はじめに
この記事ではYukarinライブラリというボイスチェンジができる機械学習モデルをお借りして、Windows10で自分の声を声優さんの声に変換してみることに挑戦しています。
色々な方法を模索した記録としての、メモ書き感が強いです。また、先駆者様の手順に乗っかって進めている部分が多いので、新しい情報は少ないです。
また、この記事はある程度のYukarinライブラリの仕組みを前提知識として書いています。
Yukarinライブラリについて簡単に知りたいという方はこの動画をご覧になるのがわかりやすくて良いと思います。
スペック
・OS:Windows10
・cuda:10.0
・GPU:GTX1080
・RAM:24GB
・CPU:i7-7700
音声処理的なこと
はじめに
このセクションでは音声の準備や環境などに関して書きます。プログラム実行に関する話はプログラムについてを見てください。
目標
声優統計コーパスという公開音声データセットの土谷麻貴さん(喜び)の声に自分の素の声を変換することを目標とする。
土谷麻貴さん(喜び)を選んだのは一番アニメっぽいと思ったので。
スペック(筆者の声)
・すごく声が小さい
・ぼそぼそ喋る
とりあえず学習してみる
解説動画にもあるように、リップシンクなどの雑音は天敵らしい。またハキハキ喋らないと変換が難しいのも理解できる。
しかし、音声変換に良い条件を満たすには筆者的には無理した喋り方をする必要があり、ひいては普段使いしづらい。
ということで、ダメもとで筆者の素の声から声優さんの音声への変換に挑戦してみた。
データの準備
データの録音、編集にはAudacity(https://audacity.softonic.jp/)を使う。
声優統計コーパスで公開されているデータは、音素バランス文という音声特徴のバランスが良い100文を読み上げた100個の音声ファイルである。
やることは音声ファイルに合わせて自分の声を録音することである。
ポイント
1.タイミング
「音声ファイルに合わせて」というのは発声のタイミングもそろえるということで、つまりは同時再生したときハモるようにすることらしい。
ただ「この調整はプログラム側でもある程度行ってくれる」らしいので、割と妥協したところもある。
具体的な手順は
・声優さんの声を聴きながら、かぶせるように同時に喋る
・マイクの入力遅延があるので、録音音声の頭の部分を少し切り取る
で行った。
2.発音
単純に文章が難しい。ちゃんと正しく発音するだけでも難しい。アナウンサー試験?
脳も舌もついていかないので、繰り返し聞いて覚えることで対応した。
3.声量
マイクが悪いのか、喉が悪いのか、全然声が入らない。
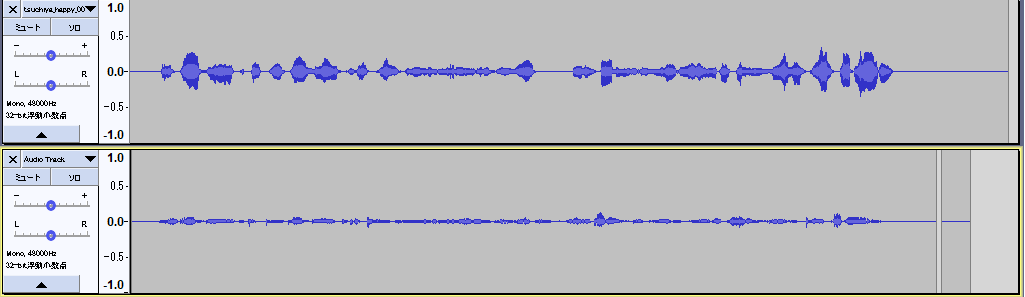
(上:声優さんの声、下、筆者の声)
これでは学習に悪影響が出そうなので、Audacityの増幅機能を使って音量を上げた。
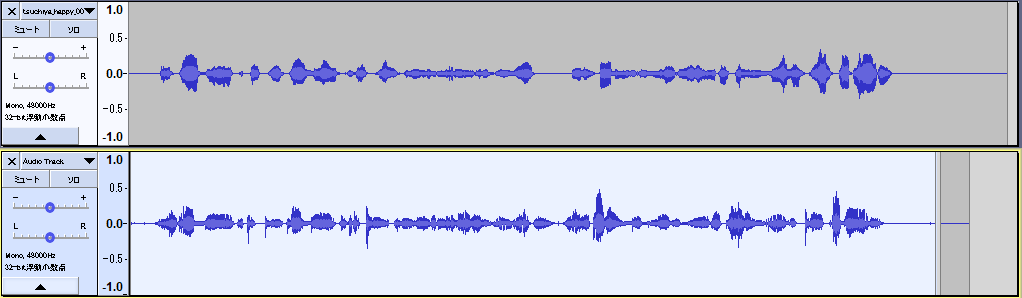
(上:声優さんの声、下、増幅フィルタをかけた筆者の声)
これで声量を同程度にすることができた。ある程度波形も一致しているように見える。
しかしこの手法だとノイズも増幅されてしまうので、悪影響があると思われる。
結局、ノイズキャンセリングマイクを買うかボイトレをするのが良いのだろう。
データ量
当然多ければ多いほど良いが、なかなか骨の折れる作業なのでとりあえず30本分を録音して学習に使う。
このとき録音したファイル名を元データのファイル名と同じにしておくと後が楽。
学習結果
1stStage150000epoch,2ndStage20000epochの学習パラメータを使って変換を行った。
結果、月から話してんのかってくらい無茶苦茶回線悪い人の声に変換された。
単語の聞き取りも危うい。
ダメもとでやってみてダメだったという話なので、今後データや環境を改善してもうちょっとトライしてみたい。
プログラムについて(試した手法)
はじめに
このセクションではプログラムの苦難やエラーについて書きます。音声の用意や楽しい話については音声処理的なことを見てください。
目標
Windowsでディープラーニングのリアルタイムボイスチェンジをしたい(ゲームやりながらDiscordとかしたい)
結論
先に今の時点で出ている結論を紹介します。
・絶対Linuxでやったほうが楽
・現在(2021年12月)のWindows10で「Yukarinライブラリ」を動かすのは非常に大変である
・もしWindowsで動かしたいならこの記事とこの記事を見ながらやるといい
・どの手法でもcupyのインストールが大変
Anacondaを使う(断念)
あらまし
Anacondaは主にPythonの仮想環境構築に使うライブラリで、いろいろなモデルを一つのPC上で動かしたいときによくお世話になる。
環境の作成も手軽で、何か失敗しても外部に影響を与えることが少ない。
しかしその分pip installが使えないという難点もある。
手順
基本的にこの記事と同じような経過をたどった。
Anacondaでつまづき、諦めた後に見つけたのでいろいろショックだった。
大変だったこと
1.condaでinstallできないライブラリがある
pysptkなど。githubなどから引っ張ってくればインストールは可能。
2.リポジトリのPythonバージョン(3.6)だとcondaでinstallできないライブラリがある
pyworld。先駆者様方は3.7にバージョンアップしていたしそれで問題なさそう。
3.cupyのインストール
ここで断念。
cupyのバージョン指定をしてもインストールに失敗する。
正着手はこの方も書かれている通り、
pip install cupy-cuda(cudaバージョン)==5.4.0
とすることだった。(conda installでも行けるのかは未検証)
ここを踏まえてAnacondaに再トライすれば、動かすことができるかもしれない。(たぶんやらない)
Docker Desktopを使う(失敗)
色々試したが、要するにNvidia-Dockerがwin10では使えなかったのが敗因。
win11にアップグレードする、CPU学習で妥協するなどの手法を使えば実行できるかもしれない。
pipでルート環境に構築する(成功)
ルート環境に色々インストールするのは嫌なのだが、仕方ないのでこの方法を試した。(というか、これで駄目なら打つ手はない)
手順
こちらの記事の通りに行った。
cuda関連は既にinstallしてあったので、become-yukarinの環境整備から。
大変だったこと
1.cupyのインストール
記事の参考文献を読みつつcupyのインストールに苦戦する。ここでcupy-cuda100を使うことに気づく。
pip install cupy-cuda100==5.4.0
つまり、結局これで行けた。環境変数などもこの記事を参考に変えたが効果があったのかはわからない。
ライブラリのバージョン調整や追加インストール
スクリプトを実行するとエラーが出て止まることがある。
そのたびエラーの内容を調べて、ヒットしたgithubのissueなどに従いライブラリのバージョンを変えたり追加インストールを行ったりソースコードをちょこっと書き換えたりして解決。
全体通して、そういった比較的軽い問題は何度か起こった。
2.pickleのエラーについて
condaの方もwindowsの方も言及しているのがpickleの問題である。これは学習時(train.py,train_sr.pyの実行時)に発生するエラーである。
解決法はリンク先に示されている。
C:\Usersユーザ名\Anaconda3\pkgs\python-3.6.5-h0c2934d_0\Lib\multiprocessing\http://reduction.py/
の15行目にある import pickleを
import dill as pickleに変更
これで問題なく動くのだが、実は別の問題を引き起こすことが試しているうちに分かった。
それが特徴量抽出がうまくいかないという問題である。
なんでこうなるのかよくわからないが、マルチプロセッシングで並列関数呼び出しをする際になんやかんやあって参照が外れてしまっているようだ。
この問題の対処は簡単である。
import dill as pickleに変更した部分をimport pickleに戻すのである。
つまり、
・学習プログラムを動かすときは「import dill as pickle」に。
・特徴抽出プログラムを動かすときは「import pickle」に編集するということである。無様な解決法だお
3.メモリリーク
最初の学習実行時、急にPCが重くなってブラウザがクラッシュした。学習もエラーで止まってしまった。
なんでかと調べたら仮想メモリ(ページングファイル)がCドライブを圧迫していた。その当時のCドライブの空き容量は10GB程度だった。つまり、Cドライブの空き容量が0になってPCが異常に重くなったらしい。
このプログラムの学習は異常に仮想メモリを使う。しかも物理メモリは使わず仮想メモリばかり使うので、ドライブの空き容量が少ないとすぐ異常終了する。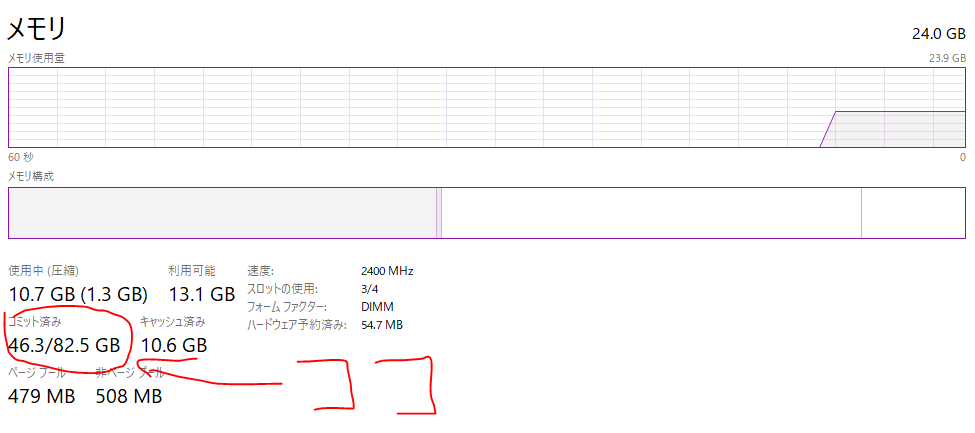
学習中のタスクマネージャーである。このうち大体35GBくらいをこのプログラムが使っている。
仮想メモリは50GBくらいだと止まることもあったので、大幅増設してこの数値になっている。
解決法がわからないので現状は大量の仮想メモリで対抗している。
そもそもこれで仕様通りなのかもしれない。
まだできていないこと
リアルタイム音声変換
試したら追記予定(今のクオリティでやっても……)
参考文献
大変参考にさせていただきました。ありがとうございます。