)にアップロードします。
この作業にはGCPのプロジェクトIDとかgcloudコマンドの設定とかは必要になります。
gcloud builds submit --tag gcr.io/{YOUE_GCP_PROJECT_ID}/{IMAGE_NAME} --project {YOUE_GCP_PROJECT_ID}
GCRのダッシュボードで指定した{IMAGE_NAME}のリポジトリがあれば成功です。
Cloud Runの設定
使用を開始するから
サービス作成を選択
コンテナイメージURLはGCRへの登録時に使用した gcr.io/{YOUE_GCP_PROJECT_ID}/{IMAGE_NAME}を使います。サービス名はお好きな物を
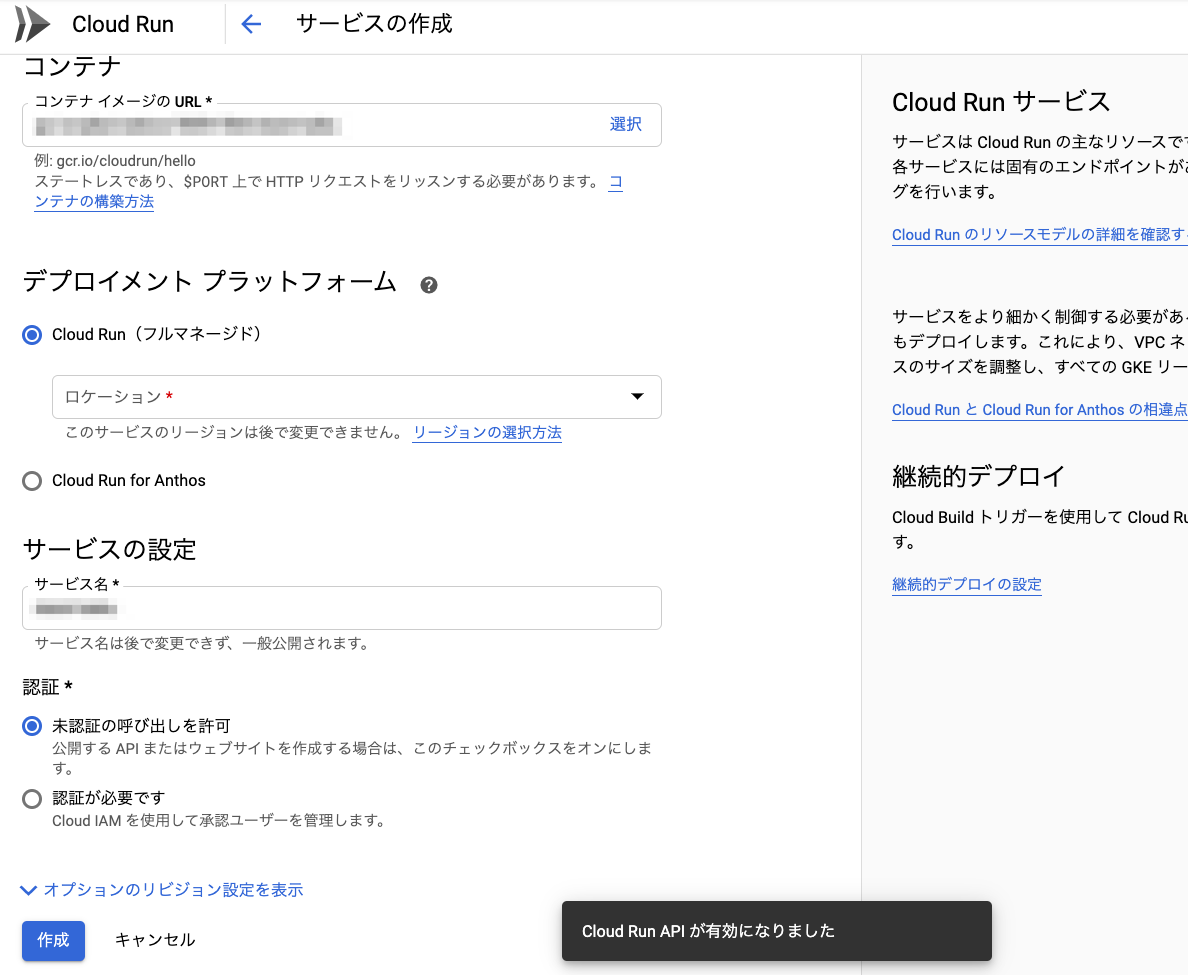
あとはロケーションなど設定すると作成を押すと完了です。
成功するとこんな感じでURLが発行されます。

その他開発中のtips
Slack event APIのtimeoutについて
SlackのAPIは仕様で3秒以内にresponseを返さないとtimeoutになって、同じ内容を再送してきます。
今回は、event APIで受け取ったtextをCOTOHA APIで形態素解析にかけてるので、3秒以内にレスポンスを返すのは難しく、textが再送されて来ると同じ文字が何回もBigQueryに入る可能性があるため、対策する必要があります。
対策としては真っ先に200を返すのがいいらしいですが、Flaskで先に200だけ返して処理を続けるいい方法が思いつかなかったので、headerのX-Slack-Retry-Reasonを見て、http_timeoutだった時はとりあえず、レスポンスだけ返すということをしています。
真っ先に200返す対策法についてはこちら
https://qiita.com/saken649/items/b70e462ae41614b72f77
ドキュメント
https://api.slack.com/events-api
We'll tell you why we're retrying the request in the X-Slack-Retry-Reason HTTP header. These possible values describe their inciting events:
http_timeout- Your server took longer than 3 seconds to respond to the previous event delivery attempt
if "X-Slack-Retry-Reason" in request.headers:
if request.headers['X-Slack-Retry-Reason'] == 'http_timeout':
return jsonify({
'status': 'OK'
}), 200
COTOHA APIでの形態素解析について
tipsかというと微妙ですが、
kanaで漢字の読み方を出してくれるので、文字の数を取る際は、kanaでカウントして、BigQueryにはformの内容を入れるようにしています。
雑に実装する気しかなかったので、kanaがなかったら漢字の文字数をカウントしてBigQueryに突っ込もうと思っていたのであってよかった。
"tokens" : [ {
"id" : 0,
"form" : "犬",
"kana" : "イヌ",
"lemma" : "犬",
"pos" : "名詞",
"features" : [ ],
"dependency_labels" : [ {
"token_id" : 1,
"label" : "case"
} ],
BigQuery周りについて
今回、BigQueryを使ったのは最近仕事でBigQueryを使うことがあって。多少は慣れているからというのが理由です。
個人的には、データ挿入の際にpandasを使って、dataframeで挿入することができるので、SQLとか書く手間がなくていいかなと思ってます。
def insert_bgq(text):
characters_record = [{
'datetime': datetime.datetime.now(),
'text': text
}]
characters_df = pd.DataFrame(characters__record)
characters_df["datetime"] = pd.to_datetime(
characters_df["datetime"], format='%Y-%m-%d %H:%M')
characters_df.to_gbq(
destination_table=f'{settings.BQ_DATA_SET}.{settings.BQ_TABLE_NAME}',
project_id=settings.PROJECT_ID,
if_exists='append',
credentials=service_account.Credentials.from_service_account_file(
'./service-account.json',
))
こんな感じでBigQueryに入ります

Cloud Schedulerについて
Cloud FunctionsやCloudRunを定期的に実行させたい場合はCloud Schedulerが便利です。
こんな感じでGUIでcron的に設定することもできますし、gcloudコマンドを使ってJSONをPOSTすることもできます。
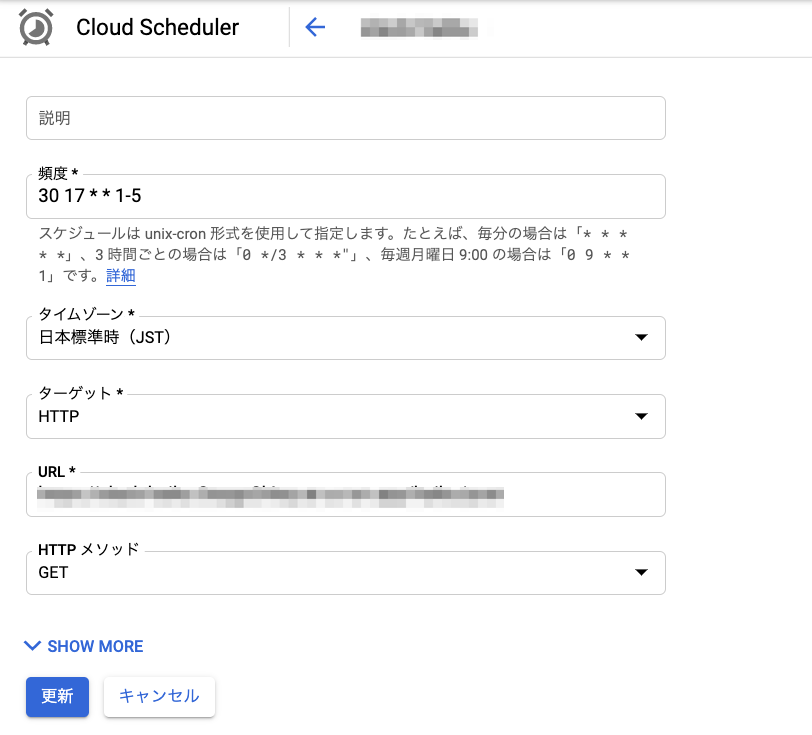
Cloud Runを使っての感想
かなり雑多な記事になりましたが、最後にCloudRunを使ってみての感想を書いておきます。
個人的には開発の段階からDockerのイメージ使っていて、完成したら、そのイメージをGCRに上げてCloudRunの設定をするだけで動いたので少し感動しました。
CloudFunctionsは何度か使ったことがあるのですが、ローカルで開発してからCloud Functionsで動かす時は結構改修した覚えがあるので、その改修が全くなく、すぐにDockerイメージがあればローカルと同様に動かせるのはすごいよかったと思います。
という感じで僕の記事は終わろうと思います。
明日は @koki-sato さんの記事です。